AWS for Industries
BridgeWise builds responsible AI in FSI with Amazon Bedrock
Why responsible AI matters to BridgeWise
When it comes to the wealth and finance space, recommendations take on additional weight. Investors decide about their capital based on the guidance provided by financial services institutions (FSIs), meaning that accuracy and data quality are paramount. If investors encounter errors or hallucinations when interacting with AI in the wealth space, their trust erodes quickly. With such a high bar, FSIs need to know the tools they make available to their customers will uphold that trust.
In this post, we show how BridgeWise was able to overcome these challenges when developing their wealth AI platform with responsible AI in mind. BridgeWise is a global leader in AI for wealth. Its proprietary technology includes a finance-specific Micro Language Model (MLM). BridgeWise provides financial institutions and trading platforms with a core AI layer that delivers analysis for over 70,000 global assets via engaging, investor-friendly solutions. It brings AI chat for investments, social and news sentiment analysis, market alerts, and more. BridgeWise’s AI is also purpose-built for wealth, ensuring accuracy and compliance across the board.
The challenges BridgeWise faced
To ensure the model uses the right language and adheres with financial regulations, BridgeWise trained a custom model. This proved a cost-effective way to handle millions of calls daily. However, every model training iteration could potentially result in the loss of some past training (a.k.a. catastrophic forgetting). BridgeWise had to assess the model periodically against a diverse set of questions. Each answer from the custom model was assessed against multiple parameters, including accuracy, language used, and factuality.
This task is cumbersome, requiring a team of subject matter experts (SMEs) for days at a time. It also created a responsible AI dilemma, choosing between:
- Evaluate frequently — fast detection of regressions with a high impact on the SME team
- Evaluate infrequently — lower impact on SMEs, but risk having regressions grow over multiple training iterations.
To maintain its position as a trusted industry leader, BridgeWise set an ambitious goal: to automate the evaluation of the model’s response. They chose an LLM-as-a-Judge approach. This automated evaluation cycle happens after each training
cycle.
It also reduced human effort, as human evaluation is now only there to prevent evaluation-drift over time. Another way to think about it is that this will do to model training what DevOps did for software developers. It allows them to move fast as they can rely on automated testing to find regressions.
Solution Overview
Let’s explore how BridgeWise and AWS collaborated to build an automated model evaluation system using Amazon Bedrock as the backbone for LLM-as-a-Judge. To run after each training cycle, the solution had to return the results quickly. It also had to have a minimal impact on the SME team. Previously, the SME team spent days reviewing thousands of question-response pairs. Now, the evaluation runs automatically. The diagram illustrates the full architecture of the evaluation system:
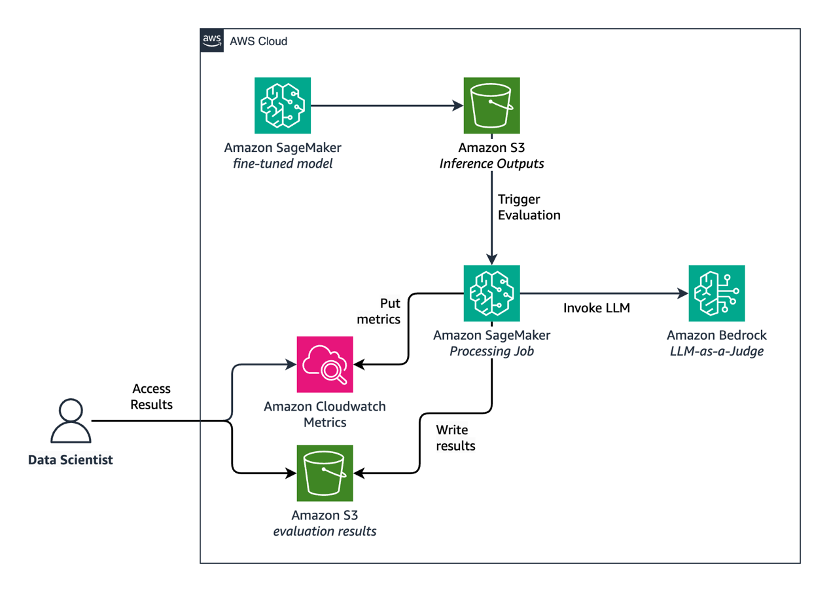
Figure 1. Solution architecture for the BridgeWise LLM evaluation system on AWS
At a high level, the workflow operates as follows:
- After a fine-tuning cycle, data scientists define evaluation criteria files and upload them to an Amazon S3 bucket.
- When new model outputs are available for evaluation, the system automatically triggers a job in Amazon SageMaker Processing.
- The processing job reads the evaluation files and model outputs from Amazon S3. It then invokes foundation models on Amazon Bedrock to evaluate each response against ground truth data.
- The tool stores evaluation results, including scores, explanations, and token usage metrics, in Amazon S3. It also sends operational metrics to Amazon CloudWatch.
- Data scientists access the results through an analysis notebook and can analyze performance across responsible AI dimensions or model versions.
This architecture provides BridgeWise with a repeatable, managed evaluation pipeline that decouples the evaluation process from individual machines and scales with its growing language coverage.
Technical Implementation
The AWS PACE (Prototyping, AI & Cloud Engineering) team worked with the BridgeWise data science team over 3-weeks to build this solution. Let’s walk through the key components of the implementation.
Evaluation Logic
The evaluation process begins with input from multiple sources:
- Inference outputs from different model versions
- Ground truth data curated by the product team
- Evaluation configuration provided by a data scientist
The evaluation tool is a containerized application with custom application logic. It retrieves this data from Amazon S3 and processes it.
For each question-response pair, the tool constructs a structured JSON prompt containing the evaluation criteria, the expected answer, and the model’s response. It then invokes a Foundation Model (FM) on Amazon Bedrock — such as Anthropic Claude — which acts as the judge. The model returns a structured evaluation output including a score (qualitative decision) and an explanation of its reasoning (qualitative). This structured approach makes the analysis consistent and quantifiable across metrics such as faithfulness, factual accuracy, and regulatory language compliance.
Serverless Execution with Amazon SageMaker
Running evaluations on individual laptops occasionally failed because of missing dependencies or inconsistent environments. The team designed the tool to run using Amazon SageMaker Processing jobs. Each evaluation run is an immutable, atomic job that uses a predefined container image. This prevents inconsistency and improves reproducibility.
Data scientists configure evaluation parameters through an interactive notebook, providing the inputs. Multiple evaluation jobs can run concurrently, each operating independently and storing results separately. This also helps process multiple versions of the model without interference.
Built-in Operational Excellence
Beyond the core evaluation capability, the team implemented several best practices during the engagement:
- Resilience: The tool uses type validators to detect and correct malformed JSON responses from the LLM. When the judge model returns improperly formatted output, a feedback loop prompts the model to correct its response, preventing pipeline failures.
- Reliability: BridgeWise’s usage pattern is spiky. Thousands of evaluations in one hour, then nothing for days. The team implemented proactive rate limiting and adaptive retry with exponential backoff through the AWS SDKs, preventing throttling failures under burst workloads.
- Monitoring: The tool sends custom metrics to Amazon CloudWatch, tracking input and output token counts, execution time, and success rates. This helps BridgeWise build dashboards for cost attribution across model versions and set alarms for anomalous behavior.
Results Analysis
To help data scientists interpret evaluation results at scale, the team built two analysis mechanisms powered by Amazon Bedrock:
- Overall explanation: A notebook that takes a completed evaluation run. It filters results below a configurable quality threshold. It then uses Amazon Bedrock to identify common patterns of failure, key missing points, and areas for improvement. For each finding, it surfaces three representative questions from the evaluation dataset.
- Overall comparison: A notebook that summarizes and compares evaluation results across multiple model versions, explaining which model performed better and why. This helps data scientists make informed decisions about which training iteration to promote.
BridgeWise also applies a human-in-the-loop pattern. Subject matter experts review a sample of evaluation results to validate the automated scores and detect potential drift in the LLM judge over time.
Conclusion
You’ve now seen how BridgeWise used LLM-as-a-Judge to put responsible AI into practice. Instead of improving the training itself, the focus is on reducing the overhead of evaluating the training’s results. They used the vast dataset of past reviews to facilitate an effective, automated evaluation. The result is faster detection of regressions in the model training (for example, catastrophic forgetting). This leads to a higher level of trust in the model. It’s also a more scalable approach, allowing BridgeWise to add questions and corner cases to continue evolving their coverage. This reduced the evaluation time from 4 human days to 3 hours.
The automated evaluation pipeline positions BridgeWise to scale its quality assurance process across multiple languages. It decouples the effort of evaluation from human labor. The serverless architecture built on Amazon SageMaker and Amazon Bedrock means evaluation capacity scales on demand. The operational instrumentation through Amazon CloudWatch provides the visibility needed to manage costs and performance proactively.
To get started with building your own responsible AI evaluation systems, explore Amazon Bedrock and Amazon SageMaker. The AI landscape evolves quickly, and AWS continues to expand its managed offerings in this space. You can also start by learning about GenAI evaluations using the managed evaluation service in Amazon Bedrock. This offers another path for teams looking to add automated evaluation to their workflows. For fine-tuning, Amazon Nova Forge delivers a managed experience from data preparation through training, with techniques like data mixing to help prevent catastrophic forgetting.