AWS Database Blog
Schema Conversion Tool blog series: Introducing new features in build 613
The AWS Schema Conversion Tool (AWS SCT) helps convert your existing database schema from one database engine to another. You can convert from a relational OLTP schema or any supported data warehouse OLAP schema to Amazon RDS (for example, Amazon Aurora MySQL or Amazon Aurora PostgreSQL, among others). You can also convert from a relational OLTP schema or a supported data warehouse OLAP schema to Amazon Redshift. Find all the supported sources and targets in our documentation.
AWS SCT is also one of our most updated tools, with frequent builds with new features released about every month. In addition to providing a release note for each feature release, we’re starting a blog series on AWS SCT releases to give more insight into important new features in each build.
We build our roadmap based on our customer requests. As an AWS SCT user, if you want to see a new feature in AWS SCT, feel free to comment on these posts. We’re happy to get feedback from you. You can also choose to leave feedback in AWS SCT itself (go to help and choose Leave feedback).
In this post, we introduce you to some new features that are part of build 613, which we released today. Here is a list of the features we look at in this blog post:
- Oracle to PostgreSQL—SQL script files conversion
- Oracle to PostgreSQL—dynamic SQL conversion improvements for EXECUTE IMMEDIATE, DBMS_SQL, and cursors
- Microsoft Windows authentication support for Microsoft SQL Server as a source
- Greenplum to Amazon Redshift—converting built-in SQL functions to Amazon Redshift scalar SQL UDFs
The new features listed are just a subset of the features that are part of build 613. For a full list, see this release notes section.
Oracle to PostgreSQL—SQL script files conversion
Previous builds of AWS SCT were good at generating assessment reports and converting Oracle database objects, like table structure, indexes, functions, and so on, into PostgreSQL. However, most enterprise database admins also have SQL scripts that they use for their daily tasks like administration and maintenance. These SQL scripts are generally standalone SQL files that were written as part of software projects. Changing database engines to reduce total cost of ownership also means these SQL scripts need to be converted.
As a matter of fact, this conversion was a big request from our customers. Customers wanted to get the same advantage of being able to assess and convert SQL scripts that AWS SCT provides for currently supported database objects.
With build 613, we bring this functionality in AWS SCT for the Oracle to PostgreSQL. Let’s look at an example.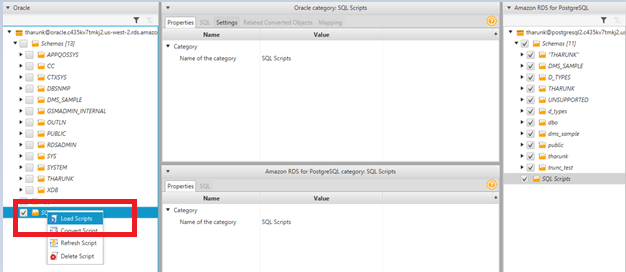
Steps to convert standalone SQL scripts
- Create a new Oracle to PostgreSQL project.
- Connect to the Oracle and PostgreSQL endpoints.
- Uncheck all nodes in the source tree.
- Open the context (right-click) menu for the SQL scripts node and choose Load Scripts.
- Choose the folder with all SQL scripts.
- Open the context (right-click) menu for the SQL scripts node again and choose Convert Script (just like when you convert database objects).
- Review the assessment report and apply the conversion.
Here is an example of a converted Oracle sample HR schema script with the assessment report.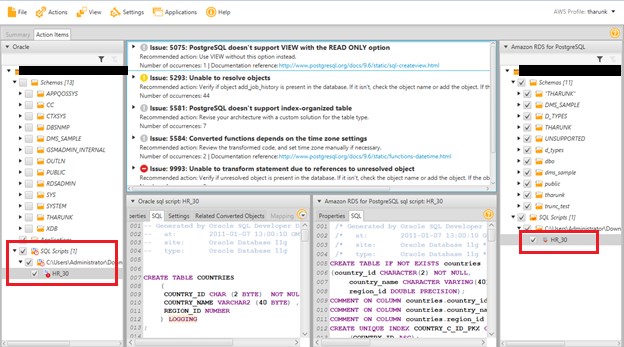
Oracle to PostgreSQL—dynamic SQL conversion improvements
Dynamic SQL is a programming methodology for generating and running SQL statements at run time. It’s useful when writing programs that must run database definition language (DDL) statements. It’s also useful when you don’t know at compilation time the full text of a SQL statement or the number or data types of its input and output variables.
Dynamic SQL parlance in PostgreSQL follows a different set of rules than in Oracle. In certain cases, the syntax and the way to convert these dynamic SQL statements differ across database versions. In this build, we improve the conversion rates of complex dynamic SQL from Oracle to PostgreSQL. We take into account different versions and the syntactical differences between different kinds of dynamic SQL and help successfully convert those into PostgreSQL.
Let’s look at an example.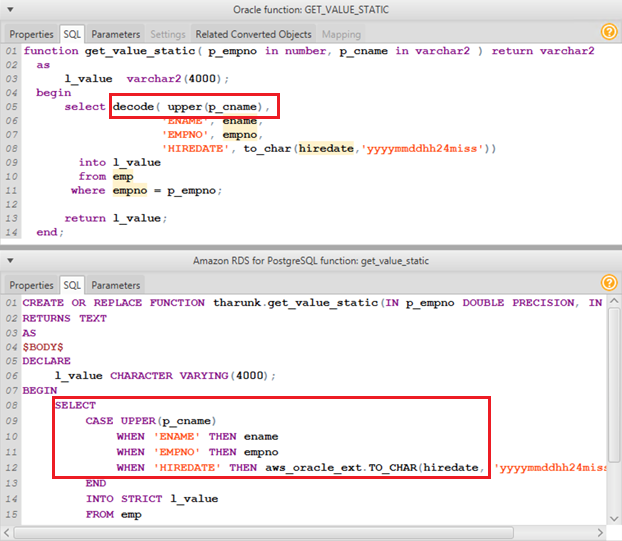
In older versions of Oracle, PL/SQL blocks used the decode statement. This function was eventually replaced by the case statement in Oracle. Enhancements in AWS SCT build 613 can pick up differences like this and convert decode statements into case statements in PostgreSQL. As in earlier builds, you can use the to_char() function conversion from the AWS SCT Oracle extension pack. To learn more about working with extension packs, see our documentation.
Let’s look at another simple dynamic SQL conversion example.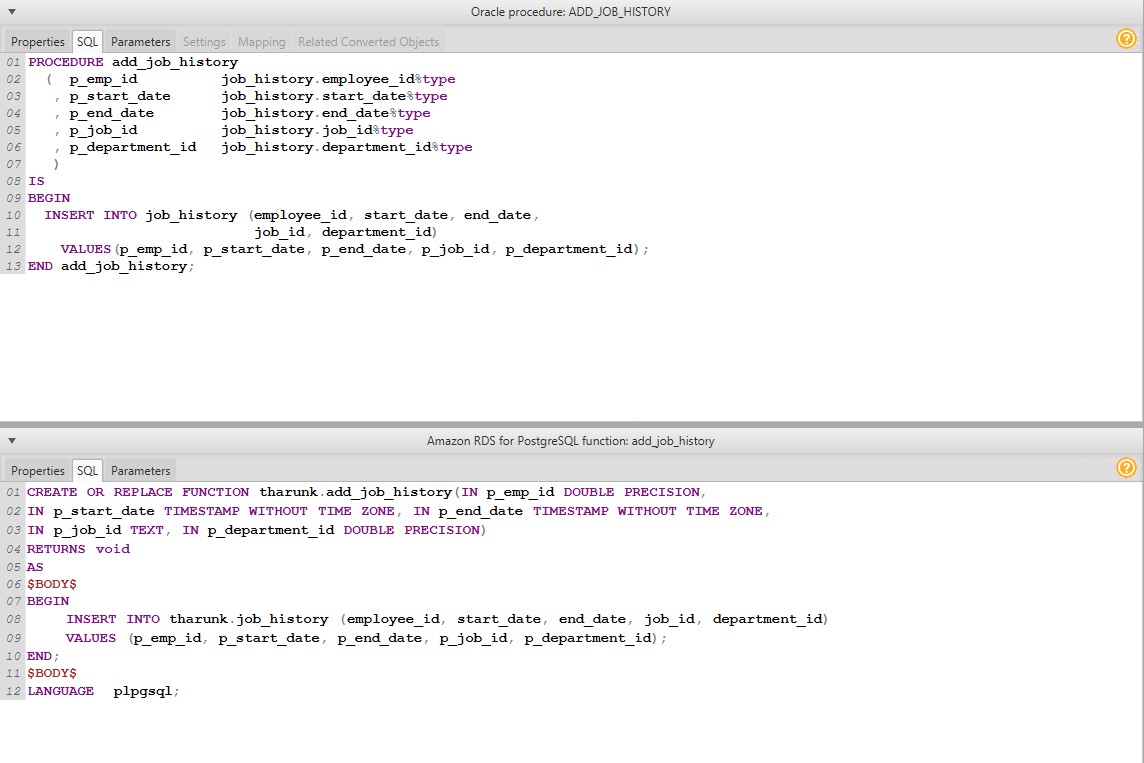 As you can see, PostgreSQL requires you to declare function arguments. AWS SCT goes through the source’s Oracle dictionary to automatically identify those argument types to show a complete conversion from Oracle to PostgreSQL.
As you can see, PostgreSQL requires you to declare function arguments. AWS SCT goes through the source’s Oracle dictionary to automatically identify those argument types to show a complete conversion from Oracle to PostgreSQL.
If you want to see more enhancements in this space, feel free to comment at the end of this post or provide feedback through AWS SCT.
Windows authentication support for SQL Server as a source
Previously, AWS SCT could use the SQL Server endpoint using SQL authentication alone. SQL Server also supports LDAP/Active Directory–based authentication, called Windows authentication. With this release, AWS SCT also supports connecting to SQL Server endpoints using Windows authentication.
Using this new feature is straightforward. To do so, just choose Windows authentication when connecting to SQL Server endpoint, as shown in the screenshot following.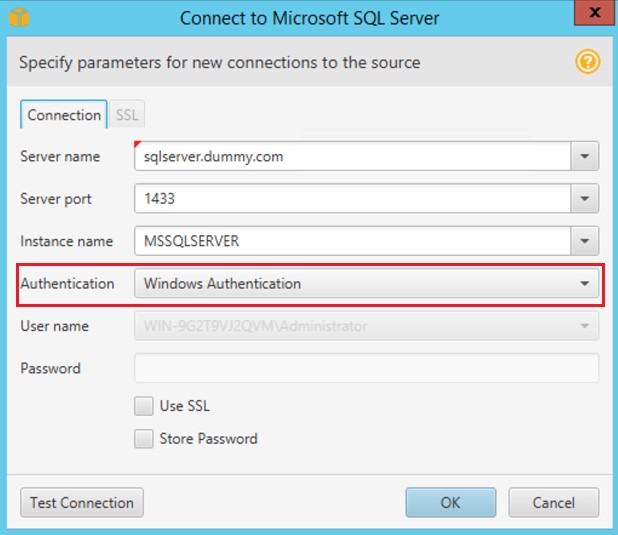
Greenplum to Amazon Redshift—Converting built-in SQL functions to Amazon Redshift scalar SQL UDFs
In Amazon Redshift, you can create a custom user-defined scalar function (UDF) using either a SQL SELECT clause or a Python program. The new function is stored in the database, and you can use it based on the permissions that the logged-in user has in Amazon Redshift.
Starting with build 613, OLAP database object conversions from Greenplum to Amazon Redshift support the conversion of SQL functions to scalar SQL UDFs in Amazon Redshift. A scalar SQL UDF incorporates a SQL SELECT clause that executes when the function is called and returns a single value. The conversion takes into account all Amazon Redshift best practices and rules. The conversion also shows an assessment report for your SQL function conversion and shows converted SQL before you apply it in Amazon Redshift. For more details on writing a scalar SQL UDF in Amazon Redshift, see the Amazon Redshift documentation.
In addition to the features we’re calling out, build 613 delivers many other enhancements. These include custom type mapping improvements, enhancements to AWS profile settings, associative array conversion support for Oracle to PostgreSQL, and others.
As always, any object that AWS SCT can’t automatically convert appears in the assessment report, which we recommend looking at before applying changes on the target endpoint. Assessment reports don’t just show you what can’t be converted automatically. They also give you links to information about how you can convert a particular object based on the target engine’s best practices.
Conclusion
To conclude this blog post, we’re happy that we get feedback on what our customers want through various channels and use that to help improve conversion rates. We want to use this blog series as another channel to collect feedback to improve conversion rates further. We want the series to help you realize the true potential of open source databases in AWS.
If you have a special requirement during your conversions, please feel free to drop a comment on this blog post. We’ll get back to you as soon as possible.
Best of luck for your future migrations!
About the Author
 Arun Thiagarajan is a database engineer with the Database Migration Service (DMS) & Schema Conversion Tool (SCT) team at Amazon Web Services. He works on DB migrations related challenges and works closely with customers to help them realize the true potential of the DMS service. He has helped migrate 100s of databases into the AWS cloud using DMS and SCT.
Arun Thiagarajan is a database engineer with the Database Migration Service (DMS) & Schema Conversion Tool (SCT) team at Amazon Web Services. He works on DB migrations related challenges and works closely with customers to help them realize the true potential of the DMS service. He has helped migrate 100s of databases into the AWS cloud using DMS and SCT.