AWS Database Blog
How to Migrate from MySQL to Amazon Aurora using AWS SCT and AWS DMS
MySQL is a great open-source database engine, which a lot of companies use because it’s cost-effective. However, like any other open-source database, it takes a lot of work to get commercial-grade performance out of it.
As the size of your database increases, the complexity of scaling and crash recovery in MySQL also increases. Scaling out a MySQL database by adding replication slaves introduces challenges to maintaining a very low replication lag, especially when a lot of write activities happen on the MySQL master. Performance consistency is difficult to achieve in most cases.
In comparison, with Amazon Aurora you can add up to 15 read replicas. Also, with Aurora you don’t have to worry about the performance of traditional binary log (binlog) replication to replay changes that occur in the writer node. This is because the data in the cluster volume is represented as a single, logical volume to the writer and read replicas within the Aurora DB cluster.
Fast recovery times in larger databases with many tables is one of the key benefits of Amazon Aurora. In a traditional MySQL implementation, recovery time increases as your database grows. MySQL uses redo log files, so after a crash, MySQL is busy doing table discovery or validation operations. The more tablespaces that the database has, the more time it needs to recover. This effect is still true in MySQL 5.7.
These factors all contribute to interest in migrating from MySQL to Amazon Aurora. There are several possible paths to perform this migration. In this blog post, we look into homogeneous migration. In this case, the homogenous migration is from either Amazon RDS for MySQL or MySQL databases on-premises or on Amazon EC2 to Amazon Aurora with MySQL compatibility.
Homogeneous migration methods
We list the methods that we recommend for homogenous migration in the Amazon Aurora Migration Handbook on the AWS whitepaper site. If you are migrating from Amazon RDS for MySQL, you can use the RDS snapshot migration method. In this method, you create an Aurora MySQL DB cluster from the DB snapshot of an RDS MySQL DB instance. This is very simple and straightforward. If you want a near-zero downtime migration to Amazon Aurora, you can create an Aurora Read Replica from your source RDS MySQL DB instance. RDS takes care of the replication to Amazon Aurora. When you are ready for the cutover, you can then invoke the command to promote the read replica to a primary Amazon Aurora instance using binary log replication.
Now, if your source MySQL database is deployed on EC2 or your on-premises server, we recommend that you use Percona XtraBackup for migration. By using this approach, you can have high performance in uploading your MySQL backup into an Amazon S3 bucket. In this approach, you create a full and incremental backup of your database to Amazon S3. The incremental file on S3 can help with narrowing the difference between the source MySQL and destination Amazon Aurora database. The other option is to use the MySQL native export and import tools. By using native tools, you get the advantage of preserving the schema so you don’t have to do manual conversions later on. However, you might need to do the heavy lifting of optimizing the migration performance. In a third approach, you can set Aurora as a read replica for your existing MySQL database.
In some cases, you might not be able to apply the option that we recommend. For instance, suppose that you are migrating from MySQL 5.7 to an Aurora version compatible with MySQL 5.6. In this case, restoring from an RDS snapshot, restoring a MySQL backup from S3, and making Aurora as a read replica for MySQL might not be options due to compatibility issues between MySQL versions. Also, you might want to supplement a change data capture from your source MySQL database to lessen the downtime during the migration after performing a bulk load from using one of the native tools.
In this blog post, we add another migration path to Amazon Aurora by using AWS Schema Conversion Tool (AWS SCT) and AWS Database Migration Service (AWS DMS). These provide another option in case you can’t use MySQL native binary log replication due to version differences or additional data transformation requirements.
Using AWS SCT for migrating your data
You can use AWS SCT to do homogenous migration of a MySQL InnoDB source database to Amazon Aurora. You can use the tool to export the source database object definitions such as schema, views, stored procedures, and functions from MySQL. However, for version-compatible homogenous migration, we recommend exporting the database object definitions from MySQL using native tools. These include mysqldump and the MySQL Workbench Data Export and Import Wizard.
To start using AWS SCT, create a new project. Set Source Database Engine to MySQL and Target Database Engine to Amazon RDS for MySQL, because Amazon Aurora for MySQL is MySQL-compatible.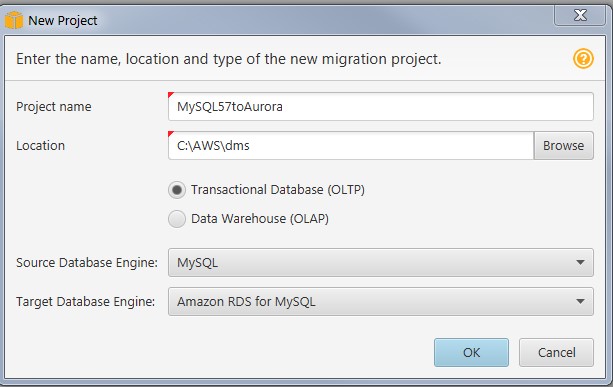
After doing this, specify the connection parameters to the source database and the target database.
To export the database object definition from the source database, right-click on the schema that you want to export and choose Convert Schema.
After the conversion is done, go to the target database section within AWS SCT and save the .sql file containing the database object definitions.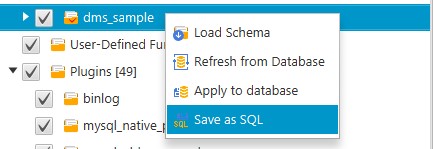
You might have to make a few edits in the AWS SCT .sql file. Editing might be necessary because we use AWS DMS later on. DMS creates the tables and primary keys for us as part of the full data load process. DMS takes the bare minimum to create only the objects it requires to migrate the data efficiently. This DMS feature is why we take this approach, rather than creating the target schema objects manually ourselves.
Because DMS is creating the tables in the target database for us, remove the following sections from the SCT .sql file.
SCT doesn’t export the existing user accounts from your source database. You might have to export the user account information and recreate the users in the target Amazon Aurora database. Alternatively, you can authenticate to your Amazon Aurora database instance using user or role database authentication based on AWS Identity and Access Management (IAM). This approach is very useful if you have an application that is already running on AWS that needs to connect to Amazon Aurora. In this approach, you don’t enter the database user name and password into your application. Instead, you use an IAM role in the EC2 instance where your application resides, which then authenticates you to the Amazon Aurora database cluster or instance.
Using AWS DMS for migrating your data
You can also migrate your data using AWS DMS. AWS DMS can do a one-time data migration, or it can do a continuous replication of the data. For our MySQL to Amazon Aurora migration, we do a bulk load first. We then perform a replication or change data capture (CDC). For ongoing replication changes, DMS has to read from the binary log files of the source database. For this approach, we need to ensure that our MySQL source database has enabled binary logging as the prerequisite.
For a MySQL source that is either on-premises or on an EC2 instance, edit the MySQL configuration file (my.ini or my.cnf) with the following parameters. Then restart the MySQL process.
For RDS for MySQL, set the preceding parameters in the parameter group associated to your RDS instance.
To check if binary logging is enabled, log in to your source MySQL and issue the show binary logs command in your MySQL client.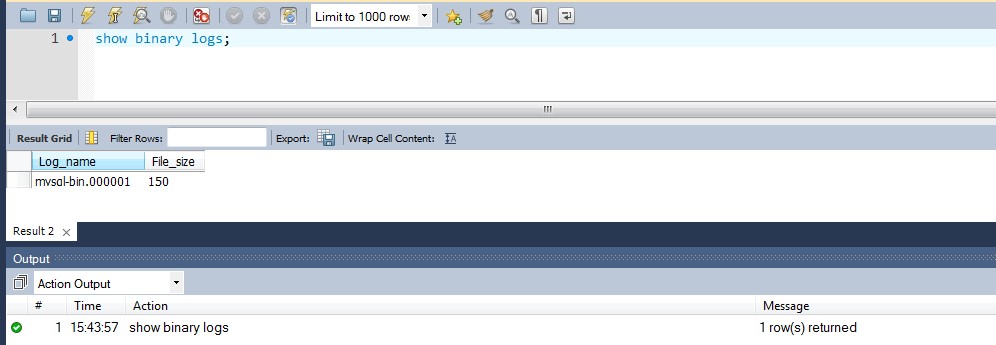
To start the migration process in DMS, first create your source and target endpoints. In this case, our source endpoint is MySQL 5.7 on Amazon EC2 and our target endpoint is Amazon Aurora.
After creating the endpoints, create a DMS task. Specify the task name, replication instance, and source and target endpoints.
For Migration type, we choose Migrate existing data and replicate ongoing changes. We choose this option because we want DMS to perform a bulk load of the existing data and then perform CDC afterward.
Also within the Task Settings section, we specify Stop Before Applying Cached Changes. We specify this option so we can apply the secondary database objects from our AWS SCT .sql file discussed preceding to the target Aurora database.
After we set up the task information, DMS then starts the task. By default, DMS loads eight tables at a time. When the bulk load is done, you should see that your task has changed status to Stopped.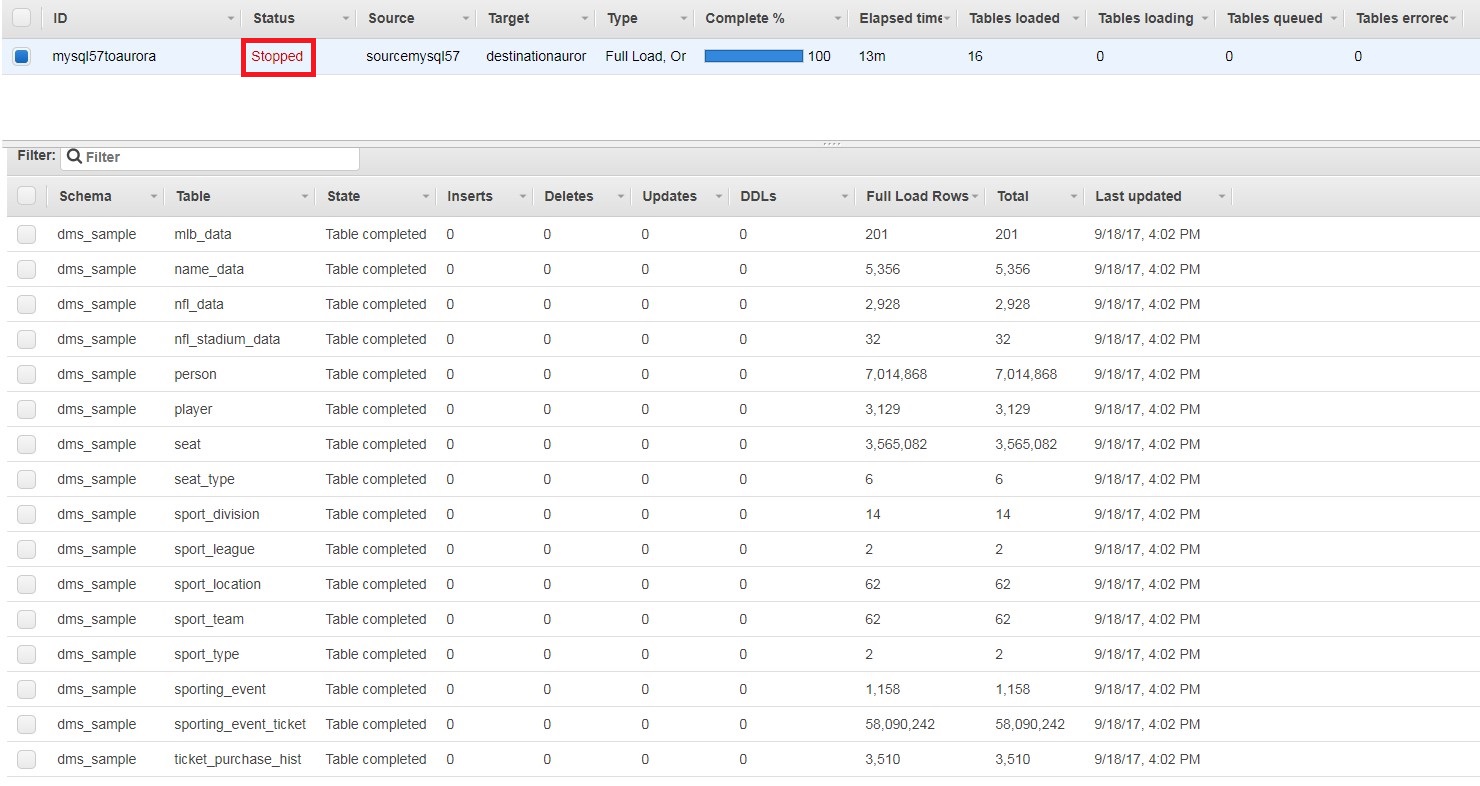
Optionally, you can set up an event notification to monitor the status of your task. If you do, you are notified as soon as the bulk load is done. You then apply the modified .sql script from AWS SCT to your destination database to create the secondary database objects.
After applying your secondary database objects to your Aurora target database, you can resume the task. This time, it performs an ongoing replication. To test that changes in the source database are captured, we add 3,534 rows to the source MySQL’s ticket_purchase_hist table. To check that constraints are created between our tables, we update the sporting_event_ticket table, which has dependencies on the ticket_purchase_hist table. To see if those changes got replicated, check the Table statistics tab for your task under DMS.
To test that changes in the source database are captured, we add 3,534 rows to the source MySQL’s ticket_purchase_hist table. To check that constraints are created between our tables, we update the sporting_event_ticket table, which has dependencies on the ticket_purchase_hist table. To see if those changes got replicated, check the Table statistics tab for your task under DMS.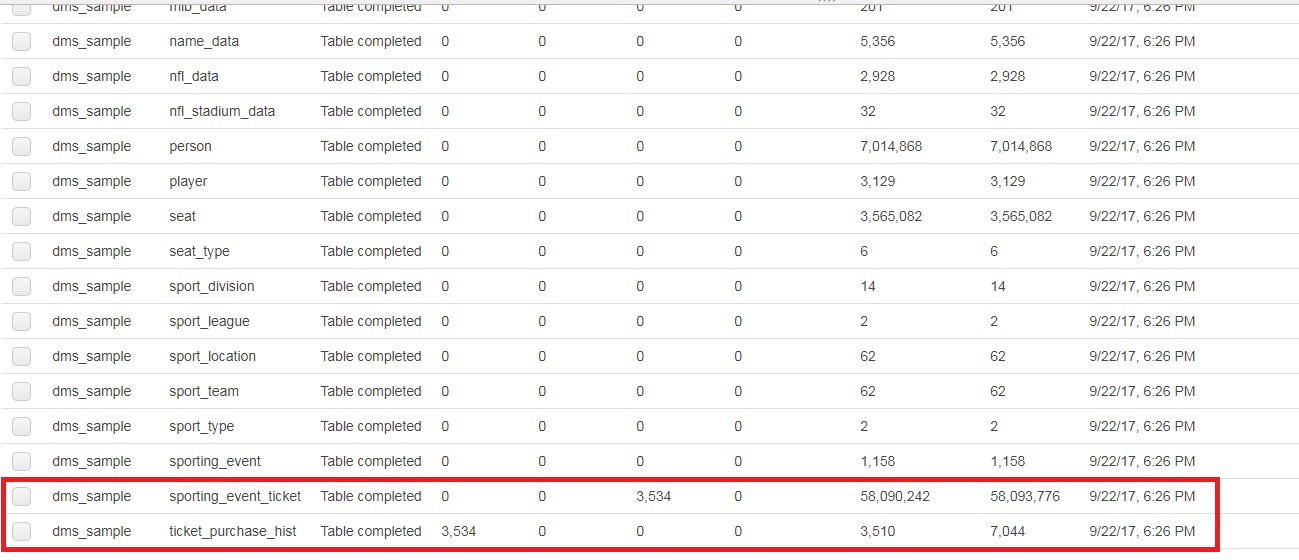
After performing the bulk data load and CDC from AWS DMS, you can use database comparison tools to validate that your source and target databases are in sync. One such tool is MySQL Workbench’s Schema synchronization and comparison utility.
Overall, by using AWS DMS, we overcome version compatibility issues and make the journey of migrating from MySQL 5.7 to Amazon Aurora easier. AWS DMS replication helps reduce the downtime during the migration, which is important for databases supporting mission-critical applications. Now with Amazon Aurora, we gain the benefits of having a highly available and scalable MySQL-compatible database cluster.
About the Authors
 Marie Yap is an enterprise solutions architect at Amazon Web Services. Marie has a technical consulting background focusing on tuning application and database performance for enterprise customers.
Marie Yap is an enterprise solutions architect at Amazon Web Services. Marie has a technical consulting background focusing on tuning application and database performance for enterprise customers.
 Hemant Borole is a big data consultant at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS.
Hemant Borole is a big data consultant at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS.