AWS Database Blog
Using Amazon Redshift for Fast Analytical Reports
With digital data growing at an incomprehensible rate, enterprises are finding it difficult to ingest, store, and analyze the data quickly while keeping costs low. Traditional data warehouse systems need constant upgrades in terms of compute and storage to meet these challenges.
In this post, we provide insights into how AWS Premier Partner Wipro helped their customer (a leading US business services company) move their workload from on-premise data warehouse to Amazon Redshift. This move enabled the company to reap the benefits of scalability and performance without affecting how their end users consume reports.
Current data warehouse environment and challenges faced
The customer was running commercial enterprise data warehouse that contained aggregated data from different internal reporting systems across geographies. Their primary goal was to provide quick and accurate analytics to drive faster business decisions. The user base was distributed globally. Meeting this goal was difficult due to the following challenges:
- The data warehouse (5 TB) was growing at over 20 percent year over year (YoY), with higher growth expected in the future. This growth required them to keep upgrading the hardware to meet the storage and compute needs, which was expensive.
- The Analytical Dashboard experienced performance issues because of the growing data and user base.
- Licensing was based on CPU cores, so adding hardware to support the growth also required additional investment in licenses, further spiraling the costs.
Migrating to Amazon Redshift
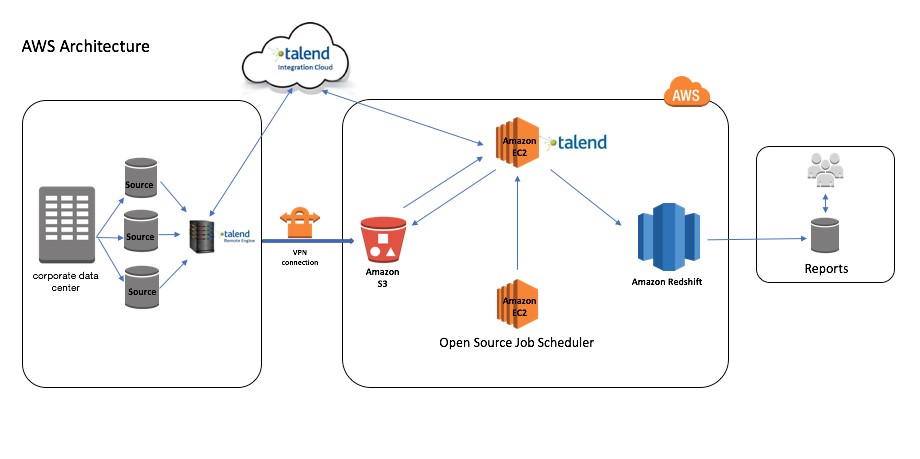
Wipro used their Cloud Data Warehouse Readiness Solution (CDRS) strategy to migrate data to Amazon Redshift. Using CDRS, they migrated 4.x billion records to Amazon Redshift. CDRS has a Source Analyzer that created the target data model and generated the data definition language (DDL) for tables that needed to be migrated to Amazon Redshift. The architecture included Talend (a data integration platform) running on Amazon EC2 to extract data from various source systems for ongoing change data capture (CDC) and then load it to Amazon Redshift. Talend has several built-in connectors to connect to various sources and extract the data.
The following diagram shows the architecture of this migration setup:
AWS also offers other technologies, like AWS Database Migration Service (AWS DMS) and AWS Schema Conversion Tool (AWS SCT), to migrate your data to and from most widely used commercial and open-source databases and data warehouses. Customers use AWS SCT to convert and migrate their schema objects (table definitions, indexes, triggers, and other execution logic) from legacy data warehouse platforms. They use the AWS SCT data extraction agents to migrate Oracle, Microsoft SQL Server, Teradata, IBM Netezza, Greenplum, and Vertica to Amazon Redshift. For more information, see the following posts:
- How to Migrate Your Oracle Data Warehouse to Amazon Redshift Using AWS SCT and AWS DMS
- How to Migrate Your Data Warehouse to Amazon Redshift Using the AWS Schema Conversion Tool Data Extractors
The AWS data warehouse consisted of three node Amazon Redshift clusters using dc1.8xlarge instances. After migration, queries showed a 2.5x performance improvement compared to an on-premises environment. They also realized a 5x performance improvement while loading data to big tables. The following table lists the data load time for big or complex tables for the two environments.
| Table | Load time (sec) | End-to-end time (sec) | |||||
| On-premises | Amazon Redshift | Improvement | On-premises | Amazon Redshift | Improvement | ||
| Table 1 | 617 | 129 | 5x | 732 | 320 | 2x | |
| Table 2 | 1766 | 184 | 9x | 1767 | 305 | 6x | |
| Table 3 | 308 | 63 | 5x | 309 | 130 | 2x | |
| Table 4 | 154 | 102 | 1.5x | 2115 | 2126 | 0x | |
Setting up an analytical reporting data warehouse on Amazon Redshift
The on-premises data warehouse environment was an extension of the transactional system. Analytical queries experienced performance issues when they were executed against large datasets because queries scanned wide row-based blocks of data that were ultimately discarded in the end SQL results. Customers reporting queries on an average took 152 seconds for execution, and it impacted the interactive experience for their dashboards. With data growing by 20 percent YoY, the query performance further degraded. The customer realized a need for a dedicated analytical environment to address the performance and scale issues for user reports.
Amazon Redshift was identified as the ideal solution for setting up this new analytical reporting environment. The following are the key guidelines and best practices that were followed while migrating to Amazon Redshift:
- Tables were encoded using the
COPYcommandAUTOfeature to reduce the I/O spend by analytical queries. - The analytical queries used date ranges to query the large FACT tables (which took 40 percent of the total database size). The FACT tables were set up using the
dataset_datecolumn as theSORTThis allows the pruning of blocks when the SQL scans the data, and further optimizing the I/O. - The dimension tables were set up with
DIST ALLto avoid theDS_BCAST_INNERandDS_DIST_BOTHdata broadcast in the SQL joins. - Amazon Redshift
ANALYZEwas executed as the pre-ultimate step in the ETL (extract, transform, and load) data loading so that reporting end-user queries benefited by an optimal execution plan. - On an average, 20 percent of the data changed weekly.
VACUUMwas scheduled as a weekly job to re-sort the time series FACT tables and claim the deleted blocks to avoid theDELETED BLOCK SCAN. STL_EVENTSandSTL_SCANtables were used to identify and prioritize tables that neededVACUUM.
The following table shows the performance impact between the two environments. On an average, there was a 8x improvement in query execution time with six queries running in parallel.
| Report names | On-premises (sec) | AWS prod (sec) | Improvement |
| Report 1 | 481 | 176 | 3x |
| Report 2 | 310 | 59 | 5x |
| Report 3 | 208 | 7 | 29x |
| Report 4 | 763 | 210 | 3x |
| Report 5 | 630 | 193 | 3x |
| Report 6 | 748 | 207 | 4x |
Cost benefits
By migrating to Amazon Redshift, the customer saw an 83 percent reduction in their operational expenses over a period of three years. Their current license, hardware, and software costs attributed to approximately $750K per year. But using the three-year Reserved Instances (RI) feature, they were able to bring down the operating cost to $133K per year. For information about this data warehousing environment, see the AWS Simple Monthly Calculator.
Conclusion
Using Amazon Redshift, the customer saw immediate performance improvements at significantly lower costs. Data users were able to query and obtain reports quickly using column-level compression and massively parallel processing (MPP) features of Amazon Redshift. This migration also enabled the customer to be more agile with their data warehouse infrastructure—relieving them of the burden of planning additional licensing costs and effort for software and hardware upgrades. Finally, using the broad partner ecosystem in AWS, customers can accelerate their cloud journey and solve many business-critical challenges.
About the Authors
 Vivek Raju is a partner solutions architect at Amazon Web Services. He works with our partners to provide guidance and technical assistance on migration projects, helping them improving the value of their solutions when using AWS. In his spare time, loves to cook and play volleyball.
Vivek Raju is a partner solutions architect at Amazon Web Services. He works with our partners to provide guidance and technical assistance on migration projects, helping them improving the value of their solutions when using AWS. In his spare time, loves to cook and play volleyball.
 Thiyagarajan Arumugam is a Big Data Solutions Architect at Amazon Web Services and designs customer architectures to process data at scale. Prior to AWS, he built data warehouse solutions Amazon.com. In his free time, he enjoys all outdoor sports and practices the Indian classical drum mridangam.
Thiyagarajan Arumugam is a Big Data Solutions Architect at Amazon Web Services and designs customer architectures to process data at scale. Prior to AWS, he built data warehouse solutions Amazon.com. In his free time, he enjoys all outdoor sports and practices the Indian classical drum mridangam.