AWS Database Blog
How Minted scaled their online marketplace on Cyber Monday 2019 by migrating to AWS cloud and Amazon Aurora
This is a guest post by Minted. In their own words, “Minted is an online marketplace for independent artists. Connecting a global creative community directly to consumers, Minted uses technology that enables products to be shared by independent artists who typically lack access to traditional retail outlets. Products available on Minted include works of art, holiday cards, home decor, and stationery created by independent artists and designers spread across all 50 states and across 96 countries. Minted’s community members share a deep love of creative expression, personal development, risk taking, and most importantly, paying it forward by helping each other.”
Minted runs several apps, including main ecommerce platforms, community-related sites to interact with independent artists and designers, wedding websites, and digital invitation platforms. Holiday card sales are one of our key businesses. Because of that, our ecommerce platform gets 10 times more traffic during November and December, especially during traffic peaks on Black Friday and Cyber Monday.
Originally, most of our apps shared a single, centralized MySQL database (DB) cluster backend. We struggled to keep the on-premises database stable and avoid site-wide outages during peak traffic. After we chose Aurora for our databases, it solved most of our database-related scaling problems. We could also move away from our centralized DB cluster to multiple, app-specific DB cluster architectures for better scaling.
This post discusses Minted’s scalability challenges and how we addressed them by migrating our infrastructure to AWS cloud, and in particular how we migrated our database clusters to the Amazon Aurora platform and scaled our online marketplace for Cyber Monday, 2019.
Infrastructure before AWS
The following diagram illustrates our infrastructure architecture before migrating to AWS.
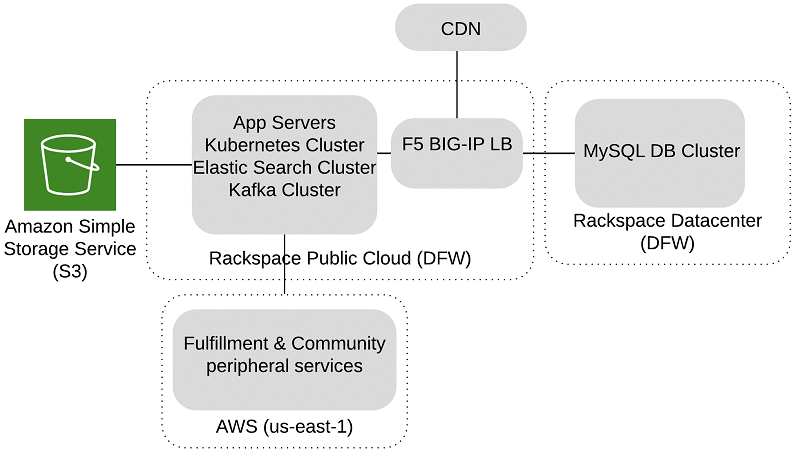
Our original infrastructure was hosted in a hybrid platform that spanned multiple data centers. For example, in the Rackspace public cloud, we had application servers, Kubernetes clusters, Kafka, Elasticsearch, and solr. We also had MySQL DB clusters in a Rackspace DFW data center, image assets in Amazon Simple Storage Service (Amazon S3), and fulfillment and community peripheral services in AWS.
The hybrid infrastructure presented major challenges for us, primarily:
- The Rackspace public cloud didn’t have an instance type powerful enough to handle our peak database load. Our database load peaked at around 20,000 select QPS, 3000 DML QPS, and 18000 database connections. We had to host our MySQL DB clusters in their on-premises data center, which was harder to maintain and scale.
- Our production database infrastructure was in a single data center. Any outage in the Rackspace DFW data center would cause a significant site-wide outage.
- We used a physical F5 Big-IP load balancer to route all L4/L7 traffic in Rackspace. Because of this, we had to plan in advance every year to scale the device vertically for the required throughput.
- We had to preplan our application server capacity needs for holiday traffic and make the request to Rackspace months in advance. This approach wasn’t sustainable and there was no room to accommodate any last-minute capacity increases.
- The Rackspace server provisioning system was comparatively slow to support our frequent deployments.
Migrating to AWS
Migrating all our apps to the AWS Cloud solved most of our capacity- and scalability-related problems. Aurora, in particular, helped address our database scalability problems. We also migrated to cloud services like Amazon Elastic Kubernetes Service (Amazon EKS) and Amazon Managed Streaming for Kafka (Amazon MSK) for our Kubernetes and Kafka infrastructure.
We built our entire infrastructure using Terraform, which greatly simplified our deployment automation framework. Our hosting cost decreased as well. Now we can quickly scale up application servers and Aurora DB clusters for peak days and scale them down as soon as they’re no longer needed. This wasn’t possible at Rackspace, where we usually provisioned 30% more for both application servers and databases, and kept them running for weeks.
The following diagram illustrates our AWS Organization.
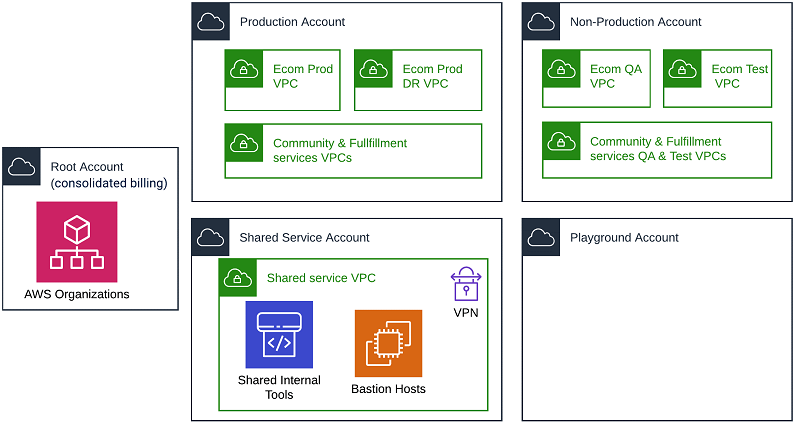
We went with multiple AWS accounts to keep production, non-production and shared internal tools environment isolated for better security as shown in the above diagram.
The following diagram illustrates the ecommerce platform high-level architecture in AWS.
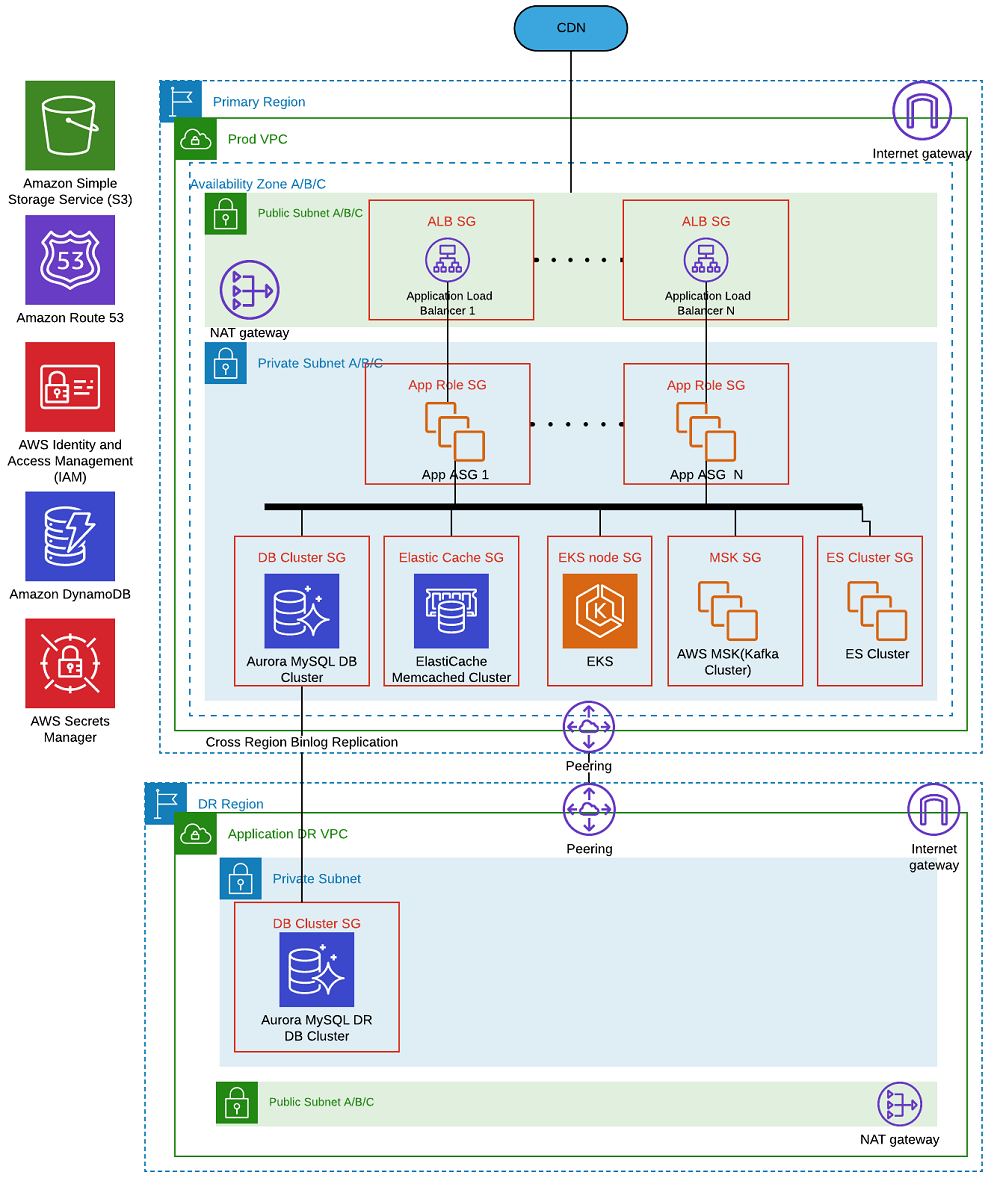
Our ecommerce platform includes shopping funnel, community sites, pricing endpoints, back-office sites. We hosted the entire infrastructure inside an Amazon Virtual Private Cloud (Amazon VPC) in us-east-1 and DR site at another VPC in us-west-2 as shown in the above diagram. We used multi-AZ deployments for infrastructure components like ALB, ASG, Aurora DB, MSK, Elastic cache and Elastic Kubernetes Service cluster for high availability. For security and isolation, we went with separate security groups for every role and also routed all traffic going out of e-com prod VPC to peripheral service VPCs via AWS peering connections.
Migrating our on-premises MySQL cluster to an Aurora DB cluster
The database was the critical part of the migration. We decided to go with Aurora MySQL for the following reasons:
- Powerful instance types – Our ecommerce platform MySQL DB cluster primary instance needs a powerful instance type to handle our holiday peak traffic. We selected db.r5.16xlarge with 64 vCPU and 512 GB memory.
- Zero downtime failover – We need to perform planned DB failovers within minutes or with almost zero downtime. We have experienced a primary instance going into read-only state briefly during failovers on some occasions. However, we’ve still reduced our typical planned site downtime maintenance window from 20 minutes to less than a few minutes overall. This is a huge win for us.
- Low replication lag – We need to keep replication lag to a minimum for maintaining read after write consistency. Aurora replicas share the same underlying volume with the primary instance. This means that we can perform replication in milliseconds because updates made by the primary instance are instantly available to all Aurora replicas. For example, the low replication lag helped us when we modified the schema of a 60 GB table.
- Up to 15 read replicas – This is useful when scaling our read-heavy workload with 200 ms+ slow community and fulfillment queries. We scaled up to only five replicas during Cyber Monday. The number of read replicas mostly depends on the traffic pattern; for example, if we see more traffic on slower pages, we may have to scale up more. This also provides peace of mind knowing that we can scale up replicas in a matter of minutes.
Performing an Aurora load test
Because the DB primary instance is our usual choke point during Cyber Monday peak traffic, we did a load test with a newly built site focusing specifically on Aurora primary DB. We used JMeter to generate load, simulating Minted’s shopping funnel. The load test had the following parameters:
- Instance class was db.r5.12xlarge (48 vCPU, 384 GB memory)
- Aurora MySQL 5.6 version 1.12
- No instances: 2 (Primary & Replica)
Load test observations
- Aurora sustained our Cyber Monday forecasted load of more than 20,000 select queries per second (QPS) and 3000 DML QPS at around 36% CPU utilization as shown in below charts. This load test doesn’t cover all our traffic, so the lower the CPU utilization, the better.

Aurora Load Test Primary DB Select Throughput

Aurora Load Test Primary DB DML Throughput and Latency

Aurora Load Test Primary DB CPU Utilization
- Replication latency stayed at around 20 ms as shown below. This gave us the motivation to unload more queries from the primary to the read replicas.

Aurora Load Test Replica DB Replication Lag
- The only problem is the 16 K hard
max_connectionlimit per Aurora MySQL instance. With a fleet of over 300 application servers, the number of database connections is likely to reach 16 K during real Cyber Monday traffic. We explored adding connection pooling in front of our DB cluster, but due to time constraints, we went with the following workarounds:- Split the main cluster into multiple app specific Aurora DB clusters.
- Reduce
SQLAlchemy pool_recycleto 120 seconds to close and reopen persistence connections every 2 minutes to avoid long sleeping database connections. Fortunately, we didn’t observe any additional load in Aurora when creating and closing connections frequently.
Rackspace to Aurora migration process walkthrough
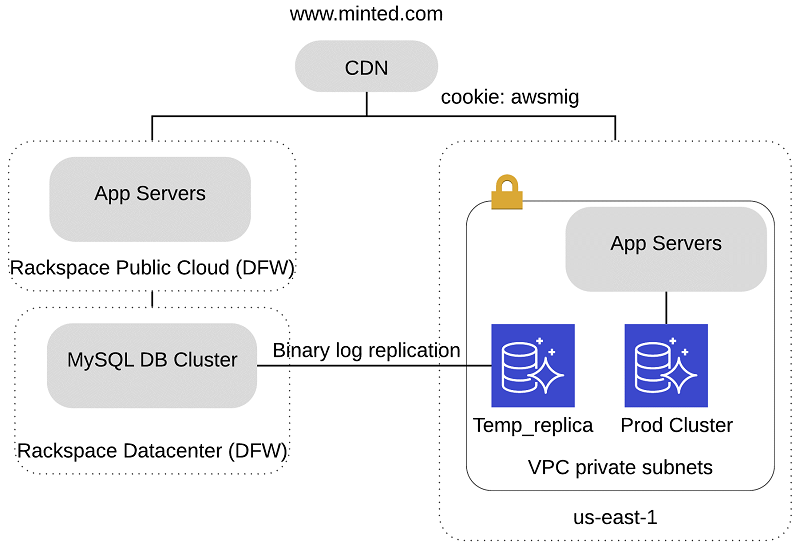
We built a duplicate site on AWS with an exact copy of the apps that we run behind our www.minted.com DNS name as shown in above diagram. The duplicate site was only accessible with the HTTP cookie awsmig:awsmig. This way, we could use the cookie to verify the new site end to end before actual cutover.
The database was the most complex part of the entire migration – we had to keep the downtime as low as possible. We also had to establish reverse replication to keep the option to roll the site traffic back to Rackspace in emergencies. The following steps review our database migration to Aurora.
Phase 1: Establishing database replication from the Rackspace primary to an Aurora replica
Establishing database replication from our primary to a replica included the following steps:
- Set up a secure VPN tunnel between the Rackspace on-premises database network to the new production Amazon VPC.
- Take a backup from the current production MySQL primary instance with Percona xtrabackup.
- Ensure the following entries in
my.cnf:innodb_flush_log_at_trx_commit=1sync_binlog=1
- Use Percona xtrabackup version 2.4.0 or above.
- Ensure the following entries in
- Upload the backup to an S3 bucket in AWS.
- Create an AWS Identity and Access Management (IAM) role for RDS (
rds-s3read-only access) withAmazonS3ReadOnlyAccess. - Create a DB parameter group and DB cluster parameter group via Amazon Relational Database Service (Amazon RDS).
- Create an Aurora DB cluster called
Temp_replicausing uploaded Percona hot backup from the S3 bucket. - Set up binary log replication between the Rackspace on-premises database primary to the newly created Aurora database replica
Temp_replica. - Start the binary log replication.
- Enable binary logging at the Aurora DB cluster
Temp_replica.
Phase 2: Database cutover
The database cutover was a 20-minute site-wide planned downtime. It included the following steps:
- Put the apps under planned maintenance.
- Put the primary database in the Rackspace DFW data center into read-only mode (
SET GLOBAL read_only = 1;). - Wait for the replication to catch up in the Aurora replica
Temp_replicaatus-east-1. - Stop replication and note down the binlog file name and position (
show master status\G). We needed this to establish reverse replication to the Rackspace database. - Promote
Temp_replicato prod cluster primary. - Add readers to the newly promoted prod cluster primary instance.
- Establish reverse binary log replication to a Rackspace database.
- Update the database connection string DNS to point to newly promoted aurora cluster and restart the apps.
- Remove the site from maintenance.
Despite several failed attempts and unexpected outages during this migration process, the database portion went according to plan.
Learnings
We encountered a data corruption issue for timestamp and datetime columns during our initial replication sync between the on-premises MySQL primary and the new Aurora replica. This occurred because of a time zone configuration mismatch coupled with a known MySQL bug. See the following code:
In the preceding code, in the on-premises database primary, time_zone is set to SYSTEM. Because system_time_zone is set to PDT on the on-premises servers, there were no issues with replication between on-premises databases. But when the data moved from the on-premises database to Aurora with time_zone set to SYSTEM, Aurora converted the values of the timestamp and datetime columns to system_time_zone = UTC. We resolved this issue by setting time_zone = PDT instead of SYSTEM in the primary and re-syncing the data.
We wrote the following data validation script using mysqldump to validate the latest subset of rows (at least 1 million) between MySQL primary and Aurora replica Temp_slave to be safe, Most of our tables have auto increment unsigned integer primary key column except a few tables, the below script compares the tables with primary key and we manually compared the ones without primary keys.
Migrating our self-hosted Kubernetes cluster to Amazon EKS
Originally we hosted most of our critical production microservices, such as the pricing endpoint, customizer API, and flink cluster, in a self-hosted Kubernetes cluster. We built those using the Kubespray open-source tool. It was complicated to maintain and scale the self-hosted cluster with a small team, so we chose to migrate to Amazon EKS.
We ran more than 3,000 pods with varying levels of memory and CPU resource quotas assigned during Cyber Monday 2019, when we usually get short and frequent surges in traffic. Amazon EKS doesn’t have monitoring data on its control plane to show the resource usage metrics of primary, etcd nodes. To be safe, we pre-provisioned our worker nodes for our anticipated traffic growth with a buffer instead of automatic scaling. We also told AWS Support in advance to adjust our control plane node resources accordingly. We plan to test automatic scaling on Amazon EKS for our Cyber Monday 2020 traffic.
Moving from self-hosted clusters helped automate our deployment pipeline end to end. The following apps worked seamlessly in AWS and Amazon EKS:
Cluster-autoscalerto auto scale Amazon EKS worker nodes.External-DNSto automatically create or update the Amazon Route 53 DNS record based on an ingress value.Aws-alb-ingress-controllerto automatically create application load balancers.
Learnings
We took away the following learnings from our Kubernetes migration:
- Amazon EKS supports networking via an Amazon Virtual Private Cloud (Amazon VPC) CNI plugin, which assigns every pod in the cluster with an IP from the VPC IP space. Because of this, we ran out of IP addresses and had to adjust the VPC subnet CIDR to keep a larger IP space in reserve.
- The AWS Application Load Balancer ingress controller adds application load balancers automatically and attaches a pod IP address as a target. An AWS target group has a 1,000 target limit, and we had to duplicate services to avoid hitting this limit.
- The
External-dnsapp polls Route 53 at regular intervals. With multiple Amazon EKS clusters, each with its ownexternal-dns, we ended up hitting a Route 53 five API calls/second rate limit, which caused deploys to fail intermittently. We had to increase theexternal-dnsinterval in non-prod environments as a workaround.
Cyber Week 2019
In terms of site stability, Cyber Week 2019 was by far the smoothest event we’ve ever had. We had our highest ever sales day on Cyber Monday, and the ecommerce site performed with no outages or latency issues. We also got great feedback from our artist and designer community about their site experience.
Aurora performed exceptionally well on Cyber Monday. We achieved almost 17,000 select QPS, 1000 DML QPS, and 16,000 database connections on the primary DB instance. Scaling infrastructure, particularly databases during peak traffic, has never been this simple.
As of this writing, we have already moved most of our MySQL database fleet to Aurora. It’s currently our default platform for hosting MySQL databases for all our new apps.
About the Author

Balachandran Ramadass is a Staff Engineer at Minted in the Site Reliability Engineering team. Bala has more than 7 years of experience in DevOps and building infrastructure at the AWS cloud. He has a keen interest in Databases, building microservices in Kubernetes, API performance optimization, and planning & scaling large-scale e-commerce infrastructure for the yearly holiday peak traffic. He holds a Masters degree in Electrical and Computer engineering from Louisiana State University, in his spare time, he loves playing cricket, hiking with his son and cooking.