AWS Database Blog
How to choose the best disaster recovery option for your Amazon Aurora MySQL cluster
August 2025: This post was reviewed for accuracy.
There are many different ways to achieve disaster recovery objectives based on business requirements, but finding the best option for a particular situation can get overwhelming. The innovation and commercial-grade features that come with Amazon Aurora MySQL-Compatible Edition expands these options even further. This post outlines options available to customers running Aurora MySQL, and evaluates the pros and cons of the most common routes to take when developing the database portion of your disaster recovery (DR) plan.
While formulating a DR solution, you need to ask several questions. Performing this due diligence up front can help ensure the success of a DR event and prevent costly over-engineered solutions. First is to define your scope—what applications and services need protection? Development, testing, and staging environments typically have lower uptime requirements than production. Failure modes are also important to consider. What is the effect if a critical instance has a hardware failure? What if a data center experiences a power issue? Or the unlikely event that a natural disaster affects a large geographic region?
DR plans are measured by a Recovery Point Objective (RPO) and Recovery Time Objective (RTO). An RPO is the amount of data you’re willing to lose during a disaster, and an RTO is the amount of downtime acceptable if a disaster were to strike. You should consider what the RTO and RPO are for the applications in scope. After you define these pieces, an architecture can begin to take shape and offer protection against these failures.
To keep this post focused, I only discuss the options available for Aurora MySQL. The data-focused portion of a DR plan is often the most challenging, but the best practices discussed here can help you evaluate and formulate an appropriate plan. Review the Disaster Recovery of Workloads on AWS: Recovery in the Cloud AWS whitepaper for more DR best practices. In this post, I first highlight the built-in durability and availability that comes native with Aurora MySQL. Then I review cases where business, compliance, or legal requirements dictate further protection, and discuss options including cold backups, Amazon Aurora Global Database, and cross-Region read replicas.
Built-in availability and durability
All AWS Regions are built with availability at the forefront by utilizing multiple Availability Zones. Each Availability Zone in a Region contains a grouping of one or more physical data centers connected together with redundant, high-throughput, low-latency network links. Availability Zones are also isolated from each other, allowing you an easy way to build highly available applications within a Region.
Aurora has a unique architecture that separates out the storage and compute layers. The storage layer uses a highly distributed virtual volume that contains copies of data across three Availability Zones in a single Region. The data is automatically replicated to provide high durability and availability. If a problem affects a copy of the data, other copies remain available to serve requests from the database instances. Aurora uses a quorum-based approach for I/O requests, which doesn’t require all data copies to be available in order to process reads and writes. Consequently, the cluster can maintain read and write availability even if an entire Availability Zone becomes unavailable. The three-AZ data storage and replication is provided by every Aurora cluster, regardless of the number or Availability Zone placement of database instances within the cluster.
An Aurora cluster’s compute layer can be comprised of two types of database instances: a primary instance that supports read and write operations, and a replica instance, also called a reader, that supports only read operations. Each cluster has one primary instance and can have up to 15 readers.
When a problem affects the primary instance, an available reader can automatically take over as the primary. This mechanism, known as failover, allows the cluster to quickly regain write availability without waiting for the recovery of the original primary instance. A cluster that contains two or more instances in at least two different Availability Zones is known as a Multi-AZ cluster. Multi-AZ clusters can maintain high availability even in the case of a AZ-wide issue, and they’re backed by a 99.99% SLA.
If the cluster contains multiple instances but all of them are located in the same Availability Zone, it’s a Single-AZ cluster. You can still use failovers to recover from localized issues (such as a hardware host failure), but you can’t improve availability in the case of AZ-wide issues. Single-AZ clusters aren’t covered by the SLA above.
A failover isn’t possible if the cluster doesn’t contain any readers (such as a cluster with one instance), or if none of the readers are available. In such a case, a problem affecting the writer instance renders the cluster unavailable until the problem is resolved.
A failover happens with no data loss (RPO of zero), and typically completes within 30 seconds. The cluster DNS endpoints are updated automatically to reflect the instance role changes.
Knowing how Aurora is architected within a Region is important. While defining failure modes in a DR plan, it should be specified what it’s protecting against—a localized hardware failure, a data center failure affecting an Availability Zone, a widespread geographic issue affecting a Region, or something else.
Now let’s explore options that provide more availability and durability than a single Aurora cluster can provide.
Cold backups with snapshots
Cold backups are the lowest cost option, but come with the longest RTO and RPO. You need to take a backup and restore it to a new instance before the database is back online. The amount of data being backed up affects how quickly a restore can happen.
You can consider a couple different options: service-provided automated backups, manual volume snapshots, and self-managed logical backups (data dumps).
Aurora backs up your cluster volume automatically and retains restore data for the length of a backup retention period, which is configurable from 1–35 days. Aurora backups are continuous and incremental, so you can restore to any point within the backup retention period with 1-second granularity. In addition to the point-in-time restore (PITR) functionality, the service performs an automated storage volume snapshot for each day within the configured retention period. When a cluster is deleted, the continuous PITR backup data is removed, but you have the option to retain the daily snapshots.
To restore using PITR, on the Amazon Relational Database Service (Amazon RDS) console, choose Databases in the navigation pane. Select the cluster DB identifier to be restored and on the Actions menu, choose Restore to point in time. On this page, you can configure the restore time and cluster properties.
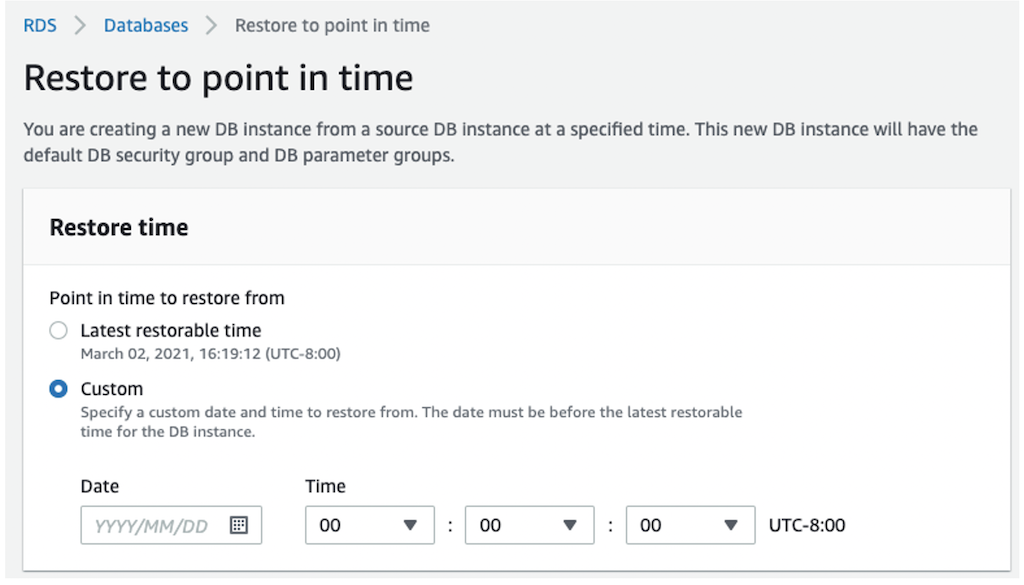
You can also take manual snapshots of an Aurora cluster. The manual snapshots are retained indefinitely unless you delete them.
Both automated and manual volume snapshots are stored with 99.999999999% durability in Amazon Simple Storage Service (Amazon S3). These types of backups use an internal, physical storage format and can’t be used outside of Aurora.
To protect from a Regional issue, after a snapshot is taken, you can copy it to another AWS Region by using the Amazon RDS console, the AWS Command Line Interface (AWS CLI) command copy-db-snapshot, or the AWS SDK command CopyDBSnapshot. For an additional layer of protection against account compromise, these snapshots can also be copied to another AWS account. Once in the other account, it can also then be copied to another region – in turn protecting from a regional disaster and an account compromise.
Cold backups with database dumps
A logical database backup (also referred to as a database dump) is an export of the database contents in a format such as SQL statements, flat files, or a combination thereof. You can use logical data exports to insert the data into another database, whether or not it’s an Aurora cluster. This is most helpful when wanting to use the data outside of Aurora, such as a self-managed MySQL-compatible database. You can complete this process with the mysqldump utility, one of the oldest and most common tools database administrators use to export data from MySQL.
This solution has downsides: you’re responsible for all configuration, storage, and management of the backups. Scale can be problematic; mysqldump is a single-threaded process and larger databases take additional time to complete. To work around this, you need to orchestrate multiple streams or use alternative solutions such as mysqlpump or mydumper.
In case of large exports, it’s best to avoid creating logical backups from active clusters under load. Instead, use the cloning or PITR features to provision a copy of the cluster, then export the data from the copy. Using a copy ensures consistency of the backup, and avoids any negative performance impact that the export might have on the ongoing workloads. The following sample mysqldump command exports all data from the database into a dump file in a MySQL-compatible SQL format:
You can run this command from any instance that has access to the database; a dedicated backup or utility server usually works well.
Although you can use cold backups for cross-Region disaster recovery, the RTO and RPO of a backup-based approach might not be acceptable. Next, we explore solutions using multiple clusters and continuous data replication.
Physical replication with Aurora Global Databases
Many business-critical applications require fast and consistent replication, and engineering teams want an easier way to fail over in the event of a disaster. Aurora Global Database helps you overcome these challenges—for both disaster recovery and multi-Region deployments.
Rather than relying on backups or snapshots to make data available in another Region, a global database takes the proven storage-level physical replication technology of Aurora and applies it across Regions. This enables low-latency global reads and provides fast recovery from an unlikely event that could affect an entire Region. An Aurora global database has a primary DB cluster in one Region, and up to five secondary DB clusters in different Regions. The primary cluster supports read and write operations, whereas the secondary clusters are read-only.
The global database provides very low cross-Region replication lag, typically under a second, even under heavy workloads. The low lag translates to a low RPO for cross-Region disaster recovery. You can monitor replication lag with the Aurora Global DB Replication Lag Amazon CloudWatch metric.
It’s also easy to set up. On the Amazon RDS console, select your Aurora cluster. On the Actions menu, choose Add AWS Region.

With the wizard that follows, set your global database identifier and the secondary Region along with a few other configuration parameters to get started.
In the event of a disaster, you need to remove the DR cluster from the global database and promote it to a standalone cluster. To remove the DR cluster from a global database, select it on the Amazon RDS console and choose Remove from global database on the Actions menu.

This process typically takes less than a minute (RTO) while replication is stopped and the selected cluster’s writer endpoint becomes active. The process is often referred to as promotion, because the cluster is promoted from a secondary role into a standalone, independent entity capable of handling read and write traffic. For more information, see Disaster recovery and Amazon Aurora global databases.
Promoting a cluster stops cross-Region replication into that cluster permanently. You can’t reattach that cluster to an existing global database, but you can add a new global database with this cluster as the primary. You can do this by selecting the newly promoted cluster and choosing Add AWS Region on the Actions menu.
Due to the requirements of physical storage-level replication, all clusters within the global database must be running the same supported major version (such as Aurora 1.x or Aurora 2.x). You’re charged for the Aurora cluster in the DR Region along with replicated write I/O to that Region. Replicating to non-Aurora MySQL instances with physical replication isn’t supported, but you can set up logical replication from an Aurora global database cluster to a non-Aurora cluster.
You can test DR failure and failback by utilizing the Aurora Global Database managed planned failover feature. This feature allows the primary writer’s Region to change with no data loss, and without breaking the global replication topology. This feature is intended for controlled environments, such as DR testing scenarios, operational maintenance, and other planned operational procedures. Managed planned failover is designed to be used on a healthy Aurora global database. To recover from an unplanned outage, follow the “detach and promote” process described above and further detailed in Recovering an Amazon Aurora global database from an unplanned outage.
Aurora Global Database also comes with an optional feature called write forwarding. When enabled, read queries sent to a database endpoint in the secondary Region get run there, but supported write queries are forwarded to the primary Region.
Aurora Global Database provides the lowest consistent RTO and RPO option while requiring the least management overhead.
Logical replication with Cross-Region read replicas
MySQL’s binary log (also referred to as a binlog) replication has been around for quite some time. It’s based on recording changes in a binary log on the primary database, and replaying those changes on replica databases. The changes are recorded and replayed in a logical form—in other words, the replicas are redoing the work that was originally done on the primary database. This is different from physical storage-level replication in Aurora that modifies storage contents directly without having to redo the work at the database level.
You can set up cross-Region logical replication in two different ways: using the cross-Region replica feature in Aurora, or manually.
Both methods require that binlogs are enabled before starting. You can do this by changing the cluster parameter group. A restart of the cluster is required before the change goes into effect.
After the binlogs are enabled, the cross-Region read replica feature is the easiest way to get started. The setup process performs all steps required, including creating the destination Aurora cluster. On the Amazon RDS console, select the Aurora cluster and on the Actions menu, choose Create cross-Region read replica.
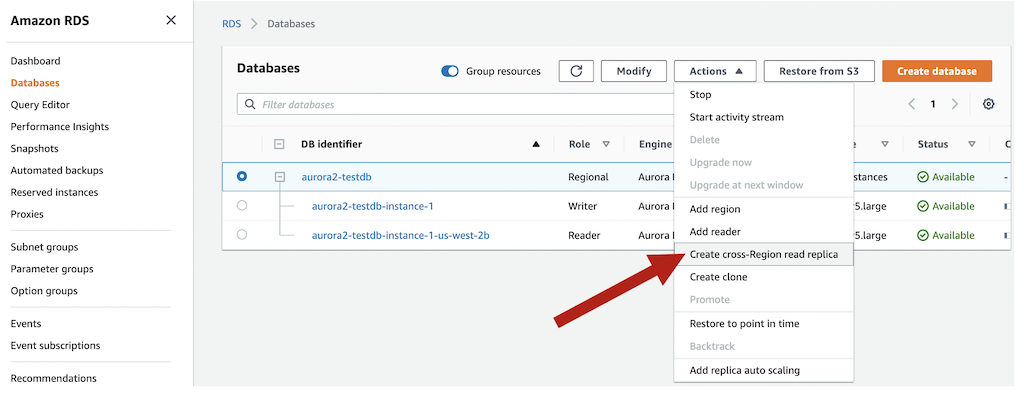
This brings up a wizard to select the destination Region and other common cluster configuration options. When it’s complete, a snapshot is taken of the instance, replicated to the destination Region, and binlog replication is set up to the destination cluster. If a database is encrypted, the setup process also handles this.
We recommend setting the read_only MySQL global parameter on this DR cluster to ensure it doesn’t get out of sync with the primary writer due to inadvertent write activity on the replica. This replica can also serve read traffic for users closer to that cluster, however the read splitting logic to make this happen falls on application owners.
One of the challenges of the logical replication approach is that write-intensive workloads can lead to substantial replication lag, something that you need to monitor closely in the context of disaster recovery use cases. To view how far behind a replica is, use the SHOW SLAVE STATUS SQL query, focusing on the Seconds_Behind_Master value. CloudWatch also monitors this with the Aurora Binlog Replica Lag metric. Another consideration is that binlog replication requires resources on the source and destination, and this can cause performance bottlenecks in write-intensive databases.
In the event of a disaster, you can promote the cross-Region replica to a standalone database. If possible, first check the replica lag in CloudWatch or with the SHOW SLAVE STATUS query to determine the RPO of the data. Then proceed by going to the Amazon RDS console, selecting the DR cluster, and on the Actions menu, choosing Promote.

This stops the cross-Region replication and reboots the DB instances. When that is complete, update the read_only cluster parameter to false, and set the application to the new cluster endpoints.
As an alternative to using the managed cross-Region read replicas, you can manually configure an Aurora cluster or a MySQL-compatible database to replicate from an Aurora source using binary logs. As a general rule, Aurora and MySQL support replication from one major release to the same major release, or next higher release. For example, you can replicate from Aurora MySQL 5.6 (1.x) to Aurora MySQL 5.6 (1.x), Aurora MySQL 5.7 (2.x), MySQL 5.6, or MySQL 5.7. Review Replication Compatibility Between MySQL Versions before setting up replication between different major versions.
To manually set up binary log replication into an Aurora cluster, use the mysql.rds_set_external_master stored procedure on the destination. This is useful when setting up cross-account replication to protect against an AWS account compromise. To set up replication into a non-Aurora destination, use the CHANGE MASTER TO SQL statement on the destination. This is commonly used to establish replication to a self-managed MySQL database in Amazon Elastic Compute Cloud (Amazon EC2), or an on-premises MySQL server.
Logical binary log replication can be considered a middle-of-the-road option. It provides greater configuration flexibility than physical replication (Aurora Global Database) at the expense of RTO and RPO. The RTO and RPO vary based on workload because they depend on the replica keeping up with the change records being sent from the primary database.
None of the options discussed here automatically fail over a database to another Region; this decision and action remains in your control.
Cross-Region and Cross-Account Backups with AWS Backup
AWS Backup provides a fully managed solution for automating and centralizing backups of Aurora MySQL clusters. Through seamless integration with Aurora, AWS Backup allows you to create and manage database snapshots. By associating your cluster with AWS Backup, you gain the ability to perform point-in-time recovery. This integration not only simplifies backup management across your AWS environment but also provides a robust foundation for protecting your critical database workloads across your AWS environment.
AWS Backup extends Aurora MySQL’s disaster recovery capabilities by providing Cross-Region backup protection. You can copy backups to multiple AWS Regions, either through on-demand copies or scheduled backup plans. The service uses backup plans to define the scheduling and destination of your Aurora MySQL backups, with backup vaults serving as secure storage locations in destination Regions. When copying to a new Region, AWS Backup performs a full copy of the Aurora MySQL backup.
AWS Backup additionally offers cross-account capabilities for Aurora MySQL clusters. This feature enables secure copying of backups to different AWS accounts within your organization. Implementation requires two accounts within the same AWS Organizations structure, along with a backup vault in the destination account configured with appropriate encryption and access policies. For encrypted Aurora MySQL clusters, the source account’s customer managed key must be shared with the destination account. Through backup plans, you can automate these cross-account copies, maintaining complete backups of your database in separate accounts.
The service manages encryption automatically for copied backups, utilizing the KMS key associated with the destination vault, even for backups that were originally unencrypted. When copying across Regions, AWS Backup always encrypts the backup using the destination vault’s key. However, it’s important to note that copies of unencrypted Aurora MySQL clusters remain unencrypted for both cross-region and cross-account copies. For cross-account scenarios, encrypted Aurora MySQL clusters require customer managed keys (CMKs), as AWS managed keys cannot be shared between accounts.
For step-by-step instructions and considerations on how to implement a disaster recovery strategy using AWS Backup for your RDS resources encrypted with Amazon Managed Key, review Protecting encrypted Amazon RDS instances with cross-account and cross-Region backups. If your RDS resources are encrypted with Customer Managed Key, refer to Automate cross-account backups of Amazon RDS and Amazon Aurora databases with AWS Backup.
Aurora Cloning
Aurora cloning provides a powerful addition to your disaster recovery toolkit for Aurora MySQL clusters by offering a fast and storage-efficient method to create independent database copies. Aurora’s clone feature leverages a copy-on-write protocol that initially shares data pages between the source and clone clusters, requiring minimal storage overhead. Additional storage is allocated only when either cluster modifies data. The clone operates as an independent cluster that can be configured differently from its source, providing the flexibility needed for comprehensive DR testing. While cloning serves as a complement to other DR strategies rather than a primary solution, its unique combination of rapid deployment, storage efficiency, and cross-account capabilities makes it an invaluable tool for maintaining and validating your disaster recovery procedures without impacting production workloads. To learn more about Aurora Cloning and it’s limitations, refer to the Aurora documentation.
Aurora Backtracking
Aurora MySQL’s backtrack feature provides a unique approach to disaster recovery by providing a “rewind” mechanism for your Aurora MySQL DB clusters. Unlike traditional backup and restore processes that launch new clusters and can take hours to complete, backtracking allows you to return to a previous point in time within minutes. This feature proves particularly valuable when recovering from an operational incident, such as an accidental DROP TABLE command or a DELETE without a WHERE clause. By specifying a target backtrack window, Aurora maintains change records that enable this time-travel capability. The actual window for recovery depends on your workload and storage availability, with Aurora automatically notifying you if the actual window becomes smaller than your target. While backtracking doesn’t replace your standard backup strategy, it significantly reduces recovery time for specific disaster scenarios. The ability to move both backward and forward in time within your backtrack window also enables quick validation of data changes, making it an effective tool for both immediate recovery and investigative purposes.
In order to enable Backtrack on an existing Aurora MySQL Cluster, you have to take a snapshot of your Aurora MySQL Cluster and restore it to a new Cluster, turning on the backtrack feature during the cluster creation process. To learn more about Aurora Backtracking and it’s limitations, refer to the Aurora documentation.
Conclusion
Whether the defined failure protection modes cover a hardware failure or a natural disaster, with an RTO and RPO of seconds, hours, or days, Aurora offers flexible options to meet the requirements. In this post, we reviewed the five most common options AWS can help you build; deciding which route to go largely depends on the requirements defined for the application:
- Aurora MySQL (single Region) – Provides fully managed in-Region protection with a highly distributed storage layer, and quick automatic in-Region failover. RPO is zero and RTO is typically 30 seconds to a few minutes, providing protection against hardware failures and Availability Zone-specific problems.
- Cold backups with Aurora volume snapshots – Provide an easy and cost-effective option to durably store data, while also allowing for cross-Region copies. RPO in-Region is as low as a few minutes with PITR, and RTO can be minutes up to a few hours dependent on cluster volume size. This option protects best against accidental data deletion, with a path to restore a cluster to a different Region.
- Cold backups with database dumps – A manual option most useful on small databases. RTO and RPO are longer and dependent on manual processes. This is best used to restore a backup to MySQL running on Amazon EC2 or an on-premises server.
- Aurora Global Database – Provides a fully managed cross-Region option with consistent replication throughput by utilizing dedicated infrastructure that handles the replication rather than the source and destination instances required to do so in logical replication. This provides for an RPO of typically less than a second, and an RTO of a few minutes. Protects against natural disasters affecting a Region and allows for easier building of multi-Region applications. You can also maintain only synchronized storage by utilizing headless cluster, helping in cost optimization.
- Logical replication – Managed and unmanaged options available that utilize MySQL’s built-in binary log replication technology. RPO is as low as a few seconds, but this can be highly dependent on the database workload. RTO is typically a few minutes, but also dependent on replication delay. You can replicate to a different AWS account to protect against account compromise.
- Aurora Cloning – Provides rapid, storage-efficient database copies using copy-on-write protocol, requiring storage only for modified data. Enables independent cluster configuration for DR testing with cross-account capabilities. While complementary to primary DR strategies, offers quick deployment and validation of DR procedures without production impact.
- Aurora Backtrack – Enables rapid “rewind” capability for Aurora MySQL clusters, allowing recovery to previous points in time within minutes. Particularly effective for operational incidents like accidental data modifications. Requires enabling during cluster creation via snapshot restore of existing clusters. While complementing standard backups, offers significantly reduced RTO for specific scenarios with bi-directional time-travel within configured window.
A database is only one portion of a complete disaster recovery solution. It’s also important to practice a DR plan by running each step in it. By running a DR plan in a controlled fashion, you can learn about what works and what doesn’t so if a disaster strikes, you’ll be ready and able to meet the RTO and RPO set out by the business. Comment and let me know what options align most with your DR objectives.