AWS Startups Blog
Q Bio: Creating the First Digital Twin Platform for Medical Analysis
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Guest post by Jyotindra Vasudeo, VP of Engineering, Q Bio
Introduction
Q Bio is building a digital twin platform that will propel the world into a future where a regular checkup with a doctor is no longer subjective – it’s data driven. We want to capture all the data we can about someone’s health by measuring every single biomarker in the body and cataloging the data, and making it easy to search and analyze. In our vision, a doctor will no longer just measure blood pressure, pulse, and weight; they’ll be able to measure every aspect of our body and make objective diagnoses based on changing patterns in our biomarkers.
We are making this possible by building a revolutionary body scanner and cloud platform that can measure, store, and process all this information, making it available to computational scientists, researchers, and doctors to gain insights. We want to scalably build a digital twin of a person’s body and represent it in such a manner that we are able to understand changes in one’s health over time and identify patterns that indicate where one’s health is going. Imagine a world where anyone could cheaply and quickly get a whole body scan, see how their health has changed since their last visit, and what health problems they may anticipate in the future. This may sound like something out of Star Trek or a sci-fi movie, but this can be a reality, and Q Bio is actively building it.
So, how do we get there?
Achieving our goal starts with data gathering. Traditional biomedical imaging devices are either too slow, too expensive, lack necessary reproducibility for measuring change, or use ionizing radiation to do a whole body scan for use in reactive care. With other instruments such as stethoscopes and blood pressure monitors, we get targeted information that isn’t actionable without a holistic view of other vitals of the body. To meet our goals, we had to rethink how we would scan someone in minutes at low cost. With that in mind, we set out to build our own scanner. This is an extremely large and challenging endeavor, but we are up for the challenge because we have been lucky enough to bring the right interdisciplinary team to the job. But the scanner is only part of the story; we firmly believe that such technologies will be commonplace in the near future.
What we also need is a platform that can capture this information and organize it for offline computation and analysis. This means that the scanner essentially is an Internet of Thing (IoT) device that captures a person’s data. The platform will then be the mechanism that research scientists use to run complex algorithms to gain insights and run experiments on the digital twin of the body. To make this possible, the platform will have to follow the following tenets:
- Reproducible data processing: For us to gain confidence in the results that we get from the platform, we will have to guarantee that the results are reproducible, meaning that any transformation that was run on a set of data can be traced back to which version of the code was running and on what version of the data.
- Data lineage: We should be able to trace how data passes through multiple workflows and how it gets transformed. Data lineage gives visibility while greatly simplifying the ability to trace errors back to the root cause in a data analytics process.
- Ease of use: We’ve built the platform to be used by multiple stakeholders:
- Computational scientists who want compute resources and access to our data to run new algorithms without having to deal with where that data lives.
- Patients who want access to the results and are able to search for biomarkers and health trend visualizations.
- Doctors and medical practitioners who want to make data driven decisions about their diagnosis and can tap into the corpus we have collected over time for a particular individual or even a whole population while preserving individual privacy and anonymity.
- Researchers who are interested in running clinical studies or diagnostic development on the digital twin data for multiple people in a certain population.
Finally, we also need a user interface that is intuitive and is able to represent the digital twin of the body without overwhelming the user.
Challenges
Apart from the challenge of building a completely new body scanner, which involves superconducting magnets, there are also many software challenges. The scanner itself is akin to a self-driving car, with a low latency feedback loop involved in acquiring the data from the scanner and making real time decisions on how to guide the scanner. Low latency data transfers and sub-millisecond eventing help us make faster and more accurate decisions so we can scan a certain part of the body at higher resolution if an anomaly is detected.
The scanner data can be processed in either batch or streaming mode. We have use cases for both, and this same code can also run directly on the scanner or in the cloud. This makes for a challenging architecture that needs to support multiple modes of operation but is easy enough to use by a computational scientist using familiar data processing tools.
Finally, we gather a large amount of data that’s captured from the scanner. Due to the immutable nature of the data, we are constantly growing in terms of storage requirements, and the platform is responsible for transferring and processing this data. The data is processed in many different ways, and the platform needs to be flexible enough to support the variety, from running computational physics simulations to more traditional machine learning/deep learning algorithms. The data also needs to be searchable and mineable to make it easy for data scientists to run queries and ask questions about an individual’s health and combine uncovered information with any medical context acquired from third party providers.
This is just the tip of the iceberg in terms of challenges. As we continue to build and mature this digital twin platform, we will need to find innovative ways to tackle the challenges we face. Therefore we needed to start with a cloud platform capable of growing with our needs.
How do we build it?
We chose AWS as our cloud platform to meet our goals. AWS provided a lot of the building blocks that we needed to get us started.
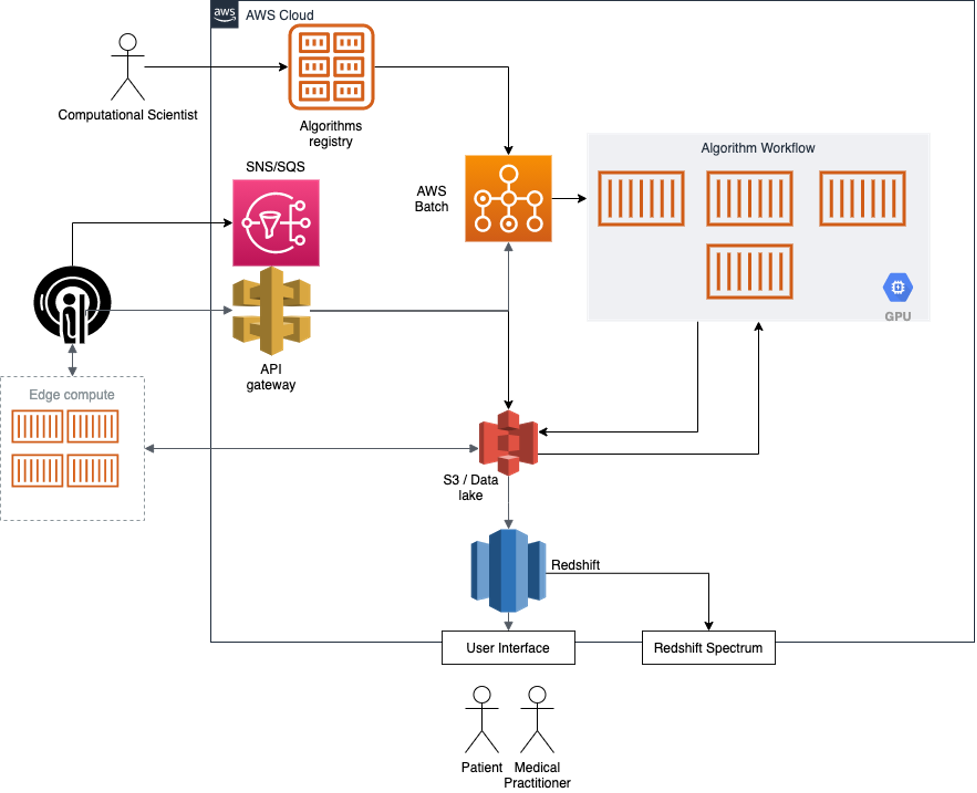
One of the most valuable aspects AWS provides is the ability to swap or extend parts of our system as we see fit without affecting our end users. For example, we standardized the practice of computational scientists building their algorithms in containers to allow us to easily run them in Amazon ECS and use AWS Batch to coordinate when and where they get run. They can be easily swapped out for a Kubernetes cluster if we wanted to go there. Similarly, we use Amazon S3 today as a data lake, and we were able to add analytics and queriability to the data by attaching Amazon Redshift Spectrum to S3. If Spectrum doesn’t meet our needs in the future, we can easily try any other host of solutions such as Amazon Athena or even Amazon OpenSearch Service (successor to Amazon Elasticsearch Service). The flexibility AWS provides with this plug-and-play model is extremely valuable to us as a startup. We have changing needs, and it gives me a good night sleep knowing that we can adapt to these changes with our cloud infrastructure.
In the future, as we continue to develop the platform we will want to do more of our computation at the edge. Today we have on-prem servers to do some of the edge compute, but with AWS solutions like outpost and wavelength, we are eager to give them a go as well and see how we can have a unified development and deployment environment for both our cloud and edge infrastructure.
What next?
Population health monitoring and management is closer than we think. Proactive healthcare will be the primary way in which communities will be able to live longer and healthier lives. It will also increase life expectancy by multiple years and save the healthcare system millions of dollars in curative, reactive care. It will also become a necessity; we will soon not have enough general physicians to service this growing population. To provide an equitable standard of healthcare for everyone, we will need to build tools that will help medical practitioners make decisions faster and more accurately. Q Bio is making this possible by working on fundamental advances in whole body scanning technology and coupling it with a software platform that will allow users to access the data to understand their bodies and what is changing in their personal baseline over time.
If you are interested in this vision, there are multiple ways in which you can help. We are currently looking for volunteers to participate in studies which will help us with data for FDA approval of this technology. Secondly, if you are excited by this vision and want to play a role in building this technology, please visit our website and apply for a job! You can also directly reach out to me.