Networking & Content Delivery
Understanding dynamic origin modification in Amazon CloudFront – Part 1
In the modern digital landscape, our lives are inescapably dominated by screens and browsers. From global product launches to flash sales and virtual concerts, events that once drew crowds to physical venues now drive millions of users to digital platforms simultaneously. The rapid rise of digital-first experiences has made the need to dynamically adjust content delivery across globally distributed origins a critical capability for organizations. Enabling dynamic origin modification allows organizations to provide reliable, high-performance access to online resources, even during periods of high traffic or rapid changes in usage patterns.
Amazon CloudFront enables organizations to deliver content globally with low latency and high transfer speeds through its extensive network of edge locations. Each CloudFront distribution can be configured to fetch content from one or more origins, such as Amazon S3 buckets, Application Load Balancers (ALBs), or custom origins. CloudFront provides support for default origins and path-based routing, but for more sophisticated routing needs, it offers powerful edge computing capabilities through Lambda@Edge and CloudFront Functions. Organizations can intercept and dynamically modify origin requests at the edge to implement dynamic origin selection directly within the CloudFront edge network, which removes the need for a traditional proxy at the origin.
This is part one of a two-part series. In this post, we review the options provided by CloudFront to implement dynamic origin selection, using examples, reference architectures, and implementation considerations. Part two of this series focuses on how to implement these solutions with code references.
Use cases
The edge-based origin modification pattern is highly scalable and capable of supporting millions of requests per second. In this section we cover a few use-cases where dynamic origin modification would be beneficial.
Geo-based routing
Global businesses can use CloudFront Functions to route users to the origin server closest to their location. This reduces latency and improves the user experience. However, it can also shift traffic between those endpoints to manage regional loads, or direct traffic away from overloaded or failing deployments.
User context-based routing
Retail and Media & Entertainment platforms can use CloudFront Functions to route requests based on user profiles or subscription tiers. They can then serve personalized experiences or prioritize the experience of customers on their paid tiers over freemium users. For example, a live sports streaming platform can route premium subscribers to their nearest optimal origin, but during periods of congestion can route free or advertisement supported viewing tiers to less congested regions.
Cell-based routing
Globally distributed, cell-based architectures can use the CloudFront Functions dynamic origin routing to intelligently direct traffic to the appropriate regional endpoints and resources based the information contained in the HTTP request. In turn, users can maintain autonomous, high-performing “cells” while still providing a seamless experience for their customers, regardless of their location.
Strangler-fig routing
Users with a mix of on-premises and cloud-hosted infrastructure can use CloudFront Functions to dynamically route requests between these different origin types during the migration journey following a strangler-fig pattern. They can use the performance and scalability of the cloud while still using existing on-premises investments, creating a hybrid architecture that is optimized for their specific needs.
Microservices routing
Users with multi-tenant architectures looking to route across microservices from the same domain name can now use CloudFront Functions to dynamically select the origin without having to rely on pre-configured cache behaviors and avoid CORS issues.
Implementation options
CloudFront provides two options for implementing custom code at edge: Lambda@Edge and CloudFront Functions. Each has its own strengths, which makes the choice dependent on your specific use case. This document compares the two options in detail across varying features. Specific to dynamic origin selection, the following are some of the defining features that help you decide which option would work best for your use-case.
Feature |
CloudFront Functions |
Lambda@Edge |
| How is content delivered? | Using CloudFront POPs | Using Regional edge caches closest to POPs |
| Lookup a key-value (KV) store to figure client routing | Support for edge-based CloudFront KeyValueStore
[*Note the KVS limits] |
Look up key-value pairs from a database in Amazon Web Services (AWS) Region (for example Amazon DynamoDB) |
| Event sources that can be accessed or modified | Viewer request, viewer response | Viewer request, viewer response, origin Request, origin response |
| Which parameters can be used to configure routing rules? | Header parameters only | Header parameters, request payload parameters |
| Typical use-cases to be considered |
|
|
| Scale | Up to millions of requests per second | Up to 10,000 requests per second per region |
| Cost | Lower per-execution costs than Lambda@Edge, but executes on every request | Executes on cache misses only |
Reference architectures
The following two scenarios describe potential reference architectures.
Sample scenario 1:
Consider a scenario where a major global e-commerce platform needs to implement dynamic origin routing of client requests based on the customer’s subscription tier or membership type—parameters that would be available as a header or cookie.
The following architecture showcases how this can be achieved by using CloudFront Functions and KeyValueStore.
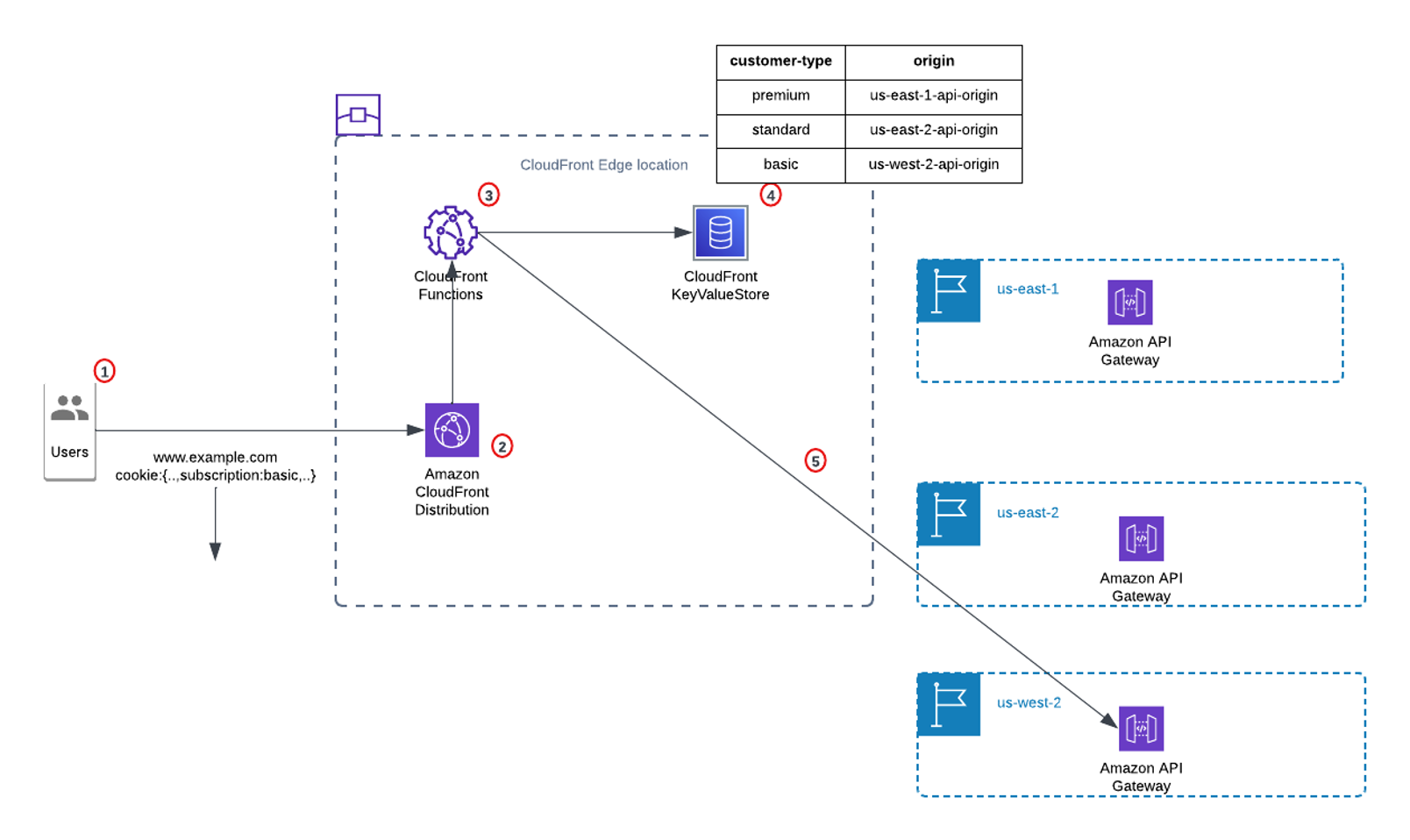
Figure 1: Edge Routing using Amazon CloudFront Functions
Solution overview:
- The client sends an incoming request to www.example.com with a cookie param
subscription:basic - The request is routed through DNS to the nearest CloudFront POP (edge location) that can best serve the request.
- The request is routed to the nearest CloudFront edge location.
- The CloudFront Function attached to the distribution looks up the
subscriptionin CloudFront KeyValueStore. - CloudFront KeyValueStore has a mapping of
subscription=basicto origin (us-west-2-api-originin this case). - CloudFront Function updates the origin based on the correct client region and forwards the request.
Sample scenario 2:
Consider a scenario of a multi-tenant software as a service (SaaS) application that needs to route its users to different customer-specific backends based on account information stored in DynamoDB. The account information is a complex key of varying parameters in the request payload.
The following architecture showcases how this can be achieved by using Lambda@Edge and DynamoDB.
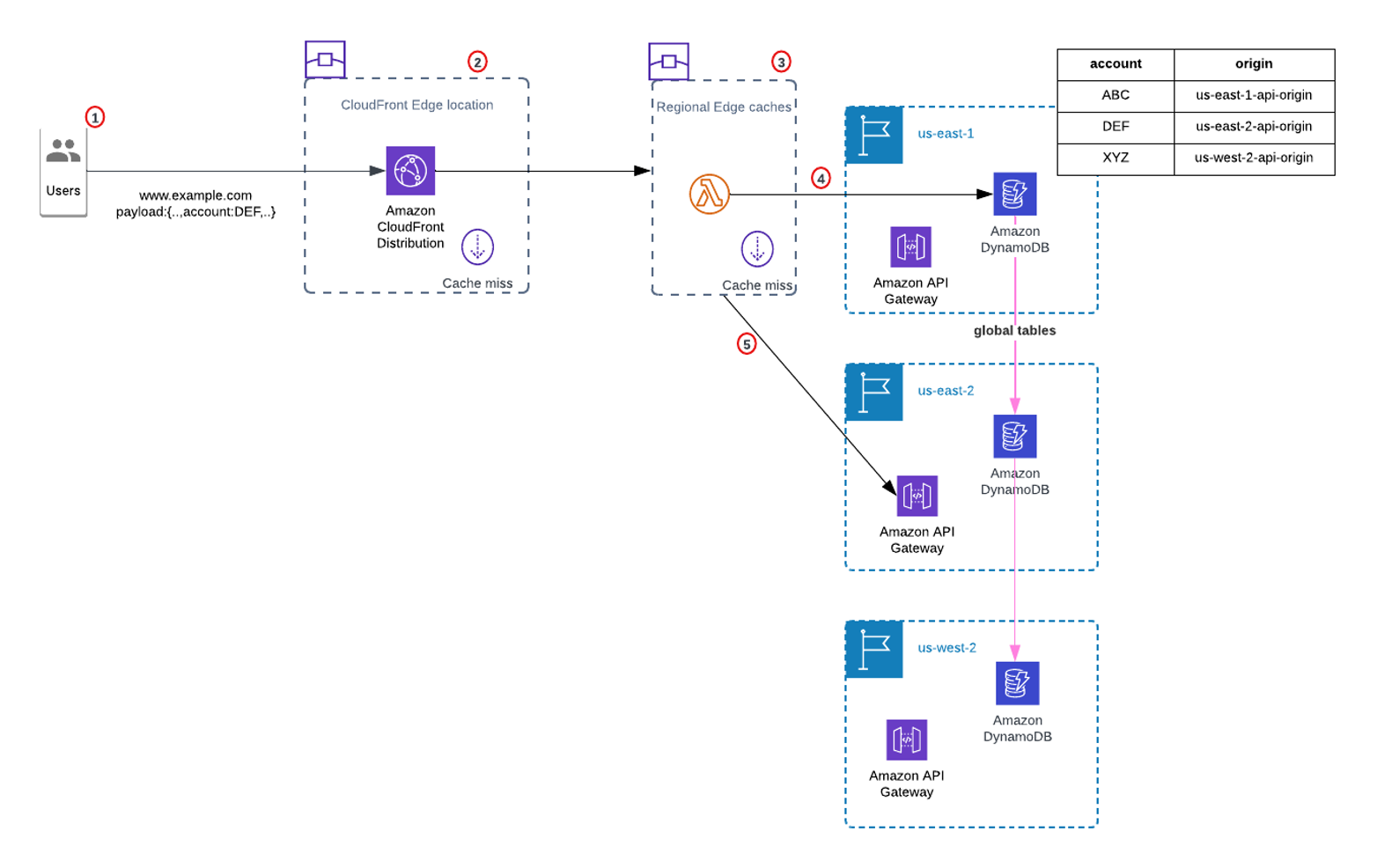
Figure 2: Edge Routing using Lambda@Edge
Solution overview:
- The client sends an incoming request to www.example.com with account information in payload.
- The request is routed through DNS to the nearest CloudFront POP (edge location) that can best serve the request.
- The edge forwards the request to a regional edge cache (REC). The regional edge cache triggers Lambda@Edge at the origin request event in case of cache miss.
- The Lambda@Edge function dynamically selects the appropriate origin based on customer payload and Dynamo DB lookup call.
- Lambda@Edge forwards the request to the selected origin.
Use CloudFront Saas Manager to implement multi-tenant architectures with a single CloudFront distribution across multiple users/organizations.
Summary
AWS is continuing to enhance Amazon CloudFront by providing clearer and more flexible solutions for users looking to implement dynamic routing at edge. You can use the options discussed in this post with CloudFront Functions and Lambda@Edge to implement custom routing rules at the edge in a latency-sensitive and high-performance way and using the AWS global network of edge locations.
Start using the new CloudFront capabilities to build sophisticated, context-aware request routing that adapts to your evolving business and technical requirements today. The Part 2 of this series focuses on how to implement these solutions with code references.
About the authors

Aish Gopalan
Aish Gopalan is a Principal Solutions Architect at AWS, providing transformative architectural guidance to enterprise customers. She specializes in transforming customer journey focusing on resilient and scalable cloud operating model. Primarily an individual contributor, she has worn multiple hats ranging from Solutions Architect, Application Architect, Cloud Transformation Delivery Lead and Developer in her 19 year+ software journey.

Nikhil Patne
Nikhil is a Senior Technical Account Manager at AWS, providing strategic technical guidance to Healthcare & Life Sciences customers. He specializes in Content Delivery Networks, Edge Computing solutions, and Cloud Networking architectures helping customers architect cost-effective, high-performance systems that strengthen security postures, build resilient infrastructures, and accelerate digital transformation outcomes.

Deepak Garg
Deepak is a Solutions Architect at AWS, where he helps customers design and implement cloud solutions. With experience in Content Delivery Networks and Telecommunications, he is passionate about diving deep into AWS services and enabling customers to achieve their cloud transformation goals.