AWS Database Blog
Introducing Amazon Aurora MySQL enhanced binary log (binlog)
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud. Aurora combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open-source databases. Aurora has a history of innovating around database engines and the underlying infrastructure running the database, while maintaining compatibility. A commonly used feature of the MySQL database engine is the binary log (binlog). The binlog is a record of the changes made to the database and is used for a variety of workloads such as disaster recovery using read replicas, change data capture for data streaming, event driven architectures, and analytics.
On May 22, 2023, AWS announced the availability of a new enhanced binlog on Aurora MySQL 3 (compatible with MySQL 8). The enhanced binlog reduces the compute overhead of enabling binlog, which in certain cases can reach up to 50%, down to 13%. This in turn allows additional throughput on the same hardware. The enhanced binlog also improves database recovery time when binlog is enabled by up to 99% compared to recovery when community binlog is enabled. In this post we dive deep into the Aurora MySQL enhanced binlog, the common challenges it addresses and the innovation that went into making it possible.
Challenges with binlog
MySQL binlog is versatile and used widely; however, there is a performance penalty that many customers observe when they enable binlog. This performance penalty is caused by compute resource contention as the database has to do extra work to process binlog in addition to transactions, when binlog is enabled. Binlog has to maintain the commit order of the changes made to the database. This is achieved through an additional process in the commit workflow for a transaction that writes binlog files serially with each transaction. A 2-phase commit (2PC) is employed at commit time to synchronize writing the transaction log and binlog which introduces additional latency to writes. These challenges are inherited by Aurora MySQL as well. The separation of compute and storage in Aurora was a groundbreaking innovation that solves one of the main challenges with databases – throughput. However, this architecture may sometimes amplify the performance impact for writing the binlog due to increased coordination work and network hops required when writing binlog files. Additionally, when binlog is enabled, Aurora may experience additional recovery time in the event of a restart or failover, as the binlog has to be read back and recovered by rolling back or rolling forward transactions. It is important to note that binlog is not required by the Aurora MySQL architecture for either database recovery or Aurora’s in-region and Global Database replication. Binlog is an optional feature you can enable for a variety of use cases.
Aurora MySQL enhanced binlog
To overcome some of the performance challenges, we first introduced the binlog I/O cache in 2021. The binlog I/O cache minimized read I/O from the Aurora storage engine by keeping the most recent binlog events in its circular cache. The binlog I/O cache for Aurora MySQL showed more than 5 times throughput improvement in a binlog-replicated setup.
Now, with Aurora MySQL 3.03 version and higher, we introduced an additional, more fundamental change to how binlog is written and stored. This enhanced binlog reduces the performance overhead of enabling binlog which in certain cases can reach up to 50%, down to 13%. This in turn allows additional transaction processing throughput on the same hardware.
The first innovation comes from separating storage of the transaction log from storage of the binlog. Instead of using the same storage node for storing both the transaction and binlog, Aurora MySQL now stores the binlog on specialized storage nodes optimized for binlog. These storage nodes have added logic which make it possible for the database engine to push down the sorting and ordering of binlog to the storage layer. This allows us to increase parallelization, reduce locking, and shorten the 2-phase commit time in the database engine when the transaction log and binlog are written, while still achieving ordered writes. These architectural improvements dramatically improve the performance of binlog writes of Aurora MySQL. The following image shows a comparison of how the transaction log and binlog events are written between community binlog (top) and the new enhanced binlog (bottom).
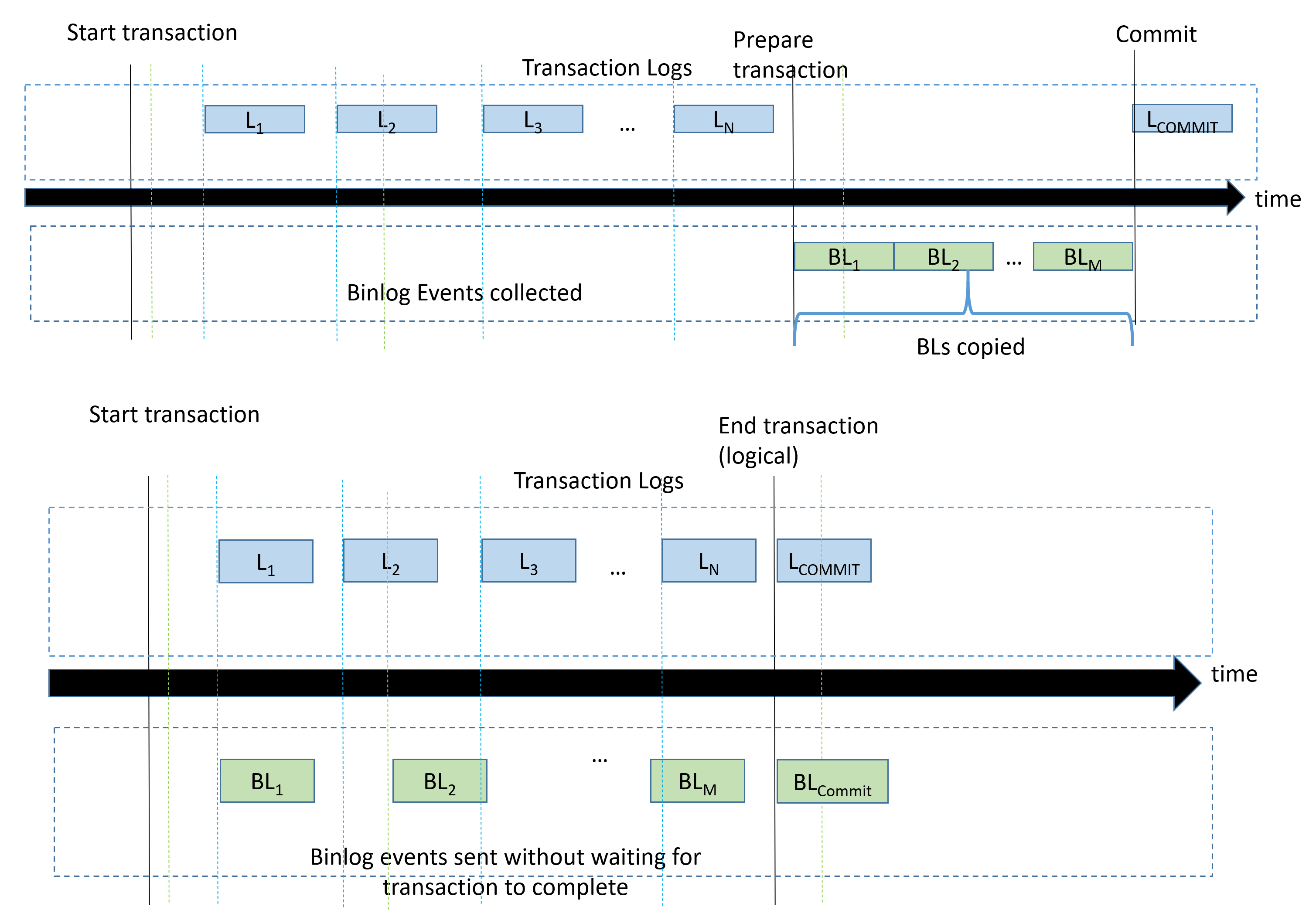
Figure 1: Community Binlog (top) and enhanced binlog (bottom) commit phases.
These changes also help improve database failover and general recovery performance when binlog is enabled. With its distributed storage layer, Aurora MySQL is able to recover in parallel and out-of-order. However, when binlog is enabled, in addition to the database recovery, the binlog has to be recovered to make sure it is in a consistent state. During crash recovery, when community binlog is enabled, Aurora MySQL has to read the binlog file sequentially to confirm if transactions should be rolled forward or back. This added overhead can impact total Aurora database recovery time, especially if a large transaction has to be rolled back. The enhanced binlog adds logic in the storage layer which makes it unnecessary for the binlog file to be scanned sequentially. Instead, transactions are recovered in a more selective manner while maintaining consistency. This reduces binlog recovery time by up to 99%. Database recovery times improve from up to several minutes down to several seconds as a result.
Enabling enhanced binlog
To turn on enhanced binlog, set the value of the aurora_enhanced_binlog cluster parameter to 1 and the binlog_backup and binlog_replication_globaldb cluster parameters to 0. These are static parameters, so you must reboot the writer instance for the changes to take effect. You can switch between community binlog and enhanced binlog, and Aurora MySQL will track the storage location of each binlog file to provide a continuous sequence. If you decide to turn the feature off, you can do so by changing the value of these three cluster parameters and restarting the writer instance. The following code block shows an example of enabling enhanced binlog via the AWS Command Line Interface (AWS CLI).
Enhanced binlog performance comparison
Improved performance is the key benefit of using the enhanced binlog. The enhanced binlog reduces the performance impact of enabling binlog so you can process more transactions per second. We benchmarked the average throughput achieved across 10 test iterations for db.r6g.8xlarge and db.r6g.16xlarge instance classes using sysbench. The tests were repeated with thread counts ranging from 25 to 4000. The data show that in large instances with high transaction throughput requirements where performance really matters, the enhanced binlog improves the transaction throughput by reducing compute contention on the writer instance. The following charts show a comparison between using community binlog and enhanced binlog and the performance improvement in transaction processing when using enhanced binlog.

Figure 2: Transactions per second (TPS) scaling results on db.r6g.8xlarge

Figure 3: Transactions per second (TPS) scaling results on db.r6g.16xlarge
The following table contains the same data as shown in the charts above and also includes percent improvement.
| Instance Type | Threads | community binlog | enhanced binlog | . |
| . | . | Transactions per second (TPS) | Transactions per second (TPS) | % Improvement |
| db.r6g.8xlarge | 25 | 2596.3 | 3063.19 | 17.98 |
| . | 100 | 6348.08 | 7776.38 | 22.49 |
| . | 1000 | 17581.01 | 20340.36 | 15.69 |
| . | 4000 | 17448.86 | 25086.51 | 43.77 |
| db.r6g.16xlarge | 25 | 2877.19 | 3026.14 | 5.17 |
| . | 100 | 7762.9 | 8841.46 | 13.89 |
| . | 1000 | 17557.1 | 22729.99 | 29.46 |
| . | 4000 | 27189.1 | 35352.81 | 30.02 |
The second area of improved performance is database recovery. We compared the difference in database recovery results between community binlog enabled and enhanced binlog enabled. You can see the recovery time differences across a range of workloads visualized in the following graph (Figure 4). As the binlog transaction size grows, the community binlog takes longer to recover whereas enhanced binlog recovery times stay consistent under a second.

Figure 4: binlog recovery time improvement
The second chart (Figure 5), shows the overall database recovery improvement which is between 92% to 99%.

Figure 5: Overall database recovery time improvement
The following table contains the same data as shown in the charts above and also includes percent improvement.
| Transaction size | Binlog recovery time (Seconds) | Total Engine recovery time (Seconds) | ||||
| Community binlog | Enhanced binlog | Percent Improvement | Community binlog | Enhanced binlog | Percent Improvement | |
| 1GB | 303.42 | 0.47 | 99.85% | 332 | 26 | 92.17% |
| 5GB | 1296.39 | 0.50 | 99.96% | 1318 | 34 | 97.42% |
| 50GB | 15879.49 | 0.61 | 100% | 15904 | 21 | 99.87% |
Limitations
For many use cases, enabling the enhanced binlog can improve the performance of your database. However, there are some limitations to keep in mind. When Amazon Aurora Global Database is used with enhanced binlog, your binlog files are not replicated to your cross-region replica so they are not available after failover. After a cross-region failover, if enhanced binlog is enabled the newly promoted cluster will start to write binlog files starting from a new file sequence. A similar limitation exists after restoring a cluster from a snapshot or cloning a database. Enabling enhanced binlog will result in a change of behavior compared with community binlog. With enhanced binlog, a newly restored database cluster or clone will not have the original binlog files available despite any retention period set on the original cluster. By contrast, the community binlog will preserve and make available the binlog files on the newly restored or cloned cluster. Last, enhanced binlog cannot be used with clusters that have ever used or have been restored from a cluster that used Backtrack. For additional information, please refer to the enhanced binlog documentation.
Cost
There is no additional cost to use the enhanced binlog compared to binlog. You continue to pay for writes, reads, and storage of binlog using a portion of your Aurora cluster’s Compute, Storage, and IO costs. Because the enhanced binlog files are stored on separate storage nodes rather than the database’s transaction log, the enhanced binlog files are not included in your backup files. This may lead to a reduction in the cost of your backup storage. You still pay for the total data storage used by your cluster inclusive of binlog and data files.
Conclusion
In this post, we discussed the new enhanced binlog now available on Aurora MySQL 3.03 version and later. The benefits of the enhanced binlog are improved throughput due to reduced compute contention and improved database recovery times with binlog enabled. You can start using the Aurora MySQL enhanced binlog today by visiting the database console and spinning up an Aurora instance. For more information, consult the documentation.
About the Authors
 Aditya Samant is a relational database industry veteran with over 2 decades of experience working with commercial and open-source databases. Over the years, he has held many roles, including database consultant, professional support, DBA and database architect. He currently works at Amazon Web Services as a Sr. Database Specialist Solutions Architect. In his current role, he spends his time working with customer designing scalable, secure and robust cloud native architectures. Aditya also helps service teams with design and delivery of the groundbreaking features for Amazon’s flagship relational database, Amazon Aurora.
Aditya Samant is a relational database industry veteran with over 2 decades of experience working with commercial and open-source databases. Over the years, he has held many roles, including database consultant, professional support, DBA and database architect. He currently works at Amazon Web Services as a Sr. Database Specialist Solutions Architect. In his current role, he spends his time working with customer designing scalable, secure and robust cloud native architectures. Aditya also helps service teams with design and delivery of the groundbreaking features for Amazon’s flagship relational database, Amazon Aurora.
 Adam Levin is a Product Manager on the Amazon Aurora team based in California. He has spent the last 10 years working on various cloud database services.
Adam Levin is a Product Manager on the Amazon Aurora team based in California. He has spent the last 10 years working on various cloud database services.