亚马逊AWS官方博客
基于 Amazon Kinesis Data Streams 实现 DynamoDB 历史数据清理与增量同步
摘要:本文介绍了一种基于 Amazon Kinesis Data Streams、AWS Lambda、AWS Glue 和 Amazon S3 的完整方案,帮助企业客户在不停机的前提下,对 Amazon DynamoDB 表进行历史数据清理、TTL 自动过期配置,并通过 Kinesis 实现增量数据的无缝同步,最终将过期数据归档至 Amazon S3 智能分层存储以降低长期成本。
一、引言
在使用 Amazon DynamoDB 构建业务系统的过程中,随着数据持续写入,表中会积累大量历史数据。对于视频字幕翻译、日志记录、IoT 事件等场景,数据往往具有明显的时效性——超过一定时间后不再被业务查询,但仍占用存储空间并产生费用。
企业客户在处理这类问题时,通常面临以下挑战:
- 存储成本持续增长:DynamoDB 按存储量计费,TB 级历史数据每月产生可观的存储费用,而这些数据可能已经不再被访问。
- 数据清理与业务连续性的矛盾:直接删除历史数据需要消耗大量写入容量(WCU),可能影响在线业务的正常读写;而创建新表并迁移数据,又面临迁移窗口期内增量数据丢失的风险。
- 增量同步的时间窗口限制:DynamoDB Streams 的数据保留期仅为 24 小时且不可修改。对于 10TB 以上的大表,历史数据的导出、清洗和导入流程可能需要数天时间,远超 24 小时的窗口期。
- 缺乏自动化的数据生命周期管理:清理后的数据如果没有归档机制,可能导致合规审计所需的历史数据永久丢失。
本文将介绍一种基于 Amazon Kinesis Data Streams 的完整解决方案,通过将增量同步的时间窗口从 24 小时扩展到最长 365 天,从根本上解决大数据量场景下的迁移时间约束问题。该方案与 AWS Well-Architected Framework 的卓越运营和成本优化支柱保持一致。
二、概览
2.1 业务场景
某字幕翻译业务中,每次翻译任务会在 DynamoDB 中生成大量字幕记录。随着业务运行,表中积累了数 TB 的历史数据,其中大部分超过 30 天的记录已不再被业务查询。客户希望:
- 仅保留最近 30 天的活跃数据
- 对保留的数据自动添加 TTL,实现持续的自动过期清理
- 迁移过程中不丢失任何增量写入
- 过期删除的数据归档到低成本存储,满足合规要求
2.2 方案收益
| 维度 | 收益 |
| 零数据丢失 | Kinesis 保留期最长 365 天,彻底消除迁移窗口期的数据丢失风险 |
| 零停机迁移 | 源表持续提供服务,增量数据通过 Kinesis + Lambda 实时同步到新表 |
| 自动生命周期管理 | TTL 自动过期删除 + DynamoDB Streams 归档到 S3 智能分层,形成完整的数据生命周期 |
| 成本显著降低 | 清理历史数据减少 DynamoDB 存储费用,归档数据利用 S3 智能分层最低至 $0.00099/GB/月 |
| 架构简洁 | 全部使用 AWS 托管服务,无需维护额外基础设施 |
2.3 方案选型:为什么选择 Kinesis Data Streams
在增量同步环节,DynamoDB 原生支持两种变更捕获机制。以下是关键对比:
| DynamoDB Streams | Kinesis Data Streams | |
| 数据保留期 | 24 小时(不可修改) | 最长 365 天(可配置) |
| 额外成本 | 免费 | Kinesis 按 shard/小时计费 |
| Lambda 代码 | 直接读取 DynamoDB 格式 | 需要 base64 解码 |
| 适用场景 | 小数据量,24h 内完成 | 大数据量,可能需要数天 |
对于 10TB 以上的大表,历史数据处理流程(导出 → Glue 清洗 → 导入新表)通常需要 2-5 天。DynamoDB Streams 的 24 小时保留期无法覆盖这一时间窗口,而 Kinesis Data Streams 可将保留期设为 7 天甚至更长,从根本上消除了时间约束。
三、方案架构
该方案分为两条并行的数据处理路径:历史数据批量处理和增量数据实时同步,最终汇聚到同一张新表,并通过 TTL + DynamoDB Streams 实现持续的数据生命周期管理。
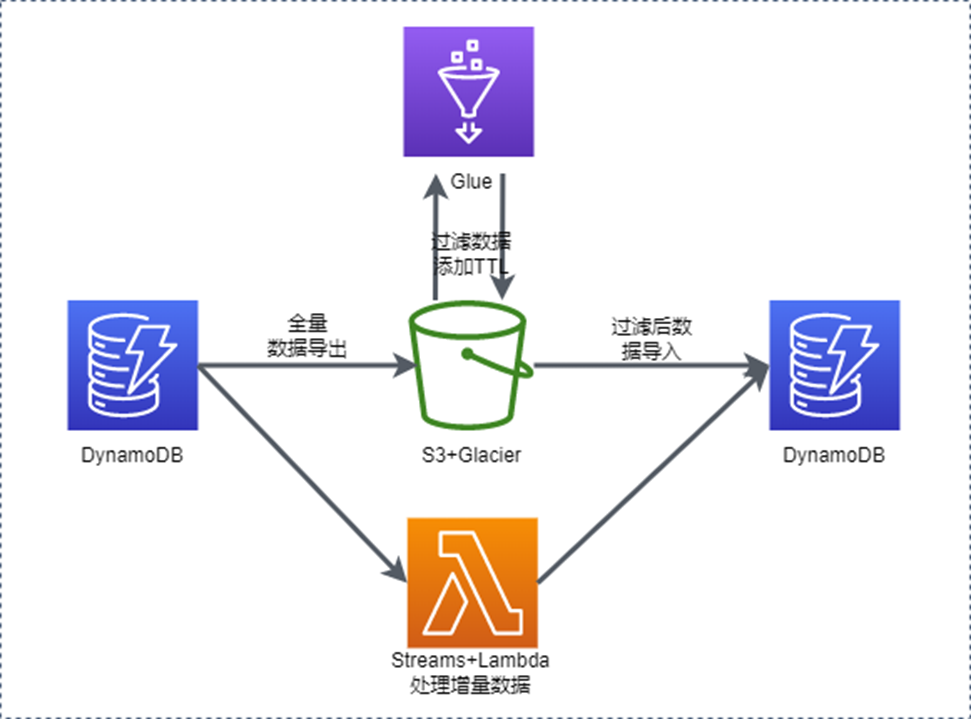
[图1] |
3.1 核心组件
| 组件 | 功能 | 说明 |
| Amazon DynamoDB | 源表与目标表 | 源表持续提供服务,新表仅包含清洗后的数据并启用 TTL |
| Amazon Kinesis Data Streams | 增量变更捕获 | 记录源表所有写入操作,保留期可配置至 7 天以上 |
| AWS Lambda | 增量同步 + 归档 | 消费 Kinesis 记录写入新表(加 TTL),消费 DynamoDB Streams 归档到 S3 |
| AWS Glue | 历史数据清洗 | 筛选有效数据、添加 TTL 字段、转换为 DynamoDB JSON 格式 |
| Amazon S3 | 数据中转与归档 | 存储导出数据、Glue 处理结果,以及过期数据的长期归档(智能分层) |
3.2 工作流程与执行顺序
整体流程的执行顺序至关重要,必须确保增量捕获先于历史数据导出启动,以避免数据丢失:
ℹ️ 关键设计说明
为什么步骤 8 使用 TRIM_HORIZON?
因为 Lambda 触发器设置为从 Kinesis Stream 的最早可用记录开始消费,这意味着从步骤 2 开始记录的所有增量变更都会被自动处理,无需手动对齐时间窗口。窗口期内与历史数据重叠的记录,通过 put_item 的覆盖特性自动去重。
四、前置条件
在开始实施之前,请确保满足以下条件:
AWS 环境要求
- 具有适当 IAM 权限的 AWS 账户
- 已有 DynamoDB 源表(本文以
VideoTranslationSubtitle为例) - 用于数据中转的 S3 存储桶(本文以
glue-test023为例) - 源表与目标表位于同一区域(本文以
us-east-1为例)
权限要求
- DynamoDB:读写源表和目标表、导出到 S3、启用 Kinesis Streaming 和 DynamoDB Streams
- Kinesis:创建和管理 Data Stream
- Lambda:创建函数、配置触发器
- Glue:创建和运行 ETL Job
- S3:读写数据桶
- IAM:创建和管理角色与策略
五、实施详解
5.1 步骤一:创建 Kinesis Data Stream
首先创建用于捕获 DynamoDB 源表增量变更的 Kinesis Data Stream,并将保留期设置为 7 天,为后续的历史数据处理预留充足的时间窗口。
控制台操作
1. Kinesis 控制台 → Data streams → Create data stream
2. 配置:
| 配置项 | 值 |
| Data stream name | VideoTranslationSubtitle-stream |
| Capacity mode | On-demand |
3. 点击 Create data stream
4. 修改保留期:点击刚创建的 Stream → Configuration 标签 → Data retention period → Edit → 修改为 168 小时(7 天)→ Save changes
CLI 操作
aws kinesis create-stream \
--stream-name VideoTranslationSubtitle-stream \
--stream-mode-details StreamMode=ON_DEMAND \
--region us-east-1
aws kinesis increase-stream-retention-period \
--stream-name VideoTranslationSubtitle-stream \
--retention-period-hours 168 \
--region us-east-1
5.2 步骤二:DynamoDB 源表关联 Kinesis Stream
将源表与 Kinesis Data Stream 关联后,源表的所有写入、更新和删除操作都会被实时记录到 Stream 中。这一步必须在导出历史数据之前完成,以确保窗口期内的增量数据不会丢失。
控制台操作:
1. DynamoDB 控制台 → Tables → 选择 `VideoTranslationSubtitle`
2. Exports and streams 标签
3. Amazon Kinesis data stream details 区域 → Turn on
4. 选择 VideoTranslationSubtitle-stream
5. 点击 Turn on stream
CLI 操作:
aws dynamodb enable-kinesis-streaming-destination \
--table-name VideoTranslationSubtitle \
--stream-arn arn:aws:kinesis:us-east-1:<account-id>:stream/VideoTranslationSubtitle-stream \
--region us-east-1
验证:
aws dynamodb describe-kinesis-streaming-destination \
--table-name VideoTranslationSubtitle \
--region us-east-1
确认 StreamStatus 为 ACTIVE 后再进行下一步。
5.3 步骤三:创建增量同步 Lambda 函数
该函数负责消费 Kinesis Data Stream 中的增量记录,为每条数据添加 TTL 字段后写入目标表。此步骤仅创建函数,暂不添加触发器——触发器将在历史数据导入完成后再添加。
创建函数:
1. Lambda 控制台 → Create function
2. 配置:
| 配置项 | 值 |
| Function name | ddb-kinesis-sync-ttl |
| Runtime | Python 3.12 |
| Architecture | arm64 |
| Execution role | Create a new role with basic Lambda permissions |
3. 粘贴以下代码:
import boto3
import json
import base64
import time
dynamodb = boto3.client('dynamodb', region_name='us-east-1')
TARGET_TABLE = 'VideoTranslationSubtitle-ttl'
TTL_DAYS = 30
def lambda_handler(event, context):
for record in event['Records']:
payload = base64.b64decode(record['kinesis']['data']).decode('utf-8')
data = json.loads(payload)
event_name = data.get('eventName', '')
if event_name in ('INSERT', 'MODIFY'):
new_image = data['dynamodb']['NewImage']
ttl_value = int(time.time()) + TTL_DAYS * 86400
new_image['test001'] = {'N': str(ttl_value)}
dynamodb.put_item(TableName=TARGET_TABLE, Item=new_image)
return {'statusCode': 200}
> ⚠️ 注意:Kinesis 版代码需要对 `record[‘kinesis’][‘data’]` 进行 base64 解码,这与直接使用 DynamoDB Streams 触发器的代码不同。
4. 点击 Deploy
配置 IAM 权限:
Lambda 函数需要读取 Kinesis Stream 和写入目标 DynamoDB 表的权限。进入 Lambda 函数页面 → Configuration → Permissions → 点击 Role name → Add permissions → Create inline policy → JSON:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "dynamodb:PutItem",
"Resource": "arn:aws:dynamodb:us-east-1:<account-id>:table/VideoTranslationSubtitle-ttl"
},
{
"Effect": "Allow",
"Action": [
"kinesis:GetRecords",
"kinesis:GetShardIterator",
"kinesis:DescribeStream",
"kinesis:DescribeStreamSummary",
"kinesis:ListShards",
"kinesis:ListStreams",
"kinesis:SubscribeToShard"
],
"Resource": "arn:aws:kinesis:us-east-1:<account-id>:stream/VideoTranslationSubtitle-stream"
}
]
}
<account-id> 替换为实际 AWS 账户 ID
Policy name:`kinesis-sync-policy` → Create policy
调整 Lambda 配置:
Configuration → General configuration → Edit
| 配置项 | 值 |
| Memory | 256 MB |
| Timeout | 1 min 0 sec |
5.4 步骤四:导出历史数据到 S3
利用 DynamoDB 原生的 Export to S3 功能,将源表的全量数据导出。该操作不会影响源表的正常读写性能。
1. DynamoDB 控制台 → 左侧 Exports to S3 → Export to S3
2. 配置:
| 配置项 | 值 |
| Source table | VideoTranslationSubtitle |
| S3 bucket | glue-test023 |
| S3 prefix | ddb-export/ |
| Export format | DynamoDB JSON |
| Export type | Full export |
3. 点击 Export,等待状态变为 Completed
验证:
aws s3 ls s3://glue-test023/ddb-export/ --recursive --summarize --human-readable
5.5 步骤五:Glue 处理历史数据(筛选 + 添加 TTL)
使用 AWS Glue ETL Job 对导出的历史数据进行清洗:筛选出最近 30 天的有效数据,为每条记录计算并添加 TTL 字段,最后转换为 DynamoDB JSON 格式输出到 S3。
上传 Glue 脚本:
aws s3 cp glue_add_ttl.py s3://aws-glue-assets-<account-id>-us-east-1/scripts/glue_add_ttl.py
Glue 脚本内容:
import sys
import time
from datetime import datetime, timedelta, timezone
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.context import SparkContext
from pyspark.sql.functions import col, udf
from pyspark.sql.types import LongType, StringType
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
S3_INPUT = "s3://glue-test023/ddb-export/"
S3_OUTPUT = "s3://glue-test023/ddb-with-ttl/"
ONE_MONTH_AGO = (datetime.now(timezone.utc) - timedelta(days=30)).strftime("%Y-%m-%dT%H:%M:%SZ")
@udf(returnType=LongType())
def calc_ttl(created_at):
dt = datetime.strptime(created_at, "%Y-%m-%dT%H:%M:%SZ").replace(tzinfo=timezone.utc)
return int((dt + timedelta(days=30)).timestamp())
df = spark.read.json(S3_INPUT)
df_flat = df.select(
col("Item.JobId.S").alias("JobId"),
col("Item.Index.N").cast("string").alias("Index"),
col("Item.Content.S").alias("Content"),
col("Item.BeginTime.S").alias("BeginTime"),
col("Item.EndTime.S").alias("EndTime"),
col("Item.CreatedAt.S").alias("CreatedAt"),
)
df_filtered = df_flat.filter(col("CreatedAt") >= ONE_MONTH_AGO)
df_with_ttl = df_filtered.withColumn("test001", calc_ttl(col("CreatedAt")))
@udf(returnType=StringType())
def to_ddb_json(job_id, index, content, begin_time, end_time, created_at, ttl):
import json
item = {"Item": {"JobId": {"S": job_id}, "Index": {"N": index}, "Content": {"S": content},
"BeginTime": {"S": begin_time}, "EndTime": {"S": end_time},
"CreatedAt": {"S": created_at}, "test001": {"N": str(ttl)}}}
return json.dumps(item, ensure_ascii=False)
df_output = df_with_ttl.select(
to_ddb_json("JobId", "Index", "Content", "BeginTime", "EndTime", "CreatedAt", "test001").alias("value"))
df_output.write.mode("overwrite").text(S3_OUTPUT)
job.commit()
创建 Glue Job(控制台)
1. Glue 控制台 → ETL jobs → Script editor → Engine: Spark → Create
2. 粘贴脚本 → Job details
| 配置项 | 值 |
| Name | VideoTranslationSubtitle-ttl |
| IAM Role | 有 S3 读写权限的 Glue Role |
| Glue version | 4.0 或 5.0 |
| Language | Python 3 |
| Worker type | G.1X |
| Number of workers | 10(大数据量可增加到 50-100) |
| Job timeout | 480 分钟 |
| Job bookmark | Disable |
3. Save → Run
验证输出:
aws s3 ls s3://glue-test023/ddb-with-ttl/ --recursive --summarize --human-readable
aws s3 cp s3://glue-test023/ddb-with-ttl/<任意文件> - | head -1 | python3 -m json.tool
5.6 步骤六:从 S3 导入创建新表
使用 DynamoDB 的 Import from S3 功能,将 Glue 处理后的数据直接导入并创建新表。
> ⚠️ 注意:Import from S3 会创建一张全新的表,不能导入到已有表。
1. DynamoDB 控制台 → Imports from S3 → Import from S3
第一页 – Source:
| 配置项 | 值 |
| S3 source URL | s3://glue-test023/ddb-with-ttl/ |
| Import file format | DynamoDB JSON |
| Import file compression | None |
第二页 – Target:
| 配置项 | 值 |
| Table name | VideoTranslationSubtitle-ttl |
| Partition key | JobId — String |
| Sort key | Index — Number |
| Capacity mode | On-demand |
2. 点击 Import,等待状态变为 Completed
验证:
aws dynamodb scan --table-name VideoTranslationSubtitle-ttl --limit 3 --region us-east-1
5.7 步骤七:启用 TTL
为新表启用 TTL,DynamoDB 将自动删除 test001 字段值小于当前时间戳的过期记录。TTL 删除不消耗写入容量(WCU),过期后最多 48 小时内完成删除。
1. DynamoDB 控制台 → Tables → `VideoTranslationSubtitle-ttl`
2. Additional settings → Time to Live (TTL) → Turn on
3. TTL attribute:test001
验证:
aws dynamodb describe-time-to-live --table-name VideoTranslationSubtitle-ttl --region us-east-1
5.8 步骤八:添加 Lambda 触发器启动增量同步
历史数据导入完成后,为 Lambda 函数添加 Kinesis 触发器,开始消费窗口期内积累的所有增量记录。
> ⚠️ 关键配置:触发器 Source 必须选择 Kinesis(不是 DynamoDB),Starting position 必须选择 TRIM_HORIZON。选错 Source 会导致数据格式不匹配,Lambda 执行失败;选错 Starting position 会导致窗口期数据丢失。
1. Lambda 控制台 → 选择 `ddb-kinesis-sync-ttl` → Add trigger
2. 配置:
| 配置项 | 值 | 说明 |
| Source | Kinesis | :warning: 不是 DynamoDB |
| Kinesis stream | VideoTranslationSubtitle-stream | |
| Batch size | 100 | |
| Starting position | TRIM_HORIZON | :warning: 从最早记录开始 |
| Batch window | 0 | |
| Enable trigger | :white_check_mark: |
3. 点击 Add
5.9 步骤九:验证数据完整性
向源表写入一条测试数据,验证增量同步链路是否正常工作。
写入测试数据:
aws dynamodb put-item \
--table-name VideoTranslationSubtitle \
--item '{"JobId":{"S":"test-kinesis-001"},"Index":{"N":"1"},"Content":{"S":"Kinesis增量同步测试"},"BeginTime":{"S":"00:00:01,000"},"EndTime":{"S":"00:00:02,000"},"CreatedAt":{"S":"2026-04-07T21:00:00Z"}}' \
--region us-east-1
查询目标表(等待几秒后):
aws dynamodb get-item \
--table-name VideoTranslationSubtitle-ttl \
--key '{"JobId":{"S":"test-kinesis-001"},"Index":{"N":"1"}}' \
--region us-east-1
验证要点:
- ✅ 数据已同步到目标表
- ✅ 所有原始字段完整
- ✅ 新增
test001字段(TTL epoch 秒数) - ✅
test001≈ 当前时间 + 30 天
如有问题,可通过 Lambda 控制台 → 选择函数 → Monitor → View CloudWatch Logs 查看执行日志。
5.10 步骤十:配置 TTL 删除数据归档到 S3 智能分层
为实现完整的数据生命周期管理,当 DynamoDB TTL 自动删除过期数据时,通过 DynamoDB Streams 捕获删除事件,将数据归档到 S3 智能分层存储。
5.10.1 开启 DynamoDB Streams
1. DynamoDB 控制台 → Tables → `VideoTranslationSubtitle-ttl`
2. Exports and streams 标签 → DynamoDB stream details → Turn on
3. View type 选择 New and old images(保留删除前的完整数据)
aws dynamodb update-table \
--table-name VideoTranslationSubtitle-ttl \
--stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGES \
--region us-east-1
5.10.2 创建归档 S3 桶并配置智能分层
aws s3api create-bucket \
--bucket ddb-archive-videosubtitle \
--region us-east-1
配置智能分层归档策略:
aws s3api put-bucket-intelligent-tiering-configuration \
--bucket ddb-archive-videosubtitle \
--id AutoTiering \
--intelligent-tiering-configuration '{
"Id": "AutoTiering",
"Status": "Enabled",
"Tierings": [
{"AccessTier": "ARCHIVE_ACCESS", "Days": 90},
{"AccessTier": "DEEP_ARCHIVE_ACCESS", "Days": 180}
]
}'
智能分层会根据数据访问频率自动在不同存储层之间迁移,无需手动管理:
| 层级 | 自动触发条件 | 存储费(us-east-1) |
| Frequent Access | 默认 | ~$0.023/GB/月 |
| Infrequent Access | 30 天未访问 | ~$0.0125/GB/月 |
| Archive Access | 90 天未访问 | ~$0.004/GB/月 |
| Deep Archive | 180 天未访问 | ~$0.00099/GB/月 |
5.10.3 创建归档 Lambda 函数
1. Lambda 控制台 → Create function
| 配置项 | 值 |
| Function name | ddb-ttl-archive-to-s3 |
| Runtime | Python 3.12 |
| Architecture | arm64 |
2. 粘贴代码:
import boto3
import json
import time
s3 = boto3.client('s3', region_name='us-east-1')
BUCKET = 'ddb-archive-videosubtitle'
def lambda_handler(event, context):
for record in event['Records']:
# 只处理 TTL 删除事件
if record['eventName'] != 'REMOVE':
continue
# TTL 删除的 userIdentity 为 dynamodb.amazonaws.com
user_identity = record.get('userIdentity', {})
if user_identity.get('principalId') != 'dynamodb.amazonaws.com':
continue
old_image = record['dynamodb'].get('OldImage', {})
keys = record['dynamodb']['Keys']
job_id = keys['JobId']['S']
index = keys['Index']['N']
# 按日期分区存储
date_prefix = time.strftime('%Y/%m/%d')
s3_key = f"archive/{date_prefix}/{job_id}_{index}.json"
s3.put_object(
Bucket=BUCKET,
Key=s3_key,
Body=json.dumps(old_image, ensure_ascii=False),
StorageClass='INTELLIGENT_TIERING'
)
return {'statusCode': 200}
3. 点击 Deploy
配置 IAM 权限:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::ddb-archive-videosubtitle/*"
},
{
"Effect": "Allow",
"Action": [
"dynamodb:GetRecords",
"dynamodb:GetShardIterator",
"dynamodb:DescribeStream",
"dynamodb:ListStreams"
],
"Resource": "arn:aws:dynamodb:us-east-1:*:table/VideoTranslationSubtitle-ttl/stream/*"
}
]
}
Policy name:`ddb-archive-s3-policy` → Create policy
调整 Lambda 配置:Memory 256 MB,Timeout 1 min。
5.10.4 添加 DynamoDB Streams 触发器
1. Lambda 函数页面 → Add trigger
| 配置项 | 值 |
| Source | DynamoDB |
| DynamoDB table | VideoTranslationSubtitle-ttl |
| Batch size | 100 |
| Starting position | TRIM_HORIZON |
| Enable trigger | ✅ |
2. 点击 Add
验证归档:
TTL 删除数据后(过期后最多 48 小时内),检查 S3:
aws s3 ls s3://ddb-archive-videosubtitle/archive/ --recursive --summarize --human-readable
六、成本分析
以一张 10TB 的 DynamoDB 源表、日均 100 万次写入为例,估算该方案的一次性迁移成本和持续运行成本。
6.1 一次性迁移成本
| 计费项 | 说明 | 估算费用 |
| DynamoDB Export to S3 | 10TB 全量导出,$0.114/GB | ~$1,140 |
| AWS Glue ETL Job | 50 DPU × 8 小时,$0.44/DPU-hour | ~$176 |
| S3 存储(中转) | 10TB 临时存储,使用后可删除 | ~$230/月(临时) |
| DynamoDB Import from S3 | 免费(仅消耗目标表 WCU) | $0 |
| 一次性迁移小计 | | ~$1,546 |
6.2 持续运行成本(月度)
| 计费项 | 说明 | 月费用 |
| Kinesis Data Streams | On-demand 模式,迁移完成后可关闭 | ~$36(迁移期间) |
| Lambda(增量同步) | 日均 100 万次调用,128MB,平均 100ms | ~$2.10 |
| Lambda(归档) | 仅处理 TTL 删除事件,量较小 | ~$0.50 |
| S3 智能分层(归档) | 归档数据随时间自动降级存储层 | 逐月递减 |
| 持续运行小计 | | ~$38.60(迁移期)/ ~$2.60(迁移后) |
以上价格基于 AWS 官方定价页面(us-east-1 区域,2026 年),实际费用可能因区域和使用模式有所不同。建议使用 AWS Pricing Calculator 进行精确估算。
七、常见问题
Q:执行顺序为什么如此重要?
A:必须先关联 Kinesis Stream(步骤 2)再导出数据(步骤 4)。如果顺序颠倒,导出开始到 Kinesis 关联之间的增量写入将永久丢失,因为这些数据既不在导出快照中,也没有被 Kinesis 记录。
Q:窗口期内的重复数据如何处理?
A:历史数据(通过 Import 导入)和增量数据(通过 Lambda 写入)可能存在重叠。由于 DynamoDB 的 put_item 操作对相同主键的记录执行覆盖写入,重叠数据会被自动去重,不会产生重复记录。
Q:Kinesis 保留期 7 天不够怎么办?
A:Kinesis Data Streams 的保留期可以延长至最长 365 天。如果预计历史数据处理需要更长时间,可以在创建 Stream 时设置更长的保留期。需要注意,延长保留期会增加 Kinesis 的存储费用。
Q:Lambda 触发器的 Source 为什么必须选 Kinesis 而不是 DynamoDB?
A:虽然底层数据来自 DynamoDB,但数据是通过 Kinesis Data Stream 传递的。Kinesis 和 DynamoDB Streams 的数据格式不同——Kinesis 记录需要 base64 解码,而 DynamoDB Streams 记录可以直接读取。选错 Source 会导致数据解析失败。
Q:TTL 删除是即时的吗?
A:不是。DynamoDB TTL 在记录过期后最多 48 小时内完成删除。删除操作不消耗写入容量(WCU),对在线业务无影响。归档 Lambda 会在实际删除发生时被触发。
Q:DynamoDB Streams 和 Kinesis Data Streams 能否同时开启?
A:可以。同一张 DynamoDB 表可以同时关联 DynamoDB Streams 和 Kinesis Data Streams,两者独立运行、互不影响。本方案中,新表同时使用 Kinesis(接收增量同步)和 DynamoDB Streams(捕获 TTL 删除事件进行归档)。
Q:大数据量场景下 Glue Job 如何优化?
A:对于 10TB 以上的数据,建议将 Worker 数量增加到 50-100 个,Worker type 可选 G.2X 以获得更大内存。同时适当增加 Job timeout(如 480 分钟以上),避免因超时导致任务失败。
八、总结
本文介绍了一种基于 Amazon Kinesis Data Streams 的 DynamoDB 历史数据清理与增量同步方案。通过将增量同步的时间窗口从 24 小时扩展到 7 天(最长 365 天),从根本上解决了大数据量场景下的迁移时间约束问题。
该方案的核心价值:
| 维度 | 效果 |
| 零数据丢失 | Kinesis 长保留期 + TRIM_HORIZON 消费,确保窗口期内所有增量数据被完整同步 |
| 零停机 | 源表持续提供服务,迁移过程对业务完全透明 |
| 自动化生命周期 | TTL 自动过期 → DynamoDB Streams 捕获 → Lambda 归档到 S3 智能分层,全链路自动化 |
| 成本优化 | 清理历史数据降低 DynamoDB 存储费用,归档数据利用智能分层最低至 ~$0.001/GB/月 |
| 架构简洁 | 全部使用 AWS 托管服务,无需维护额外基础设施,易于运维 |
适用场景:DynamoDB 大表(10TB+)的历史数据清理、需要零停机迁移且迁移周期超过 24 小时的场景、需要完整数据生命周期管理(活跃 → 过期删除 → 低成本归档)的业务。
➡️ 相关产品
- Amazon DynamoDB — 全托管 NoSQL 数据库
- Amazon Kinesis Data Streams — 实时数据流服务
- AWS Lambda — 无服务器计算
- AWS Glue — 无服务器数据集成服务
- Amazon S3 — 对象存储服务
➡️ 下一步行动:
相关产品:
- Amazon DynamoDB — 无服务器分布式 NoSQL 数据库
- Amazon Kinesis — 实时流数据处理
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- AWS Lambda — 无需服务器即可运行代码
- Amazon Glue — 简单、可扩展的无服务器数据集成
相关文章:
- 乐易游戏数据库最佳实践:超越原生Amazon DynamoDB自动弹性扩展的创新解决方案
- 使用 Amazon EventBridge 与 AWS Lambda 实现 ALB 流量镜像会话自动化配置
- 为 Amazon S3 通用存储桶引入账户区域命名空间
- 向量存储成本降低 85%:用 Amazon S3 Vectors 构建企业级多平台统一知识库
- Amazon S3 二十周年:回望初心,共筑未来
九、参考资源
- Amazon DynamoDB Developer Guide — Export to S3
- Amazon DynamoDB Developer Guide — Import from S3
- Amazon DynamoDB Developer Guide — Time to Live
- Amazon DynamoDB Developer Guide — Change data capture with Kinesis Data Streams
- Amazon Kinesis Data Streams Developer Guide
- Amazon S3 Intelligent-Tiering
- AWS Pricing Calculator
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
