¿Qué le pareció este contenido?
- Aprender
- Automatización del procesamiento de datos no estructurados con Amazon SageMaker
Automatización del procesamiento de datos no estructurados con Amazon SageMaker
por Nikhil Dinesh, Head of Startup Business Development de la región DACH en AWS, y Sayon Saha, Machine Learning Specialist Solutions Architect en AWS
Los datos no estructurados, como las imágenes, los videos y el texto, que aparecen en las publicaciones de productos de comercio electrónico tienen un impacto significativo en la tasa de conversión. Un estudio realizado por eBay Research concluyó que las imágenes de gran tamaño pueden aumentar la conversión un 15,3%, y que otros factores, como el número de fotos y el estado del producto, desempeñan un papel importante. Los mercados y los vendedores deben optimizar la conversión en función de un conjunto ilimitado de factores determinados por los equipos de marketing. El uso de la ciencia de datos y el machine learning (ML) para abordar este problema no es una novedad: AWS ha creado varios servicios para ayudar con los aspectos indiferenciados del machine learning, como Amazon Rekognition (para imágenes y videos), Amazon Comprehend (para texto), Amazon SageMaker (para desarrollo e implementación de modelos) y Amazon SageMaker Ground Truth (para anotaciones de datos).
Super.AI, una startup con sede en Berlín, cree que existe una gran oportunidad de ensamblar estos componentes de la manera correcta y con la experiencia de usuario adecuada para lo que denominan el procesamiento de datos no estructurados (UDP) en varios sectores. Según Gartner, el 80 % de los datos de una empresa típica no están estructurados. La plataforma de Super.AI extrae información procesable de datos no estructurados, lo que permite a las empresas automatizar procesos empresariales complejos. Según Brad Cordova, emprendedor en serie dedicado a la IA y fundador y CEO de Super.AI: “Los clientes del comercio electrónico, los servicios de TIC (pruebas, inspección y certificación), los seguros, la sanidad, la fabricación y la agricultura utilizan la plataforma de Super.AI para automatizar casos de uso complejos, como la evaluación de la calidad de las publicaciones de productos, la inspección visual, la detección de daños en los vehículos y la evaluación del rendimiento de los cultivos. Nuestros clientes están consiguiendo un ROI significativo gracias a la reducción de tiempo y costos, la reducción de errores y la mejora de la satisfacción de los clientes”.
Este artículo le mostrará en qué aspectos de la arquitectura de Super.AI de AWS se incluyen la ingesta de datos, el etiquetado previo, la canalización de aprendizaje activo y el etiquetado asistido en tiempo real. A continuación, analizaremos los objetivos, los riesgos y los aspectos en los que vemos oportunidades de mejora.
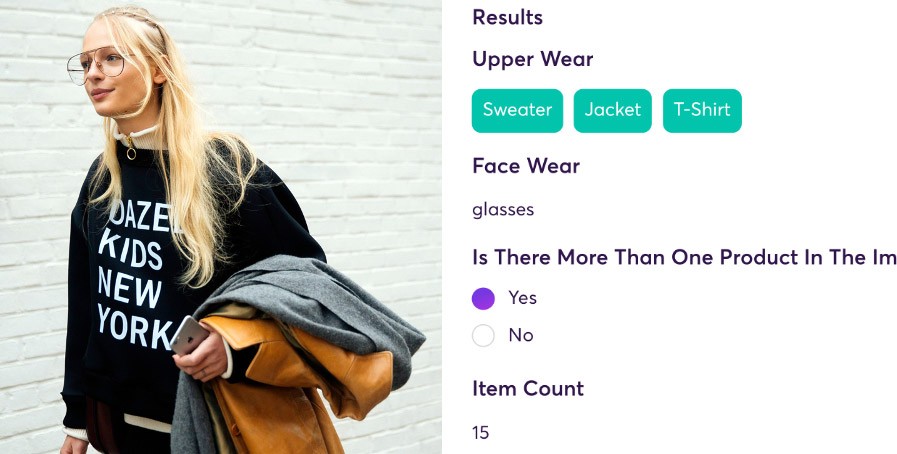

Plataforma de procesamiento de datos no estructurados de Super.AI
La plataforma de Super.AI ayuda a los clientes a transformar los procesos que implican datos no estructurados, como imágenes, videos, texto, documentos y audio, y a automatizarlos mediante una combinación de IA, software y humanos. Esta demostración de categorización de imágenes de productos de Super.AI muestra cómo la categorización de imágenes de productos de Super.AI puede ayudar a los minoristas a aumentar las conversaciones en el sitio web.
Aprendizaje activo y etiquetas previas
Los clientes de Super.AI solicitaron un mecanismo de etiquetado más eficiente y preciso. Por eso, recientemente lanzaron una nueva característica llamada Aprendizaje activo y etiquetado previo, en la que la canalización preprocesa los puntos de datos utilizando un modelo de ML que se ejecuta en SageMaker. Esta solución prioriza el etiquetado de los puntos de datos que son más útiles para el modelo. El modelo de ML se ejecuta sobre todos los puntos de datos cargados para generar un resultado, por ejemplo, una puntuación de confianza, que se utiliza para analizar los puntos de datos de forma priorizada. Siempre que sea posible, se generan etiquetas previas y se envían al etiquetador humano para que las revise o edite.
Luego, la canalización se escala según la demanda. Los clientes pueden cargar datos mediante una API (o interfaz de usuario) y aplicar varios modelos para el aprendizaje activo y el etiquetado previo. Los clientes pueden elegir entre una selección de modelos proporcionados por Super.AI o usar su propio modelo. Super.AI utiliza la puntuación de confianza generada por el modelo de ML para priorizar los puntos de datos y proporcionarlos de manera más eficiente. Cuando sea necesario, los etiquetadores humanos pueden utilizar las etiquetas previas generadas por el sistema para etiquetar los datos a mano con precisión.
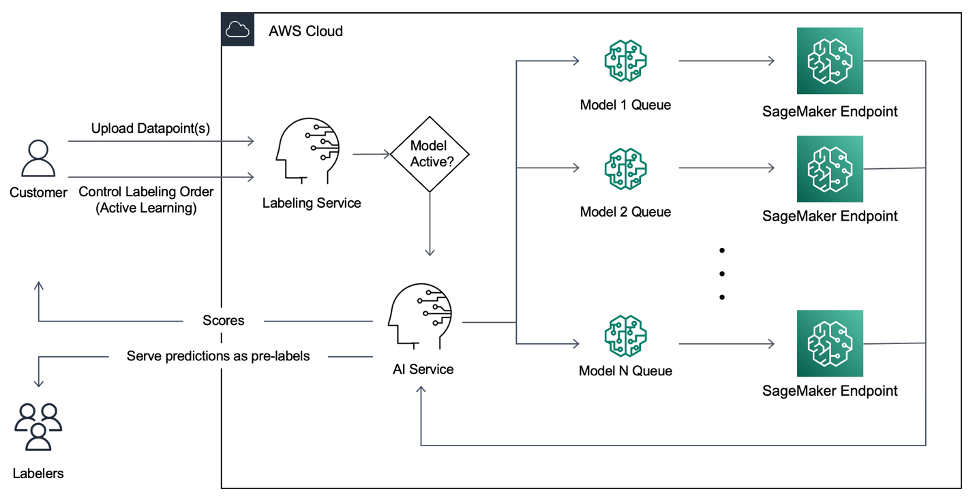
Etiquetado asistido en tiempo real
La plataforma aprovecha una arquitectura sin servidor con SageMaker. Los clientes deben disponer de este servicio en tiempo real para etiquetar sus imágenes. La herramienta utiliza AWS Lambda en combinación con Puntos de conexión de Amazon SageMaker para atender solicitudes simultáneas en tiempo real con un tiempo de respuesta inferior a 10 segundos. Puede explorar la aplicación de etiquetado de imágenes de Super.AI en su documentación en línea.
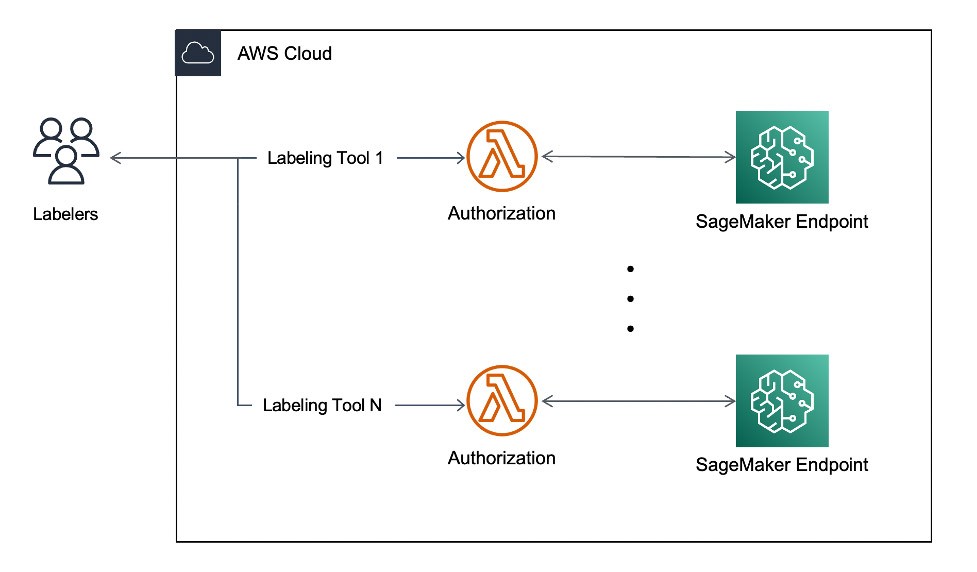
Creación de una canalización de aprendizaje activo con Amazon SageMaker Ground Truth
SageMaker Ground Truth es un servicio de etiquetado de datos gestionado para crear conjuntos de datos de ML a gran escala etiquetados con precisión con varias opciones de personal. Junto con los diversos flujos de trabajo de etiquetado de datos integrados y personalizados para texto, imágenes, videos y nubes de puntos en 3D, permite crear una canalización de etiquetado de datos automatizada con aprendizaje activo mediante la anotación automática de objetos con modelos de ML pertinentes y la asignación de objetos con menor confianza para la anotación humana.
El primer paso de la canalización incluye el envío por parte de SageMaker Ground Truth de una muestra aleatoria de conjuntos de datos para su anotación humana a fin de entrenar y validar el modelo utilizado para el etiquetado automático. La puntuación de confianza y la métrica de calidad del modelo entrenado en los datos de validación se comparan con el umbral para decidir qué etiquetas de calidad se utilizarán para anotar el resto del conjunto de datos. En función de si la puntuación de confianza alcanza el umbral deseado, se considera que un objeto se ha etiquetado automáticamente o se envía al personal humano para que lo anote. Estas anotaciones, a su vez, se utilizan para actualizar y mejorar el modelo de etiquetado automático. Esta canalización de aprendizaje activo continúa procesándose hasta que el conjunto de datos requerido esté completamente etiquetado o se cumpla otra condición de interrupción (más información en este artículo sobre cómo automatizar el etiquetado de datos). El proceso de aprendizaje activo se ilustra en el siguiente diagrama:
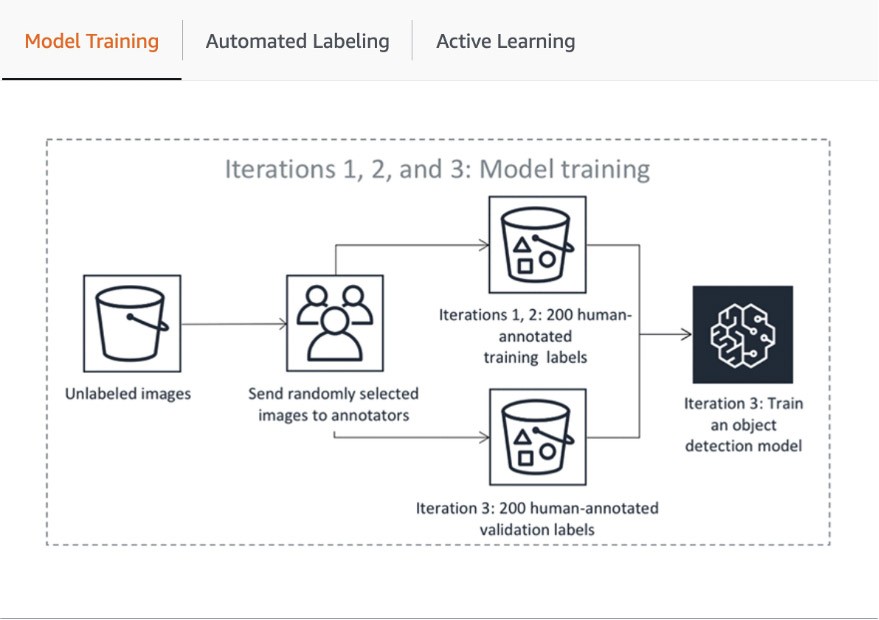
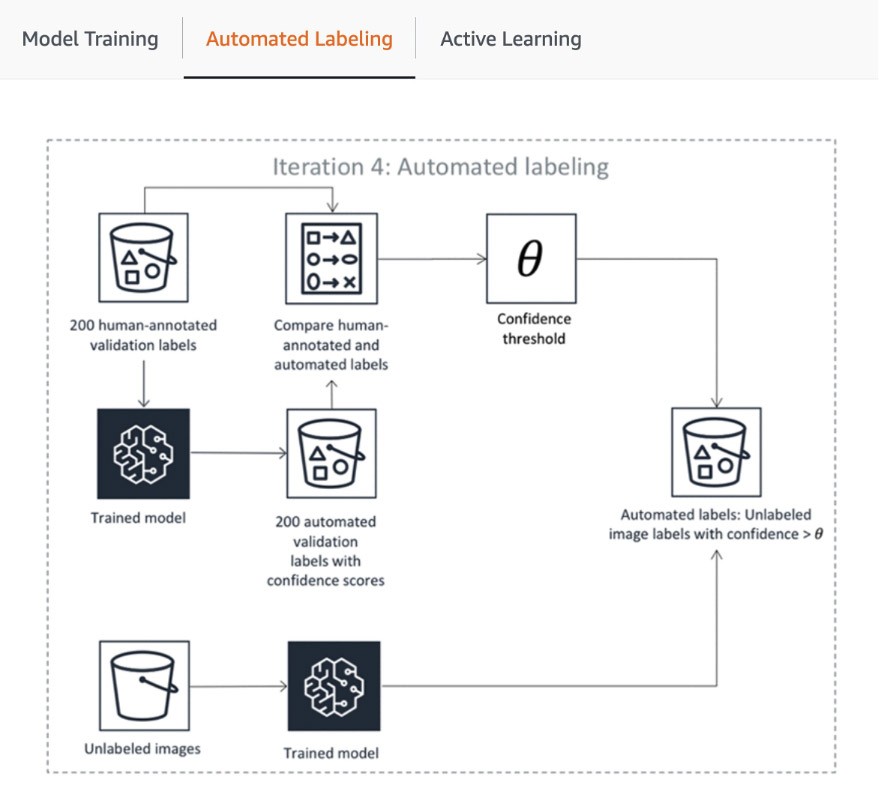
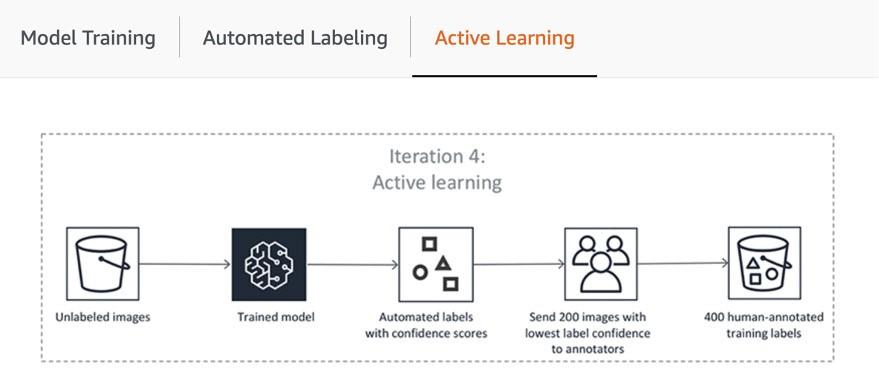
Si bien muchos clientes de AWS simplemente usan los modelos de ML integrados, SageMaker Ground Truth le permite usar los suyos si tiene un caso de uso personalizado. Puede obtener más información al respecto en el blog “Bring Your Own Model for Amazon SageMaker Labeling Workflows with Active Learning”.
La técnica de aprendizaje activo hace que el proceso de etiquetado de datos sea mucho más rápido al identificar el subconjunto de datos que los etiquetadores deben etiquetar. También reduce significativamente el costo de la fuerza laboral, ya que mantiene una alta precisión en las anotaciones. En el blog “Annotate Data for Less with Amazon SageMaker Ground Truth and Automated Data Labeling” encontrará un ejemplo de caso práctico de detección de objetos con etiquetado automatizado de datos.
Conclusión
Durante los últimos años, la automatización robótica de procesos (RPA) ha sido una de las categorías de software de más rápido crecimiento a medida que las empresas se esfuerzan por lograr la transformación digital. Sin embargo, el 80 % de los datos empresariales no están estructurados y están fuera del alcance de la automatización. Las nuevas soluciones de procesamiento de datos no estructurados de empresas como Super.AI, que utilizan los servicios de ML de AWS, están ayudando a las empresas a ampliar considerablemente el alcance de la automatización al extraer información procesable de datos no estructurados (imágenes, videos, audio, documentos y texto). Estas plataformas pueden abordar una amplia gama de casos de uso, que abarcan desde la inspección visual hasta la evaluación de la calidad de las publicaciones de productos en línea, con una intervención humana mínima. Los primeros en adoptar estas plataformas están obteniendo una ventaja competitiva que reduce los costos, reduce los errores y ofrece una experiencia de cliente diferenciada.

AWS Editorial Team
El equipo de marketing de contenido para startups de AWS colabora con startups de todos los tamaños y sectores para ofrecer contenido excepcional que eduque, entretenga e inspire.
¿Qué le pareció este contenido?