AWS for Industries
How to Build an Enterprise-Scale GenAI Gateway
Democratizing Generative Artificial Intelligence (GenAI) and enabling enterprise-scale use case development is critical to realize the full potential of GenAI [HBR Data Visual, 2025]. This democratization can be achieved technically through a GenAI Gateway that serves as the centralized enterprise hub for rapid development and deployment of GenAI use cases across the organization. In this blog post, we present a generally applicable GenAI Gateway architecture, alongside a Feature Development Funnel to steer the iterative development of the gateway and its features.
By “GenAI Gateway,” we refer to a cloud-native solution designed to help manage and facilitate interactions with GenAI models, and advanced GenAI services with the following key capabilities:
- Access Management – authenticate, authorize, and control access to different GenAI capabilities;
- Security – request filtering, content moderation, and threat protection;
- Standardization – unify Application Programming Interfaces (APIs) across models and GenAI services to accelerate use case development and simplify their maintenance;
- Optimization – load balancing, caching, and rate limiting to better optimize performance and resource pooling to help optimize cost; and
- Monitoring and Logging – comprehensive tracking of usage, performance, and costs.
The GenAI Gateway architecture presented in this blog post comprises three fundamental components as depicted in Figure 1, below. The Base Layer provides governed access to fundamental GenAI primitives, such as Large Language Models (LLMs) and guardrails designed to help ensure that LLMs operate within customer-defined ethical, legal, and technical boundaries, anywhere in the enterprise.
The Apps Layer builds on the Base Layer and provides key capabilities needed to build out different use cases. It comprises, for example, Model Context Protocol (MCP) servers to standardize communication between AI applications (incl. LLMs, agents) and external resources (incl. tools, systems, and databases), Retrieval Augmented Generation (RAG) services to connect LLMs with knowledge bases, and batch processing services.
The third component is called Control Plane and serves as the central management interface of the GenAI Gateway by helping control access to services within the Base and Apps Layers and monitoring their usage. In an enterprise-scale GenAI environment, this GenAI Gateway architecture is often complemented by two additional layers, namely Scaling and Democratization Services. While the Scaling Layer focuses on re-usability by providing reusable artifacts, such as templates for RAG and no-code GenAI tools, the Democratization Layer helps enhances discoverability through apps and tools catalogues. In other words, the Base and Apps Layers help provide centralized governance, standardization and acceleration while the Scaling and Democratization Services help decentralize use case development and innovation, an architectural principle we introduced in a preceding blog post [AWS Blog Post, 2025].
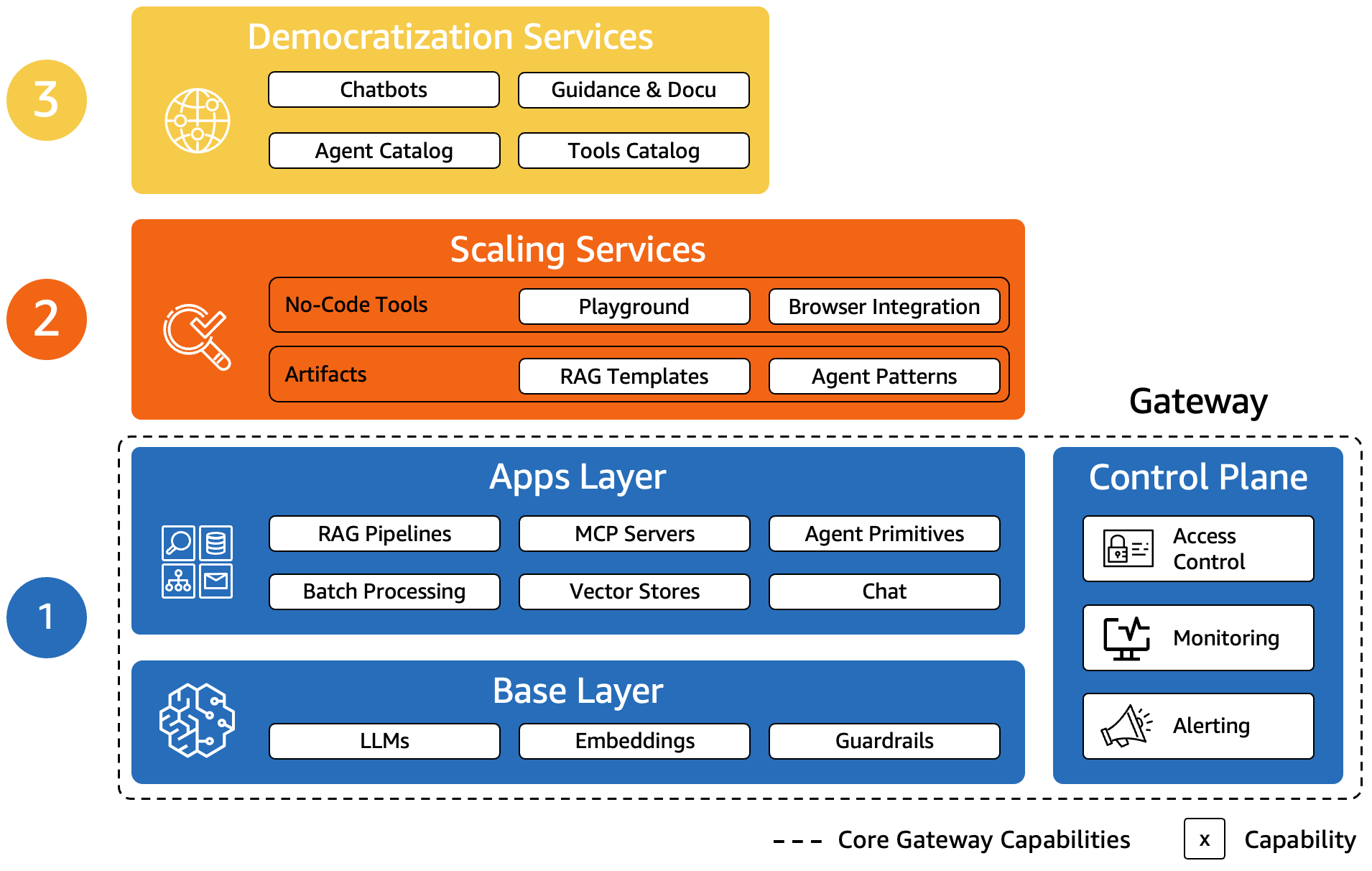
Figure 1: The three fundamental service layers of an enterprise-scale GenAI deployment (1-3).
Let’s look at a concrete example of how the GenAI Gateway provides a unified environment to develop use cases. Consider the following scenario: Bob, a maintenance engineer of a global automotive manufacturer, wants to ensure the smooth operation and optimal performance of automotive assembly lines. Initially, he explores an existing company chatbot to explore machinery documentation in the “Democratization Services” layer.
Drawing from his professional expertise, he decides to create a better performing and more accurate solution tailored to assembly lines. By utilizing the Playground in the Scaling Layer, Bob uploads relevant machinery documentation and iteratively experiments with different LLMs and prompting strategies aiming to develop a minimum viable product (MVP) that can be shared with his wider team. The positive reception from his team prompts management to expand the MVP into a more sophisticated agentic service for the whole company [see AWS Blogs, 2025].
A dedicated development team then uses the services available in the Base and Apps Layers, such as existing tools or RAG pipelines, to help implement a solution that is tailored towards Bob’s business challenge, but goes far beyond Bob’s original scope. It becomes an agentic system capable of helping detect operational anomalies, machinery downtimes, automatically alerting human experts, and recommending more immediate remediation actions.
Upon completion, Bob makes the chatbot and the new tools developed with it available within the Democratization Services layer, making it accessible to maintenance engineers across the entire company. This exemplary scenario shows how Bob can harness different layers of the stack to help accelerate the development of his use case from ideation to production readiness and share the assets he developed with others across the company.
The GenAI Gateway Feature Development Funnel
Besides standard principles of global enterprise cloud platforms [AWS Blog Post, 2024], such as multi-region availability and security, the GenAI Gateway must accommodate the rapid pace of innovation in GenAI. For example, Amazon Bedrock released dozens new features in Q1 2025 alone, and the Model Context Protocol (MCP) [AWS Blog Post, 2025] became the de-facto industry standard for LLM-tool interaction within months of its announcement.
Given this rapid pace of innovation, developing the right approach to platform enhancements is crucial for quickly adopting GenAI across a company and its ecosystem. This includes, for example, including custom APIs where possible and finding the right balance between centralized control and decentralized innovation.
Let’s consider a concrete example. Suppose the platform team wants to provide RAG capabilities to their use cases, allowing LLMs to incorporate information from external knowledge sources. Fully centralized RAG-as-a-service (RAGaaS) approaches help enable quick development for use cases and cost savings but require large platform teams and may constrain use cases.
Fully decentralized models in which use cases fully own their RAG pipelines, on the other side, enable rapid innovation but risk solution duplication and governance challenges. The optimal approach often lies between these two extremes. To help balance the degree of centralization vs. decentralization and evolve the GenAI Gateway features effectively over time, we developed the Feature Development Funnel shown in Figure 2 below.
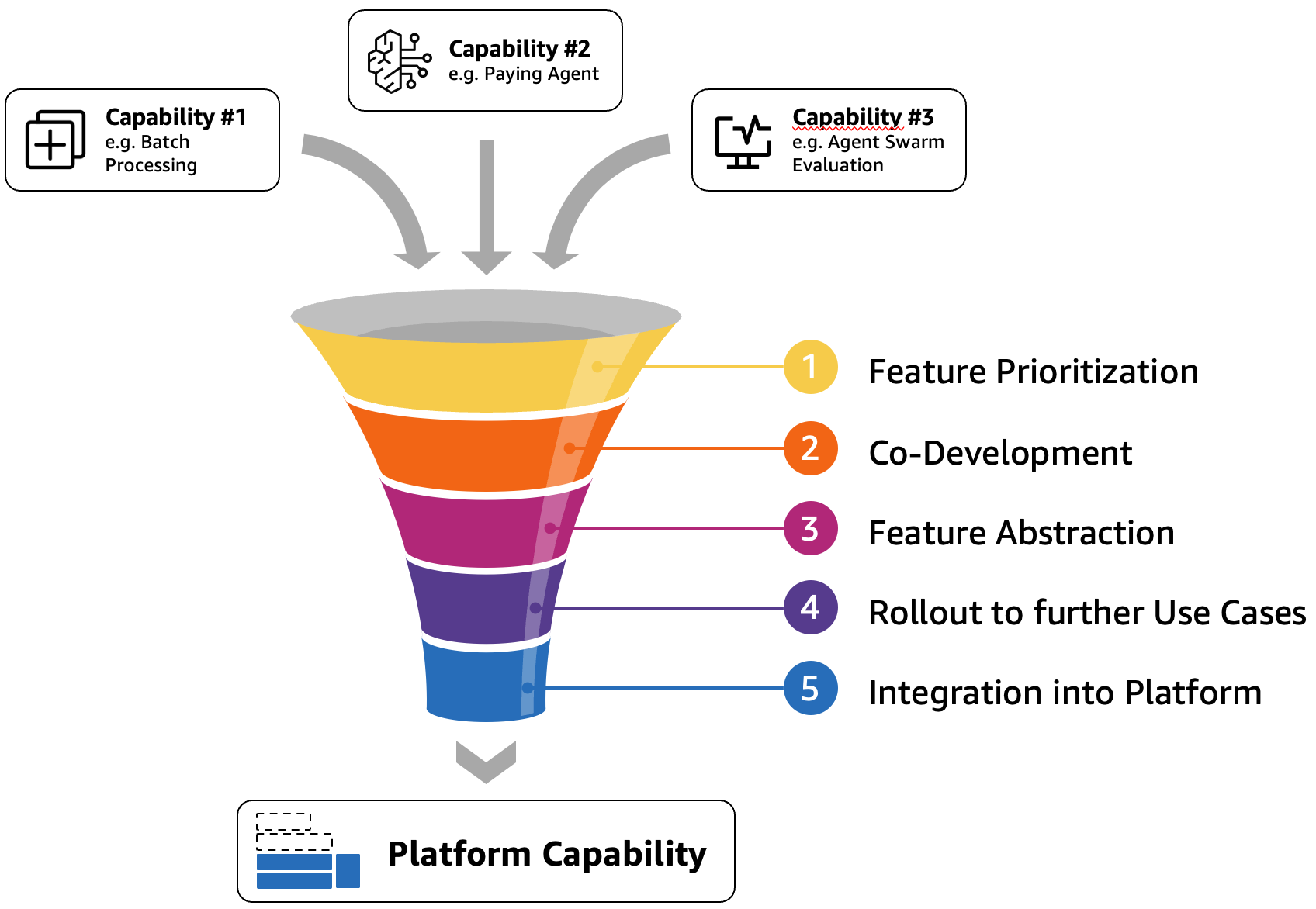
Figure 2: Feature Development Funnel describing how a use case-specific capability becomes a shared platform capability along five steps (1-5).
This Feature Development Funnel helps enables the central gateway development team to gradually integrate feature requests by use cases into (shared) GenAI Gateway capabilities. In the RAG example above, this could be a request for new agentic retrieval capabilities [see AWS Blogs, 2025]. The GenAI Gateway team prioritizes this feature (step 1) and decides to co-develop it (step 2) as a one-off solution with the leading use case, without full abstraction into the gateway, but using existing capabilities, such as LLMs, embeddings, and vector stores.
After proof of value has been established for this use case, and given enough demand by other use cases, this one-off solution is abstracted into a reusable artifact—a so-called Terraform template [Terraform Introduction, 2025], for example—that is maintained by the GenAI Gateway team (step 3) but which can be fully customized and deployed by use cases in their environment (step 4). Based on this feedback, the GenAI Gateway team might find the right layers of abstraction to integrate it as a service in the Apps layer or decide to stop feature development at the artifact stage.
Base Layer Solution Design
As we saw above, the main aim of the Base Layer is to provide GenAI Gateway users access to GenAI primitives like LLMs and guardrails available in Amazon Bedrock Runtime from any environment across the organization without creating additional AWS account(s) all while ensuring adherence to customer-defined security and governance standards. This is why the technical implementation of the Base Layer is based on the following guiding principles (GP):
- GP1: Accessibility – Amazon Bedrock runtime must integrate more easily with other applications, regardless of where they run. This requires the use of a public API.
- GP2: Governance – More fine-grained control over the Amazon Bedrock features that are accessible or need to be enforced depending on the use case is essential. This means that the GenAI Gateway must allow the definition of input and output token rate limits per use case or enforce Guardrail calls for specific use cases.
- GP3: Low-Latency – The latency of LLMs is continuously decreasing, enabling use cases that make multiple sub-second LLM calls in sequence. Reducing the overhead added through the GenAI Gateway becomes essential to help enable these use cases. Tensions in detailed governance, such as the enforcement of rate limits, take time and must be considered in the design.
- GP4: Scalability – Enterprise-wide LLM use cases can easily consume billions of tokens per month. At the same time, workload volumes are often hard to predict. A GenAI Gateway helping support hundreds of use cases must be built for this scale and volatility. Achieving this requires a design that helps enable robust scaling and load-balancing.
- GP5: Extensibility and Ease of Integration – Any GenAI Gateway architecture must consider the rapid pace of GenAI technology, as described above. Avoiding custom interfaces is essential for the GenaI Gateway team to more quickly adopt changes developed by AWS service teams or the open-source developer community.
- GP6: Minimal Maintenance – Enable GP1 to GP5 with an architecture that requires minimal maintenance and can be evolved more easily as new Amazon Bedrock features are released.
The principles outlined previously informed the architectural design of the Base Layer, as depicted in Figure 3. The Base Layer is comprised of multiple AWS accounts: A central AWS account takes Amazon Bedrock runtime requests from use cases and helps balance them across multiple accounts in a more governed, monitored, and secure way. The typical user workflow includes eight steps, which are explained in detail in Figure 3 below, along with the GPs these steps address:
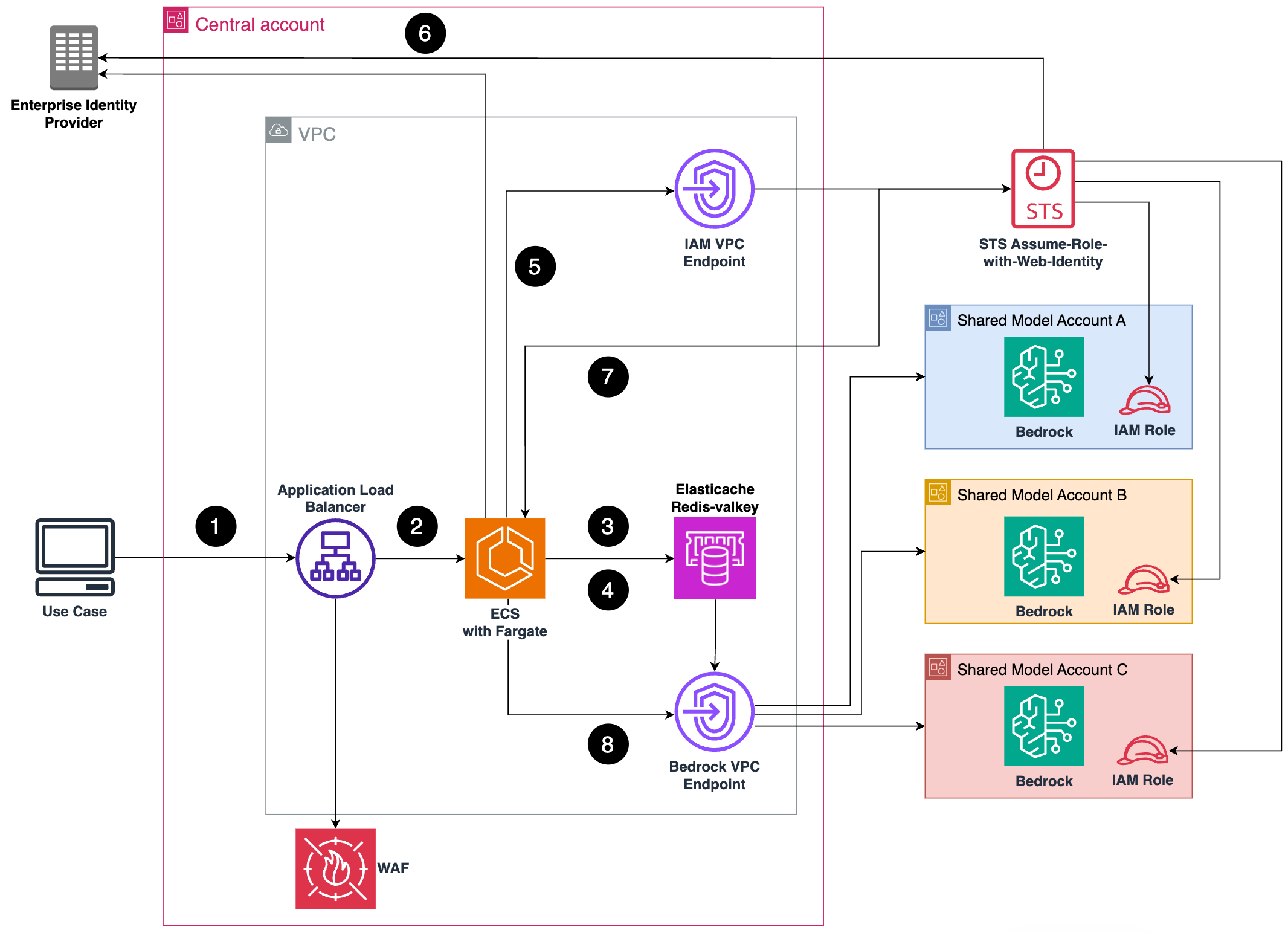
Figure 3: High-level solution design of the Base Layer, demonstrating the eight-step workflow for accessing Amazon Bedrock runtime capabilities (1-8).
- Step 1: A use case accesses the Base Layer by sending requests to an Application Load Balancer (ALB) in the central account using the existing Amazon Bedrock runtime API. The use case can do this either via direct HTTP requests or AWS Software Development Kits (SDKs), such as Amazon SDK for Python (Boto3). The ALB is accessible from anywhere in the enterprise (GP1). An ALB enables large payloads for multi-modal models (up to 100 MB for Amazon Elastic Container Service (Amazon ECS) targets) and to help support long model execution times of several minutes (e.g. for reasoning models). Using the Amazon Bedrock runtime API directly means the team can provide new Amazon Bedrock features quickly and simplify integration with major open-source tools that already support the Amazon Bedrock API (GP5).
- Step 2: The ALB has an Amazon ECS task as target that processes the request. Amazon ECS was chosen over alternatives like AWS Lambda to help enable large payloads (up to 100MBs) and low latency (GP1, GP2).
- Step 3: The Amazon ECS task checks the current quota of a use case and the available model quota in each shared model account in an Amazon ElastiCache (ElastiCache) database.ElastiCache minimizes the latency overhead of the rate lookup (GP2). The Amazon ECS task distributes the load over all shared accounts to help avoid throttling and enable scale (GP4).
- Step 4: The Amazon ECS task checks if there are already temporary AWS Security Token Service (AWS STS) credentials for the particular use case cached in ElastiCache to make the Amazon Bedrock calls in the shared model accounts (e.g., from earlier invocations). If yes, the Amazon ECS task directly proceeds to step 8.
- Step 5, 6 and 7: If there are no cached credentials the Assume Role with Web Identity function is used to create new temporary cross-account credentials scoped for the particular use case (Step 5). The identity of the use case is confirmed with the chosen Enterprise Identity Provider (Step 6). The returned temporary credentials are stored in ElastiCache to speed up future requests (GP2).
- Step 8: The Amazon Bedrock runtime request is forwarded to one of the shared model accounts based on the available quota. The quota is load-balanced across all shared model accounts. Increasing the quota of the Base Layer, as a whole, is as simple as on-boarding an additional shared model account to it (GP4).
This architecture can be extended to add unified guardrails and enforce their invocation for particular use cases. In general, this architecture enables fine-grained control over the actions that each use case can perform and detailed login. The detailed architecture of this implementation together with open-source code to deploy it shall be provided in a future blog post.
Conclusion
In this blog post, we outlined the architecture of an enterprise-scale GenAI Gateway designed to democratize GenAI capabilities across an organization. The proposed solution features a three-component design comprising a Base Layer, Apps Layer, and Control Plane, which may be complemented by Scaling and Democratization Services. The Base Layer helps provide governed access to core GenAI capabilities like LLMs and guardrails, while the Apps Layer builds on this foundation for use case development—the Control Plane serves as the backbone for both layers. We also introduced an innovative Feature Development Funnel as an effective methodology to help balance centralized governance with decentralized innovation. The architecture emphasizes accessibility, governance, low-latency, scalability, and extensibility, and can help enable organizations to effectively manage and scale their GenAI capabilities while maintaining security and compliance.