AWS HPC Blog
Running NVIDIA Cosmos world foundation models on AWS
If you’re developing physical AI systems for autonomous vehicles, robotics, or smart factories, you likely face a critical challenge: generating enough high-quality training data. This blog shows you how to deploy NVIDIA CosmosTM world foundation models (WFMs) on Amazon Web Services (AWS) to generate high quality synthetic data at scale, with two production-ready architectures optimized for different use cases.
Physical AI enables systems to perceive, sense, reason, and act autonomously in complex and dynamic environments. Pre-training and post-training these models however, requires enormous volumes of high-quality demonstration examples. Existing examples from video and new examples from human-generated demonstrations are too limited and too costly to provide enough data. Synthetic data generation is key to overcoming this data gap challenge and advancing physical AI to enable sophisticated new behaviors that can transform business across industries.
Cosmos open WFMs fill the gap and enable development of physical AI for autonomous vehicles, humanoid robots, smart factories, and video analytics AI agents through scenario synthesis, domain randomization, and spatial reasoning. Getting the most from the Cosmos models requires scalable, cost effective, managed infrastructure that is carefully architected and configured.
This blog presents system architecture and implementation best practices for deploying Cosmos WFMs on AWS infrastructure, delivering enterprise-grade scalability, security, performance, and cost-effectiveness, with easy management and repeatable deployment.
Physical AI data pipeline challenges
Large language models (LLMs) benefit from virtually unlimited training data, including decades of digitized text, books, websites, videos, and conversations readily available across the internet. This vast corpus enables models to learn linguistic patterns, reasoning, and knowledge representation at scale. However, physical AI systems face a fundamentally different challenge: the “data scarcity problem”.
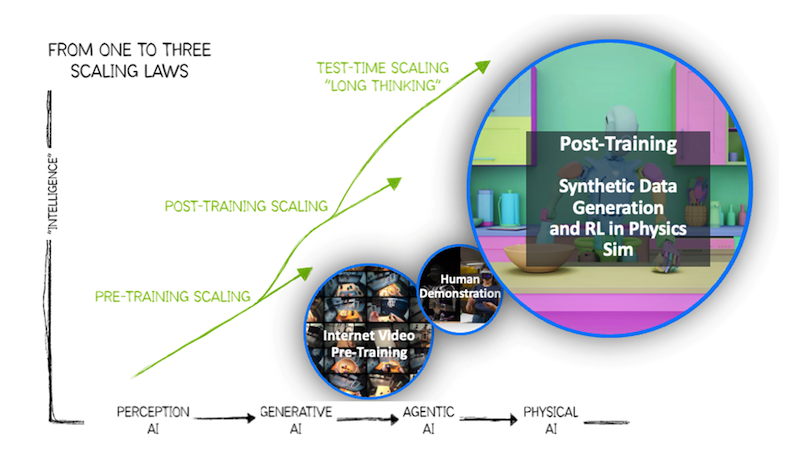
Figure 1: Evolution of Synthetic Data Generation for Physical AI
Unlike internet text, physical interaction data is scarce. Utilizing current technologies like behavior cloning imitation learning to manipulate objects, navigate environments, or perform dexterous tasks requires real-world sensor data—such as camera feeds, force measurements, and proprioceptive feedback—captured during actual physical interactions. Collecting this data is expensive, time-consuming, and often dangerous.
This is where synthetic data generation becomes essential. Cosmos WFMs can synthesize physically plausible scenarios with realistic variations in lighting, object textures, camera angles, and motion trajectories. This accelerates development cycles, improves model robustness, and makes physical AI economically viable.
Cosmos WFMs overview
Cosmos is a platform designed to advance physical AI leveraging WFMs. At its core are Cosmos open WFMs, pretrained multimodal models that developers can use to generate world states as videos and physical AI reasoning, or post-train to develop specialized physical AI models. The Cosmos platform comprises three models:
Cosmos Predict
An open world generation foundation model that generates physically and temporally accurate future states in the form of videos from initial conditions such as images, depth maps and sensor data, and text prompts.
Cosmos Transfer
An open world-to-world transfer model that generates physics-aware video world states for physical AI development using text prompts and multiple spatial control inputs derived from real-world data or simulation. Transfer can augment and multiply a given dataset by adding diversity with variation in lighting, background, weather, colors, textures, and more.
Cosmos Reason
Cosmos Reason is an open, customizable, reasoning vision language model (VLM) for physical AI. The VLM enables robots and vision AI agents to reason like humans, using prior knowledge, physics and common sense to understand and act in the real world. The model has topped the Physical Reasoning leaderboard and can be applied to a variety of use cases, including data annotation and critiquing, robot planning and training, and creation of video analytics AI agents across industries. Cosmos Reason is used in the NVIDIA Blueprint for Video Search and Summarization (VSS) to develop video analytics AI agents.
To build, customize, and deploy these models for specific domains, developers can leverage the NVIDIA Cosmos Cookbook – offering step-by-step workflows, technical recipes, and concrete examples for inference, post-training and fine-tuning.
Architecture for running Cosmos WFMs on AWS
AWS offers two deployment options:
- Real-time inference: NVIDIA NIM microservices (a set of accelerated inference microservices that allow organizations to run AI models on NVIDIA GPUs anywhere) on Amazon Elastic Kubernetes Service (Amazon EKS) for low-latency, interactive applications
- Batch inference: Containerized models on AWS Batch for high-throughput, offline workloads
The NIM-on-EKS pattern prioritizes response latency and sustained availability with persistent GPU-backed pods, while the AWS Batch pattern optimizes cost efficiency and elastic throughput through ephemeral, job-triggered compute provisioning. Selection between these architectures depends on latency requirements, inference volume patterns, cost constraints, and integration points within the broader physical AI development pipeline.
Option 1: Running live inference – Cosmos NIM microservices on Amazon EKS
The Cosmos NIM microservices on Amazon EKS option provides enterprise-grade orchestration, automatic scaling, and simplified operations. This is the recommended approach for production deployments requiring high availability, dynamic scaling, and cloud-native integration. The Cosmos NIM microservice packages Cosmos models with optimized inference engines, eliminating manual configuration complexity. For a step-by-step guide to deployment of this pattern, please refer to the “Deploying generative AI applications with NVIDIA NIMs on Amazon EKS” blog post.
Architecture Diagram
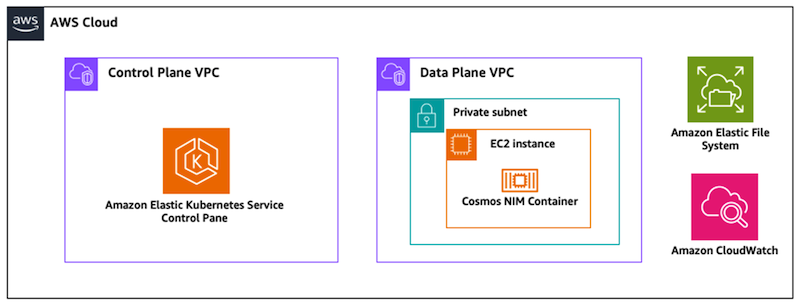
Figure 2: Reference Architecture for running live inference using the Cosmos NIM microservices on Amazon EKS.
Advantages
- Enterprise-grade orchestration: Kubernetes provides declarative configuration, automated rollouts and rollbacks, self-healing through pod restarts, and service discovery without manual configuration.
- High availability: Multi-pod deployments ensure no single point of failure. Cross-AZ node placement survives availability zone failures. Rolling updates maintain service availability during deployments.
- Simplified operations: The managed control plane eliminates node maintenance. Automated upgrades keep cluster components current. Integration with AWS services provides unified monitoring and security.
Option 2: Running batch inference – Cosmos container on AWS Batch
AWS Batch provides a fully managed service for running batch computing workloads at scale, making it an ideal platform for deploying Cosmos WFMs for offline inference scenarios. This architecture enables you to process large volumes of physical AI data—generating synthetic trajectories, scene variations, or environment predictions—without maintaining persistent infrastructure. The deployment leverages containerized Cosmos models orchestrated by AWS Batch, which automatically provisions optimal compute resources (GPU-enabled EC2 instances) based on job queue demand. Input data from Amazon S3 or Amazon EFS triggers batch jobs that perform inference tasks such as video generation, scene completion, or physical simulation. Results are written back to EFS for downstream consumption by robot training pipelines or autonomous system development workflows. Integration with Amazon CloudWatch provides comprehensive monitoring, while AWS IAM policies ensure secure, least-privilege access to model artifacts and data repositories. For a step-by-step guide to deployment of this pattern, please refer to the workshop here.
Architecture diagram
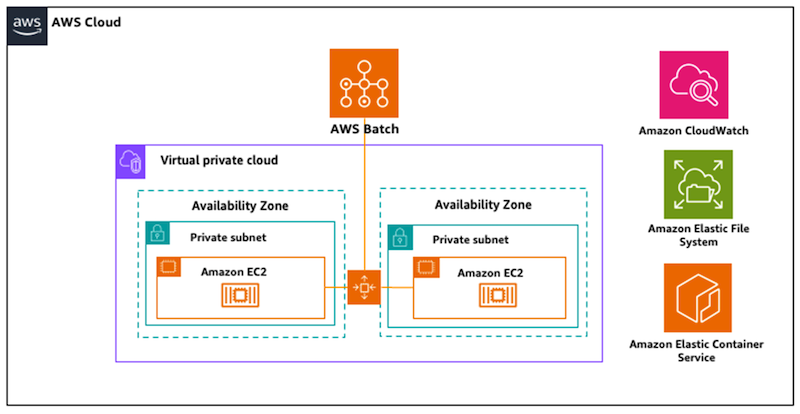
Figure 3: Reference Architecture for running batch inference using a Cosmos container on AWS Batch.
Advantages
- Cost optimization: Through dynamic scaling, AWS Batch provisions GPU compute resources only when inference jobs execute, then terminates instances upon completion. This pay-per-use model eliminates costs associated with idle infrastructure, particularly valuable for intermittent workloads like dataset augmentation or nightly synthetic data generation. Spot Instance integration can reduce compute costs.
- Simplified operational management: The managed service reduces infrastructure complexity with automatic job scheduling, resource provisioning, dependency management, and retry logic, allowing you to focus on model optimization rather than cluster operations.
- Elastic throughput for large-scale data generation: AWS Batch seamlessly scales from single jobs to thousands of parallel inference tasks, processing massive datasets for physical AI training. This elastic capacity accelerates time-to-value, supporting rapid iteration in robot policy development and autonomous system validation.
Conclusion
Running Cosmos WFMs on AWS provides powerful physical AI capabilities at scale. This blog has covered two production-ready architectures, each optimized for different organizational needs and constraints. Explore the Cosmos Reason reasoning vision language model on the AWS Model Marketplace and discover how it leverages advanced spatial-temporal understanding and physical common sense to boost your AI projects, enabling smarter robotic planning, video analytics, and automated data annotation with cutting-edge efficiency and reasoning capabilities.
Author Note: This technical guide is based on the Cosmos platform capabilities, AWS best practices, and general principles of large-scale model deployment. Specific implementation details may vary based on your requirements, the latest NVIDIA NIM microservices releases, AWS service updates, and your organization’s policies and constraints. Always consult the latest documentation from NVIDIA and AWS for the most current information.