AWS for Industries
AUMOVIO Boosts Software Development with an Agentic Coding Assistant Powered by Amazon Bedrock
In this blog post, we will learn about how AUMOVIO used the services and expertise of Amazon Web Services (AWS) to develop an innovative automotive coding assistant on the domain of software-defined vehicles (SDV). AUMOVIO’s solution makes use of multiple AI models to accelerate different development lifecycle steps while helping to ensure alignment with automotive industry standards and adherence to AUMOVIO’s own coding best practices. By maximizing code reuse and thus minimizing the required changes, the assistant significantly reduces the efforts of the other V-model steps. You can read more about AUMOVIO and their AWS-powered SDV solution here.
Challenge
As vehicles become increasingly software-defined, automakers face challenges with growing software complexity, faster innovation cycles, and stringent quality requirements. Traditional development methods, built around physical hardware, localized teams, and manual processes, are becoming constraints. Automakers now must coordinate thousands of engineers across global locations while managing extensive code bases that require validation across numerous dimensions. Additionally, development teams must adhere to domain-specific software development standards such as AUTOSAR, MISRA-C/C++ guidelines, supplemented by their own in-house rulesets. AUMOVIO’s development teams face mounting pressure to adapt their embedded systems processes for this new reality.
Recognizing the need for an intelligent solution to boost the productivity of their teams while maintaining the rigorous standards for automotive applications, AUMOVIO turned to AWS.
Distilling the problem
To better align with automotive best practices and regulations, AUMOVIO develops code following the V-Model development process. Thanks to the immense historical data showing the efforts spent in each step, AUMOVIO was able to point to the steps with highest potential of efficiency gain. Considering this and taking the guidance of AWS around the complexity for automating each step, the AUMOVIO team decided to work on creating a code assistant which can generate
- Automotive-oriented method bodies from system designs (1st release of the coding assistant)
- Unit tests out of system designs (2nd release of the coding assistant)
Moving towards a solution
To test the feasibility of an AI-powered coding assistant, AUMOVIO organized a hackathon under the guidance of AWS. First, the AUMOVIO team tried out RAG-based approaches storing their code base in a vector store and using Amazon Bedrock, a fully managed service that makes it easy to use foundation models from third-party providers and Amazon, to generate code based on retrieved chunks. However, tests showed that semantic search could not retrieve the relevant code for the given task in a single query. Instead of committing to this approach, the team moved to agentic approaches, where the coding assistant (powered by models with strong reasoning capabilities) retrieves the relevant code context step-by-step from the code base. In other words, for a given task, the agent makes multiple searches, analyzing the results from each search to determine what additional code context it needs, and then searches again until it has all the relevant information to complete the task, such as generating code.
To achieve that, the team integrated the open-source coding assistant Cline, powered by Claude 3.7 Sonnet hosted in Amazon Bedrock. The agentic setup showed great potential providing anecdotes such as the coding assistant being able to:
- Fix a bug in a few minutes which took 5 full days of a senior developer’s time
- Refactor a very large file, removing its redundancies and reducing the size by 50%
The same setup performed very well in explaining existing code too. On the other hand, the team quickly understood the limits of such standard models in automotive-specific domains, as they were not fine-tuned on the AUMOVIO code base, which includes many reusable APIs and best practices. In many cases, even if the generated code was good, it was not making use of existing libraries and thus causing duplicates or slight variations of existing implementations.
Taking the positive and negative outcomes of the workshop into account, AUMOVIO and the AWS team, including AWS’s Generative AI Innovation Center, worked together to come up with an agentic architecture as part of a Proof of Concept (PoC). The goal of the PoC was to explore the feasibility of a specialized coding assistant for automotive software development. The program followed a structured approach with defined success criteria and metrics to rapidly assess AI-driven innovation potential. The PoC framework encompassed scope definition, development, testing, performance evaluation, and technical validation, designed to deliver measurable outcomes within the timeframe.
The team designed an agentic architecture that consists of:
- Fine-tuned models or agents used to deliver cutting edge precision for specific V-model steps such as code generation and unit test generation.
- Orchestrator models, such as Claude Sonnet 3.7/4, used in the dialogue window of the application to:
- Gather information about the tasks from the user;
- Delegate tasks to fine-tuned models, if applicable; and
- Respond to tasks, which are not supported by the fine-tuned models (example: code explanation).
To establish performance baselines and understand the potential of different approaches for agents, we evaluated several models with varying capabilities. These included models using only prompt engineering like Nova Pro optimized for quick responses, as well as models like Qwen3 32B, which we later used as a base for fine-tuning on automotive-specific code.
Final Solution
This evaluation phase informed the implementation of our architecture, which integrates these different model capabilities through a flexible infrastructure. The main aspects of the architecture are described in the diagram below:
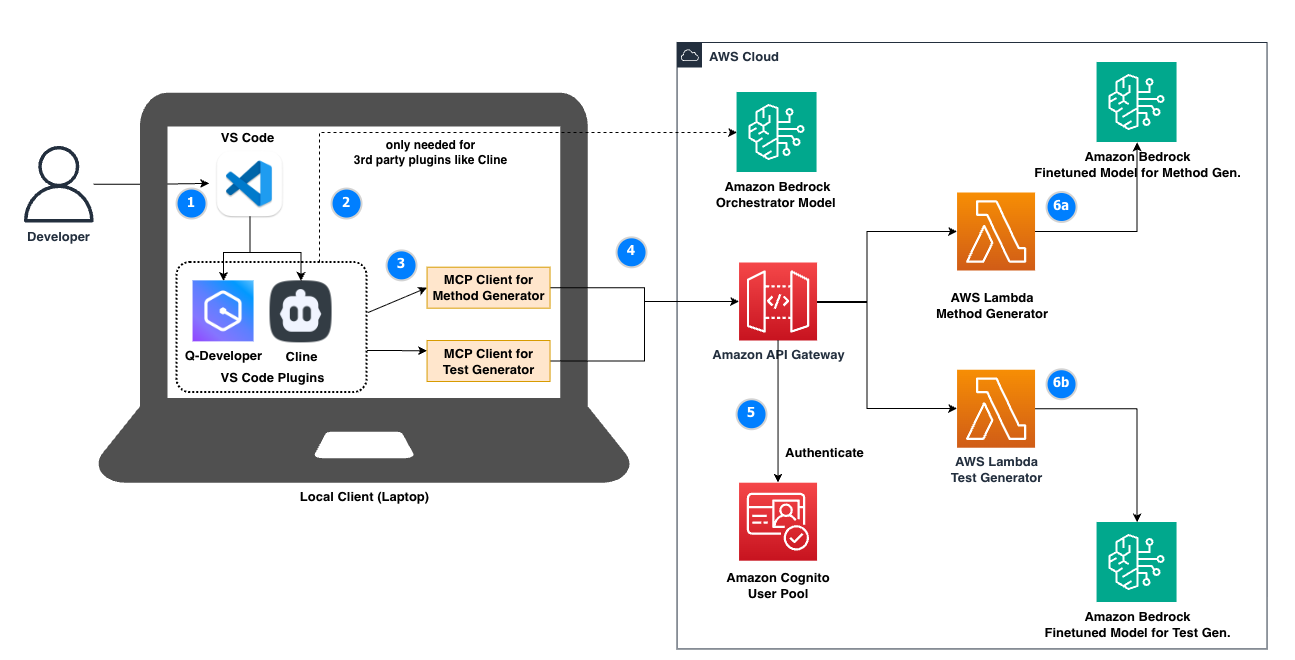
Figure 1: Multi-model / Multi-agent Code Assistant Architecture
AUMOVIO adopted VS Code as their standard integrated development environment (IDE) with multiple extensions. Building on this existing setup, our architecture uses code assistant extensions such as Q-Developer or Cline.
Amazon Q Developer is a generative AI (genAI) powered assistant that helps developers to understand, build, extend, and operate applications. When used in an IDE such as VS Code, Amazon Q can chat about code, provide inline code completions, generate new code, scan code for security vulnerabilities, and make code upgrades and improvements, such as language updates, debugging, and optimizations. The reasoning and agentic capabilities of Q-Developer are backed by premium models. At the time of writing, it can be configured to be used with Claude Sonnet 3.7 or Claude Sonnet 4.
Similarly, the open-source plugin Cline supports many different endpoints to power agentic code assistant use cases in the IDE. Cline can be easily configured with a model hosted Amazon Bedrock such as Claude Sonnet 3.7 or Claude Sonnet 4.
Furthermore, the architecture makes use of the Model Context Protocol (MCP), an open standard that enables AI assistants to interact with external tools and services. Similar to Cline, Amazon Q Developer supports MCP, allowing users to extend Q’s capabilities by connecting it to custom tools and services. In our case, we expose fine-tuned models as MCP endpoints to the orchestrator model. This way the orchestrator model can do the initial planning of the task given by the user, collect more information if necessary, and finally call the fine-tuned models via MCP protocol.
Below is an example navigation flow using Q Developer, aligned with the diagram’s numbering:
1) The developer asks a question to VS Code with Q-Developer integration.
2) Using the underlying orchestrator model, Q Developer understands that the task is about method generation. Next, the orchestrator model identifies that some of the inputs are missing to generate the relevant code. Q Developer then asks for more input (such as missing requirements document).
3) After some message exchange between the developer and the model, Q Developer has collected all inputs. Q Developer then uses the “MCP-Client for Method Generator” to forward the request to Amazon API Gateway, an AWS service for creating, publishing, maintaining, monitoring, and securing REST, HTTP, and WebSocket APIs at any scale.
4) Amazon API Gateway uses Amazon Cognito, a cloud native authentication service, to authenticate the user.
5) Amazon API Gateway delegates to “Method Generator” AWS Lambda Function, which is a cloud native serverless compute engine to run code.
6a) Ramping up a remote MCP Server, the “Method Generator” Lambda Function makes an inference request to Amazon Bedrock, which hosts the fine-tuned model dedicated to method generation. Similarly, “Test Generator” would be called if the task was about generating unit tests (6b).
7) The response from the model is returned via the path AWS Lambda → API-Gateway → MCP Client to the Q Developer, which changes the code in the local IDE and asks the user for confirmation (the numbering is left out in the diagram to improve readability).
In a different navigation flow, the user might ask for explanation of existing code. In this case, the orchestrator will conclude that it does not have any fine-tuned model to handle the task and thus it will use its own reasoning capabilities to provide an answer.
Note that the MCP endpoints of current solution are backed by model endpoints, which handle single tasks. The current iteration is therefore multi-model but not necessarily multi-agent, as the only agent doing reasoning and tool use is the orchestrator model. At the same time, this architecture supports the deployment of additional agents (with reasoning and orchestration capabilities) behind the MCP endpoints, which would result in a multi-agent coding assistant.
Deep-Dive into the Fine-Tuning
To generate domain-specific automotive code that accounts for industry standards, we fine-tune language models on high-quality human-written code from the automotive environment. This section provides details on the fine-tuning process.
Data Preparation
The foundation of effective model fine-tuning lies in high-quality, domain-specific training data. We built a preprocessing pipeline that transforms raw automotive software repositories into structured training examples that preserve the rich context essential for generating C/C++ code.
The preprocessing pipeline begins by traversing AUMOVIO’s C/C++ repositories to extract individual functions along with their comprehensive context. This context includes:
- Function Documentation: Both Doxygen-style comments and inline documentation are extracted and linked to their corresponding function implementations.
- System Requirements: The pipeline parses DOORS export XML files to map requirement identifiers mentioned in function documentation to their full requirement texts.
- Architectural Context: PlantUML diagrams referenced in documentation are extracted and included to provide behavioral specifications.
- API Context: Related header files and their function signatures are gathered to provide information about available APIs and data structures.
A key innovation in the preprocessing approach is the intelligent linking of header files with implementation files. The system identifies the main header file corresponding to each C/C++ source file and extracts additional context from included dependencies. This ensures that generated code can use existing APIs.
Figure 2: Code showcasing context aggregation
The preprocessing pipeline also implements several quality assurance mechanisms:
- Function Signature Validation: Automatically corrects function signatures in implementation files by matching them against header file declarations.
- Documentation Completeness: Only functions with comprehensive documentation are included in the training set.
- Code Compliance: Functions are validated against custom rule sets with automotive safety and architecture patterns.
To ensure balanced representation across different code complexity levels, the preprocessing pipeline implements stratified sampling based on function length and complexity. This approach creates training and test sets that maintain consistent distribution characteristics:
Figure 3: Generation of stratified training samples
The resulting dataset contains approximately seven thousand high-quality function implementations with their complete contextual information, split into training and evaluation sets while maintaining complexity distribution balance.
Fine-Tuning
The fine-tuning approach makes use of state-of-the-art techniques optimized for the computational constraints and accuracy requirements of automotive software development.
The team selected Qwen3-32B as the base model due to its strong performance on code generation tasks and reasonable computational requirements. The fine-tuning process employs Low-Rank Adaptation (LoRA) to make training efficient while preserving the model’s general capabilities:
- LoRA Configuration: Rank-8 adapters with alpha=16 applied to attention and feed-forward layers.
- Quantization: 4-bit quantization using BitsAndBytes to reduce memory footprint.
- Target Modules: LoRA adapters applied to query, key, value, and output projection layers plus all feed-forward network components.
The fine-tuning leverages Amazon SageMaker’s distributed training capabilities with PyTorch DeepSpeed integration, specifically designed to handle the computational demands of training large models on automotive codebases. We use SageMaker’s remote decorator to orchestrate distributed training across multiple GPUs within a single instance, with built-in support for scaling to multi-node configurations.
Figure 4: Training LLM’s via SageMaker remote decorator
The training infrastructure implements several key optimizations:
- Adaptive Memory Management Strategy: The system employs both DeepSpeed ZeRO-2 and ZeRO-3 optimization stages based on the training configuration. When using quantization, ZeRO-2 is preferred for its better compatibility with 4-bit quantized models, partitioning optimizer states across GPUs while keeping model parameters replicated. For full-precision training scenarios, the system automatically switches to ZeRO-3, which additionally partitions model parameters across devices and offloads them to CPU memory when not actively needed. This adaptive approach allows training of the full 32B parameter model even with limited GPU memory, while maintaining optimal performance for each configuration.
- Advanced Parameter Management: ZeRO-3’s parameter partitioning enables handling of the large context windows needed for comprehensive function documentation and requirements traceability. The bucket size and parameter persistence threshold are tuned to ensure efficient parameter streaming without excessive communication overhead.
- Communication Optimization: The distributed setup utilizes NVIDIA Collective Communication Library with optimized timeout settings and communication overlap to handle the large gradients typical of code generation models. The configuration includes gradient compression and bucketing strategies that reduce communication overhead during the backward pass.
- Fault Tolerance and Reliability: Given the extended training times, the infrastructure incorporates robust error handling with exponential backoff for model downloads and automatic retry mechanisms for transient hardware failures. The system also implements checkpoint recovery to resume training from the last saved state in case of interruption, with ZeRO-3’s parameter partitioning enabling more granular checkpointing strategies.
- Dynamic Resource Allocation: The Amazon SageMaker integration allows for dynamic scaling based on training load, with the ability to automatically provision additional compute resources during peak training phases.
The distributed training setup achieves approximately 85% GPU utilization across all devices while maintaining stable convergence, enabling AUMOVIO to complete full fine-tuning cycles within their development sprint timelines while optimizing cloud computing costs through efficient resource utilization.
The final model is packaged for deployment through Amazon Bedrock’s custom model import functionality, enabling seamless integration with the multi-model architecture described earlier. The fine-tuned model achieves significant improvements in domain-specific accuracy while maintaining the conversational capabilities needed for the IDE integration.
Testing Results
To assess the effectiveness of different code generation models deployed as MCP endpoints, we conduct comprehensive evaluations focusing on both C and C++ code generation. This section details our evaluation methodology and key findings.
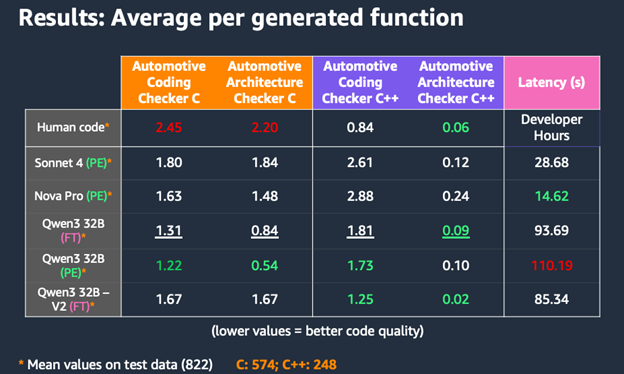
Figure 5: Evaluation of different models on compliance and latency
The table compares different base models, including fine-tuned and generic variants as well as the human code benchmark. We focus on prompt engineering (PE) and fine-tuning (FT) strategies and use multiple evaluation metrics:
- Code adherence with custom Automotive Coding rule sets, verified by custom-built static analyzers based on REGEX (measured in average number of errors per function).
- Code adherence with custom Automotive Architecture rule sets, verified by custom-built static analyzers based on REGEX (measured in average number of errors per function).
- Code generation latency (average seconds per function).
The results reveal interesting patterns: while PE-focused models like Qwen3 32B (PE) achieved strong C code quality scores showing 1.22 violations on average in Automotive Architecture, and 0.54 in Automotive Coding Checker rule set adherence, the FT-enhanced versions showed competitive results in C++ generation. Notably, Qwen3 32B – V2 (FT) achieved excellent Automotive Architecture Checker rule set C++ compliance (0.02) and solid Automotive Coding Checker rule set C++ scores (1.25), demonstrating the advantages of combining fine-tuning with prompt engineering.
These findings demonstrate the strategic advantage of having flexible access to multiple code generation models through MCP. Different models excel in different scenarios: Nova Pro offers rapid generation with 14.62s latency and good C code compliance, making it ideal for quick prototyping and C-focused development. Meanwhile, Qwen3 32B variants show superior C++ adherence scores. The ability to seamlessly switch between PE and FT approaches provides additional optimization opportunities. Developers can utilize PE models for straightforward API implementations where prompt customization is key. For more complex C++ code generation, they can switch to FT models as learned patterns prove more beneficial. This flexibility, combined with the cost-performance tradeoffs of each model, allows development teams to tailor the code generation based on project-specific requirements.
These improvements in code quality and better adherence to standards directly address our initial challenge of maintaining code quality while keeping up with the increasing complexity of software-defined vehicles.
“AUMOVIO’s Engineering Assistant has helped us keep pace with the increasing complexity of software-defined vehicles while delivering significantly faster development cycles and increased code quality. The assistant ensures we maintain automotive standards compliance without compromising on speed – exactly what we needed for today’s competitive automotive market.”
– Amir Namazi Solution Manager Virtualization Cloud and AI by AUMOVIO
Conclusion
In this first iteration, AUMOVIO created a highly specialized coding assistant supported by a finetuned model for generating code. Looking ahead, AUMOVIO will continue to iterate on the coding assistant, expanding its capabilities to better serve various phases of the V-model development process. To further boost this idea, AUMOVIO is gradually migrating its projects to Kiro as it supports spec-driven development, which covers multiple steps of V-model lifecycle, along with the agentic coding assistant capabilities of their current setup. While unit-test generation remains a key area of interest, AUMOVIO’s broader ambition is to evolve the tool into an integrated, product-grade offering that benefits AUMOVIO’s internal teams and external partners alike. The longer-term vision is to transition toward a multi-agent framework, where specialized models and orchestrators collaborate seamlessly across the development lifecycle.
For further guidance, visit the AWS for automotive and Manufacturing pages, or contact your AWS team today.