AWS Global Infrastructure and Sustainability Blog
Architecting distributed agentic AI workloads across AWS hybrid cloud services
With the general availability of Amazon Elastic Compute Cloud (Amazon EC2) G7e instances in AWS Local Zones in Los Angeles, featuring NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs and 5th generation Intel Xeon Scalable (Emerald Rapids) processors, you can now bring high-performance GPU compute closer to end users for AI workloads including inference and agentic AI at the edge. Since its launch, one question has come up repeatedly from customers operating across multiple geographies or under strict data protection regulations: how to architect distributed AI agents across AWS hybrid cloud services, where data residency, compliance, and low-latency inference demand compute closer to end users.
In this blog, we introduce two critical reference patterns, local agents and distributed agents, while discussing the key trade-offs across model capability, compliance, and operational complexity that customers should consider when architecting agentic AI workloads on AWS hybrid cloud services.
Agentic AI patterns across AWS hybrid cloud services
In a previous post, we showed two reference patterns using Retrieval-Augmented Generation (RAG):
- To comply with data residency requirements where all sensitive data must be contained within a set geographic boundary, the local RAG pattern using AWS Outposts racks or Local Zones collocates the small language model (SLM), knowledge base, and embedding model allowing you to control where your data is located.
- To comply with data protection or privacy regulations which require you to process some sensitive data within a given geographic boundary, the Hybrid RAG pattern using Outposts racks and Local Zones shows a way to use an AWS Region-based orchestrator to decide whether local data is required and delegate control to a local SLM and knowledge base.
With the release of Amazon Bedrock AgentCore, we wanted to refresh our guidance for generative AI across AWS hybrid cloud services while covering agentic AI more deeply. Across RAG and AI agents, the “local” versus “distributed” distinction still applies, and the type of data protection regulations your workload must abide by will determine which architecture pattern you should consider.
While the primitives vary between Amazon Bedrock Agents (covered in the previous post) and Amazon Bedrock AgentCore, the underlying architectural principles still apply. Where Bedrock Agents uses Action Groups and built-in orchestration logic, AgentCore provides you with more flexibility to define specific tools, or even dedicated agents, corresponding to data residing at the edge or on-premises. Given the numerous types of agent frameworks, SDKs, and tool designs, we provide a few end-to-end examples.
Local agentic AI with Strands Agents
If you must process data within a specific geographical boundary to comply with data protection requirements, Strands Agents provides a lightweight, open source framework well-suited for building agentic AI applications on AWS hybrid cloud services. Strands supports local inference through frameworks such as Ollama, llama.cpp (optimized for small language models), and vLLM (for high-throughput serving scenarios), allowing you to run foundation models directly on AWS hybrid cloud services without any traffic leaving the local environment. On the tooling side, any data source, API, or business logic available within the local environment can be exposed to the agent as a custom tool using the @tool decorator — without requiring connectivity to an AWS Region. For the runtime environment, we recommend deploying the agent as a container on Amazon Elastic Kubernetes Service (Amazon EKS) or Amazon Elastic Container Service (Amazon ECS) on the Outpost or Local Zone, giving you full control over scheduling, scaling, and resource allocation for your agent workloads.
The model you can serve locally depends on the accelerated compute available at a given location. Select Local Zones such as Atlanta, Phoenix, and Dallas have large ML capacity pools featuring latest generation instances (such as P5 with NVIDIA H100 or P6e-GB200 UltraServers), making them comparable to AWS Regions for hosting larger foundation models locally. Other Local Zones, such as Los Angeles, offer smaller instance types with G-family instances (such as the newly available G7e instances) that are well suited for SLM inference.
A key architectural advantage of running agents on hybrid cloud infrastructure is the ability to decompose the workload and place each component on the most appropriate instance type. The inference workload, serving the foundation model and generating completions, requires GPU-accelerated compute such as G-series instances (e.g., G7e with NVIDIA RTX PRO 6000 GPUs). However, the agent workload itself, the orchestration loop that manages tool calls, maintains conversation state, and executes business logic, is primarily CPU-bound and does not require GPU resources. This means you can run the agent runtime on a general-purpose instance such as a T-series (e.g., T3), which offers a significantly lower cost profile, while pointing it at a separate G-series instance hosting the model inference endpoint. By breaking these workloads apart, you can independently scale each tier based on demand: scale GPU instances to handle inference throughput, and scale general-purpose instances to handle concurrent agent sessions, optimizing both cost and resource utilization across your hybrid deployment.
When selecting where to deploy your local agents, consider whether the Local Zone’s capacity profile supports the model size and throughput your inference workload requires, and plan your general-purpose compute allocation for the agent runtime accordingly. For specific details on the supported Amazon EC2 instance types per Local Zone, visit AWS Local Zones features page.
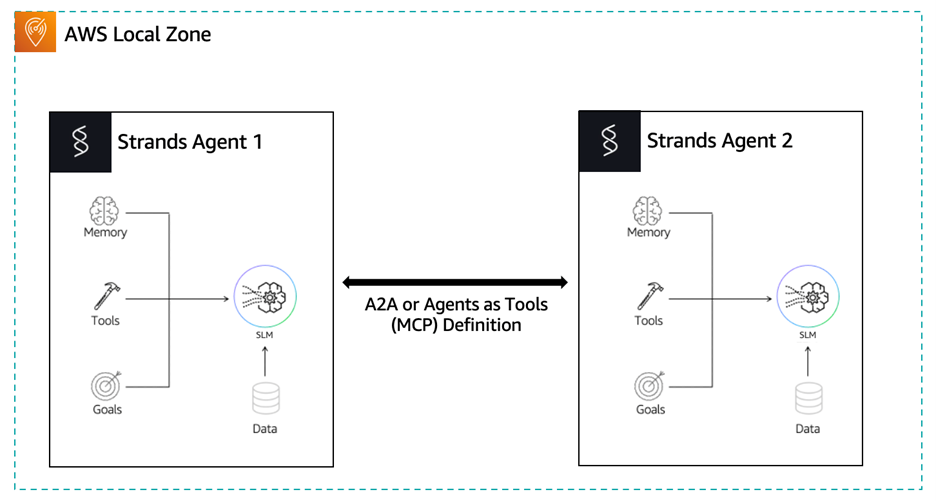
Figure 1: Multi-agent communication architecture deployed on AWS Local Zones. This deployment pattern is equally applicable to AWS Outposts environments.
Multi-agent systems primer
Confining agents to a local boundary does not mean you can’t build sophisticated multi-agent systems. Strands supports two patterns for local agent-to-agent interaction:
- Agent-as-Tool – this pattern uses one agent that is registered as a callable tool within another, enabling hierarchical delegation while keeping all communication local.
- A2AClientToolProvider – this pattern implements the Agent-to-Agent (A2A) protocol to enable peer-to-peer communication between fully independent agents—each with its own model, tools, and objectives. The Agent-as-Tool approach is well-suited for tightly coupled workflows where a supervisory agent orchestrates specialized sub-agents, while A2A is better suited for loosely coupled systems where agents are developed, deployed, and scaled independently.
If you’re operating multiple Outposts, east-west communication between agents running on different Outposts can be established through either Direct VPC Routing (DVR) or Customer-Owned IP (CoIP)-based routing, depending on your network architecture and IP address management requirements. Additionally, support for multiple Local Gateway (LGW) routing domains provides even greater flexibility, allowing you to design network topologies that align with your specific inter-site routing and segmentation needs.
This pattern is well suited for customers in regulated industries with strict data residency mandates. For example, a healthcare provider operating across multiple hospital campuses can deploy local agents on Outposts to process electronic health records (EHR) and support clinical decision making without patient data ever leaving the facility. Similarly, a financial services firm subject to national banking regulations can run agents locally to analyze transaction data and flag anomalies in real time, ensuring that sensitive financial records remain within the required jurisdictional boundary. In both cases, the local agent pattern ensures compliance with the data residency requirement while still enabling sophisticated AI-driven workflows at the point of data origin.
Distributed agents with Amazon Bedrock AgentCore
When data residency requirements apply only to a subset of the data, or when the application needs access to cloud-scale foundation models alongside edge-resident tools and data sources, a distributed pattern becomes the natural choice. In this architecture, the local agents described in the previous section continue to operate within their geographic boundary, handling sensitive data in place, while Region-based agents or orchestrators running on Amazon Bedrock AgentCore coordinate the broader workflow from an AWS Region. The local agents remain unchanged—they still run Strands (or another framework) on Amazon EKS or Amazon ECS infrastructure at the edge. What changes is the introduction of a Region-based layer that can intelligently route requests, determine whether local data is required, and delegate control accordingly. Tools and agents at the edge can be exposed to the Region through AgentCore Gateway, or directly via the Model Context Protocol (MCP) and the A2A protocol, giving you flexibility in how they integrate their distributed components.
Running your Region-based orchestrator agent on Amazon Bedrock AgentCore rather than self-managed containers on Amazon EKS or Amazon ECS offers several advantages. AgentCore provides built-in session management, automatic scaling to zero when idle, native integration with Amazon Bedrock foundation models, and managed observability through AgentCore’s telemetry pipeline. It also handles agent versioning, A/B testing, and traffic routing without requiring custom infrastructure code. For teams that do not need fine-grained control over the container runtime or have specialized networking requirements at the orchestration layer, AgentCore reduces the undifferentiated operational overhead of running agents in the Region, letting you focus engineering effort on the edge components where custom infrastructure is unavoidable.
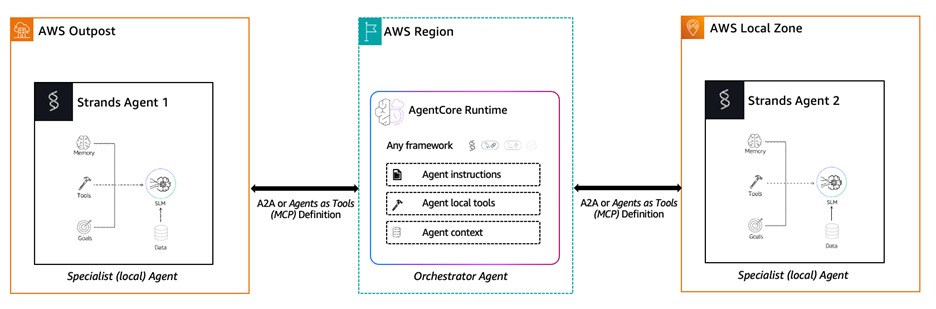
Figure 2: Distributed agentic AI architecture with a Region-based orchestrator agent running on Amazon Bedrock AgentCore coordinating specialist agents deployed on AWS Outposts and AWS Local Zones via A2A or Agents as Tools (MCP). Local agents retain data residency while the orchestrator handles routing, session management, and access to cloud-scale foundation models.
An equally valid—and in some cases simpler—pattern involves a single Region-based agent backed by AgentCore Gateway, with the underlying tools and data sources running at the edge. We have seen this pattern resonate with customers who have a significant majority of their MCP servers and data sources on-premises or running on Outposts, but who are not bound by stringent data residency requirements that would prevent a Region-based agent from orchestrating those tools remotely. In this scenario, AgentCore Gateway serves as a centralized entry point that federates access to a geographically distributed set of tools, eliminating the need to build and maintain multiple custom gateways across edge locations. The agent in the Region issues tool calls through AgentCore Gateway, which routes each request to the appropriate edge-hosted MCP server, executes the tool, and returns the result—all without requiring the underlying data to persist outside its original location.
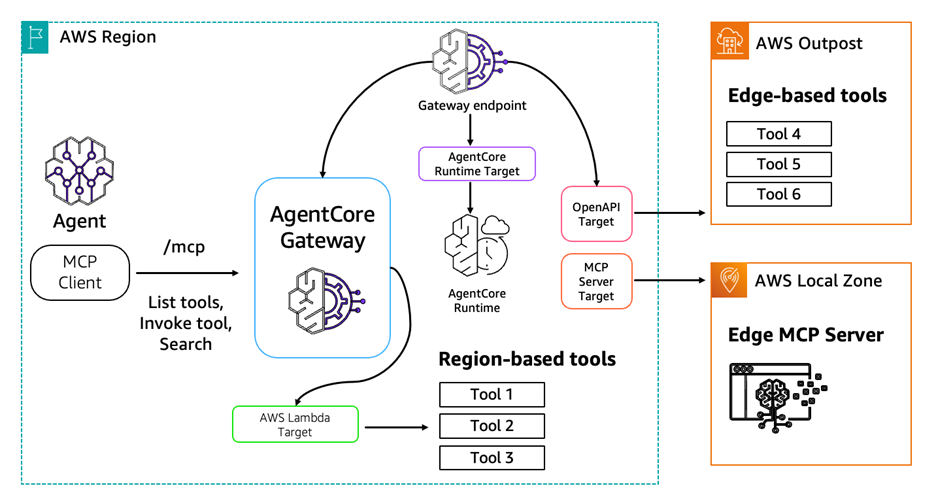 Figure 3: Single Region-based agent using Amazon Bedrock AgentCore Gateway to federate access to geographically distributed tools. The agent connects to the Gateway via MCP(/mcp endpoint), which routes tool calls across the following target types: MCP targets (internal or 3rd party external MCP servers, Lambda functions, API Gateway stages, OpenAPI schemas, Smithy models) and HTTP targets (AgentCore runtime agents).
Figure 3: Single Region-based agent using Amazon Bedrock AgentCore Gateway to federate access to geographically distributed tools. The agent connects to the Gateway via MCP(/mcp endpoint), which routes tool calls across the following target types: MCP targets (internal or 3rd party external MCP servers, Lambda functions, API Gateway stages, OpenAPI schemas, Smithy models) and HTTP targets (AgentCore runtime agents).
Beyond simple request-response tool execution, stateful MCP capabilities unlock a richer interaction model where the server can interrupt, request input, and gate forward progress rather than simply returning a result. AgentCore Gateway’s support for stateful MCP sessions allows edge-hosted servers to drive the conversation back toward the orchestrator or the end user mid-execution.
When using stateful MCP in an agent-as-a-tool pattern, the persistent session channel enables the server to drive interrupts back to the client mid-execution. Through sampling, the sub-agent’s MCP server can request more information from the agent through prompt completion from the client without breaking the task flow. Through elicitation, the server can pause and surface a structured prompt (a confirmation, a form, a choice) that the orchestrator or end user must resolve before execution continues. Human-in-the-loop (HITL) patterns compose directly on top of these: the server gates a destructive or high-stakes operation behind an elicitation request, waits for human approval over the live session, then proceeds or aborts based on the response. From the orchestrator’s perspective, the sub-agent tool call simply blocks until resolution. The approval choreography is fully encapsulated inside the stateful session, keeping the agent-as-a-tool interface clean.
This pattern is well suited for customers with multi-site operations that need edge inference combined with cloud-scale orchestration. For example, a global retailer operating hundreds of stores can deploy local agents at each location to handle inventory queries and customer interactions using on-site data, while a Region-based orchestrator coordinates cross-store demand forecasting and supply chain optimization using aggregated, non-sensitive data. Similarly, a manufacturing company with geographically distributed factories can run local agents on Outposts to monitor production line telemetry and execute real-time quality control decisions, while a central agent in the Region correlates patterns across plants, triggers predictive maintenance workflows, and surfaces insights to operations leaders. In both scenarios, the distributed pattern allows sensitive operational data to remain at the edge while the Region provides the broader intelligence layer.
Additional design considerations for distributed agents
While the local and distributed patterns provide the architectural foundation, production deployments should consider:
- Guardrails for edge agents – Local agents running SLMs at the edge operate outside the reach of managed services like Amazon Bedrock Guardrails. Customers have two options: when Region connectivity is available, agent outputs can be routed through Bedrock Guardrails via API calls for centralized content filtering and validation. When connectivity is intermittent or latency-sensitive, you can implement lightweight validation logic directly within the edge agent; this requires custom implementation and ongoing maintenance to keep policies in sync with their Region-based counterparts.
- Model selection and quantization – The foundation model you serve locally should be matched to both the task complexity and the available accelerator memory. For agentic workloads, where the model must reliably follow multi-step instructions, interpret tool outputs, and decide when to delegate, instruction-tuned models with strong reasoning capabilities are critical—even if they are smaller in parameter count. When the full-precision model exceeds the available GPU memory (for example, serving a 70B-parameter model on a single NVIDIA RTX PRO 6000 with 96 GB of VRAM), quantization techniques such as GPTQ, AWQ, or FP8 can reduce the memory footprint by 2–4× while maintaining meaningful accuracy for structured output tasks. When evaluating quantized models for agentic use, test against your specific tool schemas and agent workflows rather than relying solely on general-purpose leaderboard scores—agentic accuracy depends on structured output correctness, not just perplexity.
- Observability – Amazon Bedrock AgentCore automatically captures telemetry only from agents running on AgentCore Runtime, not from external agents connected via A2A protocol. When an AgentCore agent communicates with an external agent (like one on EC2), only the AgentCore agent’s side of the interaction is instrumented—the external agent requires separate OpenTelemetry instrumentation to capture its own telemetry. For true end-to-end visibility across hybrid topologies, you must implement distributed tracing with OpenTelemetry context propagation to correlate traces between AgentCore-hosted and external agents manually.
- Network security – Communication between AWS Regions and edge locations should prioritize internal VPC connectivity using private IP addressing whenever possible. For Outposts and on-premises infrastructure, traffic flows over the service link. For Local Zones, traffic traverses the AWS Global Network by default through VPC extensions, ensuring encrypted, low-latency connectivity while keeping all agent communication within private address space.
Conclusion
As agentic AI moves from experimentation to production, the question is no longer simply how to build agents but rather where to run each component of the agentic workload: the agent orchestration logic, the model inference, and the tools and data sources the agent depends on. For customers operating in regulated industries, across multiple geographies, or with data that cannot leave a specific physical boundary, the answer increasingly involves AWS hybrid cloud services. In this post, we introduced two architecture patterns, local agents and distributed agents, that give customers a clear framework for making these placement decisions.These patterns, however, are not mutually exclusive. In fact, many real-world deployments will blend elements of both: running self-contained local agents for the most sensitive workflows while using Region-based orchestration for everything else. By working backwards from compliance and data residency requirements, you can draw the boundary between what must stay local and what can operate in the Region, and then select the pattern, or combination of patterns, that best fits.
Beyond the local and distributed patterns covered here, the design space for hybrid agentic AI is broader than it may appear. By decomposing an agentic workload into three independent placement decisions (where the agent runs, where the model is hosted, and where tools and data reside), additional configurations emerge that address different trade-offs around latency, compliance, and model capability. In a follow-up post, we will explore this expanded pattern space in detail, examining which combinations are most practical and when to apply them.
To get hands on with these patterns, visit our workshop Hands on with Generative AI on AWS Hybrid and Edge Services. For the latest news on Local Zones, Outposts, and more, check out the AWS Compute Blog. To discuss these topics with an expert, fill out the contact form for Local Zones or Outposts.