AWS Developer Tools Blog

Referencing the AWS SDK for .NET Standard 2.0 from Unity, Xamarin, or UWP
In March 2019, AWS announced support for .NET Standard 2.0 in SDK for .NET. They also announced plans to remove the Portable Class Library (PCL) assemblies from NuGet packages in favor of the .NET Standard 2.0 binaries. If you’re starting a new project targeting a platform supported by .NET Standard 2.0, especially recent versions of Unity, Xamarin and […]

Getting started with the AWS Cloud Development Kit and Python
This post introduces you to the new Python bindings for the AWS Cloud Development Kit (AWS CDK). What’s the AWS CDK, you might ask? Good question! You are probably familiar with the concept of infrastructure as code (IaC). When you think of IaC, you might think of things like AWS CloudFormation. AWS CloudFormation allows you […]
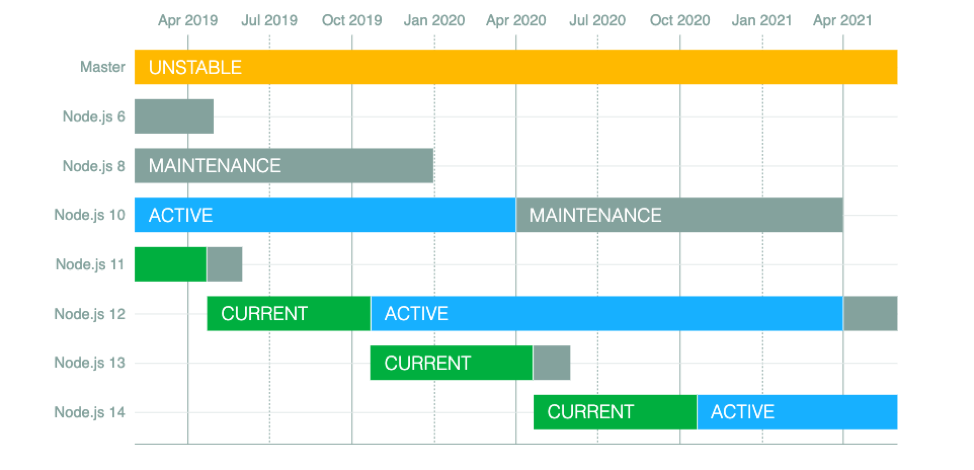
Node.js 6 is approaching End-of-Life – upgrade your AWS Lambda functions to the Node.js 10 LTS
This blog was authored by Liz Parody, Developer Relations Manager at NodeSource. Node.js 6.x (“Boron”), which has been maintained as a long-term stable (LTS) release line since fall of 2016, is reaching its scheduled end-of-life (EOL) on April 30, 2019. After the maintenance period ends, Node.js 6 will no longer be included in Node.js […]
V2 AWS SDK for Go adds Context to API operations
As of January 19th, 2021, the AWS SDK for Go, version 2 (v2) is generally available. The v2 AWS SDK for Go developer preview made a breaking change in the release of v0.8.0. The v0.8.0 release added a new parameter, context.Context, to the SDK’s Send and Paginate Next methods. Context was added as a required […]

New — Analyze and debug distributed applications interactively using AWS X-Ray Analytics
Developers spend a lot of time searching through application logs, service logs, metrics, and traces to understand performance bottlenecks and to pinpoint their root causes. Correlating this information to identify its impact on end users comes with its own challenges of mining the data and performing analysis. This adds to the triaging time when using […]
Query Systems Manager Parameter Store for AWS Regions, endpoints and more using PowerShell
In Jeff Barr’s recent blog post, he announced support for querying AWS Region and service availability programmatically by using AWS Systems Manager Parameter Store. The examples in the blog post all used the AWS CLI, but the post noted that you can also use the AWS Tools for PowerShell. In this post I’ll show you […]

Deep dive into AWS X-Ray groups and use cases
AWS X-Ray helps developers analyze and debug distributed applications, such as those built using a microservices architecture. With X-Ray, you can understand how your application and its underlying services are performing to identify and troubleshoot the root cause of performance issues and errors. X-Ray not only enables developers and DevOps engineers to get to the […]
PowerShell Standard support in AWSPowerShell.NetCore
In 2016, we released AWS Tools for PowerShell Core targeting PowerShell Core 6.0, which provided cross-platform support for macOS and Linux, in addition to Windows. We published this module separately from AWS Tools for Windows PowerShell because it was not compatible with earlier versions of PowerShell. Last year, Microsoft released PowerShell Standard: a new library […]
Generate an Amazon S3 presigned URL with SSE using the AWS SDK for C++
Amazon Simple Storage Service (Amazon S3) presigned URLs give you or your customers an option to access an Amazon S3 object identified in the URL, without having AWS credentials and permissions. With server-side encryption (SSE) specified, Amazon S3 will encrypt the data when the object is written to disks, and decrypt the data when the […]

AWS Toolkit for Visual Studio now supports Visual Studio 2019
A new release of the AWS Toolkit for Visual Studio has been published to Visual Studio marketplace. This new release adds support for Visual Studio 2019. Visual Studio 2019 is currently in preview, however, Microsoft has announced the general availability (GA) release date to be April 2, 2019. The AWS Toolkit for Visual Studio provides […]