AWS for M&E Blog
Optimizing computing performance with AWS Thinkbox deadline – Part 3
In Part 1 and Part 2 of this blog series, we discuss how to collect benchmark data, how to decide what hardware and software to run, and what AWS Thinkbox Deadline features can be used to get the highest performance at the lowest cost. In part 3, we look at the AWS Portal-specific considerations related to performance optimization.
AWS Portal Specific Considerations
Selecting the Right AWS Region
To optimize low-latency communication between on-premises and cloud infrastructures, the general rule of thumb when selecting an AWS Region to run your services is to pick the closest geographic region.
However, AWS Regions have different sizes and capacities (especially relevant for the Deadline AWS Portal is the spare capacity used by Amazon EC2 Spot Instances). For that reason, when it comes to 3D rendering via AWS Portal, the rule could be expanded to “the largest geographically closest Region.”
For example, in North America, this Region would be N.Virginia (us-east-1) for the eastern part of the continent, and Oregon (us-west-2) for the western part of the continent.
For Europe, Ireland (eu-west-1) would be the preferred region for rendering. Not only do these regions offer more (spare) capacity, but they tend to introduce the newest features and instance types first, and their prices are usually lower.
If you are located in California, for example, the geographically closest AWS Region would be N.California (us-west-1), but you should consider Oregon to get more Availability Zones with more capacity, and lower On-Demand and Spot Instances prices. The benefits would outweigh the effects of the slightly higher latency.
Diversifying the Spot Fleet
As mentioned in the previous section, the Deadline AWS Portal uses Spot Instances for its cloud-based render nodes. Spot Instances offers spare compute capacity at steep discounts compared to On-Demand Instances. The only On-Demand Instance involved in a Deadline AWS Portal Infrastructure is the so-called Gateway instance which currently defaults to a c5.4xlarge Linux instance (earlier versions of Deadline used a c4.4xlarge).
Any instances you request as render nodes will be Spot instances, and while their performance will be exactly as advertised in the On-Demand Instances lists on the AWS website, their cost will be a fraction of the On-Demand instances per-hour price.
A Spot Fleet request can consist of one or more instance types and sizes. In the context of Spot Instances, every instance size of every instance type in every Availability Zone of the selected AWS Region represents a separate pool of spare capacity with its own current market price. The price cannot exceed the On-Demand instances price, and only varies gradually over the course of days and weeks to react to fluctuations in supply and demand.
Deadline can tap into all zones in the Region, so if you select 5 instance types and sizes in your Spot Fleet request, in regions that have 3 zones you would be looking for spare capacity in 15 different pools, but in N.Virginia with its 6 zones you could be sourcing from 30.
When intending to run just a couple of render nodes on an instance type that is likely to have enough spare capacity, selecting solely your top choice based on benchmark tests might be a valid approach.
However, in typical production the number of requested Spot Instances can range from hundreds to thousands. In that case, picking a single instance type and size can result in only a partial fulfillment of the Spot Fleet request, or frequent interruptions.
For that reason, it is highly advisable to list in your Spot Fleet request all reasonably priced instance families and sizes capable of processing the jobs in question. Then you can let AWS make decisions about the makeup of the resulting Fleet based on cost and availability.
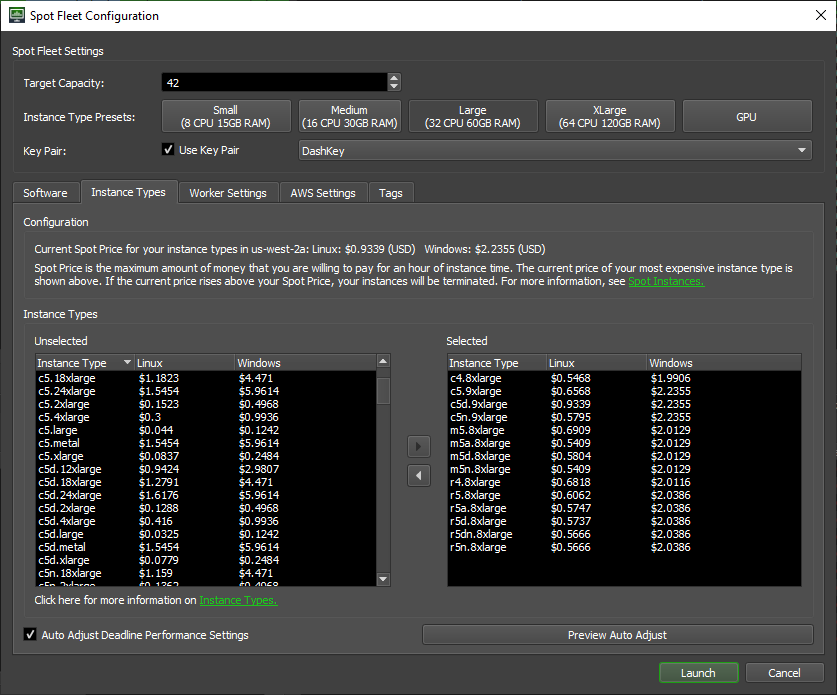
Since Spot Instance sizes within a type are based on the same underlying hardware, it follows that a single c5.18xlarge instance with 72 vCPUs uses the same hardware as two c5.9xlarge or nine c5.2xlarge instances. So it is natural that a zone will likely have a much larger number of smaller instances, and possibly a higher spare capacity.
If your workload does not fit in the 16 GiB of RAM of a c5.2xlarge, but does fit in the 32 GiB of the c5.4xlarge, then you should list c5.4xlarge, c5.9xlarge and c5.18xlarge when requesting a large number of Spot Instances.
While the smaller ones would obviously take longer to process a task, having a large number of them running in parallel will produce the same results for about the same price.
Internet Connection Bandwidth Considerations
A hybrid Deadline render farm relies on the internet connection between the on-premises and the AWS Cloud Infrastructure. It is logical that a higher bandwidth would increase the performance of the AWS Portal, in particular the Asset Synchronization portion.
For a Deadline Job to start rendering on a Spot Instance, it must first be able to find all required assets in the cloud. If the copying of the input assets takes an hour, the job will not render within that hour. Increasing the internet connection’s bandwidth by an order of magnitude (e.g. from 100 Mbps to 1 Gbps) would shorten the wait time in this example to around 6 minutes.
Comparing Linux and Windows EC2 Instances
Linux instances are billed by the second and there is no charge for the Operating System included in the price.
Windows instances are currently billed by the hour, and there is a fixed charge per vCPU for the Operating System.
EC2 Spot Instances running Linux can be up to 90% cheaper than their On-Demand instances price, but Windows Spot instances tend to be 2-4 times more expensive than their Linux equivalents because of the fixed OS cost that cannot be subject to rebates.
Deadline supports rendering in mixed Operating System environments and does all the necessary path remapping.
For that reason, even if you are submitting rendering jobs from a Windows workstation, it is highly recommended to use Linux instances on EC2 Spot Instances if the application and renderer are supported on Linux.
For example, you can submit an Autodesk Maya scene from a Windows workstation to render with the Redshift Technologies Redshift renderer, Arnold Render, or V-Ray Render on AWS. The Maya Amazon Machine Images (AMIs) supplied with Deadline run Linux and will have no problem handling the job.
Since the Windows instances are billed by the hour, creating and terminating multiple EC2 Spot Windows instances too often can negatively affect the price performance of your render farm.
For example, let’s say you launch a Spot Fleet with a Windows-based AMI and 100 instances. It renders a job with 100 frames that take 10 minutes; then you stop it, and 20 minutes later you launch another Spot Fleet request with the same Windows-based AMI, and 100 instances to render another job with 100 frames. The result: You will end up being charged for 200 hours within that hour.
In this case, it would be wiser to leave the Spot Fleet running for the whole hour to render both jobs with the first 100 machines, and get charged for only 100 hours—but this does not apply to Linux instances. In the above case, you would be charged for 100x10x60=60,000 seconds for the first Spot Fleet, and 60,000 more for the second for a total of 120,000 seconds—a huge savings over the 360,000 seconds in the case of the Windows OS. Note that these considerations apply only to user-initiated instance terminations.
The billing of EC2 Spot Instances interrupted by AWS is handled in a rather generous manner: If a Windows or Linux Spot Instance gets interrupted by AWS within the first hour after its launch, there will be no charge for that partial first hour.
This implies that if your render times are significantly shorter than an hour, an interruption within the first hour but after one or more tasks have completed successfully could lead to some “free” rendering.
For example, if you are rendering an animation where each frame takes 10 minutes, and a Spot Instance gets interrupted around the 50th minute mark having successfully rendered 4 frames before that, there would be no charge for that instance and those 4 frames would be essentially free of charge.
An interruption of an Amazon Linux Spot Instance after the first hour will lead to charges for all used seconds. If a Windows instance gets interrupted in any hour after the first hour, the full hours will be billed as usual, but there will be no charge for the partial hour of the interruption. So AWS-triggered interruptions might waste some time, but not necessarily money, making EC2 Spot Instances a great candidate for handling render tasks.
More information about Spot interruptions and billing can be found here.
Using Deadline Amazon Machine Images
Deadline provides a number of pre-built Amazon Machine Images featuring the applications and renderers officially supported by the AWS Portal system; they include Autodesk 3ds Max, Autodesk Maya, Autodesk Arnold, MAXON Cinema4D, SideFX Houdini Engine, Luxion KeyShot, Foundry Modo, Redshift Technologies Redshift, Chaos Group V-Ray etc.
These AMIs also have the Deadline Client software installed and pre-configured to work with AWS Portal. You can launch a Spot Fleet with EC2 instances running the software offered with these AMIs, or you can create custom AMIs based on them to update software versions, install additional third-party plugins, etc.
The Spot Fleet Configuration dialog of AWS Portal lists each combination of digital content creation application and renderer as a separate entry. This allows you to start multiple Fleets and to render using different tools.
However, behind the scenes, some of these entries are backed by the same Amazon Machine Image. For example, the Autodesk Maya with Arnold Render or V-Ray Render, or the Autodesk Arnold Stand-alone and Chaos Group V-Ray Stand-alone all launch using the same AMI.
Similarly, Maya with Redshift and Redshift Stand-alone share a Linux-based AMI, as do 3ds Max with Arnold and 3ds Max with V-Ray which share a Windows-based AMI. This means that if you created a Spot Fleet to render a Maya Job using Arnold, but have other Deadline Jobs on the queue that require Arnold Stand-alone, V-Ray Stand-alone, or Maya with V-Ray rendering, the same Fleet could handle them all without the need to launch and manage separate Fleets. This can save time setting up and waiting for the Fleet to start, and save money too—especially in the case of Windows instances that can introduce extra cost due to the per-hour billing.
Using Stand-alone Renderers
Some 3D applications such as Autodesk 3ds Max and Autodesk Maya currently require a license to be used on EC2 render nodes (unless Cloud Rights are available through Autodesk Subscription Benefits—read a relevant FAQ here). The fixed cost for running 3ds MaxIO or MayaIO—the headless versions designed for cloud rendering—is $0.18 per node per hour.
It would be nice to avoid incurring additional cost. If you do not have an active Autodesk Subscription, a possible workaround would be to submit the scenes for rendering in the stand-alone version of the relevant renderer, assuming it supports this workflow. Arnold, Mental Ray, Octane, Redshift, Renderman, and V-Ray all support command line rendering via a dedicated intermediate scene description format—.ASS, .MI, .ORBX, .RS, .RIB, .VRSCENE. Stand-alone renderers also start faster, increasing the overall rendering performance of Deadline.
The main drawback is that depending on the scene content, the scene description files can grow very large (especially if procedural content is baked to an explicit representation). Even if the export was performed by a Deadline Job running on AWS to avoid the asset synchronization of a huge scene description from the local network to the cloud, the actual export time could negate any benefits of running a stand-alone renderer.
Other drawbacks can include lack of support for third party plugins, and inconsistent scene representation when non-native components are used (particularly in the case of 3ds Max V-Ray vs. V-Ray Stand-alone).
In other words, if exporting a scene description and rendering in a stand-alone renderer fits your particular workflow and the benefits outweigh the drawbacks, it can be a useful way to improve performance and reduce rendering costs.
Conclusion
Getting the best performance and the lowest cost of ownership from your local, hybrid, or AWS cloud Deadline render farm requires you to consider and balance a large number of factors. Measuring the real-world performance of your hardware, picking the cloud instances with the best cost-performance profile, selecting the right software for the job, and using the Deadline features designed to improve the parallel processing of Tasks and Jobs are steps that can help you optimize your farm, and deliver your projects on time and below budget.