亚马逊AWS官方博客
基于 Amazon Connect 数据湖与 Quick 构建联络中心智能分析平台
摘要:Amazon Connect 内置报表灵活度有限,尤其难以呈现 Contact Flow 中的自定义属性数据。本文演示了一条零 ETL 的全链路方案:启用 Connect 分析数据湖,跨账号分享至客户账号,在 Lake Formation 中创建 Resource Link 并管理权限,然后通过 Athena 接入 Amazon Quick 构建可视化 Dashboard。更进一步,利用 Quick 的 Q 功能实现自然语言生成图表,并通过 Chat Agent 让业务人员以对话方式直接获取数据洞察,将数据湖从技术资产转变为全组织可用的智能分析平台。
一、前言
Amazon Connect 作为一个多渠道智能联络中心服务,为管理者提供了内置的报表和 Dashboard 功能。这些内置报表虽然开箱即用,但灵活度有限——尤其是当业务侧在 Contact Flow 中设置了自定义属性(比如客户意见反馈、满意度评价等),内置报表就很难直接呈现这些数据。很多客户需要的是能够自由组合各类维度数据、构建个性化报表的分析能力。
传统做法是自建 ETL 管道,将 Connect 数据抽取、清洗后加载到数据仓库再接 BI 工具,可行但维护成本不低。好消息是,Connect 提供了一个开箱即用的零 ETL 分析数据湖(Analytics Data Lake)。它能将联系记录(Contact Record)、Contact Lens 对话分析、性能评估等数据自动汇聚到一个托管的数据湖中,数据在记录产生后即可查询,无需构建和管理任何数据管道。
然而,数据湖的使用仍然存在门槛——编写 SQL、理解表结构、构建可视化,这些对业务人员来说并不轻松。随着生成式 AI 的快速发展,一个自然的想法浮现出来:能否让业务人员直接用自然语言提问,就能从数据湖中获得洞察?
本文将完整演示从数据湖集成到智能分析的实现路径:从启用 Connect 数据湖、跨账号分享数据,到通过 Amazon Quick 构建可视化分析(Analyses)和 Dashboard,再到利用 Q 功能和 Chat Agent 实现自然语言驱动的可视化报表创建和智能问答分析。
二、数据分析架构

[图1] |
上图展示了整个数据分析链路,我们沿着数据的流向来逐一拆解。
左侧:Amazon Connect Service Account
Connect 的分析数据湖并不在客户自己的账号里,而是存在于 Amazon Connect 的服务托管账号中。这个数据湖包含多种数据表,数据表及完整字段定义可参考 Data type definitions。
本文的演示中我们使用 Contact Record 表。这个表包含每次客户联系的详细记录,字段非常丰富(100+),涵盖通道类型、发起方式、各阶段时间戳、队列信息、座席信息,以及业务侧通过 Contact Flow 设置的自定义属性(存储在 attributes 字段中)。
中间:通过 RAM 跨账号分享
数据湖的数据要从 Connect 的托管账号”分享”到客户账号,靠的是 Resource Access Manager(RAM)服务。当你在 Connect 控制台启用数据湖分享时,系统会自动创建一个 RAM 资源分享邀请,客户在自己的账号中接受这个邀请,即可建立跨账号的数据访问通道。
注意:如果同一个 Region 中有多个 Amazon Connect 实例都开启了数据湖分享,这些数据会合并到同一张表中。下游做数据分析时,需要使用 instance_id 字段来区分不同实例的数据。
另外,只有第一次分享会创建新的 RAM 邀请,后续分享会复用已接受的邀请。
右侧:Customer Account 的分析链路
数据到达客户账号后,整个分析链路如下:
- Lake Formation 接收 RAM 分享的数据表,并创建 Resource Link(可以理解为指向共享表的”快捷方式”)。同时,Lake Formation 负责管理细粒度的访问权限。
- Amazon Athena 通过这些 Resource Link 对数据湖中的数据执行标准 SQL 查询,包括创建自定义 View 来简化下游使用。
- Amazon Quick 以 Athena 作为数据源,构建可视化 Analyses 和 Dashboard,并通过内置的 Q 功能和 Chat Agent 实现 AI 驱动的智能分析。
三、配置 Quick Sight 数据连接
3.1 启用数据湖并接受 RAM 分享
第一步是在 Amazon Connect 控制台中启用分析数据湖。进入 Analytics tools 页面,选择需要分享的数据表并启用数据湖。详细的操作步骤可参考官方文档 Amazon Connect Analytics Data Lake。
启用后,Connect 会通过 RAM 向目标账号发送资源分享邀请。切换到客户账号,在 RAM 控制台 中找到并接受这个邀请。
3.2 配置 Lake Formation 权限
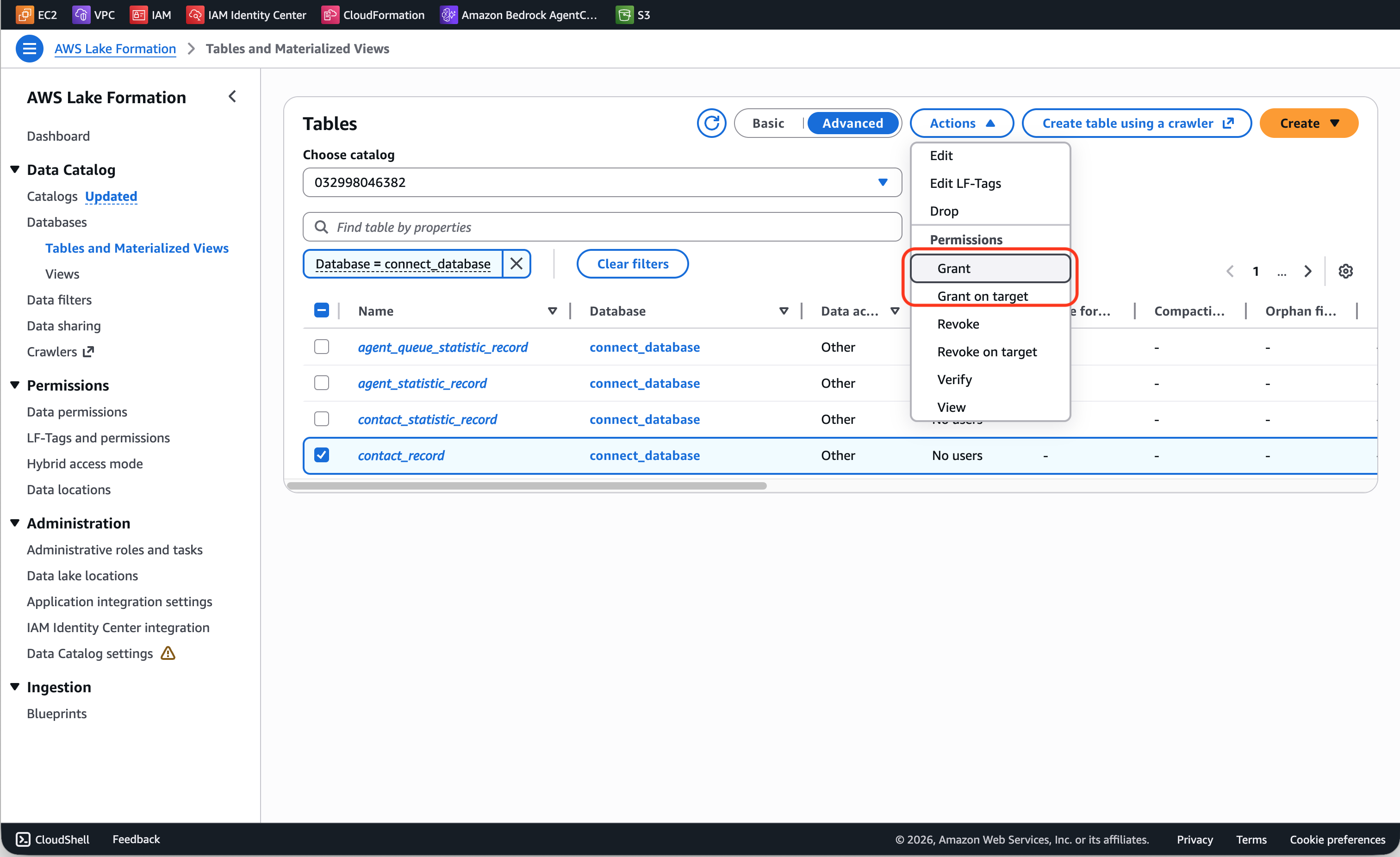
接受 RAM 分享后,在 Lake Formation 控制台的 Tables 页面可以创建 Resource Link 指向共享表。Resource Link 相当于一个”引用”,让下游服务能像访问本地表一样访问跨账号的共享数据。创建完成后,Resource Link 会以数据表的形式显示。接下来需要配置文档,对数据表进行 Grant 和 Grant on target 访问授权。不过这里有一个容易踩的坑:默认的 Basic 模式下看不到 Grant on target 选项,需要点击切换到 Advanced 模式。
[图2] |
3.3 创建 Amazon Athena 自定义 View
拿到数据访问权限后,理论上可以直接在 Athena 里查询原始表。但实际使用中,创建一个自定义 View 会方便很多,主要有三个原因:
- 原始表字段可能多达上百个,日常分析只需要其中一部分;
- 如果有多个 Connect 实例的数据混在一起,View 可以预先过滤;
- 最关键的是,Contact Flow 中设置的自定义属性存储在
attributes这个 MAP 类型的字段里,需要用特定语法提取出来才能作为独立列使用。
以座席满意度分析为例,下面的 View 从 contact_record 中提取了关键字段和两个自定义属性:
attributes['surveyResult'] 这个语法就是从 MAP 中按 key 取值,提取后就变成了一个普通的列,Quick Sight 可以直接用来做分组、过滤和聚合。创建好的 agent_satisfaction View 在后续步骤中会出现在 Quick Sight的表选择列表中。
3.4 接入 Quick Sight数据源
在正式接入之前,需要先在 Quick 的管理设置中确认两件事:一是已开启对 Amazon Athena 的访问权限,二是已对 Athena Workgroup 中配置的 S3 查询结果存储桶授予了访问权限。
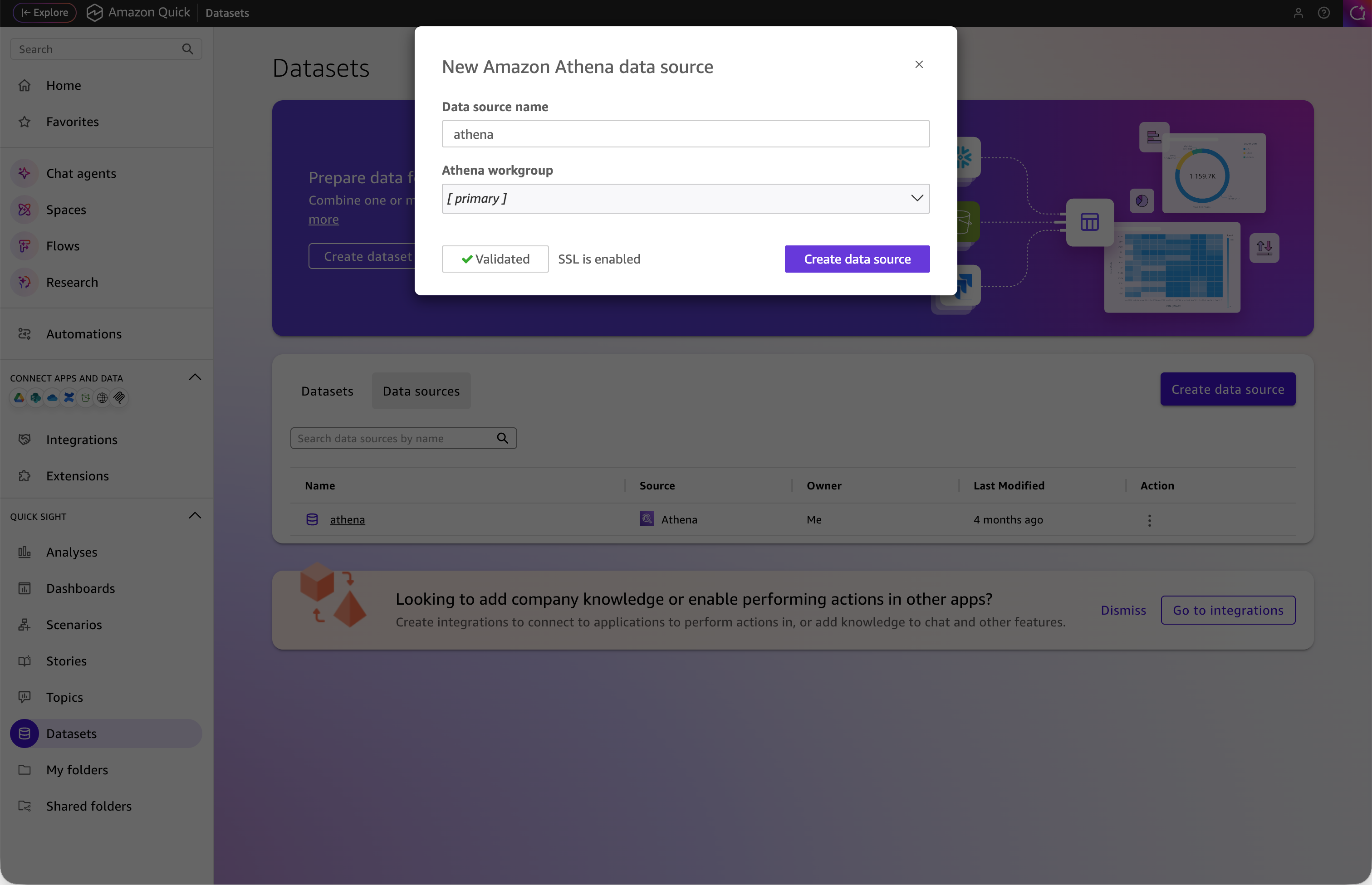
准备就绪后,进入 Quick Sight 的 Datasets 页面,点击 Create data source,选择 Amazon Athena。
[图3] |
填写数据源名称(如 athena),选择对应的 Athena Workgroup(如 [primary]),系统会自动验证连接。看到绿色的 Validated 标记和 SSL is enabled 提示后,点击 Create data source 完成创建。
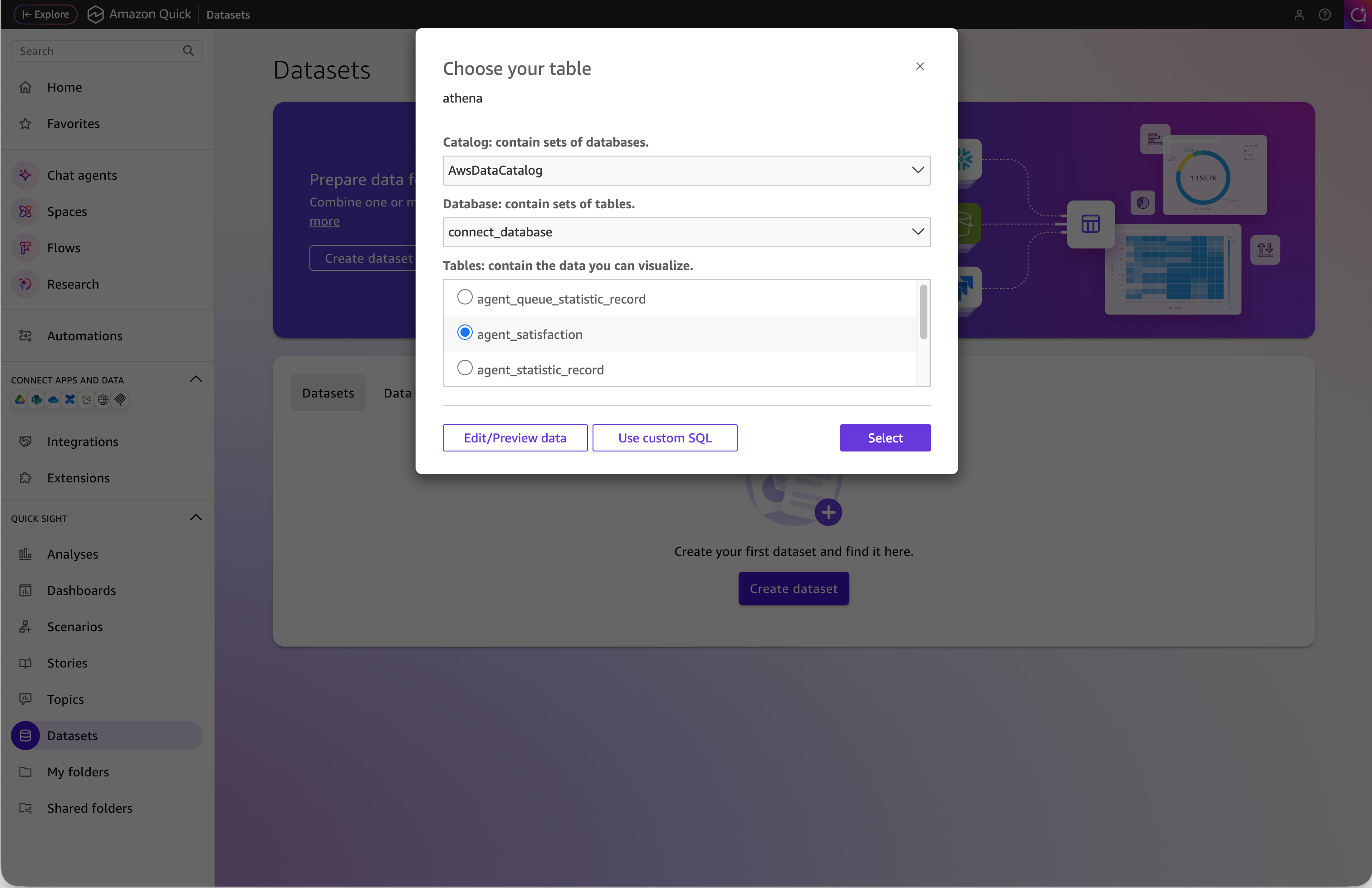
接下来创建 Dataset。点击 Create dataset,选择刚才创建的 Athena 数据源,在弹出的表选择对话框中,依次选择 Catalog(AwsDataCatalog)、Database(connect_database),就能看到可用的表和 View 列表,其中就包括我们在上一步创建的 agent_satisfaction View。
[图4] |
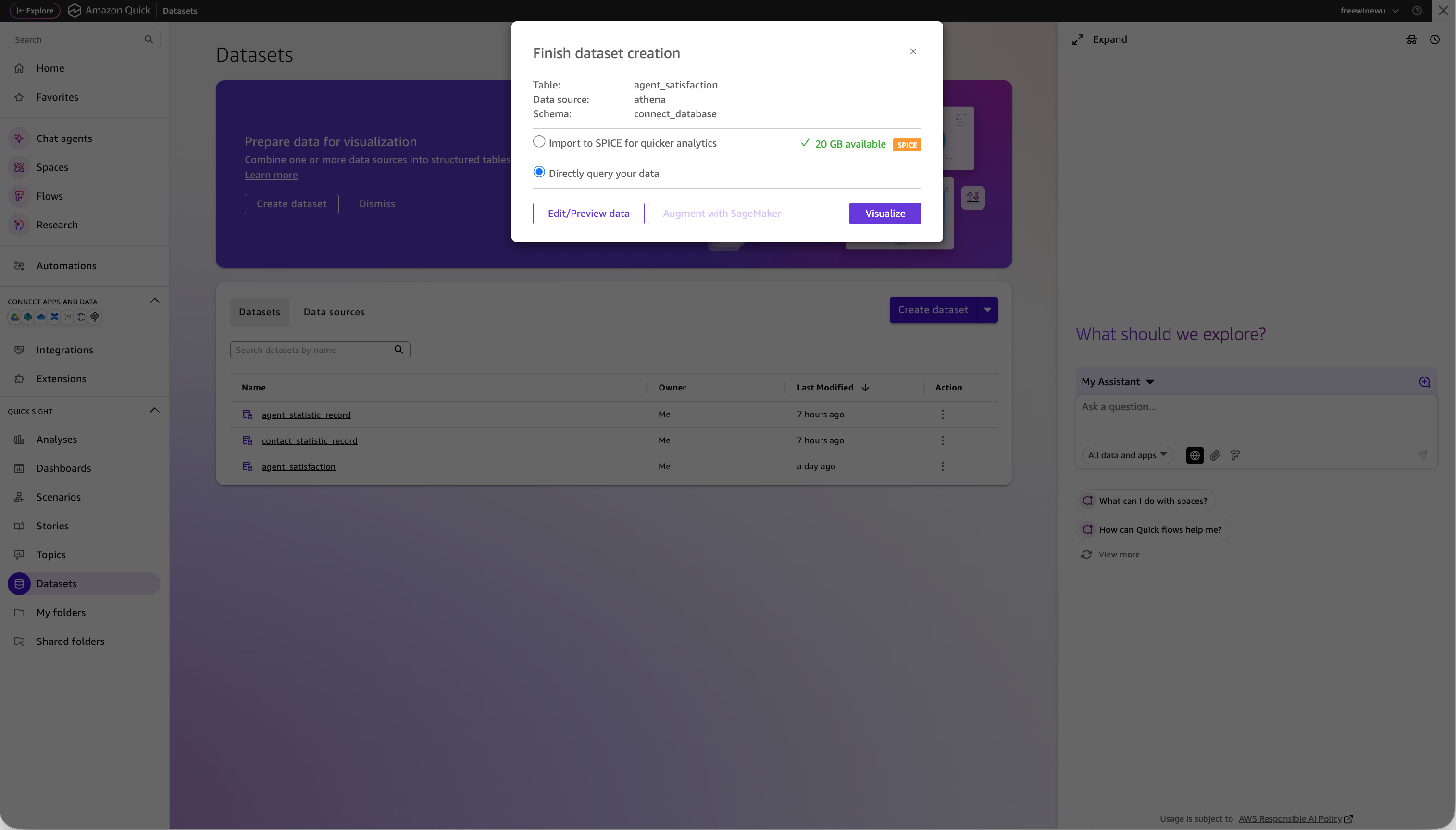
选择目标表后,点击 Select 进入下一步。然后可以选择 Edit/Preview data(进一步添加计算字段或过滤条件)或直接创建可视化组件。至此,Quick Sight 与 Connect 数据湖的数据链路就打通了。
[图5] |
四、Analyses 和 Dashboard 开发
4.1 手动构建 Analyses 可视化组件
Analyses 是 Quick Sight 的可视化编辑环境。创建一个新的 Analyses 并关联 Dataset 后,就可以通过拖拽字段来构建各种图表了。
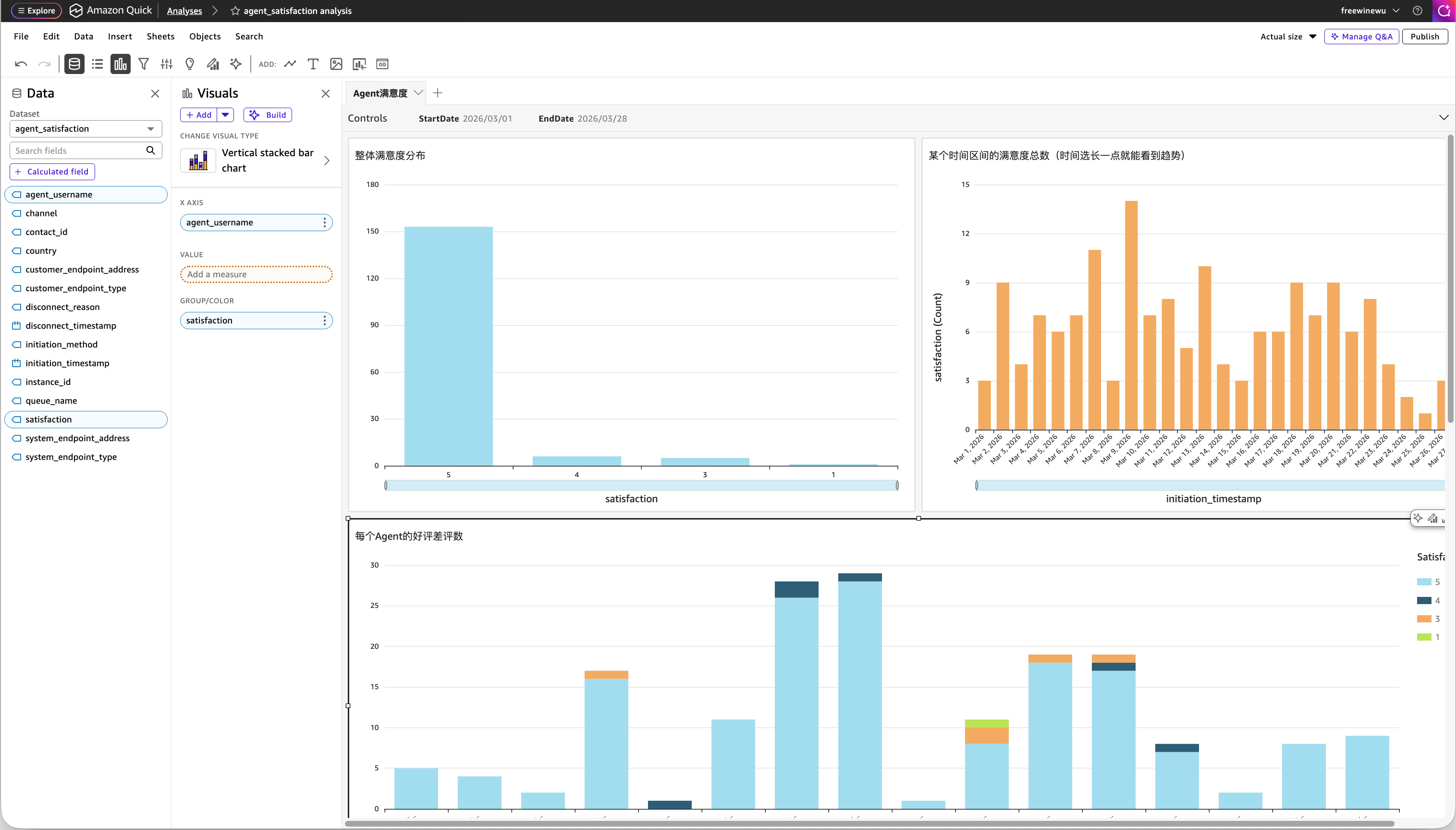
以座席满意度分析为例,下图是我们构建的 Analyses 工作区(仅作示例):
[图6] |
左侧面板展示了 agent_satisfaction 数据集的所有可用字段,右侧画布上是我们创建的三个可视化组件:整体满意度分布、满意度随时间的变化趋势、每个座席的满意度构成。
4.2 使用 Q 自然语言生成可视化组件
手动拖拽构建图表对于数据分析师来说驾轻就熟,但如果你想快速探索数据、或者不太熟悉 Quick Sight 的操作,可以试试内置的 Q 功能——直接用自然语言描述你想看的分析,Q 会自动生成对应的可视化组件。
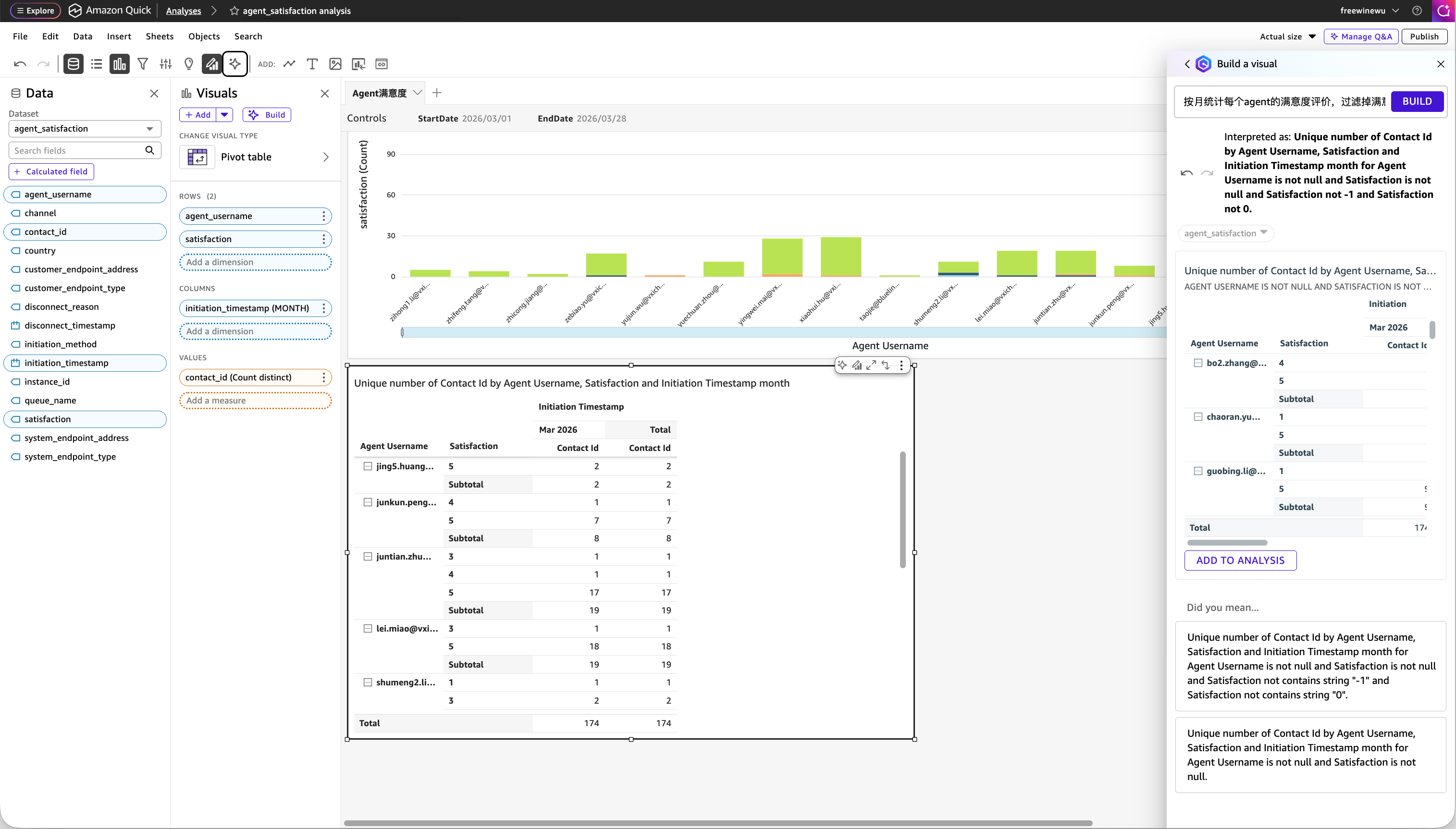
比如,我们输入以下提示:
可以看到,Q 自动生成了一个透视表,行是 Agent Username,列是按月聚合的 initiation_timestamp,值是 Contact Id 的去重计数,并且按要求过滤掉了无效数据。右侧的 Q 对话面板展示了 Q 对自然语言的理解和转换过程。确认结果符合预期后,点击 ADD TO ANALYSIS 就能将这个组件添加到当前 Analyses 中。
[图7] |
再举几个基于 agent_satisfaction 数据集的 Q 提示示例:
这个查询会利用 channel 和 satisfaction 字段,直观呈现不同Channel的客户满意度差异。
这个查询会结合 agent_username、disconnect_reason 和 satisfaction 字段,帮助发现主动挂断率较高的座席,辅助服务质量管理。
使用 Q 的一个小技巧:为 Dataset 中的字段取一个有业务含义的名称(比如把 satisfaction 改为”客户满意度”),并在 Quick Sight 中配置 Topics 来帮助 Q 理解数据的业务语义。Topics 是 Q 的语义层,创建 Topic 时系统会自动为字段生成友好名称和常见同义词,你还可以手动添加业务术语作为同义词、配置字段描述和语义类型,这些都能显著提升 Q 对自然语言提问的理解准确率。
4.3 发布 Dashboard
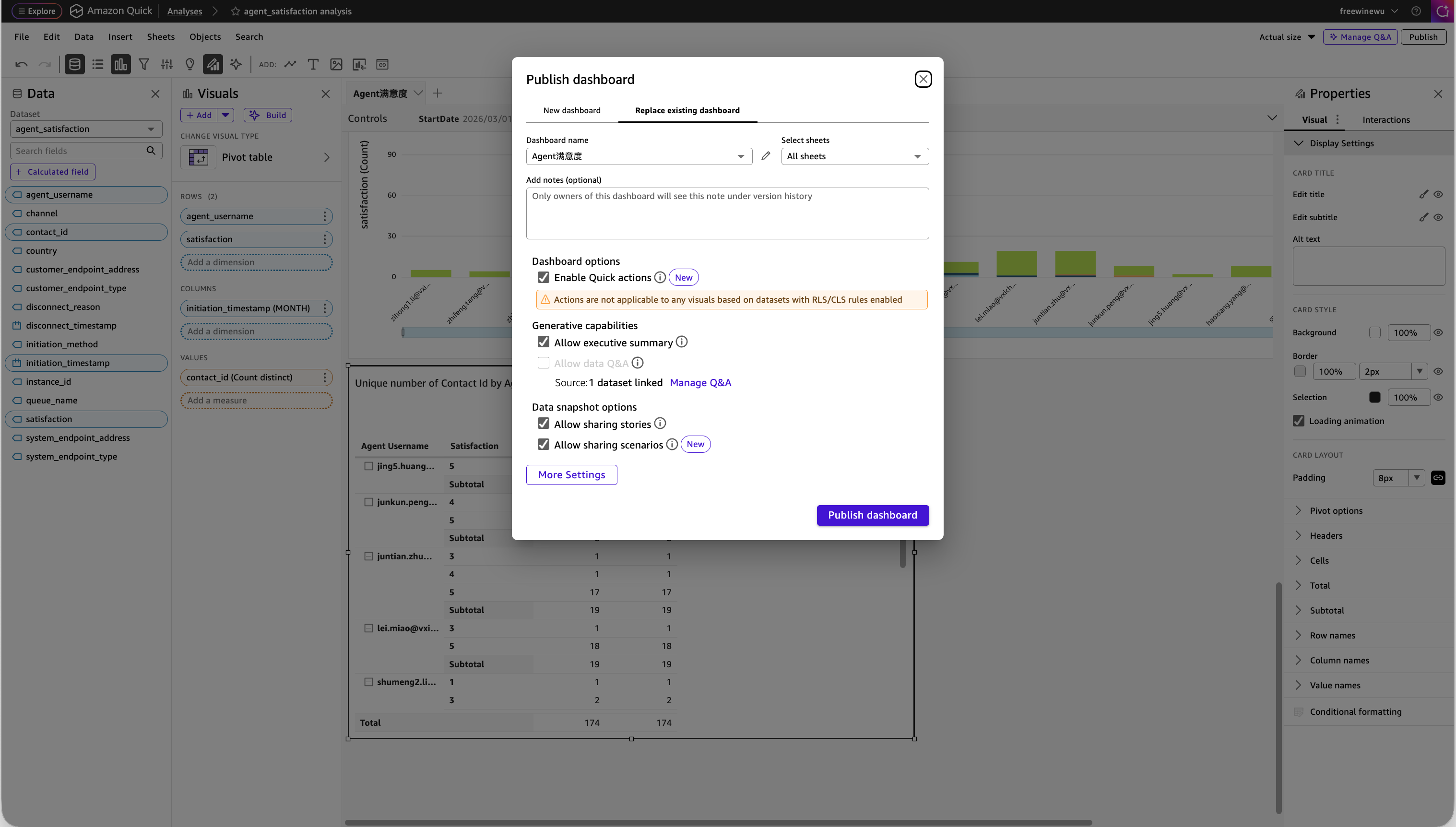
Analyses 开发完成后,可以将其发布为 Dashboard。Dashboard 是 Analyses 的只读交互版本,适合分享给团队成员查看和使用。
在 Analyses 页面点击右上角的 Publish,在弹出的对话框中填写 Dashboard 名称等信息,然后点击 Publish dashboard 即可完成发布。发布后的 Dashboard 可以分享给特定的 Quick 用户或用户组,也支持通过嵌入式分析(Embedded Analytics)集成到自建的 Web 应用中。
[图8] |
五、定制 Quick Chat Agent
Dashboard 做好了,但并非所有人都习惯看图表。联络中心的运营主管可能更希望直接问一句”上个月哪个座席表现最好?”就能拿到答案。Quick 的 Chat Agent 正是为这类需求而生。
Chat Agent 是一个基于生成式 AI 的对话界面,通过自然语言对话为用户提供数据洞察和分析解读。
设置步骤如下:
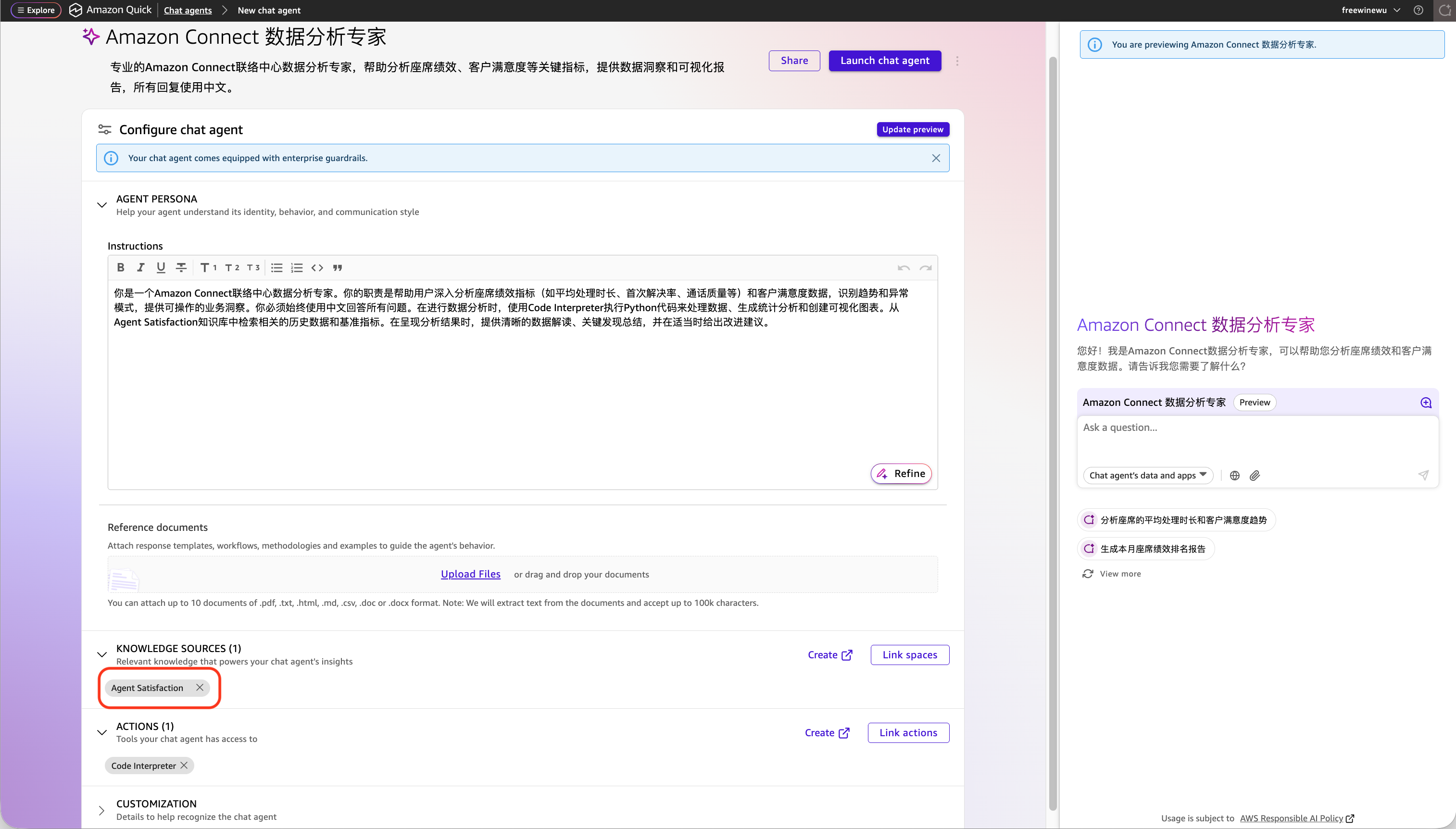
- 创建一个Quick Space,关联已发布的 Dashboard 或 Topics(参考 4.2 节)作为知识库。
- 在 Quick 左侧导航栏中进入 Chat agents 页面,创建一个新的 Chat Agent。
- 配置 Agent 的行为指令,例如”你是一个Amazon Connect联络中心数据分析专家,帮助用户分析座席绩效和客户满意度数据,回答请使用中文”。正常情况下会自动关联第1步创建的Space作为知识库。
- 为其命名并编写描述(如”Amazon Connect 数据分析专家”)。
[图9] |
配置完成后,用户就可以在 Chat Agent 中用自然语言提问了。以下是几个典型的对话示例:
示例 1:查询具体指标
Chat Agent 会通过 Topic 查询客户满意度数据,给出具体评分分布。
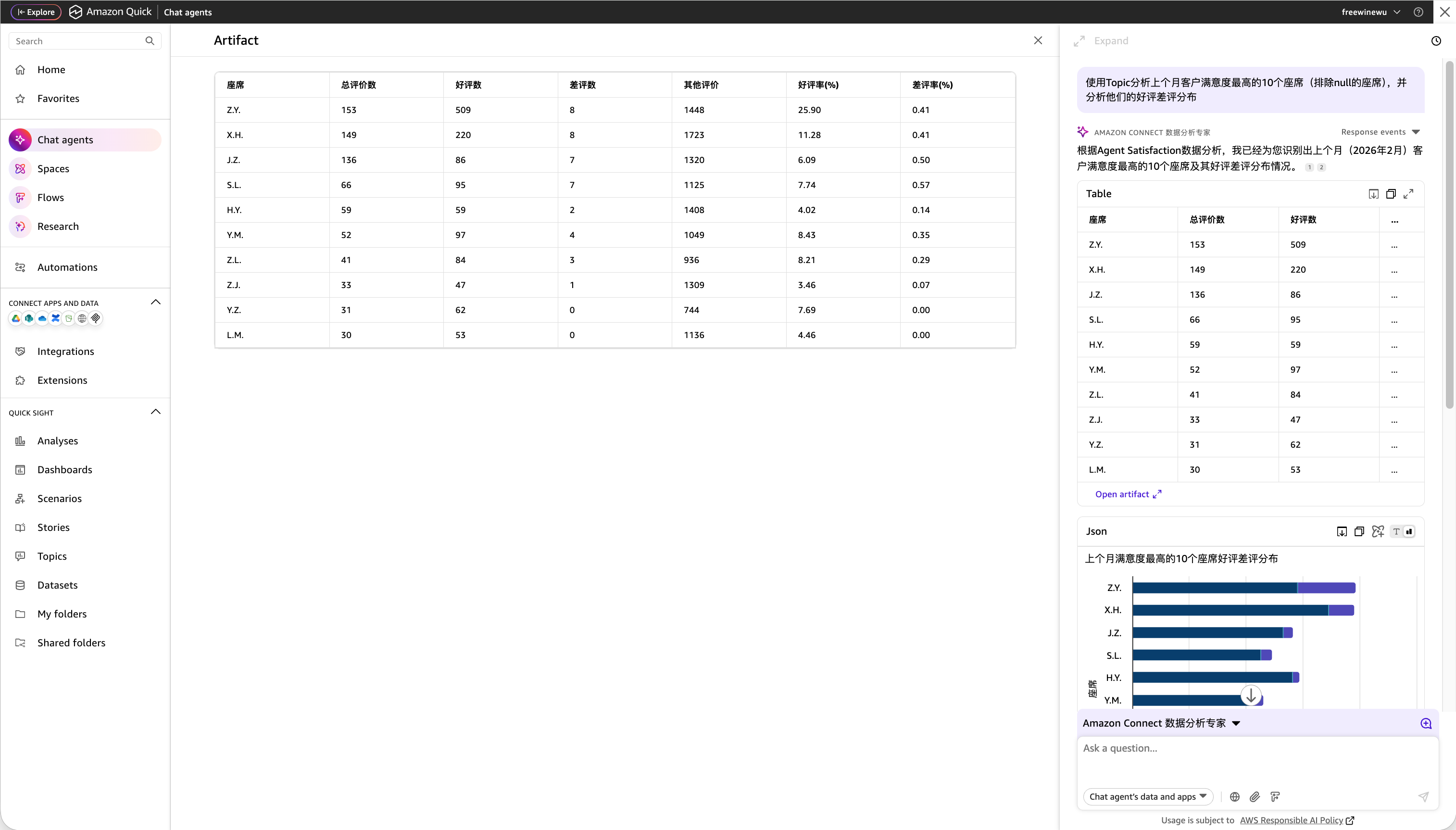
[图10] |
示例 2:趋势分析
Chat Agent 不仅会呈现趋势数据,还会主动指出异常波动并尝试给出可能的原因分析。
示例 3:全局洞察
Chat Agent 会综合 Dashboard 中所有可视化组件的数据,生成一份结构化的洞察摘要。
Chat Agent 的价值在于降低了数据分析的门槛。不需要会 SQL,不需要熟练操作 Dashboard,业务人员只需用日常语言提问,就能获得数据驱动的洞察。这让数据湖从一个技术资产变成了整个组织都能受益的智能分析平台。
六、总结
回顾全文,我们走完了一条从数据源到智能分析的完整链路:在 Amazon Connect 中启用零 ETL 数据湖 → 通过 RAM 跨账号分享数据 → 在 Lake Formation 中管理访问权限 → 用 Athena 创建自定义 View → 在 Quick 中构建 Analyses 和 Dashboard → 最后通过 Chat Agent 实现自然语言问答分析。
这套方案有三个核心优势:
- 零 ETL:无需构建和维护数据管道,Connect 的运营数据自动进入数据湖,随时可查。
- 全链路 Serverless:Lake Formation、Athena、Quick 都是全托管服务,无需管理任何基础设施,按用量付费。
- AI 驱动分析:Quick 的 Q 功能支持自然语言生成可视化,Chat Agent 支持对话式数据探索,大幅降低了数据分析的技术门槛。
本文主要使用座席满意度数据来演示整个流程,您可以根据业务需求进行扩展。例如,可以将 Contact Lens 的会话分析数据(转写文本、情绪分析)纳入数据湖,与联系记录关联,进行更深层的客户体验分析;可以将 Contact Evaluation(质量评估)数据与联系记录关联,构建座席质量评分趋势、评估通过率排名、AI 自动评估采纳率等分析视图,为联络中心的质量管理提供数据支撑;也可以利用 Quick 的嵌入式分析(Embedded Analytics)能力,将 Dashboard 集成到企业自建的运营管理平台中,实现数据分析与日常工作流的无缝衔接。
➡️ 下一步行动:
相关产品:
- Amazon Connect — AI 客户体验解决方案
- Amazon Athena — 使用 SQL 在 S3 中查询数据
- Amazon Quick — 整合人工智能代理,以实现研究、业务洞察和自动化的数字工作空间
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
相关文章:
- 告别堡垒机:使用 AWS EICE (EC2 Instance Connect Endpoint) 与 Chaterm 实现私有子网的安全智能运维
- 从数据库连接到自然语言查询:Amazon QuickSuite 数据分析全流程实践
- 不只是 Chatbot:如何设计一个真正可执行的 Agentic Commerce 电商系统
- 三剑合璧Quick Suite + Agent Core + Kiro联动实践:海外物流报价助手实战
七、参考资料
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
