Front-End Web & Mobile
Build a Conversational AI app to Interact with AWS using AWS Amplify
Developing a conversational application involves multiple complex components, such as authentication workflows, API interfaces, data management, and intent fulfilment business logic. These elements can be challenging to integrate and set up properly, especially for developers who are new to building conversational applications or who may not have extensive experience with AWS services.
This blog post showcases building a conversational application by harnessing the power of AWS Amplify and seamlessly integrating it with Amazon Lex. The post focuses on establishing the essential backend components, such as authentication workflows, API interfaces, data management, and intent fulfilment business logic, providing a practical solution for seamlessly building conversational applications.
Solution overview
The solution demonstrates an advanced virtual assistant application that empowers users to interact with AWS services using natural language queries or utterances. This virtual assistant acts as a powerful conversational AI, utilizing Lex for Natural Language Understanding (NLU).
You can automate tasks within AWS accounts by submitting simple queries to the virtual assistant. With Amplify’s extensive set of tools and services, you can easily create a robust full-stack web application, focusing on the core features of the virtual assistant.
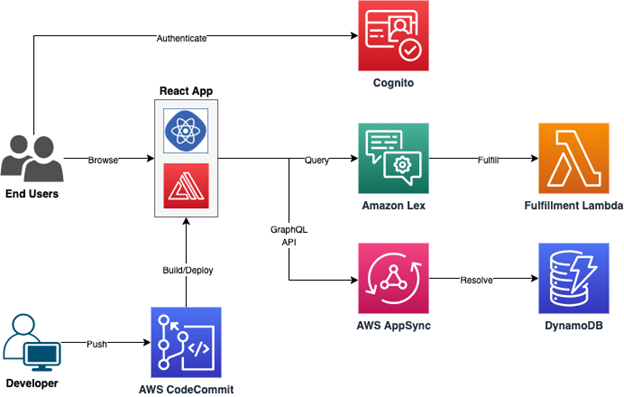
Figure 1: Application Architecture
The solution consists of the following components (Figure 1):
- React framework: React’s component-based architecture simplifies the creation of UI elements, allowing developers to build reusable and modular components for the virtual assistant’s interface. Its ability to manage state ensures a seamless user experience during interactions with the assistant.
- Amplify: Amplify provides a set of tools and services that streamline the development process, enabling developers to quickly connect the front-end to essential AWS services such as authentication and APIs. This simplifies the implementation of features like user management and data access control.
- AWS AppSync: AWS AppSync simplifies GraphQL API development, offering a single endpoint for querying the backend. This allows the virtual assistant to securely interact with backend services, manage conversations, and retrieve user session data and responses effectively.
- Amazon DynamoDB: DynamoDB provides a scalable and flexible data storage solution for the virtual assistant’s backend. It allows efficient data retrieval and persistence, ensuring that user interactions are saved for later usage and facilitating a seamless conversation history.
- Amazon Lex: With Lex, developers can create custom conversational interfaces by defining intents, slots, and sample utterances. It enables the virtual assistant to understand user queries and map them to specific intents, making it capable of fulfilling user requests and automating AWS tasks.
- AWS Lambda: AWS Lambda handles the intent fulfillment logic, executing actions based on user queries detected by Lex. It allows for scalable execution of backend logic in response to user requests. It empowers the virtual assistant to interact with various AWS services on behalf of users, automating AWS operations efficiently.
You can find the open-source code and deployment instructions in this GitHub repository. With this solution, you can automate various workflows or operations in AWS accounts by submitting simple queries/utterances such as:
-
- Launch 2 Red Hat instances on t3 micro
- Find all Red Hat instances
- Are there any instances deployed to a public subnet?
- Are there any wide-open security group rules?
- Modify security group rules to allow traffic from 10.11.12.13
- List all my S3 buckets
- Search for “ppt” in bucket XYZ
Using natural language simplifies AWS usage for non-technical AWS users who need to interact with various AWS services, as they may not have expertise or familiarity with Command Line Interface (CLI) tools or Software Development Kits (SDK).
More importantly, you can use this application as a guide on how to leverage Amplify to build any other kind of assistant-powered web application.
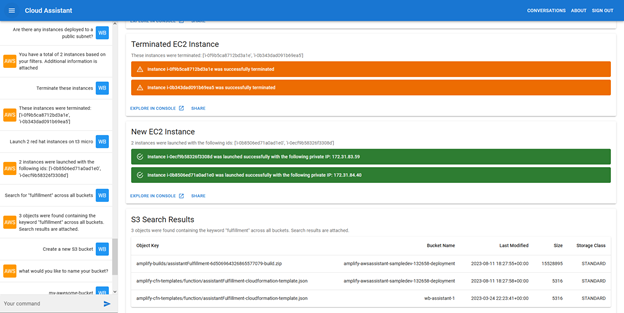
Figure 2: Application screenshot showing a user submitting queries to the assistant
Solution Components
The solution comprises several key components that collectively form a powerful virtual assistant capable of interacting with AWS services. Following are the components and their benefits:
Front-end
The front-end is a key component of any interactive conversational web application. Since we use the create-react-app Node package to set up the project structure and prepare the development environment with the latest JavaScript feature. The main App component resides in the App.js file which imports relevant React components and configures the Amplify backend. The App component consists of a basic React Router with a few key routes to other React components, including:
- Conversations component: This component lists the current user’s conversations with the assistant and allows the user to create a new conversation or delete an existing conversation. A Material UI card represents each conversation and contains a description of the conversation and a few action buttons.
- Interact component: This component highlights a specific user conversation and allows the user to view the conversation history as well as submit new queries/utterances to the assistant. The component also shows responses received from the assistant, which can take the form of text, alerts, tables, or others (Figure 2).
Backend – Authentication
We use Amplify to create an Amazon Cognito user pool. The user pool serves as a fully-managed user directory and handles user registration, authentication, account recovery, and other operations out of the box. To add authentication to the application, we simply use the “amplify add auth” command and wrap the App component’s export with the “withAuthenticator” component. You can find more details here.
Backend – GraphQL API
The GraphQL API, powered by AppSync and DynamoDB, enables efficient data management and communication between the application’s front-end and back-end. Users should also be able to resume previous conversations or retrieve previous answers/data returned by the assistant. To enable these capabilities, we use Amplify to create an AppSync GraphQL API backed by DynamoDB tables. All we need to do is run the “amplify add api” command and then define a GraphQL schema. Once deployed, Amplify will automatically transform the schema into a fully functioning GraphQL API.
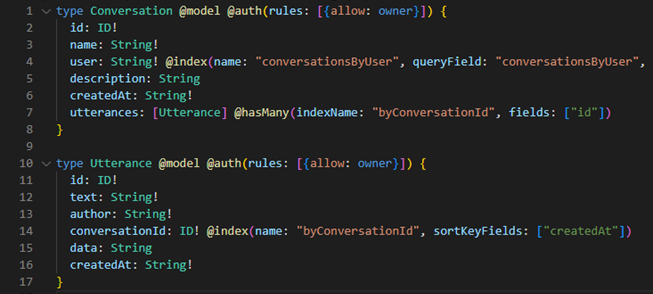
Figure 3: GraphQL API Schema
GraphQL schema – models
Since the API persists user conversation data (conversations started by the user and their attributes), and utterance data (actual queries submitted by users or responses generated by the assistant), you can model the application with two model types: Conversation type and Utterance type. Amplify maps each model type to its own DynamoDB table. The GraphQL schema below shows how to define these two model types using the @model directive (Figure 3).
GraphQL schema – attributes & relationships
The schema also allows you to define a primary key in addition to other attributes for each model type. The primary key for both model types consists of an automatically generated “id” field. Examples of additional attributes for the conversation model include the conversation name and description, the user who created the conversation, and a createdAt timestamp (Figure 3). Since a conversation consists of many utterances, we need a way to model this relationship in our schema. We do this by using the @hasMany directive which creates a one-directional one-to-many relationship between the Conversation model and the Utterance model (Figure 3). Using this relationship, you can now query the API for conversation data and optionally include the list of utterances contained in the conversation.
GraphQL schema – access patterns
You need to make sure API is able to accommodate critical application access patterns. For example, the “Conversations” React component described above requires you to display a list of conversations specific to that user. To do this, you can use the @index directive to configure a secondary index on the “user” attribute of the Conversation model (Figure 3).
GraphQL schema – authorization rules
You need to add an authorization layer to protect user data and allow a per-user data access. Given the sensitive nature of this application’s data, DynamoDB table records (of either model defined above) should only be accessible by their respective owners. To do this, we use the @auth directive for each model defined in the schema and specify “allow:owner” as the authorization strategy (Figure 3). This authorization strategy means that each signed-in user (also known as owner) can only create/read/update/delete their own conversations or utterances. Behind the scenes, Amplify leverages the Cognito user pool created previously to store an owner field containing the record owner’s identity at the time of record creation. This owner field is later verified against the claims in the user’s JWT token before authorizing access.
Application Backend: Amazon Lex bot
We use Lex to create a bot that can identify the intent associated with user requests. First, we create a list of desired intents and slots. For each intent, we provide a list of example utterances to train the bot to recognize the intent. Below are a few example intents defined as part of this bot. For a complete list, see GitHub repository.
- EC2-list: lists instances based on different types of user filters (type, ami, subnet type)
- EC2-create: creates instances based on different configurations (count, type, ami)
- S3-search: search for objects matching a specific pattern in bucket or multiple buckets
- S3-copy-to-bucket: copy objects identified from search results to new bucket
- Sg-rule-list: list unrestricted security group rules
When a user’s intent is successfully detected, the bot utilizes a custom Lambda function to carry out intent fulfillment. This Lambda function serves as the application’s backend for housing the business logic to handle user queries.
For example, if a user submits the query “Find all Red Hat instances,” the Lex bot identifies the intent as “EC2-list” and then proceeds to invoke the Lambda function. Within the Lambda function, custom logic is implemented to identify and return a list of Amazon Elastic Compute Cloud (Amazon EC2) instances that match the criteria provided by the user. The flexibility of the Lambda function allows you to customize the code to fulfill specific custom intents as needed.
Hosting the application
To host the application, we recommend using AWS Amplify Hosting as it enables full-stack CI/CD workflows out of the box. This allows you to continuously deploy front-end and backend changes in a single workflow in response to your code commits. To do this, you first have to connect git branch through the Amplify console. Alternatively, you can host the application with manual deployments using the amplify publish command which builds and publishes both the backend and the frontend of the project.
Building and deploying the app
You can find a list of pre-requisites, detailed deployment steps, example usage commands, and cleanup instructions in the GitHub repository.
Conclusion
In this post, we demonstrated how to use Amplify to build an assistant-powered web application, featuring a Lex chatbot, Lambda for requests fulfillment, a GraphQL API to manage data, and Cognito for authentication. Specifically, we built a “Cloud Assistant” application allowing users to interact with AWS using natural language and automate AWS operations/configurations. While this particular application helps flatten the learning curve for new AWS users, it also demonstrates the utility and value of building assistant-powered web applications in general.
For more information on creating full-stack web and mobile applications with Amplify and the various tools and features it provides, please visit the AWS Amplify.