AWS Storage Blog
Tag: Amazon Athena

How Vanderbilt University scales digital archive discovery with Amazon S3 Metadata
Managing massive digital collections is hard. When you’re preserving decades of historical content and adding new materials daily, making that content discoverable matters more than the storage itself. Vanderbilt University Library discovered this firsthand while managing their extensive digital archives, including the renowned Vanderbilt Television News Archive (VTNA). Amazon S3 Metadata accelerates data discovery by […]

Query Amazon S3 access logs instantly with CloudWatch and S3 Tables
Knowing who accessed your data, when, and how is the foundation for security investigations, compliance audits, cost attribution, and performance troubleshooting. Detailed access logs capture every request: who made it, which resource was accessed, and what response was returned. In practice, though, they arrive as semi-structured records spread across different locations. Turning them into actionable […]
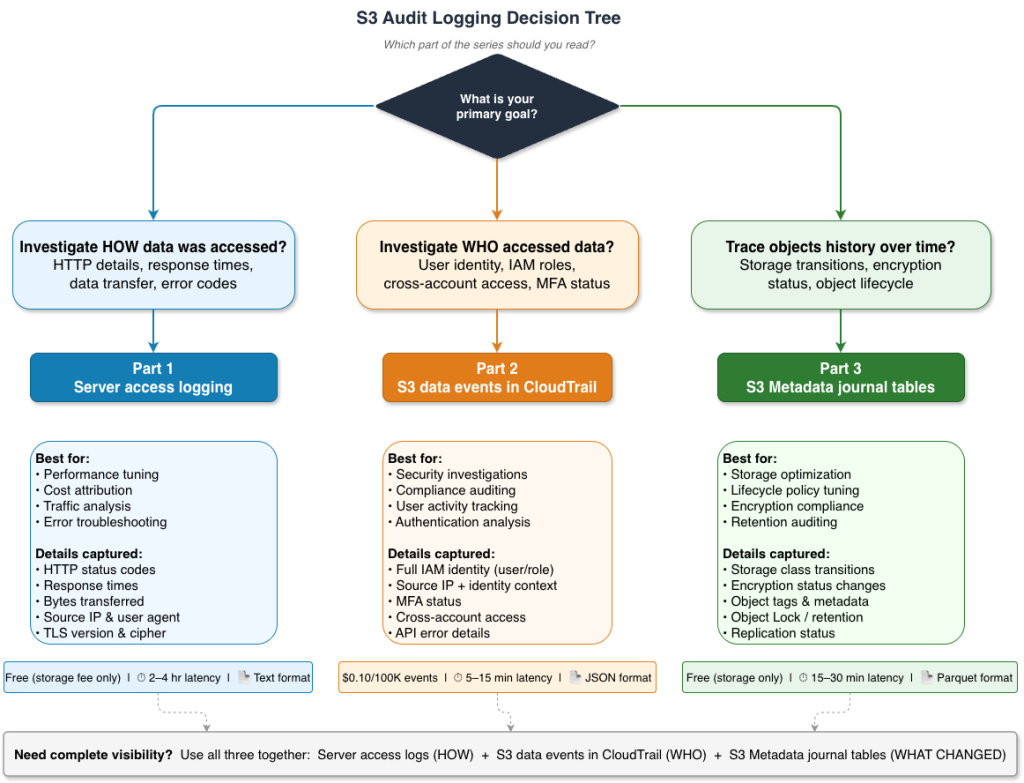
Amazon S3 audit logging, Part 3: Analyzing S3 Metadata journal tables for object lifecycle tracking
This is Part 3 of our three-part series on Amazon S3 audit logging. In Part 1, we covered server access logs for HTTP-level requests and performance analysis. In Part 2, we covered S3 data events in AWS CloudTrail for identity-focused security investigations. As data volumes grow and storage costs become a significant line item, organizations […]
Amazon S3 audit logging, Part 2: Centralized logging and analysis of S3 data events in AWS CloudTrail for security and compliance
This is Part 2 of our three-part series on Amazon S3 audit logging, focusing on identity-driven security investigations. In Part 1, we covered S3 server access logs for HTTP-level performance analysis and cost attribution. When a security incident occurs—an unauthorized download, a bulk deletion, or suspicious access from an unfamiliar location—the first question is always, […]
Amazon S3 audit logging, Part 1: Analyzing server access logs with Amazon Athena for performance insights
Organizations storing sensitive data must maintain complete visibility into how it’s accessed, by whom, and what changes occur over time. Regulatory frameworks demand detailed audit trails, security teams need rapid answers during investigations, and finance teams require granular cost attribution. Yet as data grows from terabytes to petabytes, the scale that makes centralized storage attractive […]

Data discovery: How to find out what’s on your Amazon FSx for NetApp ONTAP volumes
Enterprise storage administrators manage hundreds of terabytes, and sometimes petabytes, of file data spanning business units, applications, and users. As that storage grows, so does the challenge of understanding what is actually stored in it. Administrators are asked to make capacity decisions, identify archive candidates, track storage costs, and support compliance reviews — but with […]
Enabling natural language access to structured data using Amazon S3 Tables and Amazon Bedrock Knowledge Bases
Organizations generate massive volumes of structured data from customer transactions, operational metrics, product catalogs, and compliance records. This data contains insights that can help businesses make better and timely decisions. Financial advisors need to review client transaction histories, retail analysts track inventory trends, and healthcare administrators monitor patient outcomes. Yet accessing these insights creates a […]

Building automated AWS Regional availability checks with Amazon S3
Every day, organizations expand into new markets, migrate critical workloads across geographies, and build systems that need to operate reliably in multiple locations. At the root of these efforts is a simple question: “What can I deploy, and where?” The answer shapes important architecture decisions, from which AWS Regions to expand into, to how you […]

Applying Amazon S3 Object Lock at scale for petabytes of existing data
Organizations with petabytes of data in the cloud need a way to apply immutable storage protections to data that’s already been stored—whether for regulatory compliance or cyber resilience. Although you can enable write-once-read-many (WORM) controls for newly created storage, applying these protections to existing enterprise data at scale requires a systematic approach. Regulated industries have […]

Architecting high performance AI-driven data applications with Spice AI and AWS
As enterprises scale their adoption of generative AI, one of the biggest technical challenges is connecting AI applications to the right data and making that data fast, accessible, and secure. AI agents are transforming industries through applications like customer support automation, personalized e-commerce recommendations, and research assistance in financial services and healthcare. These applications require […]