How was this content?
- Learn
- Automating unstructured data processing with Amazon SageMaker
Automating unstructured data processing with Amazon SageMaker
by Nikhil Dinesh, Head of Startup Business Development, DACH Region, AWS, and Sayon Saha, Machine Learning Specialist Solutions Architect, AWS
Unstructured data such as images, video, and text that appear on E-commerce product listings have a significant impact on conversion rate. A study by eBay research found that super-sized images can increase conversion by 15.3%, with other factors such as photo count and item condition playing a significant role. Marketplaces and sellers must optimize conversion based on an open-ended set of factors determined by marketing teams. The use of data science and machine learning (ML) to address this problem is not new: AWS has created several services to help with the undifferentiated aspects of ML, such as Amazon Rekognition (for images and video), Amazon Comprehend (for text), Amazon SageMaker (for model development and deployment), and Amazon SageMaker GroundTruth (for data annotation).
Super.AI, a Berlin-based startup, believes that there is a significant opportunity to assemble these building blocks in the right way and with the right user experience toward what they call Unstructured Data Processing (UDP) in various industries. According to Gartner, 80% of data in a typical enterprise is unstructured. Super.AI’s platform extracts actionable information from unstructured data, allowing enterprises to automate complex business processes. According to Brad Cordova, serial AI entrepreneur and Founder/CEO of super.AI: “Customers across E-commerce, TIC (Testing, Inspection, and Certification) Services, Insurance, Healthcare, Manufacturing, and Agriculture are using super.AI platform to automate complex uses cases such a product listing quality assessment, visual inspection, vehicle damage detection, and crop yield assessment. Our customers are achieving significant ROI via reduced time and costs, fewer errors, and improved customer satisfaction.”
This piece will show you where data ingestion, pre-labeling, the active learning pipeline, and real-time assisted labeling falls in the super.AI architecture on AWS, followed by a discussion of the goals, risks, and where we see opportunities for improvement.
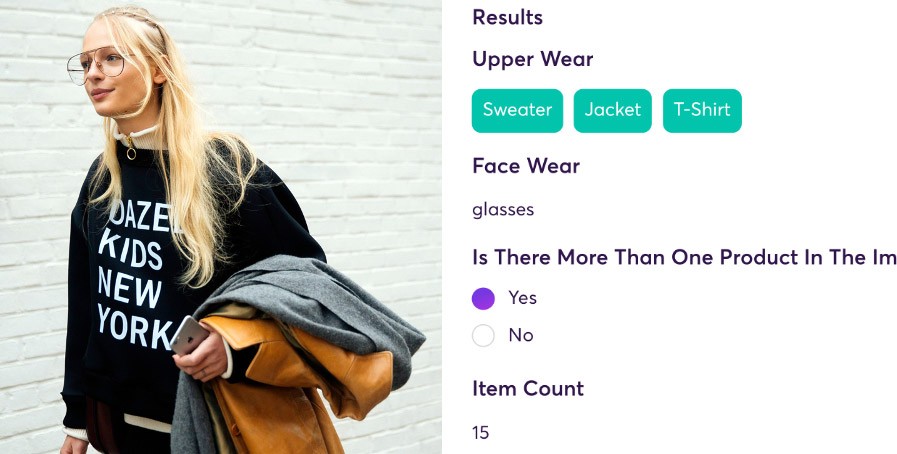

Super.AI’s Unstructured Data Processing Platform
The super.AI platform helps customers to transform processes involving unstructured data such as images, videos, text, documents, and audio and automate them using a combination of AI, software, and humans. This super.AI Product Image Categorization Demo shows how super.AI product image categorization can help retailers increase website conversations.
Active Learning and Pre-Labels
Super.AI customers requested a more efficient, highly accurate labeling mechanism. So, they recently released a new feature called Active Learning and Pre-labeling, where the pipeline pre-processes data points using an ML model running on SageMaker. This solution prioritizes labeling data points that are most useful to the model. The ML model is run over all the uploaded data points to generate an output, e.g., a confidence score, used to serve the data points in a prioritized way. Pre-labels are generated where possible and served to the human labeler for review or editing.
The pipeline then scales with demand. Customers can upload data via API (or UI) and apply multiple models for active learning and pre-labeling. Customers can choose from a selection of models provided by super.AI or bring their own model. Super.AI uses the confidence score generated by the ML model to prioritize the data points and serve them more efficiently. Where necessary, human labelers can use pre-labels generated by the system to label the data by hand accurately.
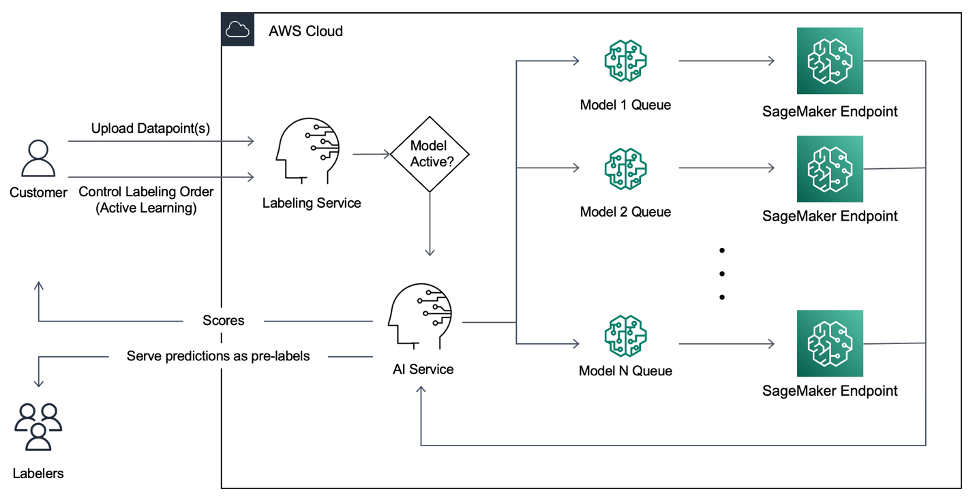
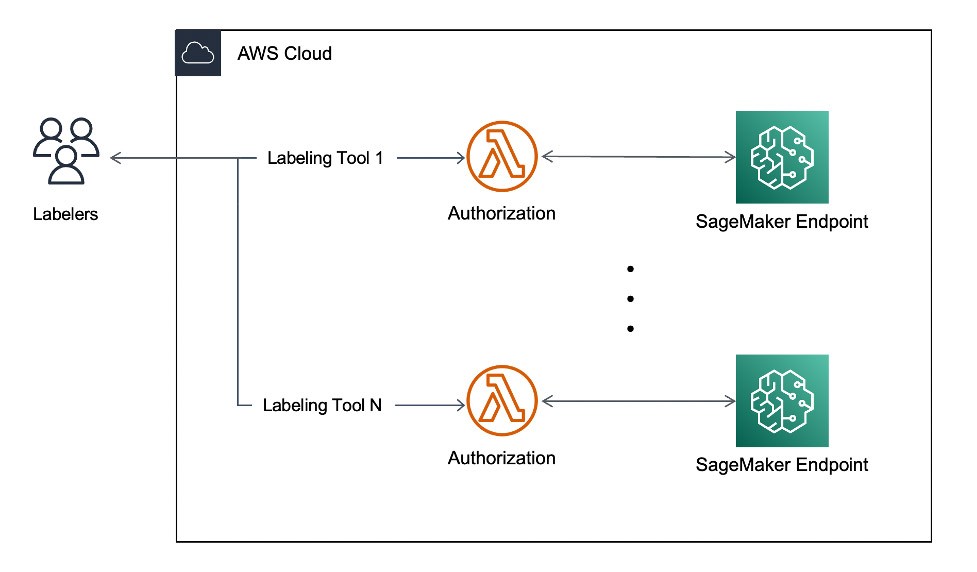
Real-time Assisted Labeling
The platform leverages a serverless architecture with SageMaker. The customers must have this service in real-time for labeling their images. The tool leverages AWS Lambda in combination with Amazon SageMaker Endpoints to serve concurrent requests in real-time with response time under 10 seconds. You can explore the Image tagging application from super.AI in their online documentation.
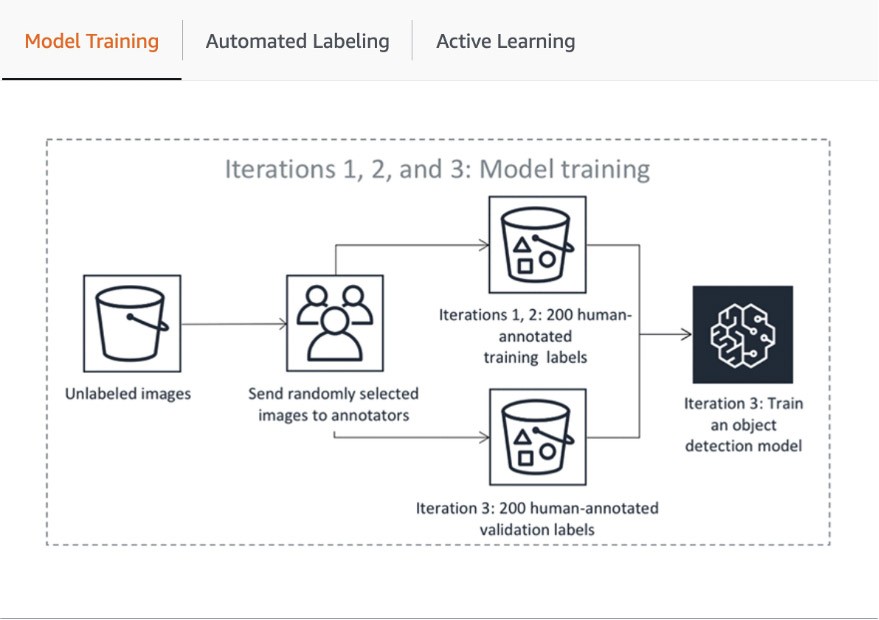
Building an Active Learning Pipeline with Amazon SageMaker GroundTruth
SageMaker Ground Truth is a managed data labeling service to build large-scale accurately labeled ML datasets with several workforce options. Along with the various built-in and custom data-labeling workflows for text, image, videos, and 3D point clouds, it allows you to build an automated data labeling pipeline with active learning by automatically annotating objects with relevant ML models and assigning objects with lower confidence for human annotation.
The first step of the pipeline includes SageMaker Ground Truth sending a random sample of datasets for human annotation to train and validate the model used for auto-labeling. The trained model’s outputs confidence score and quality metric in the validation data are compared against the threshold for deciding on the quality labels for annotating the rest of the dataset. Depending on whether the confidence score meets the desired threshold, either an object is considered auto-labeled or sent to the human workforce for annotation. These annotations, in turn, are used to update and improve the auto-labeling model. This active learning pipeline continues to process until the required dataset is fully labeled or another stopping condition is met (Learn more in this article to Automate Data Labeling). The Active Learning process is illustrated in the following diagram:
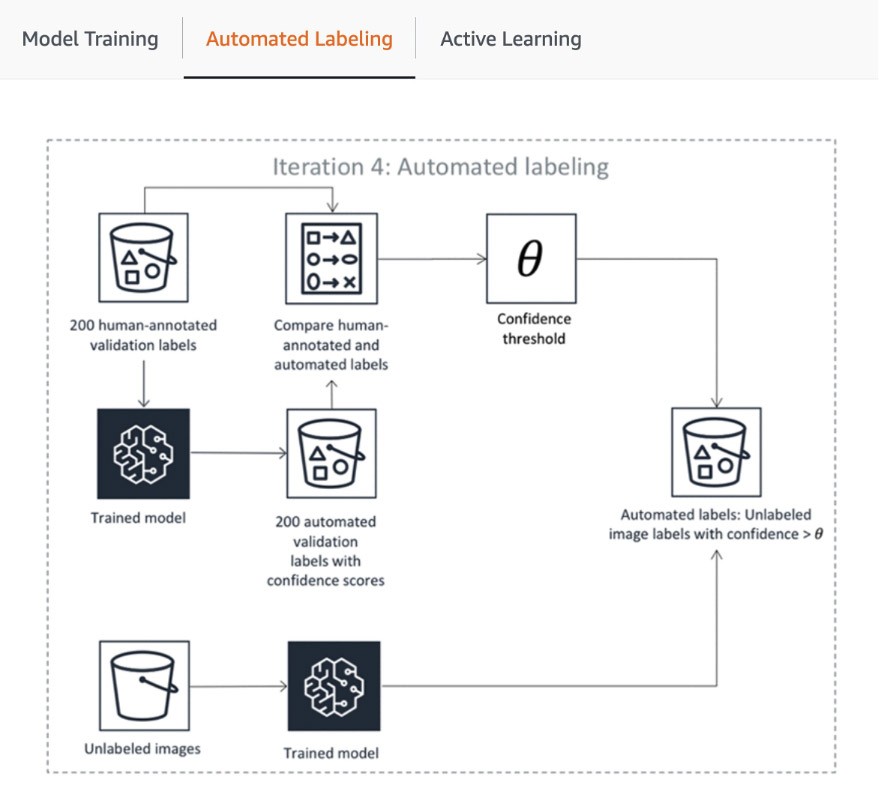
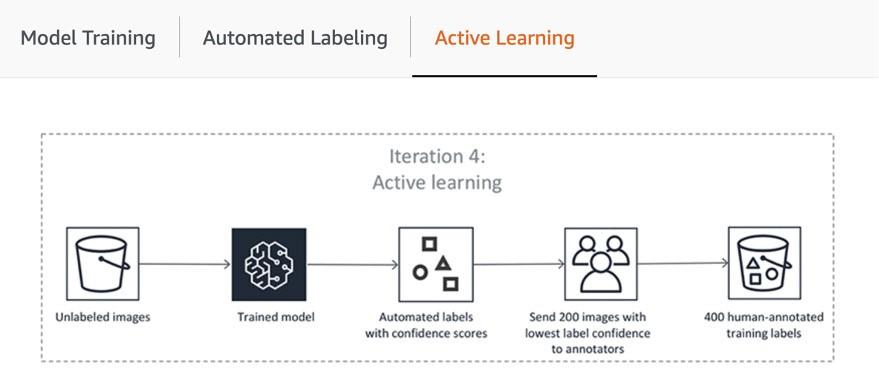
While many AWS customers simply use its built-in ML models, SageMaker Ground Truth allows you to bring your own if you have a custom use case. You can read more about it in the blog “Bring Your Own Model for Amazon SageMaker Labeling Workflows with Active Learning.”
The active learning technique makes the data labeling process much faster by identifying the subset of data that your labelers should label. It also reduces the workforce cost significantly by keeping the accuracy of annotations high. You can read about an example use-case of object detection job with automated data labeling in the blog “Annotate Data for Less with Amazon SageMaker Ground Truth and Automated Data Labeling.”
Conclusion
For the last few years, robotic process automation (RPA) has been one of the fastest-growing software categories as enterprises strive to achieve digital transformation. However, 80% of the enterprise data is unstructured and off-limits to automation. Emerging Unstructured Data Processing solutions from companies like super.AI that leverage AWS ML services are helping enterprises greatly expand the scope of automation by extracting actionable information from unstructured data – images, videos, audio, documents, and text. Such platforms can address a wide range of uses case from visual inspection to the online product listing quality assessment with minimal human intervention. Early adapters of such platforms are gaining a competitive advantage which drive down costs, reduce errors, and deliver a differentiated customer experience.

AWS Editorial Team
The AWS Startups Content Marketing Team collaborates with startups of all sizes and across all sectors to deliver exceptional content that educates, entertains, and inspires.
How was this content?