AWS Storage Blog
How Zeta Global scales multi-tenant data ingestion with Amazon S3 Tables
Zeta Global is a data-driven marketing technology company that uses consumer insights to empower brands in customer acquisition, growth, and retention. At the core of its operations is the Zeta Marketing Platform, an advanced system that applies sophisticated AI and machine learning (ML) capabilities on proprietary data from over 245 million U.S. consumer profiles. This powerful combination enables the delivery of predictive insights and personalized consumer experiences at scale
Zeta Global uses Amazon S3 Tables—managed Apache Iceberg tables—to power its AI Marketing platform. Zeta Global’s architecture is built to handle massive scale, managing over 10,000 Iceberg tables, ingesting hundreds of gigabytes of data daily, and processing 2 TB per day, all while maintaining data freshness and optimizing for cost efficiency.
In this post, we share how Zeta Global addressed critical business challenges: reducing time-to-insight for streaming marketing data from hours to minutes, minimizing compute costs per customer through efficient resource sharing, and maximizing the value of Zeta’s multi-tenant infrastructure to serve thousands of clients simultaneously. The solution needed to eliminate data silos that were slowing decision-making, reduce the operational overhead of managing disparate systems for each tenant, and establish consistent data availability across all customers while scaling cost-effectively as Zeta’s client base grows.
Challenges
Before implementing this solution, Zeta faced several critical business challenges that were impacting the ability to serve customers effectively and maintain competitive margins:
Massive scale and infrastructure demands from campaign execution: Zeta’s marketing platform processes hundreds of terabytes of streaming data daily, driven by real-time campaign execution across thousands of clients. Each marketing campaign generates continuous streams of consumer interaction data, behavioral signals, and performance metrics that must be ingested immediately to enable timely campaign optimizations. Traditional infrastructure couldn’t scale cost-effectively to handle these massive data volumes while maintaining the sub-minute data availability that Zeta’s clients expect for campaign adjustments and real-time personalization decisions.
Cost-per-customer optimization in multi-tenant environment: The primary driver for platform modernization was reducing operational costs per customer while scaling Zeta’s business. The existing solution necessitated dedicated infrastructure resources for each major client, creating inefficient resource usage and making it difficult to achieve economies of scale. As the customer base grew from hundreds to thousands of clients, the cost structure became unsustainable, threatening the ability to maintain competitive pricing while delivering the performance levels needed for successful marketing campaigns.
Data freshness requirements for real-time marketing decisions: Marketing campaigns need immediate access to fresh data to optimize advertisement spend, adjust targeting parameters, and respond to consumer behavior changes. Delays in data availability directly translate to missed revenue opportunities and reduced campaign effectiveness for Zeta’s clients. The prior architecture often experienced data lag times of several hours during peak loads, causing clients to make decisions based on stale data and potentially waste significant advertising budgets on underperforming campaigns.
Solution architecture
Zeta’s solution uses S3 Tables as the foundation of the data lakehouse, as shown in the following figure. S3 Tables are designed to be interoperable with different processing frameworks and diverse query engines, supporting both batch and streaming pipelines.
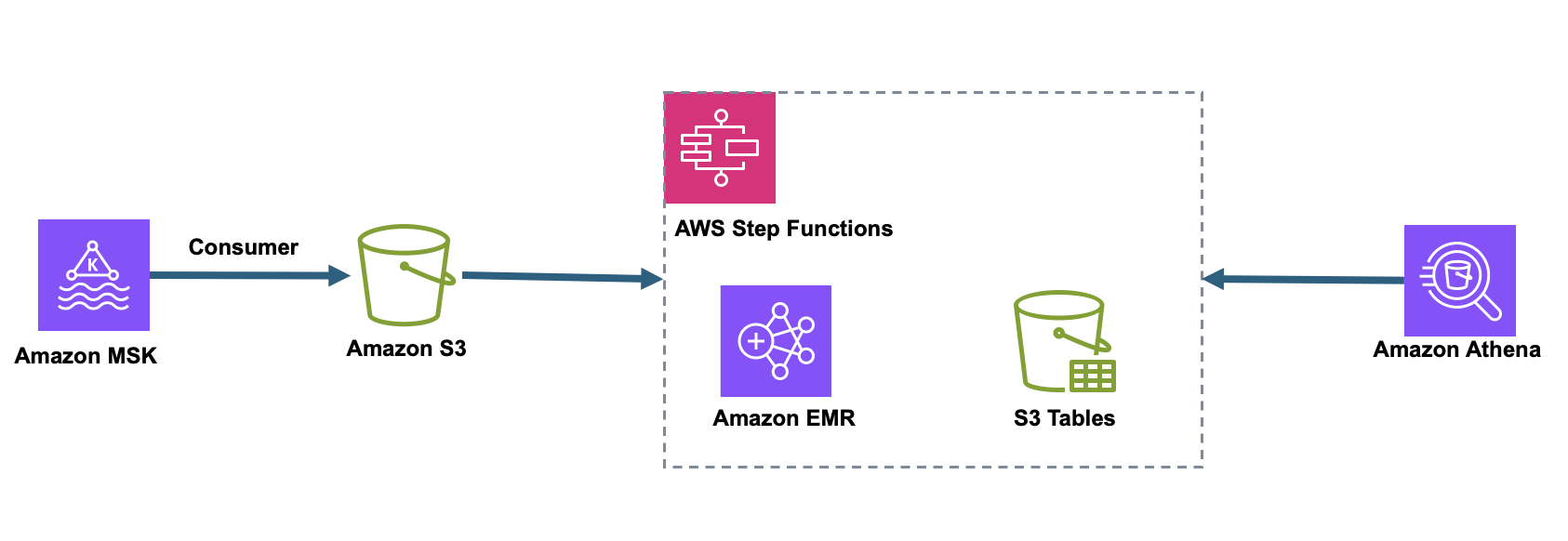
The architecture involves streaming data from Kafka into a general purpose Amazon S3 bucket, with data partitioned by tenant ID. The intermediate storage is for persisting raw data and tracking transformation consistently. AWS Step Functions is used to schedule and orchestrate tasks that run at regular intervals. As part of these tasks, it triggers Amazon EMR jobs that process and write data into S3 Tables. When the data is stored in S3 Tables, it can be queried using a range of tools, such as Amazon Athena, EMR, and Iceberg REST compatible third-party applications.
Key components of Zeta Global’s architecture
- AWS Step Functions as the orchestration layer to initiate and handle data ingestion.
- Bucket-based data partitioning for parallel processing allows the system to process multiple tenant datasets in parallel. Tenant data is distributed into configurable bins based on a hash function and the defined bin size (for example 2, 4, 8). This binning strategy allows balanced load distribution across processing jobs, allowing the system to process multiple tenant datasets in parallel. The hash-based binning further improves the system’s performance through Apache Iceberg’s hidden partitioning. Hidden partitioning abstracts the physical layout of the data to streamline query optimization and enable efficient data access across diverse tenant workloads, all without exposing partition complexity to the end user.
- Pessimistic locking mechanism coordinates access to files in a general purpose S3 bucket and maintains data integrity so that only one job can process the files at any given time. The team chose pessimistic locking over optimistic locking because it guarantees strong consistency and data integrity, which are critical for handling sensitive marketing data. However, Iceberg prefers optimistic locking by default. Although pessimistic locking may introduce performance overhead due to lock contention—potentially causing longer wait times or deadlocks—the risk of data corruption from concurrent writes outweighs these trade-offs. Making sure of correctness under parallelism was a higher priority than optimizing for throughput alone.
- Asynchronous Spark jobs are launched asynchronously to process each bucket with callback mechanisms for progress tracking.
- Automated failure recovery mechanism handles file lock management by automatically releasing locks on failed files after unsuccessful processing attempts. If multiple retry attempts result in consistent failures, then the workflow is marked as failed.
Workflow orchestration
Zeta’s implementation follows a lock-first, process-later model that prevents race conditions and avoids overlapping writes, as shown in the following figure.
- Lock acquisition: Before initiating any ingestion workflow, Step Functions acquires a lock.
- Data partitioning: After securing the lock, the system partitions tenant data into configurable buckets using a hash function.
- Parallel processing: Spark jobs are launched asynchronously to process each bucket, with controlled concurrency.
- Callback mechanism: Each Spark job, upon completion, triggers a callback to Step Functions, confirming successful execution and allowing system to safely release the lock.
- Failure handling: If any job fails, then Step Functions provides proper clean up by removing orphaned lock or temporary files, releasing the held lock, and marking the workflow as failed, thus supporting robust retry handling.
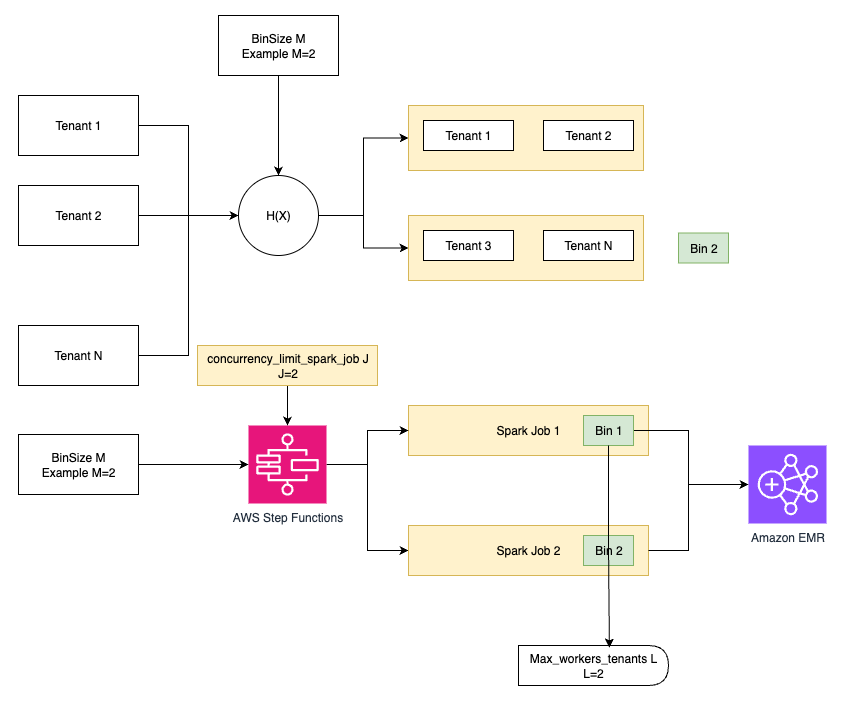
Step Functions provides a single point of control and visibility as the centralized orchestrator for complex multi-tenant workflows. This is particularly advantageous for a multi-tenant system managing thousands of tables and high data volumes, because it makes sure of the consistent application of business logic, such as the “lock-first” model, across all tenants. Zeta’s multi-tenant platform requires strong control and observability, making a centralized orchestrator such as Step Functions a fitting choice over extreme decentralization, a common trade-off in highly distributed systems.
Performance tuning and optimization
Zeta’s ingestion platform provides several configurable parameters that allow operators to fine-tune performance characteristics based on specific tenant requirements and resource constraints. The bin size parameter controls the distribution of tenant data across processing buckets using a hash-based algorithm—for example, setting the bin size to four distributes a tenant’s data across four separate bins, enabling parallel processing while maintaining data locality and reducing cross-partition operations. The concurrency setting determines the maximum number of Spark jobs that can run simultaneously across all bins, creating a controlled processing pipeline where completed jobs immediately trigger the next queued bucket to begin processing. This makes sure of optimal resource usage without overwhelming the cluster. Furthermore, the thread workers parameter governs the degree of parallelism within each individual Spark job, allowing fine-grained control over CPU and memory usage per processing unit. These three tuning parameters work in concert to provide operators with precise control over the performance-cost trade-off, enabling the system to scale from processing small tenant datasets with minimal resource allocation to handling enterprise-scale workloads that require maximum throughput and parallel processing capacity.
Zeta Global has used S3 Tables to achieve exceptional scalability managing over 4,000 tables across multiple tenants, data integrity with consistency guarantees under parallelism, and operational efficiency processing tens of terabytes daily with optimized resource usage. The platform provides flexibility supporting diverse query engines and resilience through automated recovery mechanisms. S3 Tables enhance these benefits with automated file optimization that merges smaller data objects into larger 512 MB files for improved query performance, snapshot management that automatically retains and expires table snapshots, and unreferenced file removal that identifies and deletes orphaned data objects to optimize storage usage.
Conclusion
The implementation of a scalable multi-tenant data ingestion platform built on Amazon S3 Tables has enabled Zeta Global to efficiently manage and process massive volumes of data while maintaining strict data integrity. The platform’s parameterized approach allows Zeta to maximize throughput and lower cost to match evolving scale and performance goals.
Zeta Global used S3 Tables to generate this architecture for ingestion, and it forms the foundation of Zeta’s robust, scalable, and query-efficient data lakehouse, supporting Zeta’s Marketing and Data Cloud platform’s growing requirements.