AWS Storage Blog
Getting started with self-managed Oracle in AWS using Amazon FSx for OpenZFS
Organizations of all sizes run their enterprise applications and databases in the cloud. These organizations may choose to run self-managed databases on Amazon Elastic Compute Cloud (Amazon EC2) rather than using the fully-managed Amazon Relational Database Service (Amazon RDS) due to internal policies, Amazon RDS service maximums, and other reasons. When running self-managed databases in the cloud, there are several critical aspects to consider. The compute running the database must provide the necessary CPU, RAM, and network capabilities to effectively run the database. A high-performance scalable storage solution is needed to make sure that application stability and user expectations are met. For critical workloads, high availability (HA) is essential because database and application downtime can result in financial losses and diminished customer trust. The solution must be both cost-effective and efficient to make sure of responsible resource allocation and minimize waste.
Running your Oracle database from a network attached file system provides several advantages over direct attached storage. One significant benefit is high-availability, which makes sure that your database remains accessible and operational even in the event of storage hardware failures or other disruptions. The ability to take instant zero-copy snapshots reduces your recovery point objective (RPO) and recovery time objective (RTO). You can use the snapshots to create zero-copy clone volumes to quickly create space-efficient, cost-effective copies of production for lower environments. Snapshots can also be used for native block based replication to a disaster recovery environment in the same AWS Region or across AWS Regions. Network attached file systems also offer built-in compression capabilities to reduce the storage capacity requirements of the database and save on costs.
Amazon FSx for OpenZFS is a fully-managed NFS file system capable of up to 10 GB/s throughput and 400,000 IOPS for disk operations, with even greater performance when serving data from cache. The file system can scale up to 512 TiB using all SSD storage. FSx for OpenZFS can be deployed in a highly-available configuration within a single AWS Availability Zone (AZ) or across AZs in a Multi-AZ deployment. The file system includes built-in features such as compression for capacity savings, native replication for disaster recovery, and zero-copy snapshots and cloning to reduce duplication.
In this post we review the basic configuration options and best practices when getting started with deploying a self-managed Oracle database running on Amazon EC2 with FSx for OpenZFS as the persistent database storage layer.
Solution architecture
The following figure shows the solution architecture.
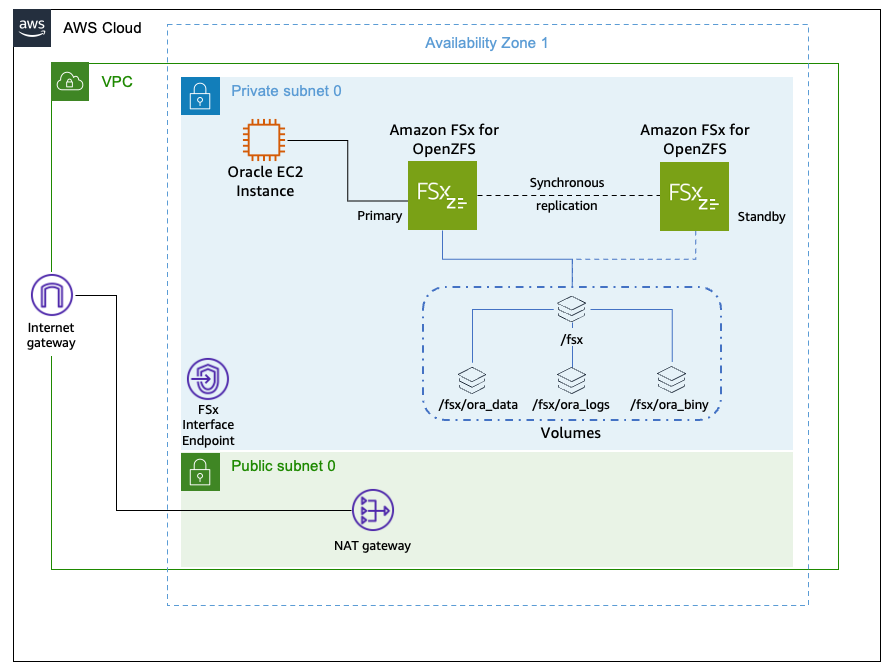
Figure 1: Oracle database running on an EC2 instance mounting the FSx for OpenZFS file system
Prerequisites
The following prerequisites are needed to implement this solution:
- Experience installing and creating Oracle databases on Linux
- Intermediate Linux skills as an administrator
- An Amazon Virtual Private Cloud (Amazon VPC) with a private subnet and identified security group for use with NFS
- A configured and operating AWS Command Line Interface (AWS CLI) and jq package
Walkthrough
This section walks you through the solution steps.
Step 1: Choose an EC2 instance type and size
Oracle database requirements vary. Some need significant memory for the System Global Area (SGA) and Program Global Area (PGA), while others need more processing power for multiple threads. Based on your specific workload, we recommend starting with either a memory-optimized or compute-optimized instance type. We advise choosing an instance size that meets the compute, memory, and network requirements for your workload. This post focuses on setup and configuration functional testing rather than database performance evaluation. Therefore, a smaller instance size can be used for this purpose.
- You can launch your EC2 instance through the Amazon EC2 console or AWS Command Line Interface after choosing your EC2 instance size and type.
- Choose an Amazon Machine Image (AMI) running one of the Oracle-supported Linux distributions that supports enhanced networking and nconnect. Amazon EC2 enhanced networking provides high-performance networking capabilities, and the nconnect mount option allows you to create multiple TCP streams to the FSx for OpenZFS file system for increased performance. You can find more information in the Amazon EC2 User Guide and in Performance for Amazon FSx for OpenZFS page for enhanced networking and nconnect.
- Note the security group ID used (eg. sg-0123456789abcdefg) for the EC2 instance deployment . This security group ID is used when deploying the FSx for OpenZFS file system in a later step. The security group must allow inbound access to the necessary NFS ports from itself so that the EC2 instance can mount the NFS export on the FSx for OpenZFS file system.
- Note the VPC subnet ID for the EC2 instance deployment. When deploying the file system, make sure the FSx for OpenZFS file system is deployed in the same subnet as the EC2 instance.
- Install the AWS CLI following the instructions for a Linux client.
- Make sure that your system has the jq package installed used to process JSON output from the AWS CLI commands.
Step 2. Deploy an FSx for OpenZFS file system
FSx for OpenZFS is used as the persistent storage layer for the Oracle database. To deploy your file system you need to consider the following:
- Deployment type: There are three deployment types to select from. Multi-AZ, Single-AZ with High-Availability (HA), and Single-AZ. For production workloads, the Multi-AZ and Single-AZ (HA) file systems are recommended. If you need availability across AZs, then you can deploy a Multi-AZ file system. However, if performance is more important, then Single-AZ (HA) is recommended as you have HA at the file server with lower write latency because writes don’t need to traverse AZs.
- Capacity: The FSx SSD storage class means that you cannot shrink your capacity and pay for provisioned capacity. We recommend starting with a capacity that holds your database plus 20% for metadata and performance.
- Throughput: When deploying the file system, you choose a throughput that the file system is capable of when reading and writing to disk. The file system can provide greater throughput than you’ve provisioned when performing reads of cached data. The throughput of the file system also determines the CPU and cache sizing of the file system as listed in the documentation. Performance testing isn’t the main purpose of this post, thus we use 320 MB/s throughput as our example value throughout.
- IOPS: Each SSD based file system automatically receives 3 IOPS/GiB of storage capacity. You can choose to provision more IOPS to the file system if needed by your workload. This post is focused on functionality, thus we leave the default 3 IOPS/GiB and do not provision any more IOPS.
After reviewing the requirements of your database, deploy an FSx for OpenZFS file system from the FSx console or the AWS CLI with the settings needed. You can always add more SSD capacity, up to 512 TiB, and dynamically adjust your throughput or IOPS up or down as your requirements change.
In our example, we deploy a Single-AZ (HA) FSx for OpenZFS file system with 256 GiB of SSD capacity, 320 MB/s of throughput, and accept the default 3 IOPS/GiB of capacity through the CLI. Before deploying, replace <SUBNET_ID> (for example subnet-0123456789abcdefg) in the following command with the subnet ID you noted previously when launching the EC2 instance. You also need the security group applied to the EC2 instance noted earlier replacing <SECURITY_GROUP_ID> (for example sg-0123456789abcdefg) with the appropriate value in the following command. The following command creates the file system with the previously mentioned configuration:
Step 3. Configure the volumes on FSx for OpenZFS
Each FSx for OpenZFS file system is deployed with a root volume called fsx. It is best practice to store your data within children volumes of the root. This also allows you to manage snapshots and clones of your database in the future.
Provision three volumes to host the Oracle database binary, data, and log files:
- Run the following commands to obtain the root volume ID of the FSx for OpenZFS file system and set it to the ROOT_VOL_ID environment variable, as well as the VPC CIDR and set it to the VPC_CIDR environment variable:In this example, the OpenZFS file system name = FSxZ-OracleDB
- Oracle Data: Create a single ora_data volume mounted under the fsx root volume with compression disabled using the following command:
- Oracle Logs: Create a single ora_logs volume mounted under the fsx root volume with compression disabled using the following command:
- Oracle Binaries: Create a single ora_biny volume mounted under the fsx root volume with LZ4 compression enabled using the following command:
Step 4. Mount the FSx for OpenZFS volumes
When deploying an Oracle database without Oracle ASM, you must manually manage the database files and storage using standard file system operations. You may forget about the reasons and benefits of using the Oracle Optimal Flexible Architecture (OFA).
OFA provides configuration guidelines that help you organize Oracle installations. These guidelines create consistent directory structures across your environment, which streamlines administrative tasks, maintenance operations, and efficient support processes. For implementation details, go to the Oracle Database Installation Guide for Linux.
The following is an example of an OFA-compliant installation, which we use for this post:
| FSxZ volume | Unix mount | Description | OFA directory |
| /fsx/ora_biny | /u01 | Oracle Base | /u01/app/oracle |
| Oracle Home | $ORACLE_BASE/product/19.0.0/dbhome_1 | ||
| /fsx/ora_data | /u02 | Oracle Data Files Directories | /u02/app/oracle/oradata |
| /fsx/ora_logs | /u03 | Oracle Recovery Files | /u03/app/oracle/fast_recovery_area/ |
The database’s persistent storage is located on FSx for OpenZFS, which means that it relies on NFS for accessing storage. Therefore, you need to make sure that the NFS client utilities package is installed on the EC2 instance where you plan to install the database.For clients using Oracle Enterprise Linux, RedHat Enterprise Linux, CentOS, or similar kernels, run the following command to install the NFS utilities package:sudo dnf -y install nfs-utilsFor clients using a SUSE Linux kernel, run the following command to install the NFS client utilities package:sudo zypper install nfs-clientNow that the NFS client utilities are installed, you can mount the FSxZ volumes to the local Unix mount points at /u01, /u02, and /u03, as described previously.
Refer to Mount your file system from an Amazon EC2 instance for more information.
Step 5. Oracle database 19c installation on NFS
With FSx OpenZFS NFS mounted, create the OFA directories needed for Oracle software installation and database creation.
- Confirm that the mounts exist by running the following:
sudo mount | grep fsx
- Add the mount points to the /etc/fstab file to make sure that the mounts are available after a reboot of the kernel by running the following:
- Run the mount command to confirm all entries in the /etc/fstab file are correct. If any errors are received, then follow the Troubleshooting Amazon FSx for OpenZFS issues.
sudo mount -a
- As the root user, create the necessary directories:
Before installing Oracle 19c, you must prepare your Linux system with the necessary OS packages, kernel parameter and resource limits, and user groups. This post assumes that you’re using a supported Oracle Linux kernel and Amazon Machine Image (AMI) from the previous instructions.
The necessary Oracle packages for database installation can be found at the following link. Choose the Linux version corresponding to your installation.
Oracle database software can be downloaded from OTN or MOS depending on your support status.
- OTN: Oracle Database 19c (19.3) Software (64-bit)
- Necessary patches.
- edelivery: Oracle Database 19c (19.3) Software (64-bit)
If you are running RHEL 9 or Oracle Linux 9, then you need to follow the MOS “Requirements for Installing Oracle Database/Client 19c (19.22 or higher) on OL9 or RHEL 9 64-bit (x86-64)” (Doc ID 2982833.1).
Next, install the Oracle database software into the Oracle Home using the preceding OFA recommendations. Refer to the Installing Oracle Database in Database Installation Guide for Linux for more information and detailed instructions.
Step 6. Oracle database creation
When the Oracle database software has been installed, you are ready to create a new database. For this post, we use the Oracle Database Configuration Assistant (DBCA) tool in silent mode.
Verify Oracle database file locations:
Oracle file system options
For Oracle Database on NFS, we recommend setting filesystemio_options to setall. The Oracle Database filesystemio_options parameter has no effect in Oracle dNFS and ASM environments. The use of dNFS or ASM automatically results in the use of both asynchronous and direct I/O. However, we can always fall back to the OS NFS client in case of misconfiguration, thus its good practice to set filesystemio_options to setall, as a precaution, even if we don’t plan to use NFS.
filesystemio_options is not a dynamic parameter so a database bounce is needed for it to take effect.
Cleaning up
-
- Shutdown the Oracle database
- Unmount the FSx for OpenZFS volumes
- Delete the FSx for OpenZFS file system
- Terminate the EC2 instance
Conclusion
This guide demonstrates how to deploy a self-managed Oracle database on AWS using Amazon FSx for OpenZFS, which offers a robust, scalable, and efficient solution for various organizational needs. You can use FSx for OpenZFS’s high-performance capabilities to ensure your database handles demanding workloads while maintaining high availability. The built-in features such as compression, native replication, and zero-copy snapshots further enhance the value proposition by optimizing costs and streamlining disaster recovery.Setting up this environment involves choosing a suitable Amazon EC2 instance, deploying the FSx for OpenZFS file system with appropriate configurations, and properly configuring and mounting the volumes. Following the OFA guidelines ensures a streamlined and organized installation process. Installing Oracle Database 19c and creating the database on the NFS-mounted file system completes the setup, enabling you to use the flexibility and power offered by AWS infrastructure. This approach not only meets the rigorous requirements of enterprise-grade databases but also makes sure that you can scale and manage your resources efficiently.