このコンテンツはいかがでしたか?
- 学ぶ
- Amazon SageMaker による非構造化データ処理の自動化
Amazon SageMaker による非構造化データ処理の自動化
AWS、DACH リージョンのスタートアップ事業開発責任者、Nikhil Dinesh 氏、および AWS、機械学習スペシャリストソリューションアーキテクト、Sayon Saha 氏による投稿
e コマースの商品リストに表示される画像、動画、テキストなどの非構造化データは、コンバージョン率に大きな影響を与えます。eBay リサーチの調査によると、特大サイズの画像はコンバージョン率を 15.3% 増加させることができ、写真の枚数や商品の状態などの他の要因が重要な役割を果たしていることがわかりました。Marketplaces と出品者は、マーケティングチームが決定した自由形式の要素に基づいてコンバージョンを最適化する必要があります。この問題に対処するためにデータサイエンスと機械学習 (ML) を使用することは新しいことではありません。AWS は、Amazon Rekognition (画像と動画用)、Amazon Comprehend (テキスト用)、Amazon SageMaker (モデル開発およびデプロイ用)、Amazon SageMaker GroundTruth (データアノテーション用) など、ML の差別化されていない側面を支援するサービスをいくつか作成しました。
ベルリンを拠点とするスタートアップ企業である Super.AI は、さまざまな業界において、これらのビルディングブロックを適切な方法および適切なユーザーエクスペリエンスで、組み立てる大きなチャンスがあると考えています。これは、いわゆる非構造化データ処理 (UDP) に向けられたものです。Gartner によると、一般的な企業のデータの 80% は非構造化です。Super.AI のプラットフォームは非構造化データから実用的な情報を抽出し、企業が複雑なビジネスプロセスを自動化できるようにします。シリアル AI の起業家であり super.AI の創業者兼 CEO でもある Brad Cordova 氏は次のように語っています。「e コマース、TIC (試験、検査、認証) サービス、保険、医療、製造、農業に携わるお客様は super.AI プラットフォームを使用して、商品リストの品質評価、目視検査、車両の損傷検知、作物の収穫量評価などの複雑なユースケースを自動化しています。お客様は、時間とコストの削減、エラーの減少、顧客満足度の向上により、高い ROI を達成しています」
この記事では、AWS の super.AI アーキテクチャにおけるデータインジェスト、事前のラベル付け、アクティブ学習パイプライン、およびリアルタイム支援ラベル付けがどの部分に該当するかを示し、続いて目標、リスク、改善の余地がある分野について説明します。
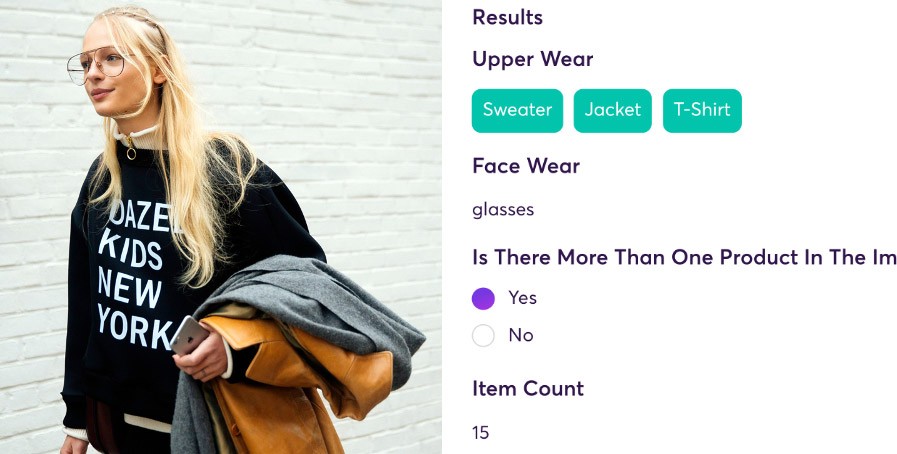

Super.AI の非構造化データ処理プラットフォーム
super.AI プラットフォームは、お客様が画像、動画、テキスト、文書、音声などの非構造化データを含むプロセスを変換し、AI、ソフトウェア、および人間を組み合わせて自動化するのに役立ちます。この super.AI 製品画像分類デモでは、super.AI の商品画像分類が小売業者のウェブサイトでの会話を増やすのにどのように役立つかを示しています。
アクティブ学習と事前ラベル
Super.AI のお客様は、より効率的で精度の高いラベル付けメカニズムを要望していました。そこで、同社は最近、アクティブ学習と事前のラベル付けと呼ばれる新機能をリリースしました。この機能は、パイプラインが SageMaker で実行されている ML モデルを使用してデータポイントを前処理します。このソリューションでは、モデルにとって最も有用なデータポイントに優先的にラベル付けします。ML モデルは、アップロードされたすべてのデータポイントに対して実行され、信頼度スコアなどの出力を生成します。この出力は、データポイントに優先順位を付けて提供するために使用されます。事前ラベルは可能な限り生成され、レビューや編集のためにラベル付けを行う人間の作業者に提供されます。
その後、パイプラインは需要に応じてスケールされます。お客様は API (または UI) を介してデータをアップロードし、複数のモデルを適用してアクティブ学習や事前のラベル付けを行うことができます。お客様は super.AI が提供するさまざまなモデルから選択することも、独自のモデルを持ち込むこともできます。Super.AI は ML モデルによって生成された信頼度スコアを使用してデータポイントに優先順位を付け、より効率的に提供します。必要に応じて、ラベルをつける人間の作業者はシステムによって生成された事前ラベルを使用して、手作業でデータに正確にラベル付けできます。
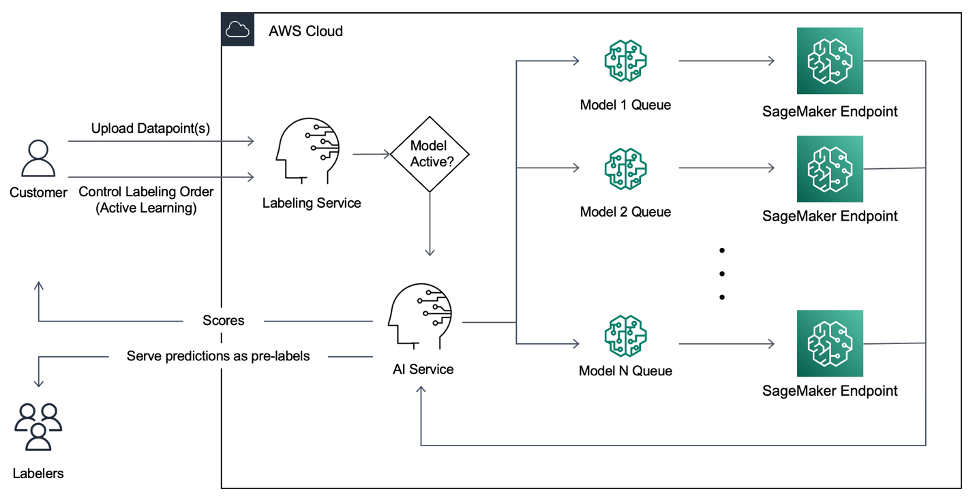
リアルタイム支援ラベル付け
このプラットフォームは、SageMaker のサーバーレスアーキテクチャを活用しています。お客様は画像にラベルを付けるためにこのサービスをリアルタイムで利用する必要があります。このツールは AWS Lambda と Amazon SageMaker エンドポイントを組み合わせて活用し、10 秒未満の応答時間でリアルタイムに同時リクエストを処理します。super.AI の画像タグ付けアプリケーションについては、オンラインドキュメントで調べることができます。
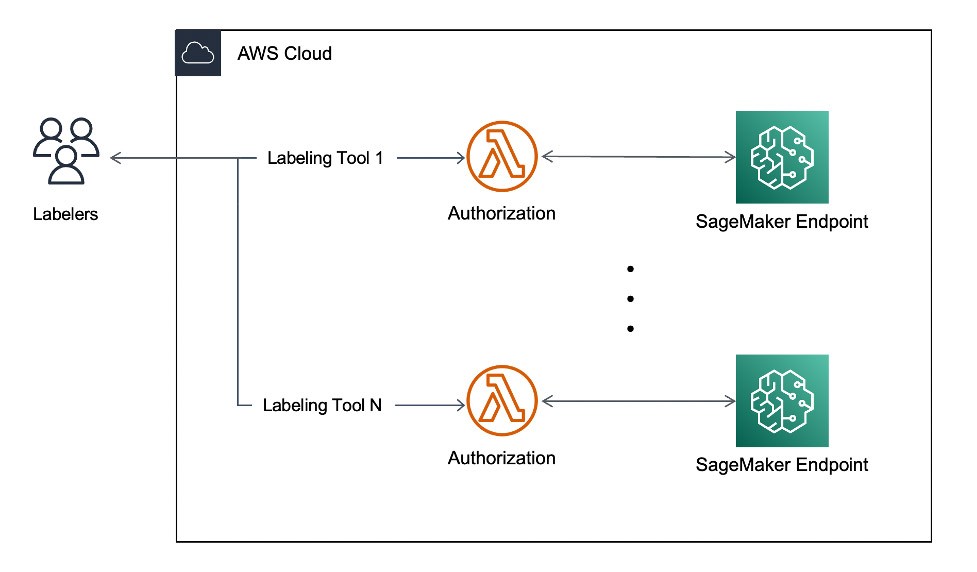
Amazon SageMaker GroundTruth によるアクティブ学習パイプラインの構築
SageMaker Ground Truth は、複数の労働力オプションを備えた、正確にラベル付けされた大規模な ML データセットを構築するためのマネージドデータラベリングサービスです。テキスト、画像、動画、3D ポイントクラウド向けのさまざまな組み込みおよびカスタムのデータラベリングワークフローに加えて、関連する ML モデルを使用してオブジェクトに自動的に注釈を付け、人間によるアノテーションとして信頼性の低いオブジェクトを割り当てることで、アクティブ学習による自動データラベリングパイプラインを構築できます。
パイプラインの最初のステップには、SageMaker Ground Truth が人によるアノテーションのためにデータセットのランダムなサンプルを送信して、自動ラベル付けに使用されるモデルのトレーニングと検証を行うことが含まれます。トレーニングされたモデルの出力信頼度スコアと品質メトリクスは、データセットの残りの部分に注釈を付けるための品質ラベルを決定するためのしきい値と比較されます。信頼度スコアが目的のしきい値を満たしているかどうかに応じて、オブジェクトは自動ラベル付けされたと見なされるか、またはアノテーションを求めて人間の作業者に送られます。これらのアノテーションは、今度は自動ラベル付けモデルの更新と改善に使用されます。このアクティブ学習パイプラインは、必要なデータセットが完全にラベル付けされるか、別の停止条件が満たされるまで処理を続けます (詳細については、こちらの記事「データラベリングを自動化する」をご覧ください)。アクティ学習のプロセスは以下の図に示されています。
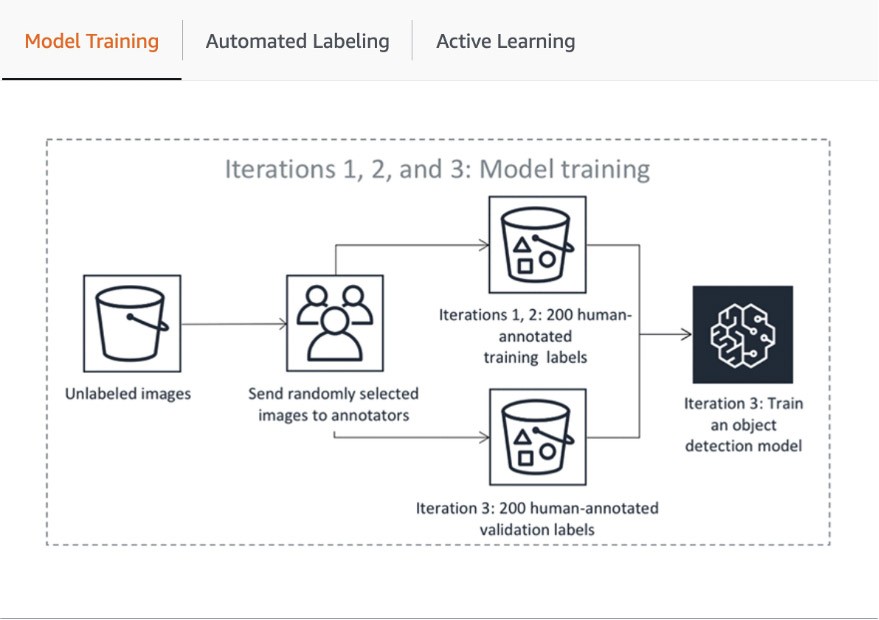
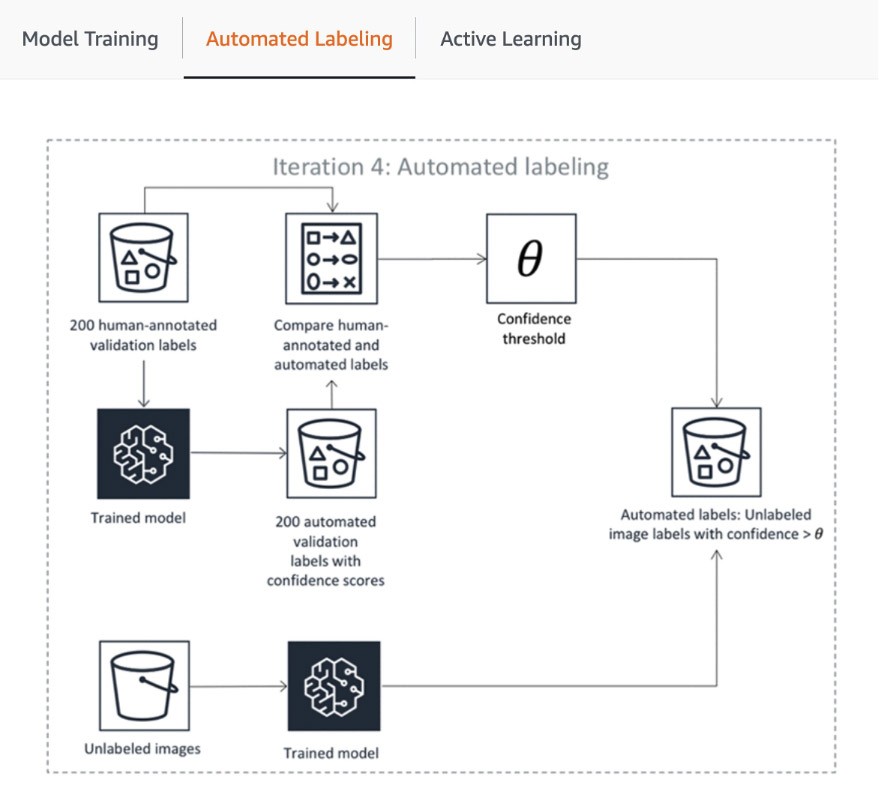
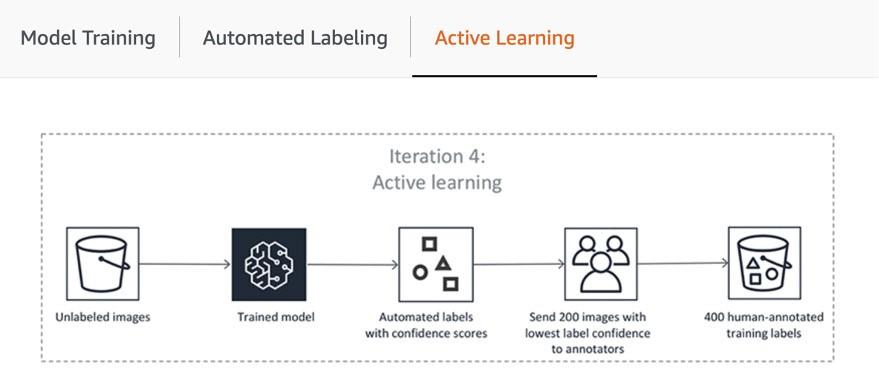
AWS のお客様の多くは、組み込み ML モデルを使用するだけですが、SageMaker Ground Truth ではカスタムユースケースがある場合は独自のモデルを導入できます。詳細については、ブログ「アクティブ学習を使用して Amazon SageMaker ラベリングワークフローに独自のモデルを導入する」をご覧ください。
アクティブ学習の手法は、ラベリング作業者がラベル付けすべきデータのサブセットを特定することで、データラベリングのプロセスを大幅に高速化します。また、アノテーションの精度を高く保つことで、作業コストを大幅に削減できます。自動データラベリングによるオブジェクト検出ジョブのユースケースの例については、ブログ「Amazon SageMaker Ground Truth と自動データラベリングで少ないコストでデータにアノテーションを付ける」を参照してください。
まとめ
ここ数年、企業がデジタルトランスフォーメーションの達成を目指す中で、ロボティックプロセスオートメーション (RPA) は最も急速に成長しているソフトウェアカテゴリの 1 つとなっています。しかし、企業データの 80% は構造化されておらず、自動化の対象外です。super.AI のような企業の AWS ML サービスを活用する新しい非構造化データ処理ソリューションにより、画像、動画、音声、文書、テキストなどの非構造化データから実用的な情報を抽出することで、企業は自動化の範囲を大幅に拡大できるようになっています。このようなプラットフォームは、目視検査からオンラインでの製品リストの品質評価まで、人間の介入を最小限に抑えながら、幅広いユースケースに対応できます。このようなプラットフォームを早期に導入すると、コストダウン、エラー削減、差別化されたカスタマーエクスペリエンスの提供という競争上の優位性が得られます。

AWS Editorial Team
AWS スタートアップの Content Marketing Team は、教育、エンターテインメント、インスピレーションを提供する優れたコンテンツをもたらすために、あらゆる規模およびあらゆるセクターのスタートアップと連携しています。
このコンテンツはいかがでしたか?