AWS Database Blog
How Informatica Cloud Data Governance and Catalog uses Amazon Neptune for knowledge graphs
This post was co-written with Tiju Titus John and Deepak Ram from Informatica.
In this post, we discuss the significance of data governance and cataloging, and how Informatica’s latest product can help enterprises address challenges in this area of high complexity. We also discuss how Informatica uses a graph database solution based on Amazon Neptune to track the lineage of enterprise data originating from multiple sources.
Data is a critical asset for successful digital transformation. Data consumers need access to trusted data for various use cases to enhance customer experience, provide a new product or service, or to work towards compliance with regulatory frameworks. The key to success for these initiatives is in having a data governance framework that improves operational efficiency, assures data quality, and provides authorized access to accurate data, empowering business leaders in decision-making. Data lineage plays a critical role in a data goverance and catalog solution.
Gartner defines data governance as “the specification of decision rights and an accountability framework to ensure the appropriate behavior in the valuation, creation, consumption and control of data and analytics.” A data catalog maintains an inventory of data assets through the discovery, description, and organization of datasets. A catalog provides the context that enables data analysts, data scientists, data stewards, and other data consumers to find and understand a relevant dataset for the purpose of extracting business value. Data lineage helps track the origins of data as it moves through its lifecycle, undergoing various transformations and eventual consumption. It can enable tracing back of errors introduced in data along the chain of analytical processes, thereby playing a crucial role in strategic business decisions that depend on the accuracy of underlying datasets.
Why a graph database?
Storing information for data goverance and lineage requires the ability to handle many different entities with complex relationships that aren’t known until runtime. Maintaining and querying data lineage information from a relational database would require complex joins of tables at multiple levels, because data often goes through multiple hops and transformations before it lands in its destination. Using a graph database gave Informatica the flexibility to have the flexibility to have as few restrictions as possible on the number of hops for the data or the number of facts for each asset, allowing us to answer complex queries on data with millisecond response times.
Unlike a relational database, a graph database is optimized for the storage and retrieval of relationships. This provides dynamic searching on the relationships. The assets, relationships, and facts can be modeled as nodes and edges and searched using a graph database.
How does Informatica use graph databases?
Informatica Cloud Data Governance and Catalog is a cloud-native solution that enables you to discover, understand, govern, and trust your data. It unifies data cataloging, governance, quality, and democratization capabilities into a single cloud-native solution for data intelligence.
This multi-tenant software as a service (SaaS) solution is built for organizations with vast assets in cloud data lakes and data warehouses who want to maximize their investments by turning data into insights. The solution combines the capabilities of discovery, lineage, profiling, business glossary creation, stakeholder and policy management, and the ability to document and manage AI models and their implementations. This way, the solution enables self-service analytics and governance for cloud data lakes and data warehouses. It also integrates into existing data landscapes and scans hybrid sources like cloud data lakes and data warehouses across various environments like Amazon Web Services (AWS), Snowflake, Databricks, analytics and BI (business intelligence) systems, databases, ETL (extract, transform, and load) tools, and other cloud and enterprise systems.
The following diagram is a sample dashboard that shows various assets in the catalog.

The datasets are modeled as a graph connecting assets and relationships and published in the catalog. This dashboard is derived from the metadata knowledge graph created after scanning the data ecosystem.
The Informatica Cloud Data Governance and Catalog comes with automated metadata and data profiling scanners that can connect to different data sources such as databases, files, and ETL and BI tools. The physical location of these data sources can be on-premises or in the cloud. The scanners collect metadata about the data, profile the data, and add insights into the collected data using AI models. This data is then formatted and ingested into a graph database (Amazon Neptune) to build a knowledge graph in order to track data lineage from source to target in the catalog.
Let’s look at how this metadata is modeled in the graph database. The data is represented as assets (vertices) and relationships (edges).
As an example, if the scanner scanned an Amazon Relational Database Service (Amazon RDS) for MySQL database, database assets like database names, table names, and column names are added to the catalog. The relationships are parent-child from a database to table and table to column.
The following diagram captures a visual model representation of the assets and relationships in the metadata knowledge graph.

The following screenshot shows how data flows between various databases. Among other capabilities, this helps deduce the data lineage and impact analysis for data assets. This lineage information is obtained by querying the graph database.

The attributes of assets and relationships are referred to as facts in the catalog. Facts can be added or removed from assets or relationships. This allows flexibility in customizing and augmenting them. For example, the asset column can have facts like name, data type, column length, and more.
The Informatica Cloud Data Governance and Catalog provides an out-of-the-box metamodel, which is a collection of asset types and relationship types. Asset types can be Business Glossary Terms, Policy, Domain, or Stakeholders, or technical metadata like Databases, Tables, and Columns. You can customize these asset types and relationship types by changing their facts. You can also add additional asset types or relationship types.
Additionally, Informatica Cloud Data Governance and Catalog provides automated profiling, classifications with intelligent domain, and entity recognition. AI model governance provides organizational visibility into models built over a certain period along with relevant business and usage context.
You can apply search and lineage filters on an attribute of the vertices or edges. The data store should provide indexing capabilities that support indexing on attributes, which can be added at runtime.
Ingesting data to build the knowledge graph
Metadata is ingested to the knowledge graph by different ingestion jobs running in parallel using Apache TinkerPop Gremlin queries. The number of ingestion jobs can vary based on workload, and multiple import jobs can be run at the same time. The ingestion pipeline also supports multi-tenancy. Metadata can be imported and ingested irrespective of order, which requires the same vertices or edges to be edited from different jobs at the same time. The following diagram provides a view of the ingestion pipeline.
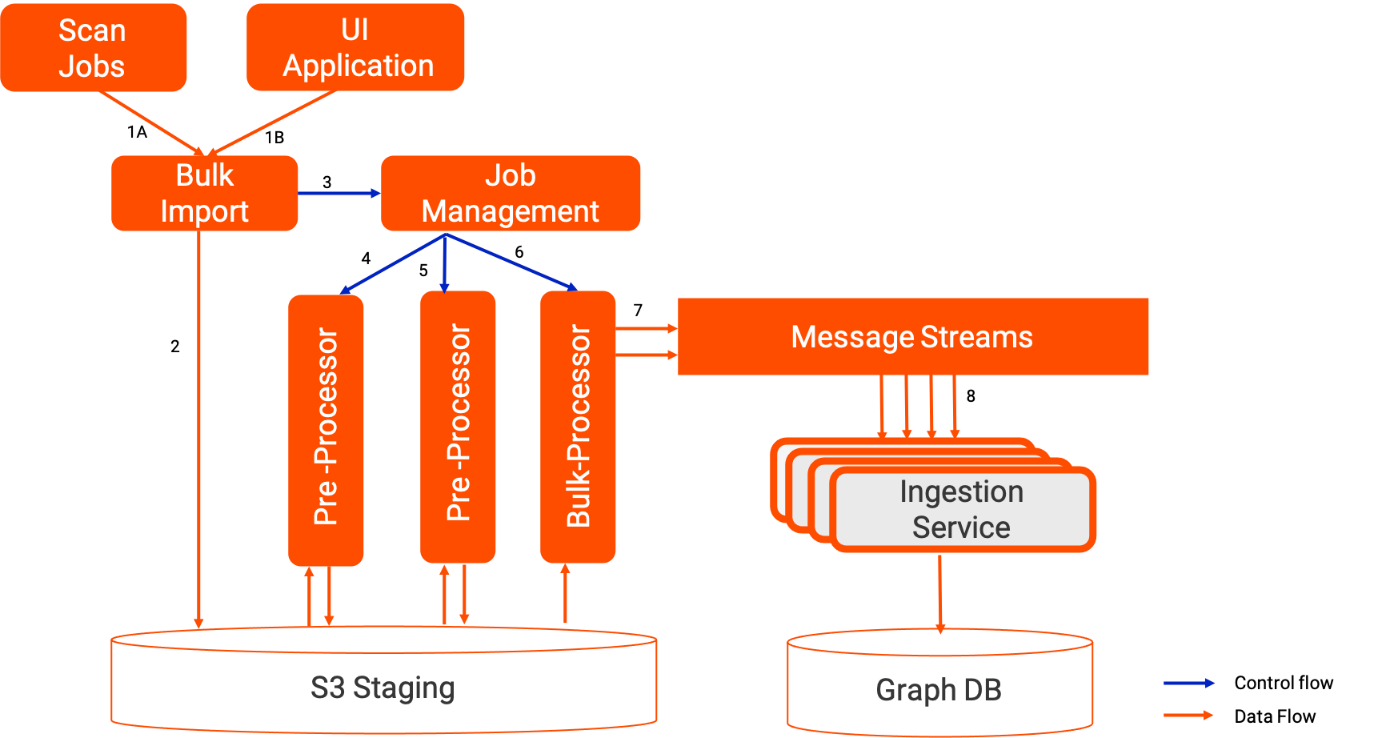
As depicted in the above illustration, the metadata ingestion process involves these steps:
- Multiple clients publishing data via the ingestion pipeline
- Scan jobs periodically can scan resources such as Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Snowflake, Azure Synapse, etc., ingesting data to the metadata knowledge graph.
- User can import business assets and other metadata from Microsoft Excel or CSV files to the knowledge graph.
- The bulk import process stores the data in an Amazon S3 staging bucket.
- The bulk import triggers the orchestration of jobs.
- Various preprocessor jobs such as an Excel processor or data validator are run to transform data into a standardized format.
- The bulk processor processes the data and writes to message streams.
- The ingestion service reads from message streams and ingests to the metadata knowledge graph.
The solution can handle hundreds of millions of assets and relationships, ingesting one million assets, in a short amount of time, to the knowledge graph. Once the data is ingested, it is available for exploring lineage and searching assets within seconds. Scalability, for both ingestion and read, is achieved elastically, as concurrent sessions can increase without impacting response times.
The solution has a lot of parallel write queries with small datasets, while ingesting data to graph in order to avoid deadlocks or concurrent modification waits. It also uses the exponential backoff retry strategy to handle concurrent modification exceptions. With this approach, the solution can ingest millions of assets in a short time.
Queries on data lineage can often be complex and time-consuming. To improve the query performance, various parallel read queries are run for graph traversal. The solution provides an asynchronous streaming API to the clients, combining the results of these parallel read queries.
Why Amazon Neptune?
Amazon Neptune is a managed graph service that meets the performance and scalability requirements of the solution. The Informatica Cloud Governance and Catalog solution uses Amazon Neptune to build the metadata knowledge graph capability. The basic unit of Amazon Neptune graph data is a four-position (quad) element. The following are the four positions of an Amazon Neptune quad: subject (S), predicate (P), object (O), and graph (G). For more information, refer to Neptune Graph Data Model.
Knowledge graph
A knowledge graph captures the semantics of a particular domain using a set of definitions of concepts, their properties, relations between them, and logical constraints that are expected to hold. Logic built into such a model allows us to reason about a graph and the information it contains, and to make implicit information in the graph explicitly accessible. Amazon Neptune provides an ideal tool to build such a knowledge graph in AWS. To learn more, refer to Knowledge Graphs on AWS.
Replicas and elasticity
The metadata knowledge graph is a very read-intensive solution. The read queries should be responded to in real time. Amazon Neptune supports up to 15 low-latency read replicas across three Availability Zones to scale read capacity and run more than 100,000 graph queries per second.
The solution can scale elastically, starting with a smaller cluster but adding more replicas and nodes based on the concurrent query load.
The solution relies on multiple Amazon Neptune clusters to scale across different tenants.
Open API compatibility
Amazon Neptune supports open graph APIs for Gremlin, SPARQL, and openCypher. Apache TinkerPop allows querying graph data as label property graphs, where it can be modeled as vertices and edges.
Amazon Neptune also supports highly concurrent online transactional processing (OLTP) workloads over data graphs. The Apache TinkerPop Gremlin graph traversal language documentation doesn’t define transaction semantics for concurrent query processing. Because ACID support and well-defined transaction capabilities can be very important, Amazon Neptune has introduced formalized semantics to help avoid data anomalies. Refer to Transaction Semantics in Neptune to learn more.
The open standard adoption of Apache TinkerPop Gremlin helped enable the Informatica Cloud Data Governance and Catalog solution to use the available Gremlin tools and libraries.
Conclusion
Amazon Neptune provides a powerful graph data store for the Informatica Cloud Governance and Catalog solution to build the metadata knowledge graph. It helped the Informatica team focus on building the functional capabilities while non-functional requirements of performance, scalability, and recoverability were handled by Amazon Neptune. It also helped in optimizing product development time and reducing the solution complexity.
For a deep dive into the Informatica Cloud Governance and Catalog solution, you can join an upcoming live demo event. The product documentation is available through Informatica Documentation. An to learn more about Amazon Neptune, we encourage you to try the Amazon Neptune workshop and review the product documentation.
About the authors
 Tiju Titus John is a Sr. Development Architect at Informatica.
Tiju Titus John is a Sr. Development Architect at Informatica.
 Farooq Ashraf is a Sr. Solutions Architect at Amazon Web Services.
Farooq Ashraf is a Sr. Solutions Architect at Amazon Web Services.
 Deepak Ram is the Director Product Management at Informatica.
Deepak Ram is the Director Product Management at Informatica.