亚马逊AWS官方博客
宣布推出适用于自定义 Amazon Nova 模型的 Amazon SageMaker 推理
自从我们在 2025 年 AWS 纽约峰会上在 Amazon SageMaker AI 中推出 Amazon Nova 定制功能以来,客户一直要求 Amazon Nova 具有与在 Amazon SageMaker 推理中自定义开放权重模型时相同的功能。他们还希望在自定义模型推理方面拥有更多的控制权和灵活性,包括实例类型、自动扩展策略、上下文长度以及并发设置等,这些是生产工作负载所要求的。
今天,我们宣布在 Amazon SageMaker 推理中正式推出自定义 Nova 模型支持,该服务是一款用于部署和扩展全秩定制 Nova 模型的生产级、可配置且经济高效的托管推理服务。现在,您可以体验端到端的定制之旅,使用 Amazon SageMaker 训练作业或 Amazon HyperPod 来训练具有推理能力的 Nova Micro、Nova Lite 和 Nova 2 Lite 模型,并使用 Amazon SageMaker AI 的托管推理基础设施对它们进行无缝部署。
借助适用于自定义 Nova 模型的 Amazon SageMaker 推理,您可以使用 Amazon Elastic Compute Cloud(Amazon EC2)G5 和 G6 实例而不是 P5 实例、基于 5 分钟使用模式的自动扩展以及可配置推理参数通过优化利用 GPU 来降低推理成本。此功能可让您部署定制的 Nova 模型,并对其进行持续的预训练、监督式微调或强化式微调,以适合您的应用场景。您还可以设置有关上下文长度、并发和批量大小的高级配置,以针对您的特定工作负载优化延迟-成本-准确性之间的权衡关系。
让我们来看看如何在 SageMaker AI 实时端点上部署定制的 Nova 模型、配置推理参数,并调用模型进行测试。
在 SageMaker 推理中部署自定义 Nova 模型
在 AWS re:Invent 2025 中,我们在 Amazon SageMaker AI 中针对包括 Nova 模型在内的常用人工智能模型推出了新的无服务器定制选项。只需点击几下,您便能无缝选择模型和定制技术,并处理模型评测和部署工作。如果您已有经过训练的自定义 Nova 模型构件,您可以通过 SageMaker Studio 或 SageMaker AI SDK 在 SageMaker 推理上部署模型。
在 SageMaker Studio 中,在模型菜单的模型中选择经过训练的 Nova 模型。您可以通过选择部署按钮、SageMaker AI 和创建新端点来部署模型。
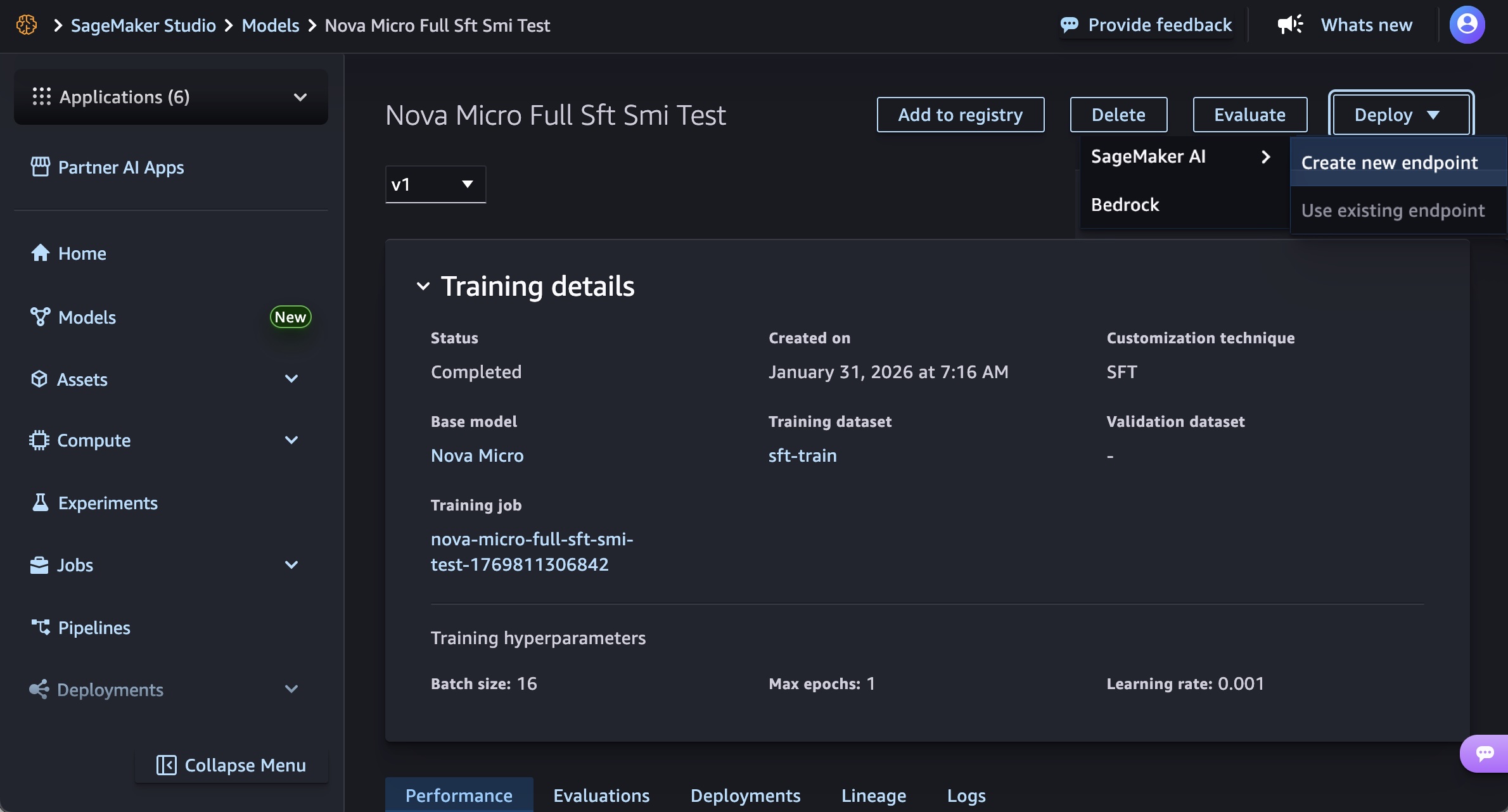
选择端点名称、实例类型和实例数、最大实例数、权限和联网等高级选项,然后选择部署按钮。在正式发布时,您可以将 g5.12xlarge、g5.24xlarge、g5.48xlarge、g6.12xlarge、g6.24xlarge、g6.48xlarge 和 p5.48xlarge 实例类型用于 Nova Micro 模型,将 g5.24xlarge、g5.48xlarge、g6.24xlarge、g6.48xlarge 和 p5.48xlarge 用于 Nova Lite 模型,并将 p5.48xlarge 用于 Nova 2 Lite 模型。
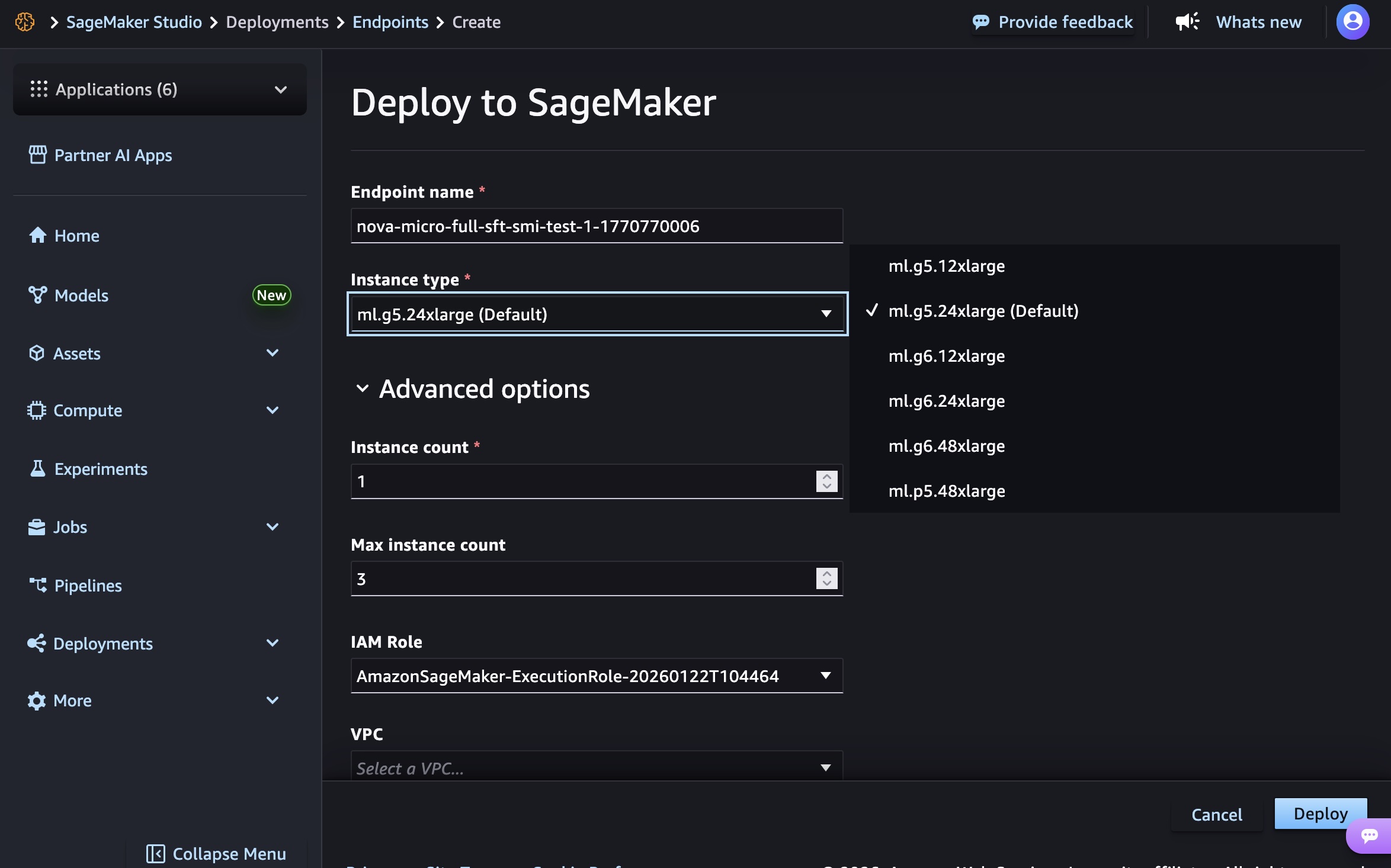
创建端点需要时间来预置基础设施、下载模型构件和初始化推理容器。
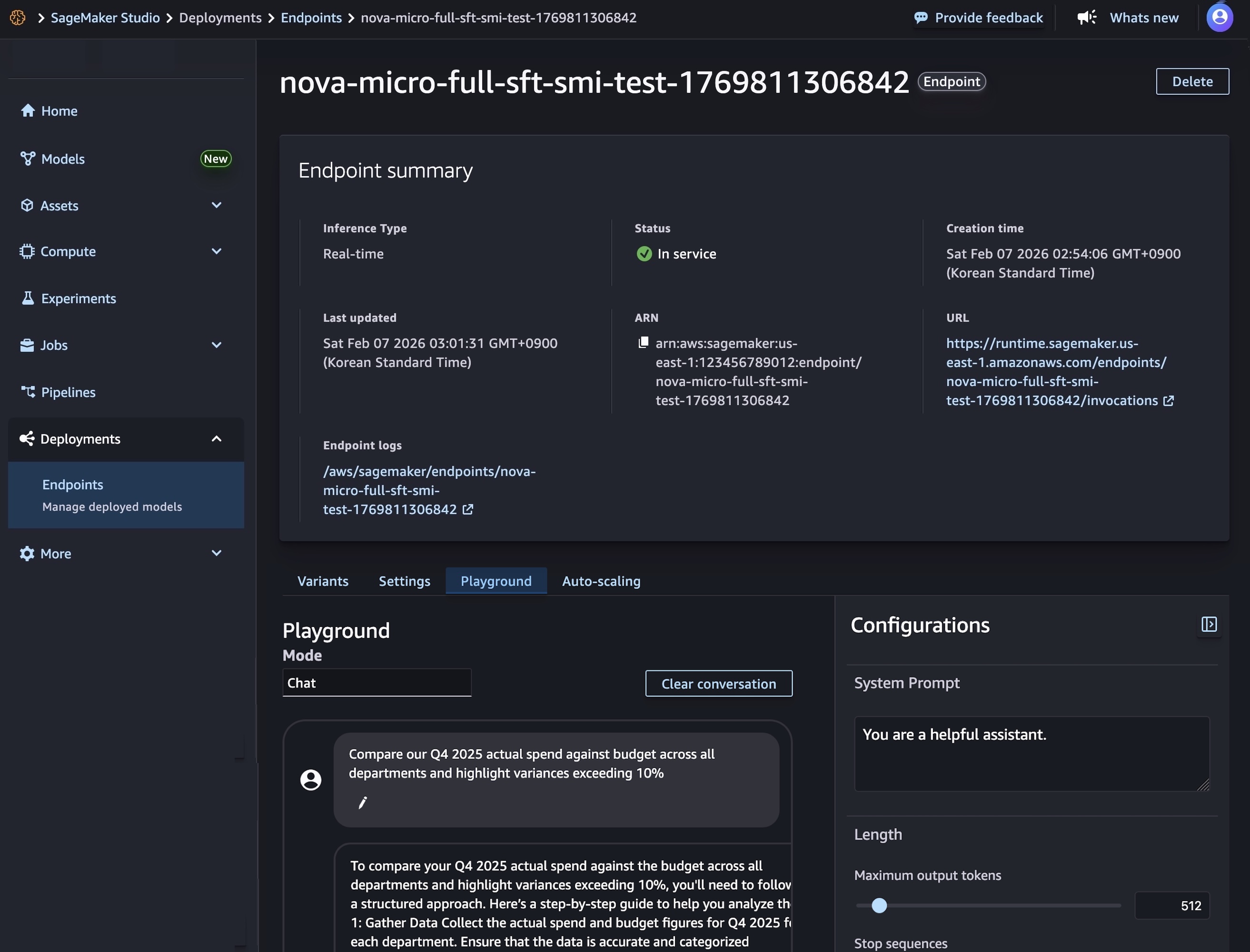
模型部署完成且端点状态显示为 InService 后,您可以使用新端点执行实时推理。要测试模型,请选择平台选项卡并在聊天模式中输入您的提示。
您还可以使用 SageMaker AI SDK 创建两个资源:一个引用 Nova 模型构件的 SageMaker AI 模型对象和一个定义模型部署方式的端点配置。
以下代码用于创建一个引用您的 Nova 模型构件的 SageMaker AI 模型:
# Create a SageMaker AI model
model_response = sagemaker.create_model(
ModelName= 'Nova-micro-ml-g5-12xlarge',
PrimaryContainer={
'Image': '123456789012.dkr.ecr.us-east-1.amazonaws.com/nova-inference-repo:v1.0.0',
'ModelDataSource': {
'S3DataSource': {
'S3Uri': 's3://your-bucket-name/path/to/model/artifacts/',
'S3DataType': 'S3Prefix',
'CompressionType': 'None'
}
},
# Model Parameters
'Environment': {
'CONTEXT_LENGTH': 8000,
'CONCURRENCY': 16,
'DEFAULT_TEMPERATURE': 0.0,
'DEFAULT_TOP_P': 1.0
}
},
ExecutionRoleArn=SAGEMAKER_EXECUTION_ROLE_ARN,
EnableNetworkIsolation=True
)
print("Model created successfully!")接下来,创建一个端点配置,该配置将定义您的部署基础设施,并通过创建一个 SageMaker AI 实时端点来部署您的 Nova 模型。此端点将托管您的模型,并提供一个安全的 HTTPS 端点,用于提出推理请求。
# Create Endpoint Configuration
production_variant = {
'VariantName': 'primary',
'ModelName': 'Nova-micro-ml-g5-12xlarge',
'InitialInstanceCount': 1,
'InstanceType': 'ml.g5.12xlarge',
}
config_response = sagemaker.create_endpoint_config(
EndpointConfigName= 'Nova-micro-ml-g5-12xlarge-Config',
ProductionVariants= production_variant
)
print("Endpoint configuration created successfully!")
# Deploy your Noval model
endpoint_response = sagemaker.create_endpoint(
EndpointName= 'Nova-micro-ml-g5-12xlarge-endpoint',
EndpointConfigName= 'Nova-micro-ml-g5-12xlarge-Config'
)
print("Endpoint creation initiated successfully!")
创建端点后,您可以发送推理请求,以根据您的自定义 Nova 模型生成预测。Amazon SageMaker AI 通过流式/非流式传输模式支持实时同步端点和用于批处理的异步端点。
例如,以下代码为文本生成创建流式传输完成格式:
# Streaming chat request with comprehensive parameters
streaming_request = {
"messages": [
{"role": "user", "content": "Compare our Q4 2025 actual spend against budget across all departments and highlight variances exceeding 10%"}
],
"max_tokens": 512,
"stream": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"logprobs": True,
"top_logprobs": 2,
"reasoning_effort": "low", # Options: "low", "high"
"stream_options": {"include_usage": True}
}
invoke_nova_endpoint(streaming_request)
def invoke_nova_endpoint(request_body):
"""
Invoke Nova endpoint with automatic streaming detection.
Args:
request_body (dict): Request payload containing prompt and parameters
Returns:
dict: Response from the model (for non-streaming requests)
None: For streaming requests (prints output directly)
"""
body = json.dumps(request_body)
is_streaming = request_body.get("stream", False)
try:
print(f"Invoking endpoint ({'streaming' if is_streaming else 'non-streaming'})...")
if is_streaming:
response = runtime_client.invoke_endpoint_with_response_stream(
EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Body=body
)
event_stream = response['Body']
for event in event_stream:
if 'PayloadPart' in event:
chunk = event['PayloadPart']
if 'Bytes' in chunk:
data = chunk['Bytes'].decode()
print("Chunk:", data)
else:
# Non-streaming inference
response = runtime_client.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Accept='application/json',
Body=body
)
response_body = response['Body'].read().decode('utf-8')
result = json.loads(response_body)
print("✅ Response received successfully")
return result
except ClientError as e:
error_code = e.response['Error']['Code']
error_message = e.response['Error']['Message']
print(f"❌ AWS Error: {error_code} - {error_message}")
except Exception as e:
print(f"❌ Unexpected error: {str(e)}")要使用完整的代码示例,请访问在 Amazon SageMaker AI 上定制 Amazon Nova 模型。要详细了解部署和管理模型的最佳实践,请访问 SageMaker AI 的最佳实践。
现已推出
适用于自定义 Nova 模型的 Amazon SageMaker 推理现已在美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)的 AWS 区域推出。有关区域可用性和未来路线图,请访问按区域列出的 AWS 功能。
该功能支持具有推理功能的 Nova Micro、Nova Lite 和 Nova 2 Lite 模型在支持自动扩展的 EC2 G5、G6 和 P5 实例上运行。您只需为实际使用的计算实例付费,采用按小时计费方式,且无需最低承诺。要了解更多信息,请访问 Amazon SageMaker AI 定价页面。
欢迎在 Amazon SageMaker AI 控制台中尝试此功能,并将反馈发送给 AWS re:Post for SageMaker 或通过常见的 AWS Support 联系人发送。
— Channy