亚马逊AWS官方博客
Amazon Bedrock模型推理的Serverless 异步架构 – 处理在线多模态高负载案例
摘要:当大模型应用从纯文本扩展到图片、PDF 等多模态输入时,推理耗时长且不可预测、RPM/TPM限流频发成为生产落地的两大瓶颈。本文分享一套基于 Amazon SQS 与 AWS Lambda Serverless 异步架构,在 Amazon Bedrock之上串起缓冲、控速、重试与结果入库的完整管道,经多模型压测验证可稳定支撑高并发多模态负载,适用于内容审核、文档处理、合规审查及多 Agent 协作等场景。
目录
一、引言
越来越多企业将大模型应用搬入生产系统,场景也从纯文本扩展到多模态——图片审核、PDF 信息提取、文档摘要和多 Agent 协作调用。但当多模态输入遇上高并发调用的时候,两个瓶颈几乎无法回避:
本文分享一套基于 Amazon Simple Queue Service (Amazon SQS) 和 AWS Lambda 的 Serverless 异步架构,在 Amazon Bedrock 上解决这些瓶颈。客户端提交任务后立即拿到任务 ID,不用同步等模型跑完;任务在后台排队处理,结果写入数据库,客户端随时查询。推理慢不阻塞用户,突发流量不丢请求。这种模式适合用户触发、需要知道结果、但不愿意盯着等的任务——内容审核、文档处理、合规检查都是典型场景。Agent 场景也一样,每个子任务独立入队,调用方随时查进度,不用同步等整个 Agent 链跑完。
我们以内容审核为例来拆解架构,但同样的模式适用于文档处理流水线、商品数据增强、合规审查,以及多 Agent 协作调用多模态模型等场景。
二、Amazon Bedrock 推理 API 概览
先看一下 Amazon Bedrock 提供的几种推理方式:
| API | 适用场景 | 特点 | 局限性 |
| Converse / InvokeModel | 实时短推理 | 同步调用,Converse 是跨模型统一接口 | 突发受RPM/TPM配额限制 |
| ConverseStream | 聊天对话 | 流式输出,首 token 响应快 | 同上 |
| StartAsyncInvoke | 单个长任务(视频生成等) | 异步调用,结果存 S3 | 仅视频生成等特定模型(Nova Reel、Twelve Labs 等) |
| (batch)CreateModelInvocationJob | 离线批量 | 批处理折扣 | 延迟分钟到小时级 |
下面的决策流程图帮你快速判断该选哪种方式:
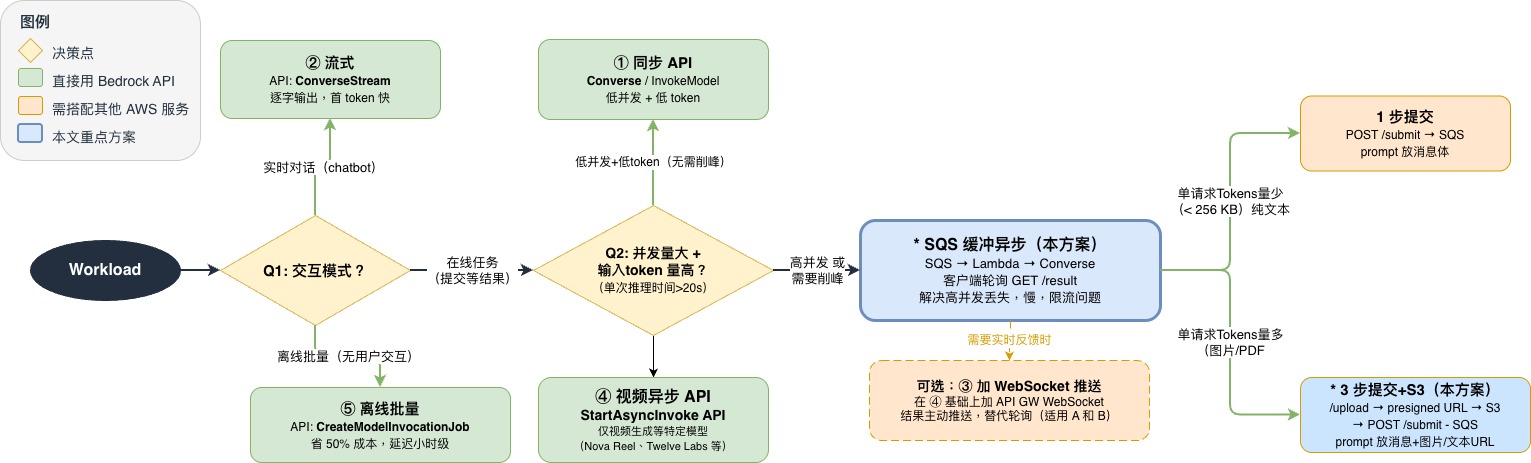
[图1] |
当我们的场景是”高并发且持续上传文件,要尽快拿到结果”,现有的API无法满足需求。Converse 是同步的,突发流量可能会遇到网络资源或超出TPM/RPM;StartAsyncInvoke 虽然是异步的,但没有内置的队列缓冲和并发控制,会被限流,而且结果只存S3,后续自行处理通知;Batch Job 延迟太高。所以需要在 Converse API 之上自己搭一层异步架构,把缓冲、控速、重试、结果入库串成一个完整管道。
三、为什么需要异步架构
3.1 挑战一:处理时间长且不可控
多模态输入的 token 消耗比纯文本高很多,处理时间也随之增长。我们实测了不同输入类型(Nova 2 lite, haiku 4.5, sonnet 4.6, opus 4.6)的推理时间。
| 输入类型 | 文件大小 | Input Tokens | 推理时间 |
| 单张图片 | 114 KB | ~1,600 | 1-5s |
| 20 页带图 PDF | 4.5 MB | ~33,000 | 20-26s |
| 100 张图片 | 11.1 MB | ~23,000 | 50~70s |
多图或多页 PDF 单次 token 消耗高,各模型都要 20 秒以上。在应用服务端,同步调用每个请求占用一个线程,高并发时也需要处理大量线程阻,服务端资源耗尽,网络中断恢复等问题。而且多个服务实例同时调用模型 API,没有全局并发控制,突发流量会直接触发限流(见挑战二)。需要一个异步机制来持久化任务、释放服务端资源、统一控速,让应用提交任务后立即返回,处理在后台可靠完成。
3.2 挑战二:突发流量直接触发限流
主流大模型 API 都有 RPM(每分钟请求数)和 TPM(每分钟 token 数)配额限制,Amazon Bedrock 也不例外。多模态请求的 token 量远高于纯文本,RPM 和 TPM 两道限制更容易同时触发。我们对多个模型做了多轮 100-600 并发的突发测试(图片和多文件 PDF),发现高并发不做流量控制,大量请求会直接失败丢失(详见压测章节)。
这两个挑战的本质一样:客户端直接调 Bedrock API,既没有缓冲也没有并发控制。解决思路是在调用方和 Bedrock 之间加一层队列,把’同步等结果’变成’提交即返回、后台慢慢消化”。
四、方案:Amazon SQS + AWS Lambda 异步管道
针对上面两个挑战,我们基于 AWS 博客 Serverless generative AI architectural patterns — Part 2 中针对长耗时推理任务的模式进行扩展。让方案可以处理多模态高并发场景——支持图片、PDF 等大文件的批量上传,并且能做失败的自动重试。核心思路是三个:
- 提交即返回,处理在后台:应用端提交文件后立即拿到任务 ID,不需要同步等模型跑完。处理时间再长也不影响用户体验,网络断连也不会丢请求——任务已经持久化在队列里
- 队列缓冲 + 并发控制 = 精确调速:突发流量先进 Amazon SQS 队列排队,SQS 事件源映射的 MaximumConcurrency 限制同时调 Amazon Bedrock 的请求数。效果等同于把一波涌入的请求拉平成稳定的持续速率,从根源上避免限流
- 失败自动重试,不丢数据:单条消息处理失败只重试那条,不影响其他。重试多次仍失败的进入死信队列(DLQ),既不阻塞流水线,也不丢数据
整套架构全部使用按需付费的 Serverless 服务,不需要预置和管理服务器。
五、架构详解
5.1 整体架构
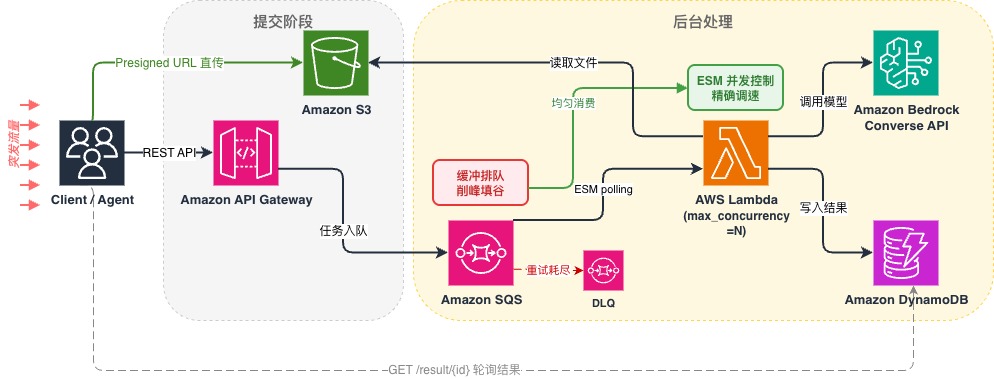
[图2:SQS + Lambda 异步管道架构 — 突发流量经 SQS 缓冲排队,Lambda 并发控制均匀消费,实现削峰填谷] |
5.1.1 提交阶段(应用端)
提交阶段的处理逻辑在应用端完成。根据输入数据大小,有两条路径:
文本提交:应用端直接调 POST /submit,把 prompt 放在请求体中提交。Submit Lambda 将 prompt 写入 Amazon SQS 消息体(上限 256 KB),API 立即返回任务 ID。
大文件提交(图片、PDF 等):图片、PDF 等大文件无法直接放入消息体传递,需要借助 Amazon S3 中转,分为三步。一是应用端调 POST /upload,获取 presigned URL 和任务 ID。二是应用端通过 presigned URL 把文件直传 Amazon S3。三是应用端调 POST /submit 确认提交,Submit Lambda 往 Amazon SQS 发一条任务消息(包含 prompt + S3 key 列表),API 立即返回任务 ID。 上传和提交分两步,是为了确保文件就绪后才触发处理,避免竞态问题。
5.1.2 后台处理阶段
任务进入 Amazon SQS 后的处理流程完全一样:Amazon SQS 缓冲住所有突发请求,处理 Lambda 从队列拉消息,构建 Amazon Bedrock Converse API 请求——一个任务 = 一条 SQS 消息 = 一次 Bedrock 调用,不管里面有几个文件。结果写入 Amazon DynamoDB。
5.1.3 获取结果
应用代码拿着任务 ID 轮询 GET /result/{id} 查结果,拿到后更新页面或继续下游逻辑。对终端用户来说,看到的只是”处理中 → 完成”,轮询过程完全由应用代码自动完成。对于 Agent 或后端服务,可以把提交 + 轮询封装为同步函数,调用方无感知异步管道。多个 Agent 同时调用也不会触发限流——请求都在队列里排队,由并发控制逐步消化。
5.2 关键组件
5.2.1 SQS 事件源映射:连接队列与 Lambda
Amazon SQS 本身是一个被动的消息队列——消息进来就存着,不会主动推送给任何人。真正驱动整个异步管道的是 AWS Lambda 的事件源映射(Event Source Mapping,ESM)。ESM 是 Lambda 服务内置的轮询器,持续从 SQS 拉取消息、攒成一批调用 Lambda 函数、读取返回值决定哪些消息成功删除、哪些需要重试。削峰靠 Amazon SQS 排队,控速靠 ESM 限制并发——两者配合才是完整的调速机制。
5.2.2 并发控制 = Amazon Bedrock 调速阀
ESM 的 MaximumConcurrency 参数直接决定了同时有多少个 AWS Lambda 实例从队列拉消息处理。设 max_concurrency = 10,就是最多 10 个 Lambda 实例同时运行,也就是最多 10 个并发 Amazon Bedrock 调用。其余请求待在 Amazon SQS 队列里,等有空闲的 Lambda 实例,ESM会自动拉取投递。
5.2.3 Partial Batch Failure + 死信DLQ队列
在ESM开启 ReportBatchItemFailures 后,Lambda handler 可以通过返回值告诉ESM哪些消息处理失败——ESM把失败的消息放回队列重试。注意 ReportBatchItemFailures 必须显式开启,否则 handler 返回的 batchItemFailures 会被忽略,任何一条消息失败都会导致整批重试。配上死信队列(DLQ),Amazon SQS 会为每条消息维护接收计数,重试超过 maxReceiveCount 次仍失败的消息自动进 DLQ,既不阻塞后续处理,也不丢数据。生产环境里可以针对 DLQ 做告警和人工复查。
六、压测验证
我们对多个 Claude 模型和 Nova Pro 做了系统性压测,覆盖图片和多文件 PDF 两种输入,验证直连调用和 SQS 管道在不同负载下的表现。
6.1 RPM 瓶颈:突发流量触发限流
Amazon Bedrock 的 RPM(每分钟请求数)配额可通过工单提升,但突发场景仍易受限。以 200 RPM 的 Claude Sonnet 4 为例,同时发出 300 个图片请求(每请求 ~1,617 tokens),不做流量控制时 75% 请求失败。走 SQS 管道后,请求进队列缓冲,Lambda 按并发 5 逐步处理,全部成功零限流。本质是把突发流量削峰填谷,从瞬时高峰均摊到时间窗口内。
| 方式 | 用户等待时间 | 全部完成耗时 | 成功率 | 适用场景 |
| 同步直接调用 | 9 秒(阻塞等待) | 9 秒(234 个丢失) | 22% | 低并发实时 |
| 同步直调+重试 | 353 秒(阻塞等待 6 轮) | 353 秒 | 100% | 自行实现重试逻辑 |
| SQS 异步管道(mc=5) | < 1 秒(提交即返回) | 221 秒 | 100% | 在线持续流入 |
| Batch Job | < 1 秒(提交即返回) | ~11 分钟 | 100% | 离线批量(性价比高) |
在速度方面,调整好SQS异步管道比Batch Job以及客户端重试快,而且每条结果处理完就能立即查到,不用等整个 job 跑完或等重试轮次结束。客户端重试虽然最终能全部成功,但 6 轮重试产生多次限流,浪费大量 API 调用且需要自行实现重试逻辑。Batch Job 的优势是价格折扣,适合对延迟不敏感的离线场景。
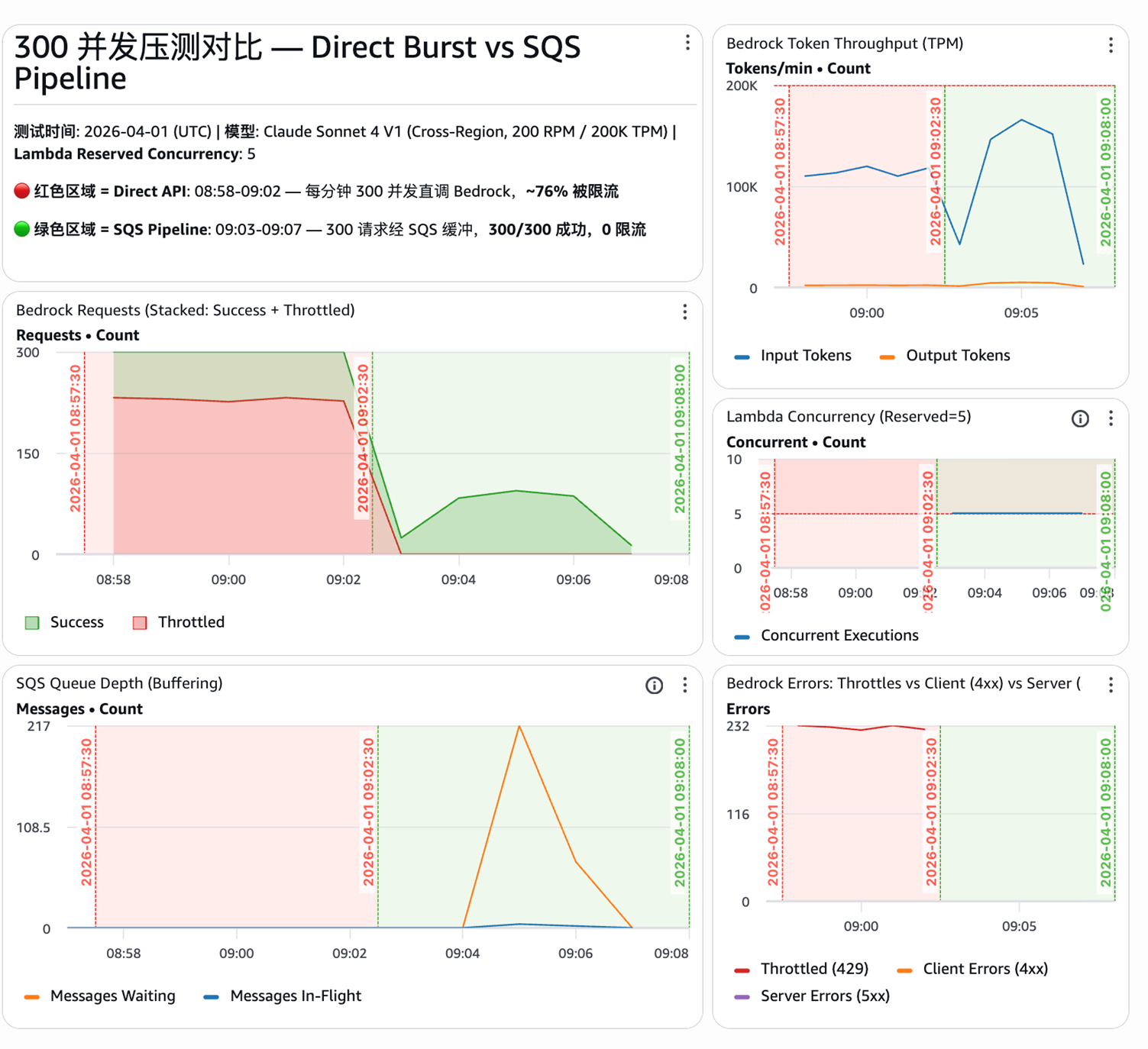
[图3:CloudWatch 监控截图] |
红色区域是直连调用阶段,每分钟约 230 次限流;绿色区域是 SQS 管道阶段,Lambda 并发稳定在 5,300 个请求全部成功,限流归零。
6.2 TPM 瓶颈:多模态大文件加剧限流
多模态请求的 token 消耗远高于纯文本(单张图片 ~1,600 tokens,多文件 PDF 可达 ~70,000 tokens/请求),更容易触发 TPM(每分钟 token 数)限制。实测中,PDF 解析错误、ModelErrorException 等非限流类失败也会随着并发量高出现。二SQS 管道统一解决了这些问题:
| 模型 | TPM 配额 | 并发 | 输入 | 直连+重试 | SQS 管道 | |
| Claude Sonnet 4 | 200K | 300 | 图片×1 (~1.6K t) | 首次24%成功 ,6轮342.5s | 221s, 100%, 并行mc=5 | |
| Claude Opus 4.5 | 2M | 150 | 4MB PDF×5 (~70K t) | 首次48%成功 ,3轮408.3s | 387s, 100%, 并行mc=40 |
6.3 大规模 SQS 管道压测
为验证 SQS 管道在更高负载下的可靠性,我们分别用两个模型做了大规模压测。 Nova Pro 直连 600 并发,三分之一请求直接失败且无法恢复;SQS 管道虽然总耗时更长(请求排队处理),但全部成功。Nova 2 Lite 的 2000 请求共计 20 万张图片,SQS 管道同样 100% 完成。
| 指标 | Nova Pro 600并发×5 PDF | Nova 2 Lite 2000并发×100 图 |
| 模型配额 | 250 RPM / 1M TPM | 2000 RPM / 8M TPM |
| 总请求数 | 600(每请求 5 个 4MB PDF) | 2,000(每请求 100 张图片) |
| 每请求 tokens | ~71K | ~23K |
| 并行请求数量 | 18 | 400 |
| SQS 管道成功率 | 600/600 (100%) | 2,000/2,000 (100%) |
| SQS 管道总耗时 | ~30 分钟 (可调整,并行请求越高,时间越短) | ~7.5 分钟 |
七、核心代码与部署配置
7.1 参数调优
7.1.1 max_concurrency
max_concurrency 直接决定同时有多少个 Lambda 同时调用 Bedrock,相当于 Bedrock 的调速阀。并行值越大吞吐越高,更容易超过模型的 RPM/TPM 配额触发限流。虽然 SQS 会自动重试失败的消息,但限流过多会导致消息反复重试、队列膨胀,反而拖慢整体完成时间。 建议分别按 RPM 和 TPM 计算限额下最高并行请求值 mc_rpm 和 mc_tpm,取较小值作为起点。其中 RPM 是硬限制,mc_rpm 不能超;TPM 有一定弹性,实测中部分模型的 mc_tpm 可上调,具体需实测验证。
mc_rpm = RPM额度 × 单次平均处理的时间avg_time / 60秒
mc_tpm = TPM额度 × 单次平均处理的时间avg_time / (每个请求的Token量×60秒)
max_concurrency = min(mc_rpm,mc_tpm)
7.1.2 Timeout 链路计算
这条管道涉及三个 timeout,分别配置在不同的组件上:read_timeout 在 Bedrock SDK 客户端配置,Lambda timeout 在 Lambda 函数配置,visibility_timeout 在 SQS 队列配置。三者直接影响系统行为:设太小,请求会被中断或消息被重复处理;设太大,失败的消息会长时间滞留队列才能重试,拖慢整体完成时间。三个 timeout 必须按 visibility_timeout > Lambda timeout > read_timeout > 实际处理时间 层层递增,每一层大于内层。 | 参数 | 配置位置 | 必须大于 | 原因 | |—|—|—|—| | read_timeout | Bedrock SDK | 最慢请求的处理时间 | SDK 等待模型响应的上限,小于处理时间会导致 SDK 提前断开,请求白做 | | Lambda timeout | Lambda 函数 | read_timeout | Lambda 还需要读 S3、写 DynamoDB,若 ≤ read_timeout 可能 Bedrock 完成了但 Lambda 来不及写结果就被终止 | | visibility_timeout | SQS 队列 | Lambda timeout | 消息”隐藏”的时间,若 ≤ Lambda timeout,Lambda 还没处理完消息就重新出现被重复拉取。同时也是失败消息的重试间隔——设太长(如 720s),被限流的消息要等 12 分钟才能重试;设太短又会导致消息重复处理 |
配置建议:根据输入类型的实测耗时,两种典型场景的推荐配置如下:
| 参数 | 图片场景(1-5 张) | 大文件 PDF 场景(20+ 页 / 多文件) |
| 实测处理时间 | 1-6s | 20-70s |
| read_timeout | 30s | 120s |
| Lambda timeout | 60s | 180s |
| visibility_timeout | 120s | 300s |
图片场景处理快,timeout 可以设得紧凑,失败消息 2 分钟内即可重试。大文件 PDF 单次推理可能 60 秒以上(如 5 个 4MB PDF 约 70s),每层 timeout 都需要留足余量。如果业务同时包含两种输入,按最慢的场景配置——timeout 偏大的代价只是失败重试稍慢,而偏小会导致请求被中断或消息重复处理。
7.2 处理 Lambda 代码
整条管道涉及多个 Lambda(Upload、Submit、Result 等),但核心逻辑集中在处理 Lambda——它从 SQS 拉取消息、调用 Amazon Bedrock、写入结果,是唯一与模型交互的组件,也是限流和重试策略的实际执行者。其余 Lambda 只做轻量的 API 转发(生成 presigned URL、发 SQS 消息、查 DynamoDB),逻辑简单,这里不展开。
处理Lambda Function从 SQS 消息读取 S3 key 列表和 prompt,读取所有文件,构建一次 Converse API 请求。开头加幂等检查——SQS 是 at-least-once 投递,消息可能被重复消费,必须防止重复处理。Bedrock client 配置需要注意两点:read_timeout 要覆盖最慢的请求(多文件 PDF 可能 60 秒以上),max_attempts=1 让失败快速返回给 SQS 重试,而不是 SDK 内部重试占用 Lambda 时间。SQS 重试之间有 visibility timeout 冷却期,比 SDK 立即重试更安全。
handler 用 batchItemFailures 实现 Partial Batch Failure——单条失败只重试那条,不影响同批其他消息:
7.3 生产环境配置要点
以下是核心基础设施的 CDK 配置。
八、总结
回到开头提的两个瓶颈——推理慢和限流,这套 Amazon SQS + AWS Lambda 异步管道都给出了实测验证的解法:
- 限流:SQS 排队 + ESM MaximumConcurrency 控速,300 并发突发 0% 限流,2000 并发 20 万张图片也全部完成
- 长耗时:提交即返回,2s-70s 的推理在后台跑完。单条失败只重试那条(Partial Batch Failure),重试多次仍失败的进死信队列,不丢数据
- 调优:max_concurrency 按模型 RPM/TPM 配额和单次处理时间算;三层 timeout(visibility_timeout > Lambda timeout > read_timeout)按场景配,图片可以紧凑,PDF 要留余量
模型选型与成本:对于图片和文档审核等多模态批量任务,Amazon Nova 2 Lite 是高性价比之选。Nova 2 Lite 对所有图片和文档页面统一按 ~230 tokens 计费,不论分辨率和页面复杂度, Claude 系列每张图片优化到~1,600 tokens。因此在本文大规模测试时候,选用Nova。
➡️ 下一步行动:
相关产品:
- Amazon SQS — 托管式消息队列
- AWS Lambda — 无需服务器即可运行代码
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon Nova — 提供前沿智能和最高性价比的基础模型
- Amazon Batch — 完全托管式批处理
九、参考资料
- Serverless generative AI architectural patterns — Part 2
- Amazon Bedrock Converse API 文档
- Using AWS Lambda with Amazon SQS
- Lambda Concurrency Configuration
- Scaling and processing with SQS event source mappings
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
