AWS Database Blog
Speed up database migration by using AWS DMS with parallel load and filter options
Some migrations might take a long time because they have large tables. However, AWS Database Migration Service (AWS DMS) features such as parallel load and filters might be able to help speed up this process.
AWS DMS is a data migration service that has robust features for supporting both homogenous and heterogeneous database migrations. AWS DMS provides parallel load and filter options to load data optimally. It also helps reduce data loading time.
In this post, we demonstrate how you can speed up database migrations by using AWS DMS parallel load and filter options to make data loading more efficient for selected relational tables, views, and collections.
Parallel full load
Parallel load can improve database migration by splitting a single, full load task into multiple threads in parallel. To use parallel load, you can segment your table, view, or collection by defining a table mapping rule of type table-settings with parallel-load and set the type parameter of parallel-load with one of the following settings:
- Load all existing table or view partitions using partitions-auto, or load only selected partitions using the partitions-list type with a specified partitions array
- Load all existing table or view subpartitions using the subpartitions-auto type (Oracle endpoints only)
- Load table, view, or collection segments that you define by using column-value boundaries by specifying the ranges type with specified columns
However, it’s important to know where to use partitions-auto instead of partitions-list, where ranges is a good choice, and possible combinations of these settings.
partitions-auto
When we use the parallel-load option with type partitions-auto, every table, view, or collection partition (or segment) or subpartition is automatically allocated to its own thread. Let’s see how we can optimize data loading by using partitions-auto.
For example, we have the table SALES_HIST in Oracle with 258 million rows and have five partitions defined on the column sales_year:
We used the following configuration without parallel-load in our task settings and measured the performance of data load time:
The following screenshot shows that our task took around 9 minutes.

We then modified table-settings in the tasks with parallel-load with type partition-auto. The following code is our updated task settings JSON:
The new task took 6 minutes to migrate the same number of rows, as we can see in the following screenshot.

Let’s take a closer look into Amazon CloudWatch Logs and how AWS DMS treated this task. Upon checking the logs, we can see AWS DMS created five threads, because the SALES_HIST table has five partitions and loaded the data in parallel.

AWS recommends that you don’t load a large number of large collections using a single task with parallel-load. AWS DMS limits resource contention as well as the number of segments loaded in parallel by the value of the MaxFullLoadSubTasks task settings parameter, which has a maximum value of 49.
For more information about CloudWatch logging, refer to Logging task settings.
partitions-list
To overcome this issue with parallel-load, AWS DMS provides another option to load partitions in parallel: partitions-list.
With partitions-list, only specified partitions of the table or view are loaded in parallel, unlike with partition-auto, where all partitions are loaded in parallel. Again, each partition you specify is allocated to its own thread.
Let’s see how we can use partitions-list and optimize data loading by applying partitions-list for our SALES_HIST table.
The following query shows how the rows are allocated to each partition in our SALES_HIST table:

In this test, we created three different tasks and distributed all partitions of the SALES_HIST table to each task. So, the task saleshist-partition-list-2018-2019 loaded two partitions (2018 and 2019), the task saleshist-partition-list-2020-2021 loaded two partitions (2020 and 2021) and the task saleshist-partition-list-2022 loaded partition 2022.
We used the following task settings for each task:
The following screenshot shows the output of each task.

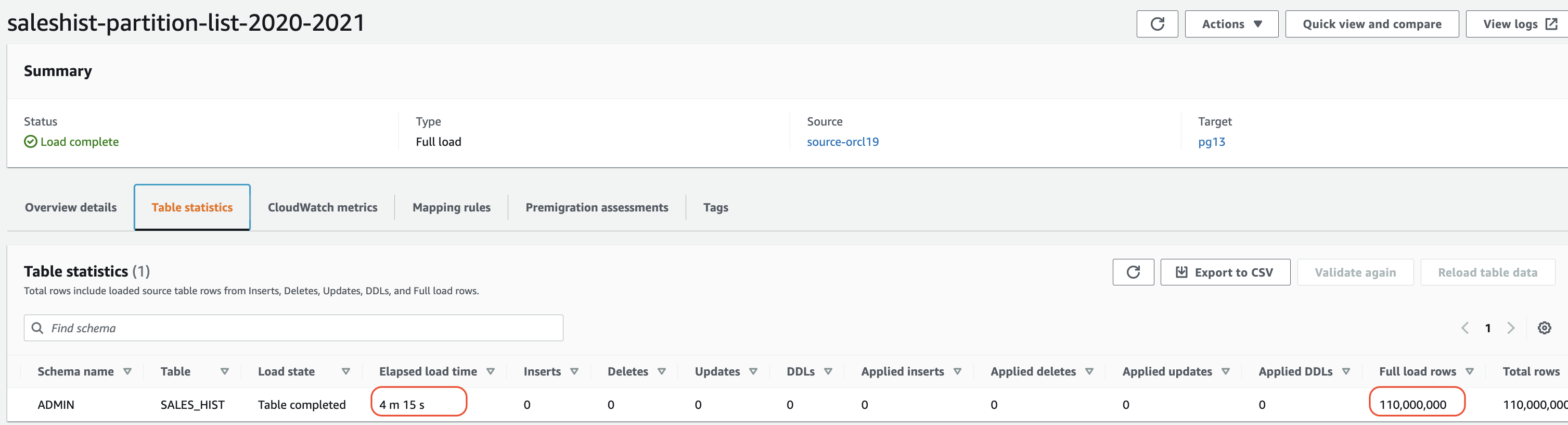

The maximum time is about 4 minutes for second task, which means we loaded all five partitions in just 4 minutes by creating three tasks using partition-list.
You could consider partition-list for the following use cases:
- You have a large number of partitions for a single table
- You don’t want to move all partitions
ranges
Let’s suppose you have huge tables without partitioning. How can you load data efficiently by using parallel-load?
The ranges type defines the data ranges for all the table or view segments by specifying a boundary array as the value of boundaries. Each table, view, or collection segment that you identify is allocated to its own thread. You specify these segments by column names (columns) and column values (boundaries).
We loaded our SALES_HIST table using ranges with parallel-load. To do so, we first need to know which column is a good choice to create boundaries. It’s always a good idea to use unique and indexed columns. In this case, we have the column product_id, which is unique and indexed in the SALES_HIST table.
First let’s find the min and max values for this column:

We created 10 boundaries using PRODUCT_ID by specifying type ranges in our task:
The following screenshot shows that AWS DMS loaded the table within 5 minutes, and reduced our load time by almost 50% as compared to without parallel-load.

Let’s take a closer look how AWS DMS uses ranges to load data. In this case, AWS DMS created 10 segments, one for each boundary, and loaded rows in parallel using the following WHERE clause:
- segment1 load rows with
PRODUCT_ID <=100000 - segment2 load rows with
PRODUCT_ID <=200000 and rows other than segment1 - segment3 load rows with
PRODUCT_ID <=300000 and rows other than segment1 and segment2, and so on
The CloudWatch logs shows that we have 10 threads (one thread allocated to each boundary).

The AWS DMS ranges option allows you to load data parallelly for huge tables even without partitioning.
You should consider the following when using ranges:
- If possible, use a primary key or unique index column to avoid duplication
- Avoid uneven distribution of records; if possible, use range columns that distribute records evenly between ranges
- You can specify up to 10 columns
- You can’t use columns to define segment boundaries with the following AWS DMS data types: DOUBLE, FLOAT, BLOB, CLOB, and NCLOB
- Specifying indexed columns can improve performance
- You can create multiple tasks using ranges for better performance
Row filters
Sometimes, even after using all the options of parallel-load, we don’t get optimal data loading performance. What should we do in that case?
AWS DMS provides the filters option to limit the rows and break large tables into multiple chunks by creating a WHERE clause. These tasks work independently and can run concurrently. For example, our table SALES_HIST has more than 150 million rows, and we want to split this table into multiple tasks for better performance. First, we need to find an efficient filter that we can use to break up the table. It’s always good idea to break up a table by the same number of rows.
Let’s choose the column SALES_YEAR to create filter rows.
We break the table into three tasks using a filter operator on each partition using the column SALES_YEAR, and use the following task settings for each task:
Consider the following while using filters:
- The filter column always should have an index.
- Try to break the table into an equal number of rows as much possible.
- Apply filters only to immutable columns, which aren’t updated after creation.
- Monitor your replication instance using CloudWatch logs, and don’t overburden the replication instance and source server. The replication instance has a quota of maximum 100 tasks.
Conclusion
In this post, we shared some of the best practices to improve AWS DMS full load performance and reduce data loading times using parallel load and filter options. If you have any feedback or questions, leave them in the comments.
About the Author
 Ashar Abbas is a database specialty Architect at Amazon Web Services. He accelerates customer the database migration to AWS. He specializes in databases and comes with 20+ years of experience.
Ashar Abbas is a database specialty Architect at Amazon Web Services. He accelerates customer the database migration to AWS. He specializes in databases and comes with 20+ years of experience.