亚马逊AWS官方博客
使用您自己的 Amazon SageMaker 主动学习标签工作流程
借助 Amazon SageMaker Ground Truth,您可以轻松,低成本地构建精确标记的机器学习 (ML) 数据集。为了降低标记成本,SageMaker Ground Truth 使用主动学习来区分难以标记和易于标记的数据对象(例如图像或文档)。难以标注的数据对象被发送给人工人员标记,而易于标注的数据对象则通过机器学习自动标记(auto-labeling)。
SageMaker Ground Truth 中的自动标记功能使用预定义的 Amazon SageMaker 算法来标记数据,并且仅当您使用受支持的 SageMaker Ground Truth 内置任务类型之一创建标记作业时才可用。
利用此博文,使用您自己的算法创建一个主动学习工作流程,在该工作流程中进行训练和推理。此示例可用作执行自定义标签作业主动学习和自动注释。
本文包含两个部分:
- 在第 1 部分中,我们演示了如何使用 Amazon SageMaker 内置算法 BlazingText 创建主动学习工作流程。
- 在第 2 部分中,我们用自定义 ML 模型替换 BlazingText 算法。
要运行和自定义这些部分中使用的代码,请在笔记本实例的 SageMaker 示例部分中使用笔记本bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb(笔记本)。您可以进一步修改此代码。例如,您可以使用此 GitHub 存储库的src目录中提供的代码,使用不同的主动学习逻辑而不是随机选择。
本文引导您使用 UCI 新闻数据集完成自定义主动学习工作流。该数据集包含大约 420,000 篇文章的列表,这些文章分属以下四个类别之一:商业(b)、科学和技术 (t)、娱乐 (e) 和健康与医学 (m)。
解决方案概述
对于此解决方案,您可以使用 AWS Step Functions 为文本分类标签作业创建主动学习工作流。AWS Step Functions提供了一种管理分布式应用程序的简单方法。
下图描述了此解决方案的主动学习循环逻辑。
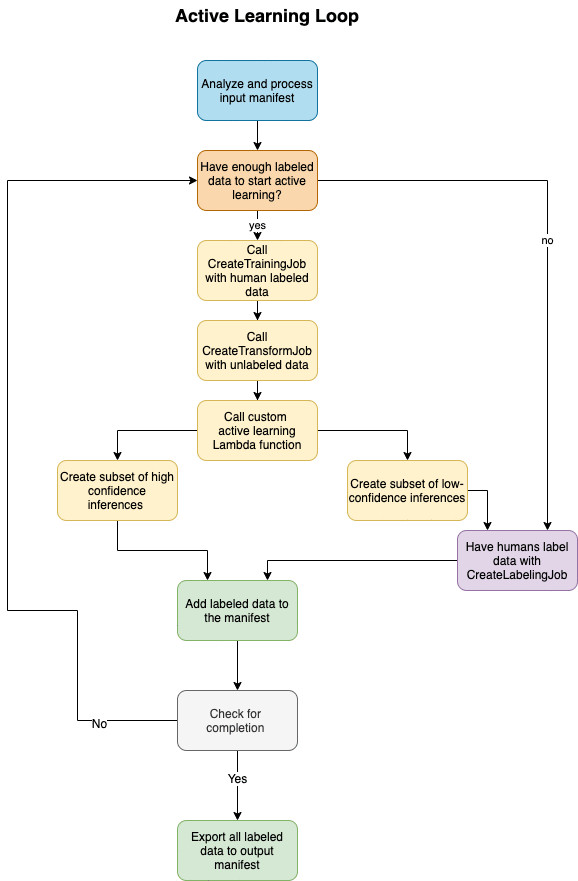
在GitHub 中的 Python 模块对应于上述步骤:
- 在 Bootstrap 中指定了“分析和处理输入清单”。
- 在 MetaData 中指定“是否有足够的标签数据来开始主动学习?”。
- 在Labeling中指定“使用
CreateLabelingJob人工添加标签数据”。 - 在Output中指定了“将标签数据添加到清单”和“将所有标签数据导出到清单”。
- ActiveLearning 中指定了除“检查完成情况”之外的其余步骤。
- “检查完成情况”不属于任何 Python 模块,而是直接在Step Function中指定。
主动学习工作流包含以下步骤:
- 分析输入清单以确定已标记的数据对象的数量(count)。必须标记至少 20% 的数据才能启动主动学习循环。
- 如果所有数据都已标记,请复制当前清单作为最终输出清单。
- 如果标记的数据不足 20%,请使用
CreateLabelingJob发送 20 % 的数据进行人工标记。
- 当有足够的数据来训练模型时,启动主动学习循环。
- 转换作业结果所针对的自动标签数据具有最高的置信度来推断标签。
- 调用
CreateLabelingJob,以较低的推理置信度人工标记未标记的数据对象的子集。
- 重复该循环。
先决条件和设置
要使用本文创建自定义主动学习工作流,您需要完成以下先决条件:
- 创建 AWS 账户
- 使用完成本演练所需的权限创建一个 IAM 角色。您的 IAM 角色必须附加以下 AWS 托管策略:
- IAMFullAccess
- CloudWatchFullAccess
- AWSLambdaFullAccess
- AWSStepFunctionsFullAccess
- AmazonSageMakerFullAccess
- AWSCloudFormationFullAccess
- 熟悉 Amazon SageMaker 的标签、训练和批量转换、AWS CloudFormation 和 Step Functions。
此外,您将需要一个Amazon SageMaker Jupyter 笔记本实例来使用该笔记本。要了解如何创建新的 Amazon SageMaker Jupyter 笔记本实例,请参阅创建笔记本实例。使用附加了AmazonSageMakerFullAccessIAM 策略的 IAM 角色来创建您的笔记本实例。
启动笔记本实例后,请在您的实例的 SageMaker 示例的Ground Truth 标记作业部分中查找bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb。请参阅使用示例笔记本以了解如何查找 Amazon SageMaker 示例笔记本。
启动 CloudFormation 堆栈
第一步是启动 CloudFormation 堆栈。这将在 AWS Lambda, Step Functions 和 IAM 中创建创建主动学习工作流所需的资源。
您可以使用以下启动堆栈按钮在 AWS Region us-east-1 中的CloudFormation 控制台中启动堆栈。要在其他 AWS 区域中启动堆栈,请参考 GitHub 存储库的 README 文件中的说明。

此 CloudFormation 堆栈在 AWS Step Functions 中生成两个状态机:ActiveLearning-* 和 ActiveLearningLoop-*,其中 * 是您启动 CloudFormation 堆栈时使用的名称。
成本
在 Amazon SageMaker Jupyter 笔记本实例中运行本演练的第 1 部分和第 2 部分时,将产生以下成本:
- Amazon SageMaker Ground Truth 中的人员数据标签成本。这将取决于您使用的劳动力类型。如果您是 SageMaker Ground Truth 的新用户,我们建议您使用私人劳动力,并自己以员工身份来测试您的添加标签作业配置。要了解有关这些成本的更多信息,请参阅 https://aws.amazon.com/sagemaker/groundtruth/pricing/。
- Amazon SageMaker 训练和推断成本。该成本将根据您使用的算法类型而有所不同。要了解有关 Amazon SageMaker 定价的更多信息,请参阅 https://aws.amazon.com/sagemaker/pricing/。
- Amazon SageMaker Jupyter 笔记本实例 EC2 成本。请参阅 https://aws.amazon.com/sagemaker/pricing/instance-types/ 确定创建的笔记本实例类型产生的成本。
- AWS Lambda 和 Step Function 成本。使用提供的 CloudFormation 模板创建的主动学习工作流使用 AWS Lambda 和 Step Functions。
- 请参阅 https://aws.amazon.com/lambda/pricing/ 了解有关 AWS Lambda 定价的更多信息。
- 请参阅 https://aws.amazon.com/step-functions/pricing/ 了解有关 Step Function 定价的更多信息。
- S3 的存储成本。请参阅 https://aws.amazon.com/s3/pricing/ 了解有关 S3 定价的更多信息。
第 1 部分:使用 BlazingText 创建主动学习工作流
您可以在 Amazon SageMaker Jupyter 笔记本实例中,使用笔记本的第 1 部分来创建主动学习工作流中所需的资源。具体来说,您需要执行如下操作:
- 清理数据并创建一个输入清单文件。
- 创建创建添加标签作业所需的资源。例如,指定标签类别和工作线程任务模板以生成工作线程 UI。
您可以使用这些资源来配置添加标签作业请求(JSON 格式)。在第 1 部分末尾,将此 JSON 复制并粘贴到调用 CreateLabelingJob的 Step Function 中。
创建输入清单和添加标签作业资源
要创建清单文件,请执行以下步骤:
- 在 Amazon SageMaker 笔记本实例中打开笔记本。
- 设置 Amazon SageMaker 环境。以下代码为数据定义了会话、角色、区域和 S3 存储桶:
- 下载并解压缩 UCI 新闻数据集。本演练使用文件
newsCorpora.csv并从该文件中随机选择 10,000 篇文章来创建我们的数据集。每篇文章对应于我们输入清单文件的一行。 - 清理数据集并创建 10,000 篇文章的子集。
- 将数据集保存到
news_subset.csv。
您使用此文件来创建我们的输入清单文件。为了启动主动学习循环,必须标记 20% 的数据。为了快速测试主动学习组件,本文包括了输入清单数据集中提供的 20%的原始标签。
您将使用部分标记的数据集作为主动学习循环的输入。本文档将演示如何使用主动学习来生成其余标签。
笔记本的其余部分指定了创建添加标签作业配置所需的资源。这些资源包括:
- 一个存储在 S3 存储桶中的标签类别 JSON 文件。
- 一个用于创建工作线程界面的工作线程任务模板。
- 一个工作团队 ARN。您可以对其进行自定义,以使用公共 (Amazon Mechanical Turk)、私人或供应商工作团队。要使用私人劳动力,请将
USE_PRIVATE_WORKFORCE设置为True。 - Lambda 之前和之后的函数 ARN。
- 帮助工作线程找到并完成您的任务的任务标题、描述和关键字。
您可以在your human_task_configJSON 中使用这些资源。
- 使用以下代码生成 JSON:
print(json.dumps(ground_truth_request, indent=2))
- 复制结果。您可以使用它在 Step Functions 中启动主动学习工作流。
启动主动学习工作流
在使用笔记本生成用于配置添加标签作业请求的 JSON 之后,您可以使用它来启动主动学习工作流。您的 CloudFormation 堆栈构建默认使用 Amazon SageMaker BlazingText 算法。
要使用 BlazingText 启动主动学习工作流,请执行以下步骤:
- 在 AWS Step Functions 控制台上,选择State Machines。选择状态机 ActiveLearningLoop-*,其中 * 是启动 CloudFormation 堆栈时使用的名称。
- 另外,为您的主动学习工作流指定execution name。
- 将您从笔记本复制的 JSON 粘贴到Input – optional代码块中。
- 选择Start execution。
监控您的主动学习工作流
由于您开始时标记了 20% 的标签数据,所以这将启动您的主动学习工作流。要监视工作流的进度,请执行以下步骤:
- 在 AWS Step Functions 控制台上,选择State Machines。
- 选择状态机 ActiveLearningLoop -*。
在Executions部分,有一个主动学习工作流及其状态的列表。
- 要查看工作流的状态,请从列表中选择您的工作流。
您可以在Visual workflow部分中监控状态。
标记完所有数据后,所有标签都将导出到 S3 存储桶中的输出清单文件中。下图描述了完整的主动学习工作流的架构

第 2 部分:创建自定义模型并将其集成到主动学习工作流中
第 2 部分演示了如何将自己的自定义训练和推理算法引入开发的主动学习工作流中。
在本部分中,您将使用 Keras 深度学习模型将自定义模型添加到主动学习工作流中。您可以使用 Amazon SageMaker Jupyter 笔记本中 UCI 数据集中的 1,000 个数据点训练模型。该模型仅用于该演示,在本教程的其余部分中,我们仅使用训练和推理算法。
要完成本部分,请使用笔记本的第 2 部分。
本部分假定您已执行以下步骤:
- 完成本文中的先决条件
- 启动提供的 CloudFormation 堆栈
- 完成了本文第 1 部分中的Creating an input Manifest and labeling job resources部分。
开发和容器化模型
本文中开发和容器化模型的方法受到以下 GitHub 存储库的启发,该存储库使用自定义 TensorFlow Docker 容器构建、训练和部署 ML 模型。
您可以使用笔记本执行以下操作:
- 读取并清理数据集。
- 使用 Keras Tokenizer 类对数据对象进行标记。
- 将数据集标记化之后,您可以使用它来训练模型。我们训练了Keras 深度学习模型。
- 在 Docker 容器中容器化该模型。
- 将容器添加到 ECR。Amazon SageMaker 将在主动学习工作流期间检索此图像以进行训练和推理。
笔记本中的最终代码单元将打印 Docker 映像的 ECR ID。您可以将其用于整个 Amazon SageMaker 的训练和推理。
使您的容器进入主动学习工作流:
在确定算法符合标准之后,请使用本部分用主动学习工作流中的自定义 ML 模型替换第 1 部分中使用的 BlazingText 算法。
步骤 1:更新容器 ECR 参考
要更新容器 ECR 参考,请执行以下步骤:
- 在 AWS Lambda 控制台上,找到名称为 *-PrepareForTraining-<###> 的 Lambda 函数,其中 * 是启动 CloudFormation 堆栈时使用的名称,而 -<###> 是字母和数字的列表。
- 识别现有算法规范,该规范类似于以下代码:
- 将
TrainingImage从 dkr.ecr.us-east-1.amazonaws.com/blazingtext:latest 替换为笔记本中最后打印语句的输出。
步骤 2:更改批处理策略
CreateTransformJob支持两个批处理策略 –MultiRecord和SingleRecord。有关更多信息,请参阅 CreateTransformJob。Amazon SageMaker BlazingText 算法支持MultiRecord,而本演练中使用的 Keras 容器则支持SingleRecord。要更改批处理策略,请执行以下步骤:
更改批处理策略:
- 在 AWS Step Functions 控制台上,选择State Machines。
- 选择“ActiveLearning-*”旁边的单选按钮。
- 选择edit。
- 查找
CreateTransformJob状态,该状态负责调用批处理转换作业。请参阅以下代码:
- 将
MultiRecord替换为SingleRecord。 - 选择Save。
以下屏幕截图显示了进行此编辑后状态机控制台的页面。

完成这些步骤之后,重复第 1 部分中的步骤以启动主动学习工作流。具体来说,您将需要使用Start an Active Learning Workflow部分来启动主动学习工作流。
成功完成状态机之后,您已经使用机器标签和人工标签以及自定义训练和推理算法生成了标签数据。
清理
为避免产生未来成本,请停止并删除用于演练的笔记本实例。
另外,在 Amazon SageMaker 控制台上,停止完成本教程时创建的所有训练(Training部分中)、转换(Inference 部分中)或标记(在 Ground Truth 部分中)作业。
结果
在本文的第 1 部分中,有 52% 的数据为人工标记,另外 48% 的数据为自动标记。这些百分比取决于您使用的特定训练算法、推理算法和主动学习逻辑。当您实施自己的主动学习工作流时,这些数字可能会因您使用的算法和主动学习逻辑以及所需标签准确性级别而异。
当您将自己的模型带入主动学习工作流时,为获得更好的结果(自动标记数据的百分比较高),请确保当用于训练模型的标记数据中存在噪声时,能够继续按预期执行模型。
结论
在本文中,您创建了一个主动学习工作流,并使用该工作流从 ML 模型推论和人工工作线程产生高质量的标签。
您可以将此工作流用于各种自定义添加标签任务,以减少为大型数据集添加标签的成本。您可以使用任何自定义学习算法和主动学习逻辑,并根据需要更改此示例。要开始使用 Blazing Text 预览主动学习工作流,请启动 Cloud Formation 堆栈并完成第 1 部分。