AWS Database Blog
Implementing real-time change data capture with Debezium for Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL
Amazon Aurora PostgreSQL-Compatible Edition (Aurora PostgreSQL) and Amazon Relational Database Service (Amazon RDS) for PostgreSQL support native streaming replication, which allows data changes to stream from source databases. However, many organizations struggle to reliably capture and propagate these changes to downstream systems in real time without affecting database performance or introducing data lag. Traditional batch-based extract, transform and load (ETL) pipelines fall short, often introducing delays of minutes or hours that make it impossible to react to events in real time. The result is stale inventory data, delayed notifications, and missed opportunities to act on transactional signals as they occur. Debezium, an open-source distributed platform for change data capture (CDC), monitors databases and streams changes to applications or data pipelines. It streams changes from databases to Kafka topics in real time to support event-driven architectures. This capability helps businesses maintain up-to-date data across multiple systems, reduce data synchronization delays, and respond instantly to business events.
When building event-driven architectures that require low-latency streaming of database changes to Apache Kafka, Debezium is a natural fit, particularly for architectures where downstream consumers need to react to individual database changes in near real time. This post focuses on the Debezium approach for teams building event-driven architectures on Amazon Aurora for PostgreSQL.
Debezium provides purpose-built, real-time streaming by reading directly from PostgreSQL’s Write-Ahead Logging (WAL), which provides low-latency data delivery for analytics, machine learning, Large Language Model (LLM)-based applications, and Retrieval-Augmented Generation (RAG) applications.
In this post, we demonstrate how to implement a production-ready CDC solution by using Amazon Aurora for PostgreSQL, Debezium connectors, and Amazon Managed Streaming for Apache Kafka (Amazon MSK). This solution captures database changes in real time and streams them to Kafka topics so that downstream consumers can process the same data for different business purposes.
Solution overview
This post’s CDC solution uses the native logical replication capabilities of PostgreSQL combined with the robust change capture framework of Debezium. Both Amazon Aurora for PostgreSQL and Amazon RDS for PostgreSQL support logical replication, providing flexible options for implementing CDC solutions. However, in this post we use Amazon Aurora for PostgreSQL.
The solution begins by enabling logical replication on Amazon Aurora for PostgreSQL through DB cluster parameter groups. Debezium connectors then monitor the database’s WAL through logical replication slots, converting transaction log entries into structured event streams for downstream consumption.
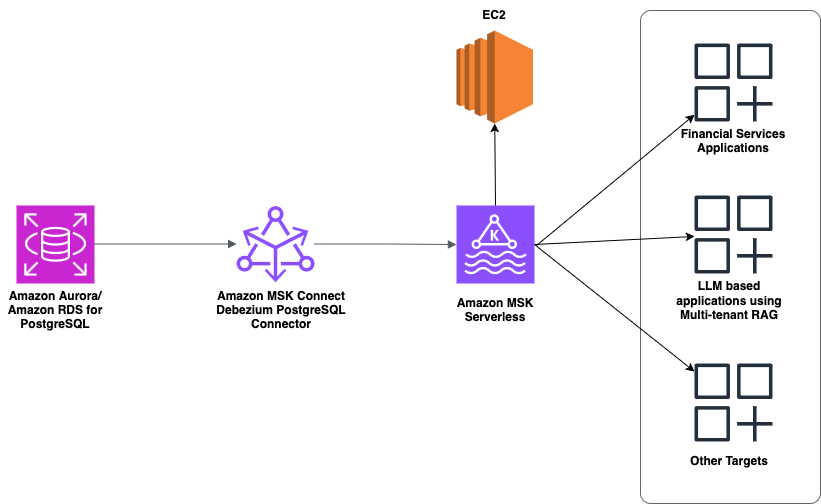
The key components of this solution architecture
The following are the key components of this solution architecture:
- Amazon Aurora for PostgreSQL as the source database with logical replication enabled
- A Debezium PostgreSQL connector running on MSK Connect for managed change capture
- Amazon MSK for reliable, scalable message streaming
- An Amazon Elastic Compute Cloud (Amazon EC2) instance for testing and consuming change events
Note: Additional downstream integration targets shown in the architecture diagram can be configured based on specific use case requirements but are not part of this core CDC implementation.
Implement the solution
You can implement this solution either from the AWS Management Console or by using the latest version of the AWS Command Line Interface (AWS CLI).
Create an Amazon Aurora for PostgreSQL DB cluster and turn on logical replication
Create an Aurora PostgreSQL DB cluster and complete the following steps to turn on logical replication:
- Create a DB cluster parameter group. Choose a Parameter group family consistent with the PostgreSQL major version of your database instance. We recommend using the latest version available for Aurora PostgreSQL.
- Modify the DB cluster parameter group to set the
rds.logical_replicationparameter to 1. - Associate the DB cluster parameter group with the Aurora PostgreSQL DB cluster, and stop and start the DB cluster for the parameter group to be in sync with the database.
Create an Amazon MSK cluster
Now that you have set up the database to support replication, create an Amazon MSK serverless cluster by following these instructions:
- Sign in to the AWS Management Console and navigate to the Amazon MSK console.
- Choose Create cluster.
- Choose Custom create. This option lets you choose a virtual private cloud (VPC), subnets, and security groups.
- For Cluster name, enter a descriptive name for your cluster.
- For Cluster type, select Serverless and choose Next
- On this Networking page of the cluster creation process, for VPC Configuration 1, select the VPC in which the database was created.
- For Subnets, select at least two subnets (up to four subnets) of the chosen VPC.
- For Security groups, use the same security group attached to the database and choose Next.
- Choose Next on the Security page of the cluster creation process.
- Choose Next on the Metrics and tags page.
- On the Review and create page of the cluster creation process, review your selections and then choose Create cluster.
- Check the cluster Status on the Cluster summary page. The status changes from Creating to Active as Amazon MSK provisions the cluster. Wait for the status to change to Active before proceeding to the next step.
Set up the EC2 Instance
Now, create and launch an Amazon EC2 instance to install Kafka, download dependencies, use IAM to authenticate with the Amazon MSK cluster, configure a Kafka client to use IAM authentication, and connect to the database. To connect to both the Amazon MSK cluster and the database, use the same VPC and assign the same security group as you did in the previous steps when creating the Amazon MSK cluster and Aurora PostgreSQL database.
Also, add another security group that gives you SSH access to the instance. For detailed instructions about creating and configuring security groups, see Amazon EC2 security groups for your EC2 instances and Allow inbound traffic from the Amazon Instance Connect service to your instance.
- To install Kafka on Amazon Linux or Red Hat Enterprise Linux, use following commands:
- To use AWS Identity and Access Management (IAM) to authenticate with the Amazon MSK cluster, follow the instructions in the Amazon MSK Developer Guide to configure clients for IAM access control. Download the latest stable release of the Amazon MSK Library for IAM:
- In the
~/kafka_2.13-4.0.0/config/directory, create aclient.propertiesfile to configure a Kafka client to use IAM authentication: - Source the environment variables. Add Kafka binaries to the
PATHand the Amazon MSK Library for IAM to theCLASSPATH, and update the Bash profile: - To install a psql client and all the related dependencies to connect to the Aurora PostgreSQL database, run the following command. This command installs PostgreSQL version 17 on your Amazon EC2 instance:
Create a custom plugin
Next, create a custom plugin so that Amazon MSK can install this plugin on MSK Connect workers where the connector is running to replicate the changes from RDS for PostgreSQL.
From the Debezium website, download the PostgreSQL connector plugin for the latest stable release. This plugin comes in .tar.gz format and must be converted to ZIP format because MSK Connect supports custom plugins in ZIP or JAR format only.
Use the following steps to download and zip the Debezium connector on the Amazon EC2 instance:
- Create a directory for Debezium plugins (if it doesn’t exist):
- Change the directory:
- Download the Debezium connector by using
wget. Make sure to use the link for the latest stable version. - Extract the downloaded file:
- (Optional) Clean up the tar file:
- Verify the installation:
- Zip the plugin files:
You then can use the AWS CLI to upload the custom plugin exported zip format to an Amazon Simple Storage Service (Amazon S3) bucket in the same AWS Region in which MSK Connect is being created:
- Upload this zip to your Amazon S3 bucket:
MSK Connect doesn’t include Debezium by default. Creating a custom plugin from the S3 path lets MSK Connect distribute the connector code across workers for CDC capabilities. Using the path of the preceding Amazon S3 object, create a custom plugin in MSK Connect.
Note: MSK Connect workers run in your VPC. If the connector’s subnets don’t have outbound internet access through a NAT gateway, create an interface VPC endpoint for Secrets Manager (com.amazonaws.us-east-1.secretsmanager) so the connector can retrieve credentials at runtime. Depending on your networking, you may also need endpoints for AWS STS and Amazon CloudWatch Logs, and a gateway endpoint for Amazon S3.
Next, store the credentials in AWS Secrets Manager in the same AWS Region as your Amazon MSK cluster and Amazon RDS database. Store the following credentials:
- IAM user credentials – IAM user with access key as
aws_access_key_idand access key secret asaws_secret_access_key. - Aurora PostgreSQL database credential – Database including hostname as
host, port asport, database name asdatabase, database username asusername, and database password aspasswordin AWS Secrets Manager. For instructions, see Managing the master user password for a DB instance with Secrets Manager.
Create an IAM role and policy
MSK Connect requires an IAM role with specific permissions to access AWS Secrets Manager (to retrieve database and IAM credentials) and interact with Amazon MSK clusters. Create the required IAM role and policy for MSK Connect, and attach the policy to the role.
- Create the IAM role:
- Create the MSKConnect policy. Update the information in the following code with values specific to your environment, such as your AWS account ID, Amazon S3 bucket name, AWS Region, Amazon MSK cluster name, secret ARNs, and Amazon CloudWatch Logs group (all highlighted in red in the following code).
This policy establishes the permissions needed to perform various operations through the previously created role, including:
- Permissions to connect, describe and create, read, and write topics to the Kafka cluster.
- Permissions to write logs to a CloudWatch log group.
- Permissions to access Secrets Manager.
- Permissions to access the Amazon S3 bucket
- Attach the policy to the role:
Connect to the database from the Amazon EC2 instance
Now that you have created the IAM role and policy and attached the policy to the role, connect to the Aurora PostgreSQL database from the Amazon EC2 instance to prepare it for replicating changes through publications.
Connect using the default PostgreSQL superuser postgres and the default database postgres and run the following commands to create a test table with data and prepare it for replication:
Create an Amazon MSK connector to stream database changes
The Amazon MSK connector enables Debezium to continuously capture change data from your PostgreSQL database and stream it in real time to Amazon MSK topics. This connector acts as the bridge between your database’s logical replication stream and Kafka, transforming database changes (inserts, updates, deletes) into Kafka events that downstream applications can consume. The final step before verifying the replication setup is to create an Amazon MSK connector:
- Open the Amazon MSK console.
- In the navigation pane, under MSK Connect, choose Connectors.
- Choose Create connector.
- On the Select plugin page, in the list of custom plugins, find and select the Debezium PostgreSQL connector plugin you created earlier, and then choose Next.
- On the Configure connector page, for Connector name, enter a descriptive name for your connector.
- (Optional) For Description, enter a description for the connector.
- For Cluster, choose the Amazon MSK cluster you created earlier.
- For Connector configuration, paste the following configuration, replacing the placeholder values with your environment-specific information:
Note: To get the bootstrap servers for your MSK cluster, see Get bootstrap brokers using the AWS Management Console.
- Choose Next.
- On the Connector capacity page, keep the default values and choose Next.
- On the Worker configuration page, for Apache Kafka Connect version, select 3.7.x.
- Before creating the connector, create a custom worker configuration (Amazon MSK console > Worker configurations > Create worker configuration) that registers the AWS Secrets Manager configuration provider:
- For Worker configuration, select Use a custom configuration, choose the worker configuration you just created, and choose Next.
- On the Access permissions page, for IAM role, select the MSKConnectRole02 IAM role you created earlier and choose Next.
- On the Security page, review the settings for authentication and encryption in transit (these are inherited from your Amazon MSK cluster) and choose Next.
- On the Logs page, select Deliver to Amazon CloudWatch Logs. By using CloudWatch Logs, you can manage retention and interactively search and analyze log data with CloudWatch Logs Insights.
- For Log group, enter the Amazon Resource Name (ARN) of the log group you specified in the IAM policy and choose Next. For more information about logging, see Logging for MSK Connect.
- On the Review and create page, review all your configurations and then choose Create connector.
MSK Connect connectors typically take about 10–15 minutes to create and become fully operational. Proceed to the next section after the connector has been created.
Test the solution
Now, test the architecture that you just set up. Connect to the Amazon EC2 instance you created and create the BOOTSTRAP_SERVERS environment variable to store the bootstrap servers of your Amazon MSK cluster.
To get the bootstrap servers for your MSK cluster:
- Open the Amazon MSK console.
- Choose your cluster name.
- Choose View client information.
- Copy the bootstrap server endpoints (either private or public, depending on your network configuration).
Then, on your EC2 instance, run
Now, run the following commands to test the connection and then verify if replication is successful
After running the preceding command, you should see the records replicating as shown in the following output:
Test real-time changes
Now that you have verified the initial data replication, test the real-time change data capture by inserting new records into the PostgreSQL database. These changes should automatically stream through Debezium to your Amazon MSK topics, demonstrating the live CDC functionality.
- Insert new records in PostgreSQL:
- Update existing records:
- Delete records:
- Observe real-time events in the Kafka consumer showing
INSERT,UPDATE, andDELETEoperations.
In the Kafka consumer terminal window, you see new change events appear in real time for each operation you performed. Each event is a JSON message that includes:
- Operation type:
"op": "c"forINSERT(create),"op": "u"forUPDATE, and"op": "d"forDELETE - Before and after values: For updates, you see both the old value (
"before": {"slno": 2}) and new value ("after": {"slno": 20}) - Table and schema information: The source table (
public.reptab1) and database details - Transaction metadata: Timestamps, transaction IDs, and LSN (Log Sequence Number) positions
For example, the INSERT operation shows a message with "op": "c" and "after": {"slno": 11}. The UPDATE shows both before and after values, and the DELETE shows "op": "d" with the deleted record in the "before" field. This confirms that Debezium captures all types of database changes and streams them to Amazon MSK in real time.
Monitoring and troubleshooting
Monitor and troubleshoot your CDC pipeline by using these key metrics:
MSK Connect metrics
Available through CloudWatch Logs:
- Worker-level logs for debugging connector issues and tracking task execution
Available through the MSK Connect console:
- Connector status (Creating, Running, Failed, Deleting)
- Connector configuration details
- Task status and count
Available through Amazon CloudWatch metrics:
- Connector-level metrics such as task count and status
- For additional Kafka Connect metrics (task failure rates, throughput, processing latency, and error counts), you need to configure custom metric reporting. For more information, see Monitoring Kafka Connect in the Apache Kafka documentation.
For more information about MSK Connect logging, see Logging for MSK Connect.
Amazon MSK cluster metrics
Monitor these CloudWatch metrics for your MSK cluster:
- BytesInPerSec – Rate of bytes received per second by brokers
- BytesOutPerSec – Rate of bytes sent per second by brokers
- MessagesInPerSec – Number of incoming messages per second
- MessagesOutPerSec – Number of outgoing messages per second
- CpuIdle – Percentage of CPU idle time
- MemoryUsed – Amount of memory in use by brokers
- KafkaDataLogsDiskUsed – Disk space used by Kafka data logs
- OfflinePartitionsCount – Number of partitions that are offline (should be 0 for healthy clusters)
For detailed information about these metrics, including units and recommended thresholds, see Monitoring Amazon MSK with Amazon CloudWatch.
Aurora PostgreSQL metrics
Monitor these CloudWatch metrics for your database:
- ReplicationSlotDiskUsage – Disk space used by replication slots to retain write-ahead logs (WAL)
- TransactionLogsDiskUsage – Disk space used by transaction logs
- DatabaseConnections – Number of database connections in use
- CPUUtilization – Percentage of CPU utilization
- FreeableMemory – Amount of available random access memory
- FreeStorageSpace – Amount of available storage space
For detailed information about these metrics, including units and recommended thresholds, see Monitoring Amazon RDS metrics with Amazon CloudWatch.
Common issues and solutions
Replication slot lag
Issue: The replication slot accumulates WAL files faster than Debezium can consume them, causing disk space issues.
Check replication slot status:
Connect to your PostgreSQL database and run:
Resolution steps:
- Restart the connector: In the MSK Connect console, select your connector and choose Restart to resume WAL consumption. For more information, see Managing connectors.
- Increase connector parallelism: In your connector configuration, increase the
tasks.maxparameter to allow more parallel processing. For example, change"tasks.max": "1"to"tasks.max": "2"or higher based on your workload. For more information about connector configuration, see Connector configuration in the Apache Kafka documentation. - Drop unused replication slots: If you have inactive replication slots from previous connectors, drop them to prevent unnecessary WAL retention. Connect to your PostgreSQL database and run:
Replace
slot_namewith the name of the unused slot. For more information about managing replication slots, see Replication Slots in the PostgreSQL documentation. - Monitor PostgreSQL parameters: Check your database parameter group settings for
max_wal_sizeandwal_keep_size(formerlywal_keep_segments) to ensure they’re configured appropriately for your workload. For more information, see Working with parameter groups.
Connector failures
Issue: The MSK Connect connector fails to start or stops unexpectedly.
Resolution steps:
- Check the CloudWatch Logs log group you specified during connector creation for detailed error messages. Common errors include authentication failures, network connectivity issues, or configuration problems. For more information about MSK Connect logging, see Logging for MSK Connect.
- Verify that the IAM role attached to your connector has the necessary permissions to access MSK, Secrets Manager, S3, and CloudWatch Logs. For more information, see IAM roles for MSK Connect.
Schema evolution
Issue: Database schema changes (adding columns, changing data types) cause connector failures or data inconsistencies.
Resolution steps:
- Configure AWS Glue Schema Registry for automatic schema management and evolution. The Schema Registry tracks schema versions and ensures compatibility between producers and consumers. For more information, see Integrating AWS Glue Schema Registry with MSK Connect.
- In your Debezium connector configuration, add schema registry settings:
Network connectivity
Issue: The MSK Connect connector cannot reach the RDS database or MSK cluster.
Resolution steps:
- Verify that the security groups attached to your MSK cluster, Aurora PostgreSQL database, and MSK Connect workers allow the necessary traffic:
- MSK Connect to database: Port 5432 (PostgreSQL)
- MSK Connect to MSK: Port 9098 (IAM authentication) or 9092 (plaintext)
- Ensure all resources are in the same VPC or have proper VPC peering/transit gateway configuration. For more information, see Security in Amazon MSK and Security in Amazon RDS.
- Test connectivity from an EC2 instance in the same subnets as your MSK Connect workers to verify network paths are open.
Clean up
To avoid incurring future charges, delete the resources you created in the following order:
- Delete the MSK Connect connector: Open the Amazon MSK console, under MSK Connect choose Connectors, select your connector, choose Delete, enter delete, and wait 5–10 minutes for completion.
- Delete the custom plugin: Under MSK Connect, choose Custom plugins, select your plugin, and choose Delete.
- Delete the Amazon MSK cluster: Choose Clusters, select your cluster, choose Delete, enter delete, and wait 10–15 minutes.
- Delete the Aurora PostgreSQL database instance: Open the RDS console, choose Databases, select your cluster, choose Actions > Delete, clear Create final snapshot and retain automated backups, and enter delete me.
- Terminate the EC2 instance: Open the EC2 console, choose Instances, select your instance, choose Instance state > Terminate instance, and confirm.
- Delete the IAM role and policy: Open the IAM console, delete the role MSKConnectRole02 from Roles, then delete the policy MSKConnectPolicy02 from Policies.
- Delete Secrets Manager secrets: Open the Secrets Manager console, delete both secrets (aws-access and postgres-config) by choosing Actions > Delete secret with a 7-day waiting period.
- Delete the CloudWatch Logs log group: Open the CloudWatch console, choose Log groups, select your log group, and choose Actions > Delete log group(s).
- Delete the S3 bucket: Open the S3 console, select your bucket, choose Empty (enter permanently delete), then choose Delete bucket (enter the bucket name).
Important: Deletion is permanent and cannot be undone. Back up any data you want to retain before proceeding.
Conclusion
In this post, we demonstrated how to implement CDC by using Debezium with Amazon Aurora for PostgreSQL. This solution offers robust capabilities for real-time data streaming and event-driven architectures through logical replication and Debezium connectors. By understanding the setup process and components involved in this solution, you can better configure your CDC pipeline for your specific needs. Try implementing this CDC solution in your environment and share your feedback and questions in the comments section below.