Comment a été ce contenu ?
- Apprendre
- Automatisation du traitement des données non structurées avec Amazon SageMaker
Automatisation du traitement des données non structurées avec Amazon SageMaker
par Nikhil Dinesh, responsable du développement commercial des start-ups, région DACH, AWS, et Sayon Saha, architecte de solutions spécialiste du machine learning, AWS
Les données non structurées comme les images, les vidéos et le texte contenus dans les listes de produits proposés dans le cadre du commerce électronique ont un impact significatif sur le taux de conversion. Une étude d'eBay research a révélé que les images de taille supérieure peuvent augmenter la conversion de 15,3 %, d'autres facteurs comme le nombre de photos et l'état de l'article jouant un rôle important. Les plateformes de marché et les vendeurs doivent optimiser la conversion en fonction d'un ensemble non limitatif de facteurs déterminés par les équipes marketing. L'utilisation de la science des données et du machine learning (ML) pour résoudre ce problème n'est pas une nouveauté : AWS a créé plusieurs services pour faciliter les aspects hétérogènes du ML, notamment Amazon Rekognition (pour les images et les vidéos), Amazon Comprehend (pour le texte), Amazon SageMaker (pour le développement et le déploiement de modèles), et Amazon SageMaker GroundTruth (pour l'annotation des données).
Super.AI, une start-up basée à Berlin, met en lumière l'opportunité d'assembler des blocs de conception intelligemment et avec une expérience utilisateur adéquate dans le cadre du traitement de données non structurées (UDP) dans divers secteurs. Selon Gartner, 80 % des données d'une entreprise type sont non structurées. La plateforme de Super.AI extrait des informations exploitables des données non structurées, ce qui permet aux entreprises d'automatiser des processus commerciaux complexes. Selon Brad Cordova, entrepreneur spécialisé dans l'IA en série et fondateur/PDG de Super.AI : « Les clients des secteurs du commerce électronique, des services TIC (test, inspection et certification), de l'assurance, de la santé, de la fabrication et de l'agriculture utilisent la plateforme Super.AI pour automatiser des cas d'utilisation complexes comme l'évaluation de la qualité des listes de produits, l'inspection visuelle, la détection des dommages causés aux véhicules et l'évaluation du rendement des récoltes. Nos clients obtiennent un retour sur investissement significatif grâce à la réduction des délais et des coûts, à la diminution du nombre d'erreurs et à l'amélioration de la satisfaction client. »
Cet article présente le rôle de l'ingestion des données, du pré-étiquetage, du pipeline d'apprentissage actif et de l'étiquetage assisté en temps réel dans l'architecture de Super.AI sur AWS, suivi d'une discussion sur les objectifs, les risques et les opportunités d'amélioration que nous entrevoyons.
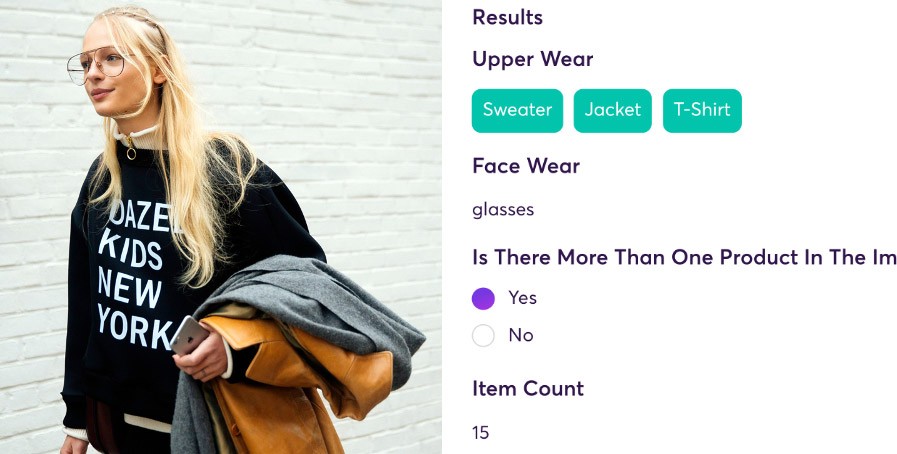

Plateforme de traitement de données non structurées de Super.AI
La plateforme Super.AI assiste les clients dans la transformation des processus impliquant des données non structurées comme les images, les vidéos, le texte, les documents et l'audio, et dans leur automatisation en utilisant une combinaison d'IA, de logiciels et d'humains. Cette démonstration de catégorisation d'images de produits Super.AI révèle comment la catégorisation d'images de produits Super.AI peut aider les détaillants à augmenter les conversations sur le site Web.
Apprentissage actif et pré-étiquettes
Les clients de Super.AI ont souhaité exploiter un mécanisme d'étiquetage plus efficace et plus précis. Super.AI a donc récemment lancé une nouvelle fonctionnalité appelée Apprentissage actif et pré-étiquetage, dans laquelle le pipeline prétraite les points de données à l'aide d'un modèle de ML fonctionnant sur SageMaker. Cette solution donne la priorité à l'étiquetage des points de données les plus utiles au modèle. Le modèle de ML est exécuté sur tous les points de données téléchargés pour générer un résultat, par exemple un score de confiance, utilisé pour servir les points de données de manière prioritaire. Des pré-étiquettes sont générées dans la mesure du possible et transmises à l'étiqueteur humain pour examen ou modification.
Le pipeline se met alors à l'échelle en fonction de la demande. Les clients peuvent télécharger des données par le biais de l'API (ou de l'interface utilisateur) et appliquer plusieurs modèles pour l'apprentissage actif et le pré-étiquetage. Les clients peuvent choisir parmi une sélection de modèles fournis par Super.AI ou apporter leur propre modèle. Super.AI utilise le score de confiance généré par le modèle de ML pour hiérarchiser les points de données et les servir plus efficacement. Le cas échéant, les étiqueteurs humains peuvent utiliser les pré-étiquettes générées par le système pour étiqueter les données à la main avec précision.
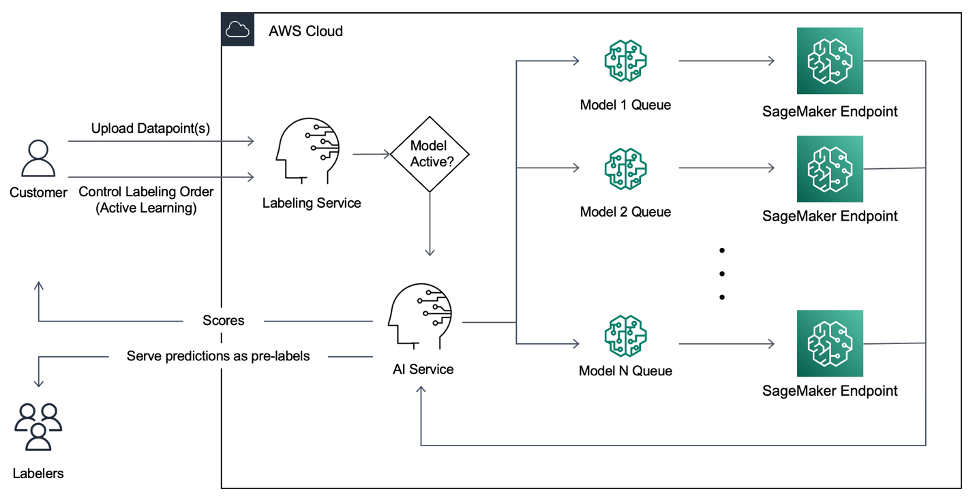
Étiquetage assisté en temps réel
La plateforme s'appuie sur une architecture sans serveur avec SageMaker. Les clients doivent disposer de ce service en temps réel pour étiqueter leurs images. L'outil exploite AWS Lambda et Amazon SageMaker Endpoints pour répondre aux demandes concurrentes en temps réel avec un temps de réponse inférieur à 10 secondes. Vous pouvez explorer l'application d'étiquetage d'images de Super.AI dans sa documentation en ligne.
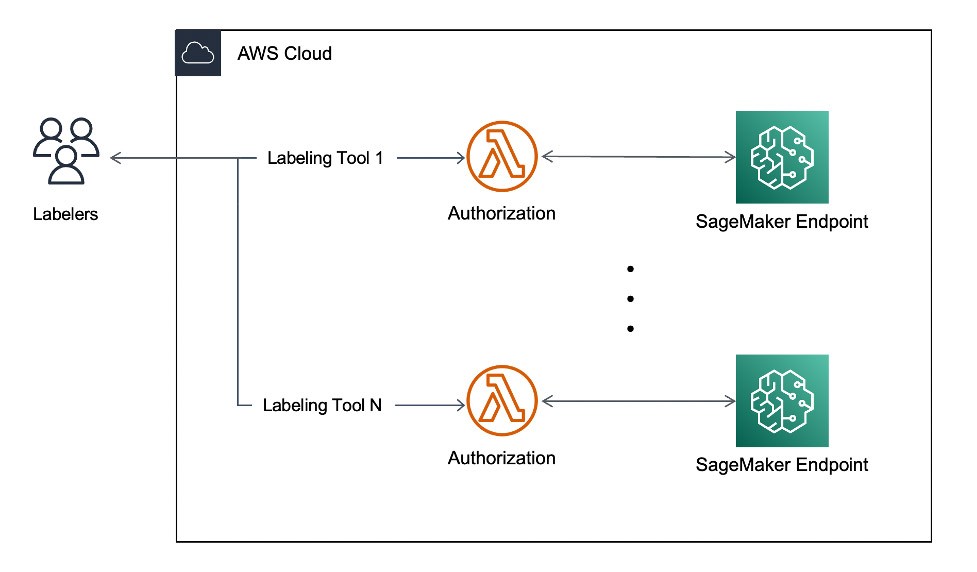
Création d'un pipeline d'apprentissage actif avec Amazon SageMaker GroundTruth
SageMaker Ground Truth est un service d'étiquetage des données géré visant à créer des jeux de données de ML à grande échelle étiquetés avec précision en utilisant plusieurs options de main-d'œuvre. Outre les divers flux de travail d'étiquetage des données intégrés et personnalisés pour le texte, les images, les vidéos et les nuages de points 3D, il vous permet de créer un pipeline d'étiquetage des données automatisé avec apprentissage actif en annotant automatiquement les objets avec des modèles de ML pertinents et en assignant les objets moins fiables à l'annotation humaine.
La première étape du pipeline comprend l'envoi par SageMaker Ground Truth d'un échantillon aléatoire de jeux de données pour l'annotation humaine afin d'entraîner et de valider le modèle utilisé pour l'étiquetage automatique. Le score de confiance des sorties du modèle entraîné et la métrique de qualité dans les données de validation sont comparés au seuil pour décider des étiquettes de qualité pour l'annotation du reste du jeu de données. Selon que le score de confiance atteint ou non le seuil souhaité, l'objet est considéré comme étiqueté automatiquement ou envoyé à la main-d'œuvre humaine pour être annoté. Ces annotations, à leur tour, servent à mettre à jour et améliorer le modèle d'étiquetage automatique. Ce pipeline d'apprentissage actif fonctionne jusqu'à ce que le jeu de données requis soit entièrement étiqueté ou qu'une autre condition d'arrêt soit remplie (pour en savoir plus, référez-vous à l'article Automatiser l'étiquetage des données). Le processus d'apprentissage actif est illustré dans le diagramme suivant :
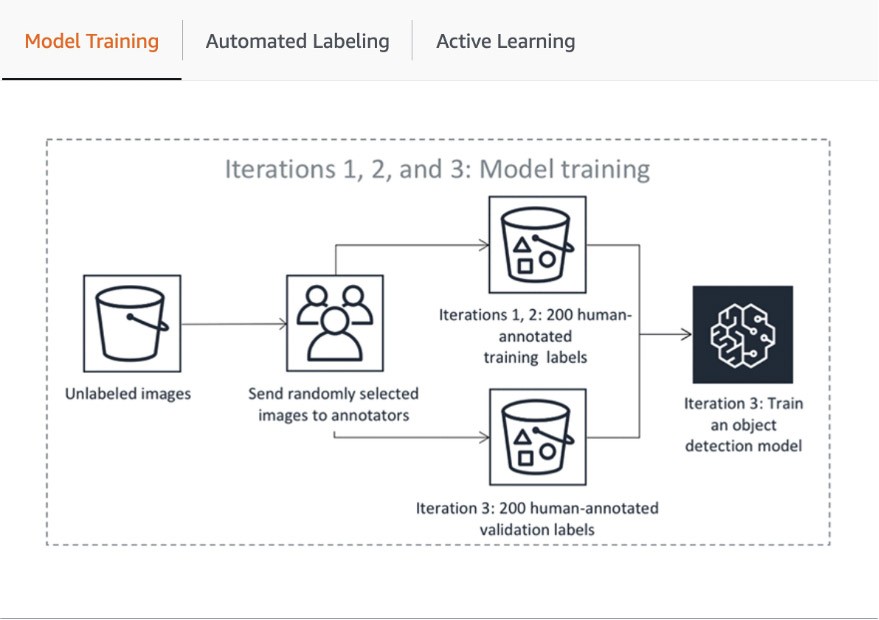
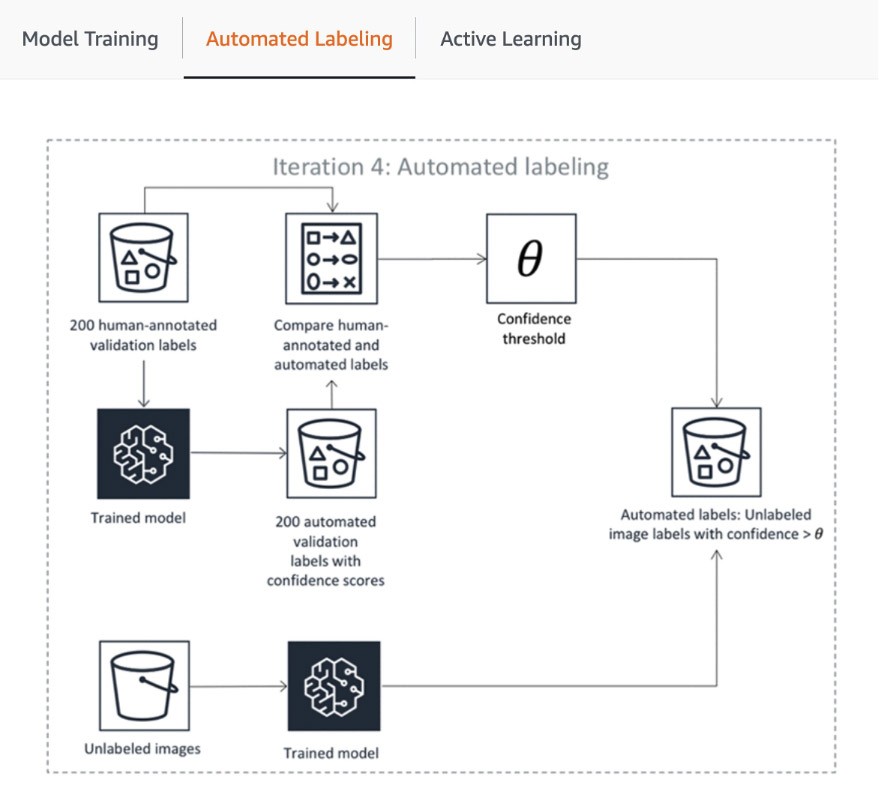
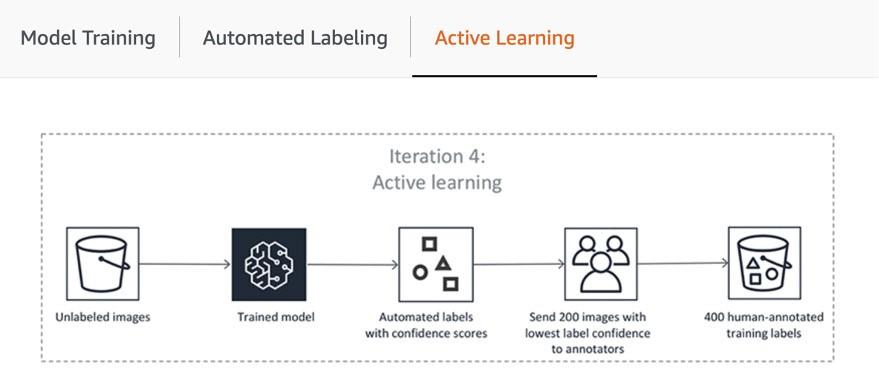
Bien que de nombreux clients d'AWS utilisent simplement ses modèles de ML intégrés, SageMaker Ground Truth vous permet d'apporter votre propre modèle si vous avez un cas d'utilisation personnalisé. Pour en savoir plus, visitez le blog « Apportez votre propre modèle pour les flux de travail d'étiquetage Amazon SageMaker avec l'apprentissage actif. »
La technique d'apprentissage actif accélère considérablement le processus d'étiquetage des données en identifiant le sous-jeu de données que vos étiqueteurs doivent étiqueter. Elle réduit aussi considérablement le coût de la main-d'œuvre en maintenant la précision des annotations à un niveau élevé. Vous pouvez lire un exemple de cas d'utilisation d'une tâche de détection d'objets avec étiquetage automatique des données dans le blog « Annoter les données à bas prix avec Amazon SageMaker Ground Truth et l'étiquetage automatisé des données. »
Conclusion
Au cours des dernières années, l'automatisation des processus robotiques (RPA) a été l'une des catégories de logiciels dont la croissance est la plus rapide dans un contexte où les entreprises s'efforcent de réaliser la transformation numérique. Cependant, 80 % des données de l'entreprise sont non structurées et interdites à l'automatisation. Les solutions émergentes de traitement des données non structurées proposées par des entreprises comme Super.AI, qui s'appuient sur les services de ML d'AWS, aident les entreprises à élargir considérablement le champ de l'automatisation en extrayant des informations exploitables à partir de données non structurées – images, vidéos, audio, documents et texte. Ces plateformes peuvent répondre à une grande variété de cas d'utilisation, de l'inspection visuelle à l'évaluation de la qualité des listes de produits en ligne, avec une intervention humaine minimale. Les premiers utilisateurs de ces plateformes acquièrent un avantage concurrentiel qui leur permet de réduire les coûts et les erreurs et d'offrir une expérience client unique.

AWS Editorial Team
L'équipe de marketing de contenu d'AWS Startups collabore avec des startups de toutes tailles et de tous secteurs pour proposer un contenu exceptionnel qui éduque, divertit et inspire.
Comment a été ce contenu ?