亚马逊AWS官方博客
Amazon MSK 推出从 Apache Kafka 到您的数据湖的托管数据传输
我很高兴地宣布 Amazon Managed Streaming for Apache Kafka(Amazon MSK)今天发布一项新功能,让您能够将数据从 Apache Kafka 集群持续加载到 Amazon Simple Storage Service(Amazon S3)。我们使用 Amazon Kinesis Data Firehose(一种提取、转换、加载(ETL)服务)从 Kafka 主题中读取数据,转换记录,然后将其写入 Amazon S3 目标。Kinesis Data Firehose 是完全托管的,只需在控制台中单击几下即可对其进行配置。无需任何代码或基础设施。
Kafka 通常用于构建实时数据管道,以便在系统或应用程序之间可靠地移动大量数据。它提供了一个高度可扩展且容错的发布/订阅消息收发系统。许多客户采用 Kafka 来捕获点击流事件、交易、物联网事件、应用程序和机器日志等流数据,并拥有执行实时分析、运行连续转换并将这些数据实时分发到数据湖和数据库的应用程序。
但是,部署 Kafka 集群并非没有挑战。
第一个挑战是部署、配置和维护 Kafka 集群本身。这就是我们在 2019 年 5 月发布 Amazon MSK 的原因。MSK 减少了在生产环境中设置、扩展和管理 Apache Kafka 所需的工作量。我们将处理基础设施事宜,让您可以腾出时间专注于数据和应用程序。第二个挑战是编写、部署和管理使用 Kafka 数据的应用程序代码。它通常需要使用 Kafka Connect 框架对连接器进行编码,然后部署、管理和维护可扩展的基础设施来运行连接器。除了基础设施外,您还必须对数据转换和压缩逻辑进行编码,管理最终错误,并对重试逻辑进行编码,以确保从 Kafka 传出的过程中不会丢失任何数据。
今天,我们宣布推出一款完全托管的解决方案,用于通过 Amazon Kinesis Data Firehose 将数据从 Amazon MSK 传输到 Amazon S3。该解决方案是无服务器的,无需管理服务器基础设施,也不需要代码。只需在控制台中单击几下即可配置数据转换和错误处理逻辑。
下图展示了此解决方案的架构。

Amazon MSK 是数据来源,Amazon S3 是数据目标,Amazon Kinesis Data Firehose 则负责管理数据传输逻辑。
使用此新功能时,您不再需要开发代码来从 Amazon MSK 读取数据、转换数据并将结果记录写入 Amazon S3。Kinesis Data Firehose 会管理对 Amazon S3 的读取、转换和压缩以及写入操作。它还会处理错误和重试逻辑,以防出现问题。系统会将无法处理的记录传送到您选择的 S3 存储桶以供手动检查。该系统还会管理处理数据流所需的基础设施。它将横向扩展和缩减,以适应要传输的数据量。您无需进行任何配置或维护操作。
Kinesis Data Firehose 传输流支持公共和私有 Amazon MSK 预配置集群或无服务器集群。它还支持跨账户连接,以便从 MSK 集群中读取数据以及写入不同 AWS 账户中的 S3 存储桶。Data Firehose 传输流从您的 MSK 集群读取数据,将数据缓冲到可配置的阈值大小和时间,然后将缓冲的数据作为单个文件写入 Amazon S3。MSK 和 Data Firehose 必须位于同一 AWS 区域,但是 Data Firehose 可以将数据传输到其他区域的 Amazon S3 存储桶。
Kinesis Data Firehose 传输流也可以转换数据类型。它具有内置的转换功能,支持从 JSON 转换为 Apache Parquet 和 Apache ORC 格式。这些是列式数据格式,可以节省空间并加快在 Amazon S3 上的查询速度。对于非 JSON 数据,您可以使用 AWS Lambda 将 CSV、XML 或结构化文本等输入格式转换为 JSON,然后再将数据转换为 Apache Parquet/ORC。此外,您可以在将数据传输到 Amazon S3 之前从 Data Firehose 指定数据压缩格式,例如 GZIP、ZIP 和 SNAPPY,也可以将数据以原始形式传输到 Amazon S3。
下面我们来看看它的工作原理
首先,我使用了一个 AWS 账户,其中已经配置了 Amazon MSK 集群,还有一些应用程序向其流式传输数据。要开始并创建您的第一个 Amazon MSK 集群,建议您阅读本教程。
在本演示中,我使用控制台创建和配置数据传输流。或者,我也可以使用 AWS 命令行界面(AWS CLI)、AWS SDK、AWS CloudFormation 或 Terraform。
我导航到 AWS 管理控制台的 Amazon Kinesis Data Firehose 页面,然后选择创建传输流。
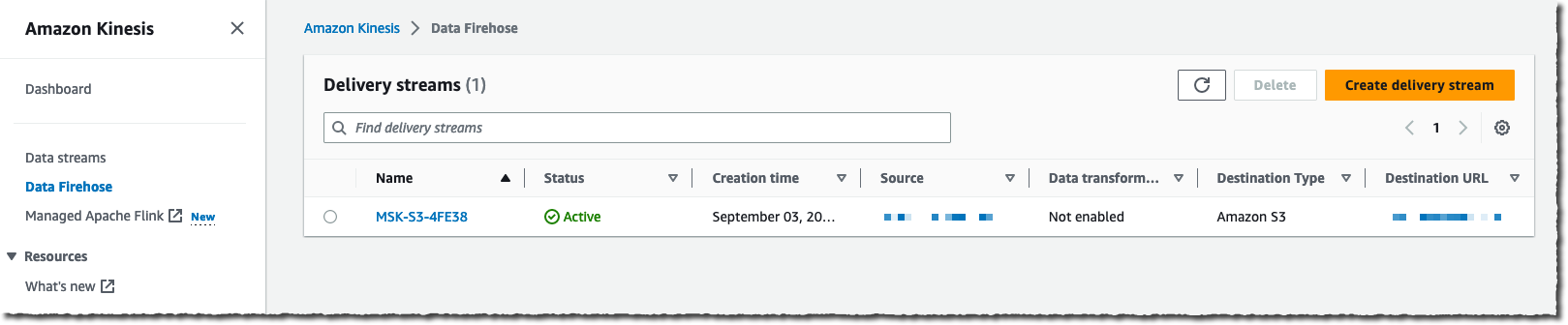
我选择 Amazon MSK 作为数据来源并选择 Amazon S3 作为传输目标。在本演示中,我想连接到私有集群,因此我在 Amazon MSK 集群连接下选择私有引导代理。
我需要输入集群的完整 ARN。和大多数人一样,我记不住 ARN,所以我选择浏览并从列表中选择我的集群。
最后,我输入要从中读取此传送流的集群主题名称。

完成来源配置后,我向下滚动页面以配置数据转换部分。
在转换和转换记录部分,我可以选择是提供自己的 Lambda 函数来转换非 JSON 格式的记录,还是要将我的源 JSON 记录转换为两种可用的预建目标数据格式之一,即 Apache Parquet 或 Apache ORC。
在从 Amazon S3 查询数据方面,Apache Parquet 和 ORC 格式比 JSON 格式更高效。当源记录采用 JSON 格式时,您可以选择这些目标数据格式。您还必须提供 AWS Glue 中的表的数据架构。
当使用 Amazon Athena、Amazon Redshift Spectrum 或其他系统执行下游分析查询时,这些内置转换可优化您的 Amazon S3 成本并缩短获得见解的时间。

最后,我输入了目标 Amazon S3 存储桶的名称。同样,当我记不住名称时,会使用浏览按钮让控制台引导我浏览存储桶列表。或者,我为文件名输入 S3 存储桶前缀。在本次演示中,我输入了 aws-news-blog。如果我不输入前缀名称,Kinesis Data Firehose 会使用日期和时间(UTC)作为默认值。
在缓冲区提示、压缩和加密部分下,我可以修改缓冲的默认值,启用数据压缩,或者选择 密钥来加密 Amazon S3 上的静态数据。
准备就绪后,我选择创建传输流。片刻之后,流状态变为 ✅ 可用。

假设有一个应用程序将数据流式传输到我选择作为来源的集群,我现在可以导航到我的 S3 存储桶,并且会在 Kinesis Data Firehose 流式传输数据时看到以所选目标格式显示的数据。
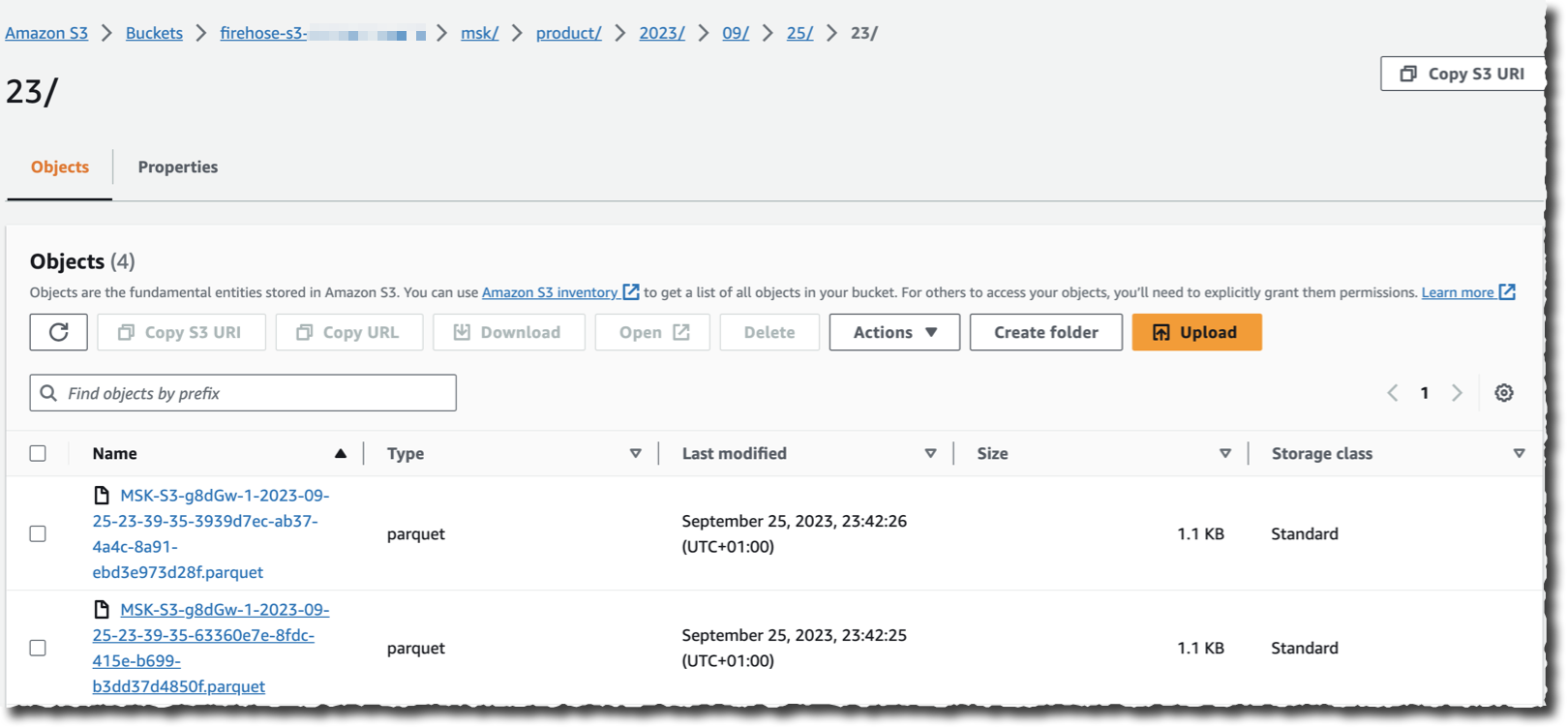
如您所见,无需任何代码即可读取、转换和写入 Kafka 集群中的记录。而且,也不必管理底层基础设施来运行流式传输和转换逻辑。
定价和可用性。
这项新功能现已在所有提供 Amazon MSK 和 Kinesis Data Firehose 的 AWS 区域推出。
您需要为从 Amazon MSK 传出的数据量付费,以每月 GB 量为单位。计费系统会考虑确切的记录大小;不四舍五入。与往常一样,定价页面包含所有详细信息。
我迫不及待想要听到您在采用这项新功能后将停用的基础设施和代码数量。现在就去配置您在 Amazon MSK 和 Amazon S3 之间的第一个数据流吧!