亚马逊AWS官方博客
Data for AI:明其所耗,知其所因!让每一分 Token 消耗都可量化的全栈实践
摘要:本文是”解决 Agentic AI 应用 Token 爆炸问题”系列的第四篇,聚焦可观测性(Observability)。前三篇分别介绍了 Token 爆炸的根本原因、记忆管理优化和 Skill 检索优化。本篇从 OpenClaw 的成本可观测性现状出发,梳理社区主流方案,并结合亚马逊云科技全栈能力给出经过实测验证的落地路径。
目录
一、看不见的 Agent,是最危险的 Agent
1.1 Agentic AI 为什么让传统监控失效
在开篇博客中,我们提到了 Token 爆炸的三类根本原因,其中黑盒型爆炸是企业最难处理的一种——不是花了钱,而是不知道钱为什么花掉。这背后是 Agentic AI 与传统后端服务的一个本质差异:Agent 的行为是非确定的。传统 API 调用的代码路径是静态可分析的,而 OpenClaw Agent 的每次执行路径由大模型实时推理决定,同样的输入可能产生完全不同的工具调用序列。
这种不确定性让成本监控失效,具体体现在三个维度:
- 多轮调用难以计量:Agent 在完成一个任务时会自主决策、多次调用模型,每一轮的 Token 消耗都不同,传统监控只能看到”总量”,无法拆解到每一步
- 工具调用成本不透明:Agent 调用了哪些 Skill、每个 Skill 消耗了多少 Token、哪一步触发了重试,在传统日志里几乎看不到
- 成本归因困难:同一个用户的不同任务、不同渠道的会话,Token 消耗无法按维度拆解,出了问题不知道该优化哪里
未经观测的 Agent 在生产环境中存在典型风险:Token 成本失控(Agent 可能陷入”思维循环”,一夜产生高额账单)、上下文窗口逐渐填满导致响应延迟持续增加、输出被强制截断却无人察觉。
1.2 OpenClaw 的成本可观测性现状
通过分析 OpenClaw 的源码和文档,可以看到它在可观测性方面已经做了相当扎实的基础建设,但在成本可见性方面距离生产级要求还有明显差距。
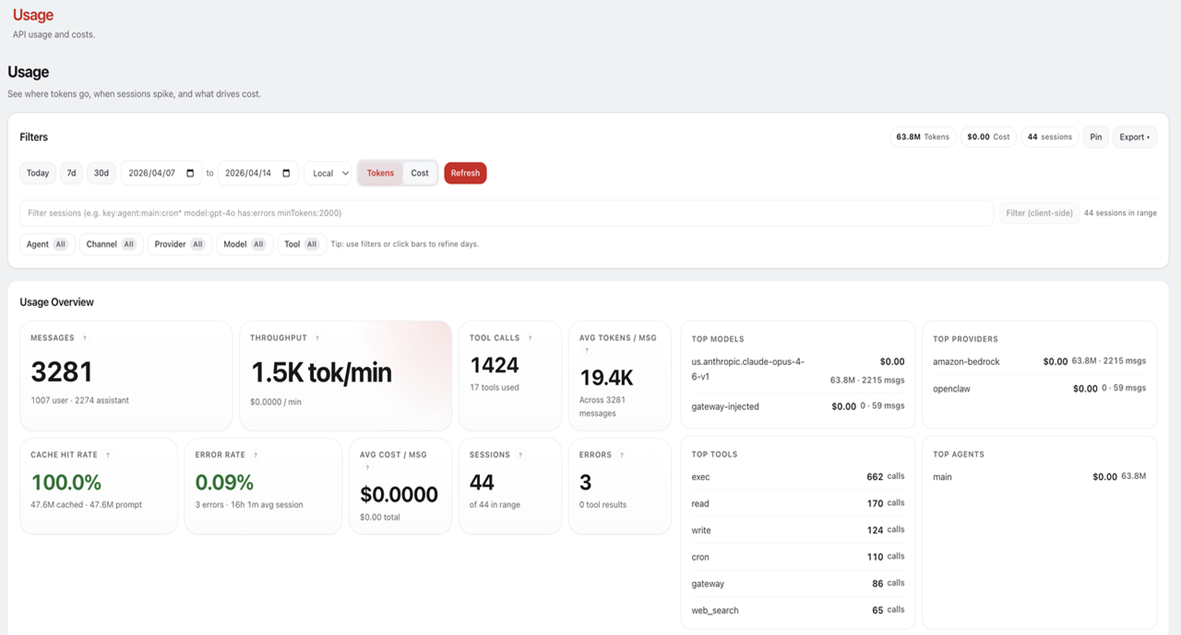
[图1:OpenClaw 控制台自带监控信息展示] |
1.2.1 OpenClaw 默认具备如下监控能力
1. 基础 Token 监控
/status 命令显示上次响应的 input/output tokens 和预估成本;Context 窗口追踪实时显示当前 Token 使用量 vs 上下文窗口限制;Session 级别的完整对话历史和 Token 使用数据保存在 sessions.json 中。
2. 结构化日志系统
完整的 JSONL 结构化日志体系,支持多级别(debug/info/warn/error)、多子系统前缀,敏感信息脱敏。每一条 assistant 消息都记录了 usage(input/output/cacheRead/cacheWrite tokens)、stopReason、model、provider 等字段,是成本分析的原始数据来源。
3. diagnostics-otel 插件:原生 OpenTelemetry 集成
OpenClaw 官方内置了 diagnostics-otel 插件,通过 OTLP/HTTP 协议将诊断事件导出为 OTel Metrics/Traces,涵盖 openclaw.tokens、openclaw.cost.usd、openclaw.run.duration_ms 等 18 个指标。
1.2.2 成本可见性的核心短板
- 实际费用数据缺失:OpenClaw 的费用估算依赖本地定价配置(`models.providers.<provider>.models[].cost`),用户需要手动在配置中为模型添加价格参数才能获取到实际费用支出
- 无 Skill 级别归因:工具调用嵌套在
message.content[]数组里,官方插件不捕获,无法知道哪个 Skill 消耗了多少 Token - 无预算控制机制:没有 Token 预算上限,超出时无法自动告警或降级
- 无主动推送:所有监控都需要主动打开界面查看,异常发生时不会主动通知
1.3 成本可观测性需要回答的三个问题
基于以上现状,我们认为 OpenClaw 的成本可观测性需要回答三个核心问题:
1. 花了多少钱:这次任务消耗了多少 Token,实际 API 费用是多少?Bedrock 用户如何在没有费用字段的情况下估算成本?
2. 钱花在哪里:哪个 Skill 消耗最多?哪个渠道最贵?哪种工具调用频率最高?输出截断率是否偏高?
3. 异常如何发现:费用突增时能否主动告警?不需要主动查看时如何保持感知?
回答不了这三个问题,就无法有效控制 Agentic AI 的运营成本。
二、实测:四种可观测性方案
面对官方插件的不足,我们在实际环境中测试了四种方案,从轻量本地工具到亚马逊云科技全栈服务,覆盖从个人开发到企业生产的完整场景。
2.1 方案一:OTel + 亚马逊云科技 Managed Grafana
2.1.1 核心组件
- OpenClaw diagnostics-otel 插件:将诊断事件转换为 OTel Metrics,通过 OTLP/HTTP 推送
- Distro for OpenTelemetry(ADOT):亚马逊云科技维护的 OpenTelemetry Collector 发行版,作为数据管道中间件,通过 SigV4 签名写入 AMP
- Amazon Managed Service for Prometheus(AMP):托管的 Prometheus 兼容时序数据库,完全兼容 PromQL,无需运维,按存储量和查询量计费
- Amazon Managed Grafana:托管的 Grafana 服务,支持亚马逊云科技 SSO 登录,原生集成 AMP 数据源

[图2:OTel + Managed Grafana 方案流程图] |
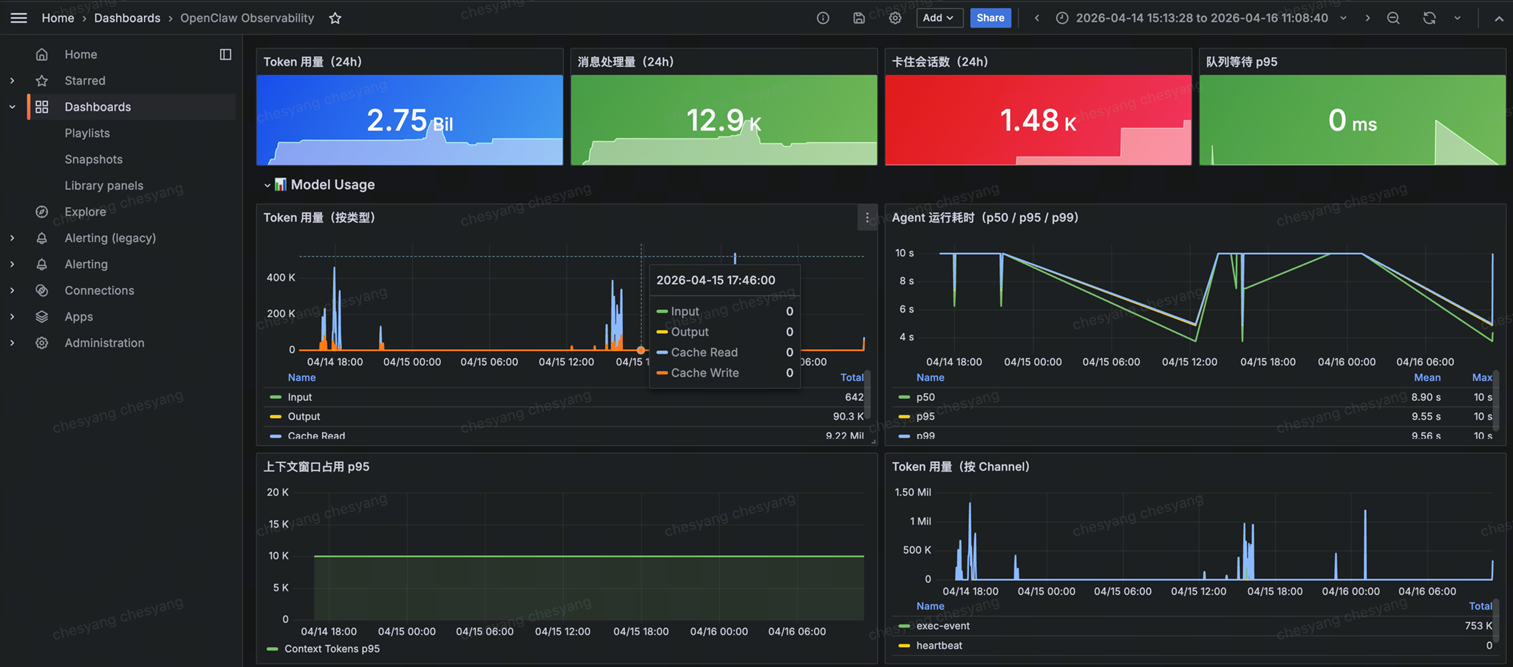 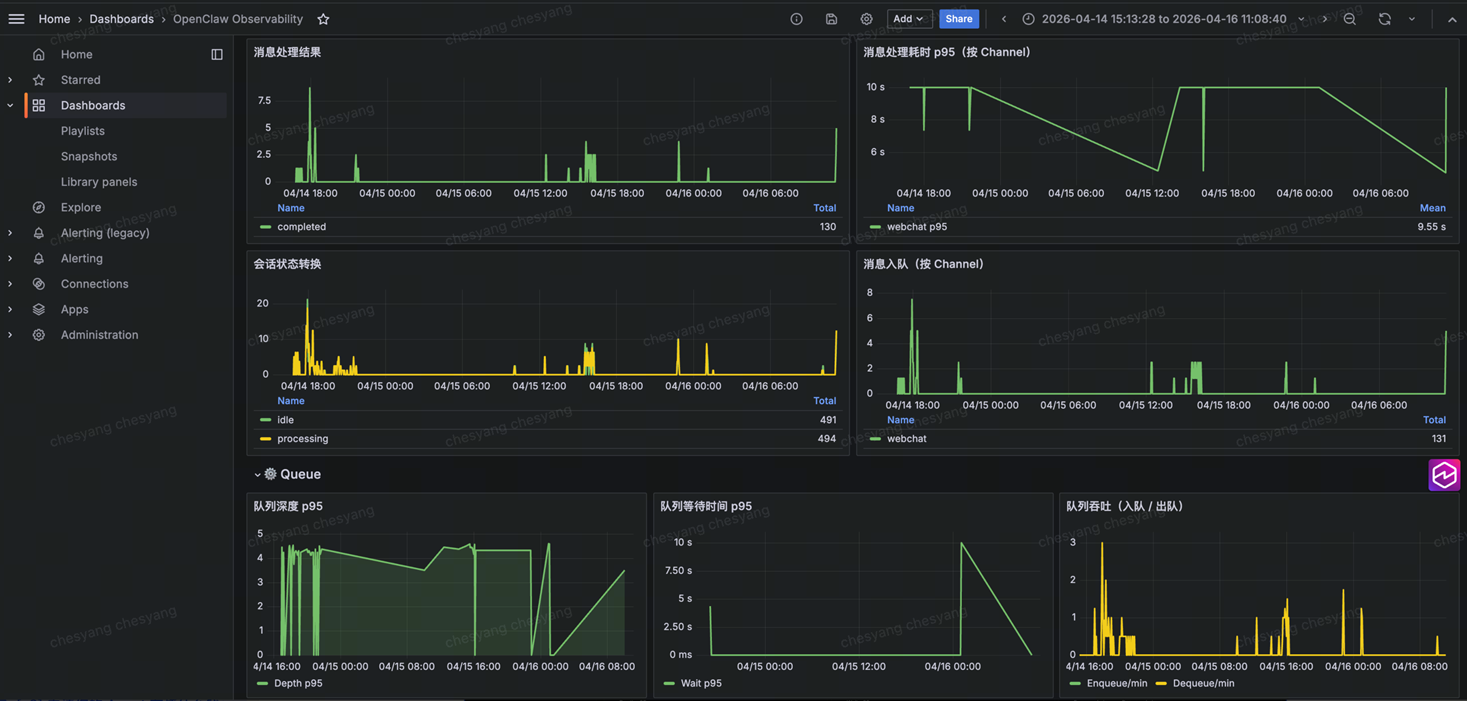
[图 3-4:OTel + Managed Grafana 方案成果示例] |
2.1.2 与纯开源方案相比的优势
- 支持在Grafana 手动配置告警规则,帮助企业及时发现 Token 以及其他性能指标的异常情况。
- AMP 按量计费无需预置容量,Managed Grafana 支持亚马逊云科技 SSO 统一身份认证,ADOT 与 亚马逊云科技服务原生集成开箱即用。
2.1.3 回答了哪些问题
✅ 花了多少 Token:用量趋势、Agent 运行耗时、上下文窗口占用
✅ 钱花在哪里:按 channel/provider/model 分维度的 Token 消耗
✅ 企业级监控还需要关注什么指标:除了 Token之外,还包括了消息处理延迟、队列深度、错误率等指标
✅ 主动告警:支持在 Grafana 手动配置告警规则
❌ Bedrock 费用:openclaw_cost_usd_total 指标为空,Bedrock 用户看不到费用数据
❌ Skill 级归因:工具调用不被捕获,无法拆解到 Skill 维度
适用场景:需要长期存储、跨服务聚合、生产告警的团队,熟悉 Grafana 的运维人员。
2.2 方案二:ClawProbe + 亚马逊云科技 Managed Grafana
ClawProbe 是社区开发者专为 OpenClaw 设计的开源工具(github.com/seekcontext/ClawProbe),直接读取本地 session .jsonl 文件,内置 30+ 模型价格表,在 Bedrock 不返回费用的情况下自行估算:
clawprobe status:即时快照,含今日费用、上下文占用率、活跃告警clawprobe top:2 秒刷新的实时仪表盘clawprobe cost --week:本周费用明细,含每日分布和月度预测clawprobe session:逐轮 Token 时间线、工具调用统计、压缩事件记录
核心思路:通过自行编写的桥接脚本,每 10 秒将 ClawProbe 数据转换为 OTLP Metrics 推送到 ADOT,在托管 Grafana 中展示,侧重点是 Agent 级费用细节。

[图 5:ClawProbe + Managed Grafana 方案流程图] |
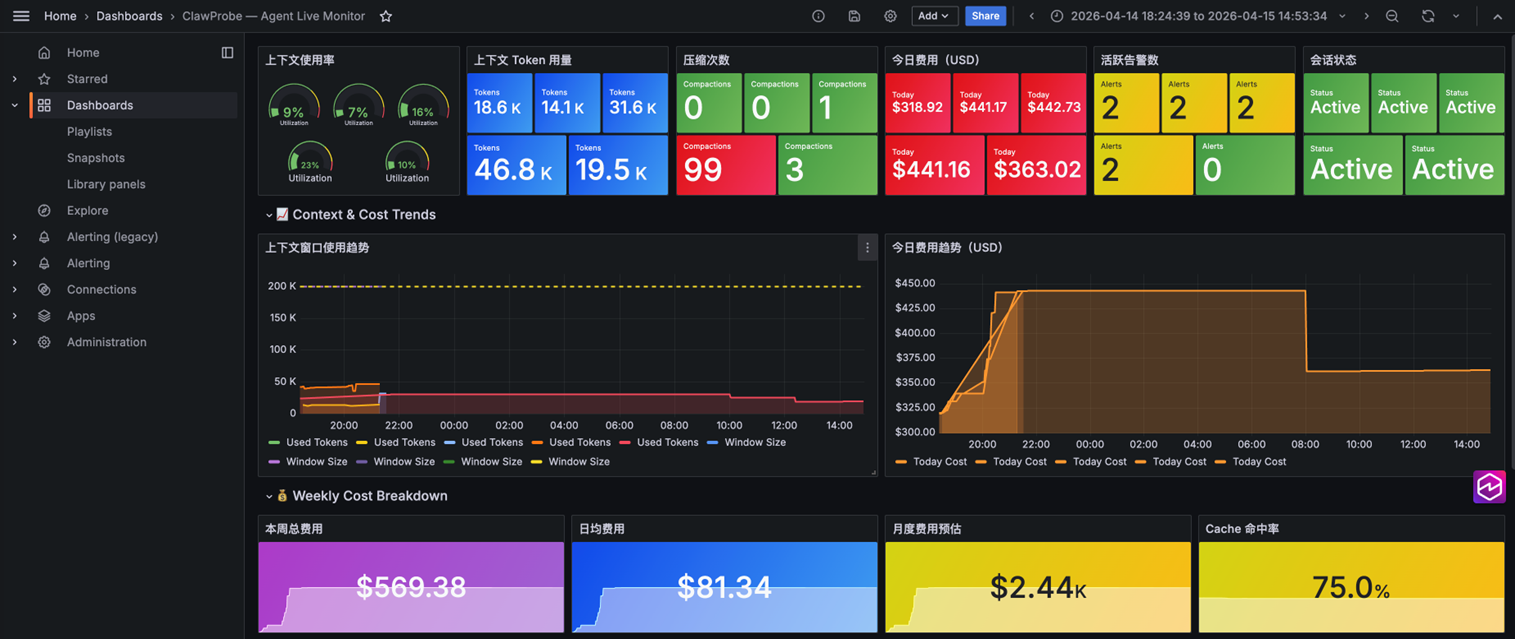 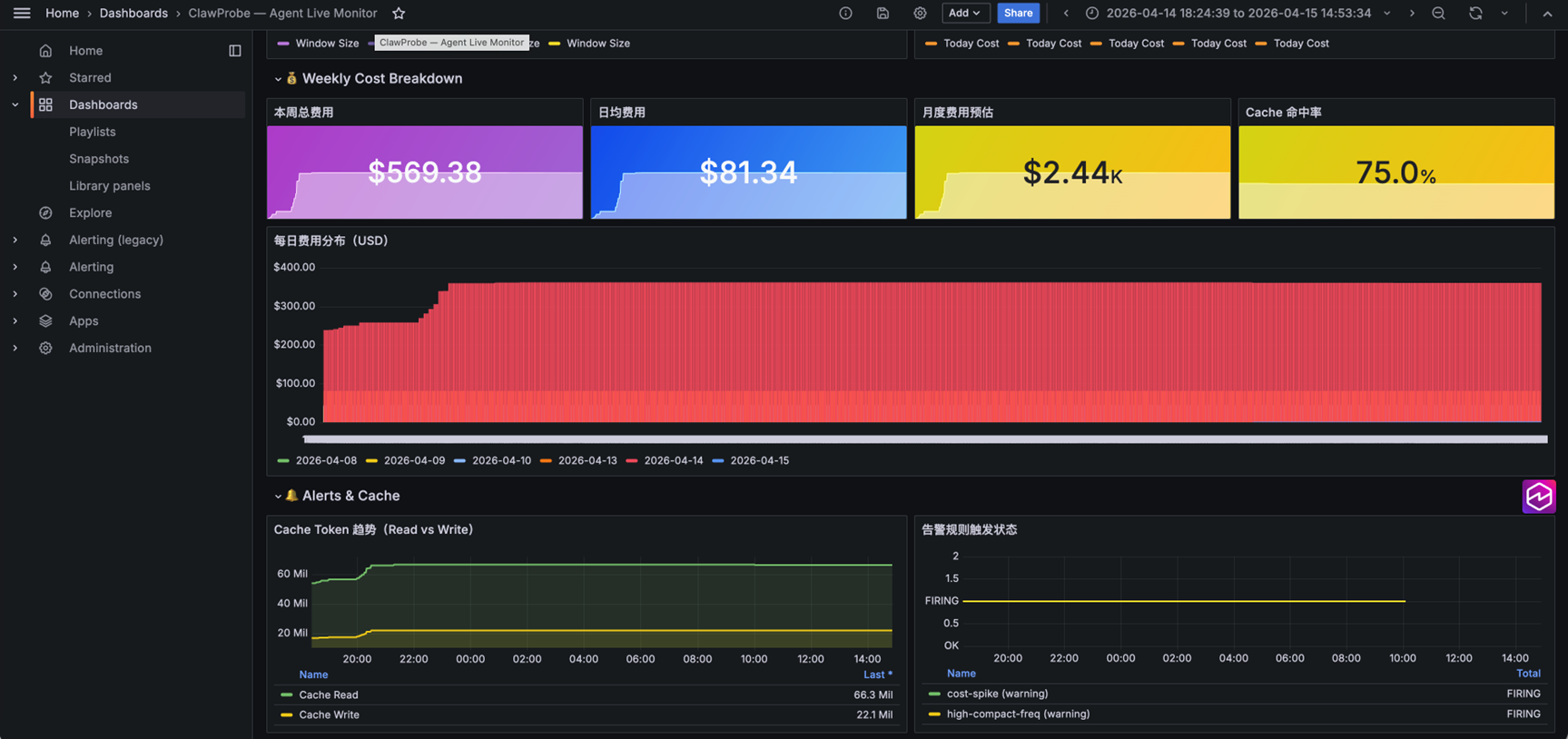
[图 6-7:ClawProbe + Managed Grafana 方案成果示例] |
2.2.1 回答了哪些问题
✅ 花了多少钱:Bedrock 内置价格表估算,今日/本周/月预测费用全部可见
✅ 钱花在哪里:逐轮 Token 明细、工具调用统计、压缩事件记录
✅ 异常如何发现:5 条内置告警规则(截断率偏高、压缩频率过高、上下文窗口 >90%、费用突增、Memory 过大)
✅ 主动告警:支持在 Grafana 手动配置告警规则
❌ Skill 级归因:工具调用不被捕获,无法拆解到 Skill 维度
适用场景:开发调试时的实时细粒度分析,Bedrock 用户的费用监控。
2.3 方案三:创建 Skill 解析日志 + HTML 展示
核心思路:直接解析本地 session .jsonl 文件,生成自包含 HTML 报告,通过 OpenClaw cron + Skill 每天定时自动推送摘要到 webchat 或者其他渠道。

[图 8:Skill 解析本地日志 + HTML 展示方案流程图] |
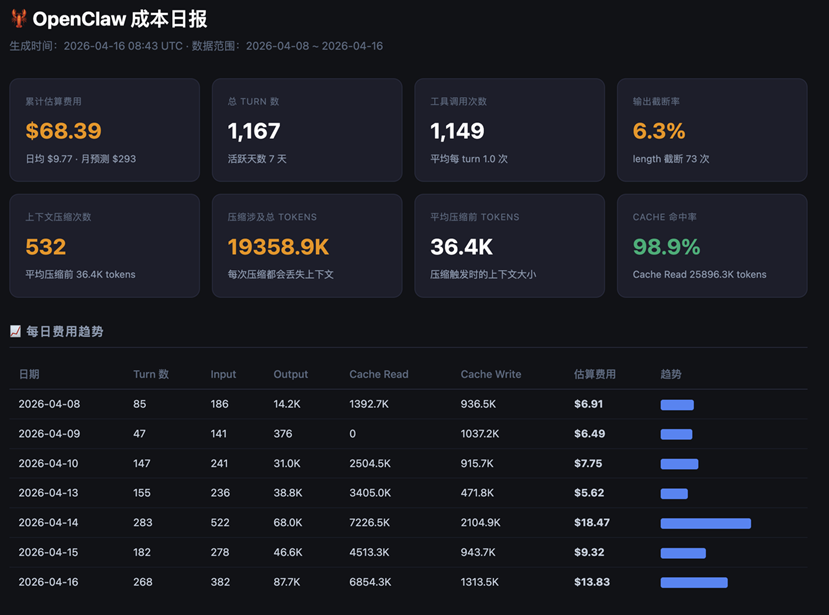 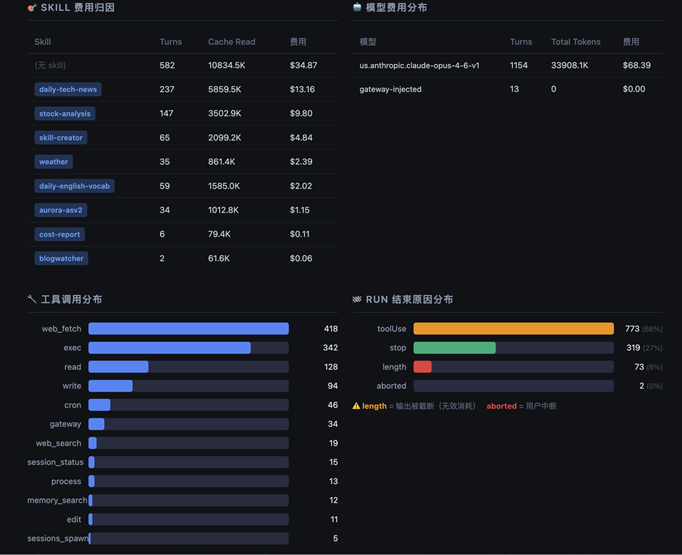 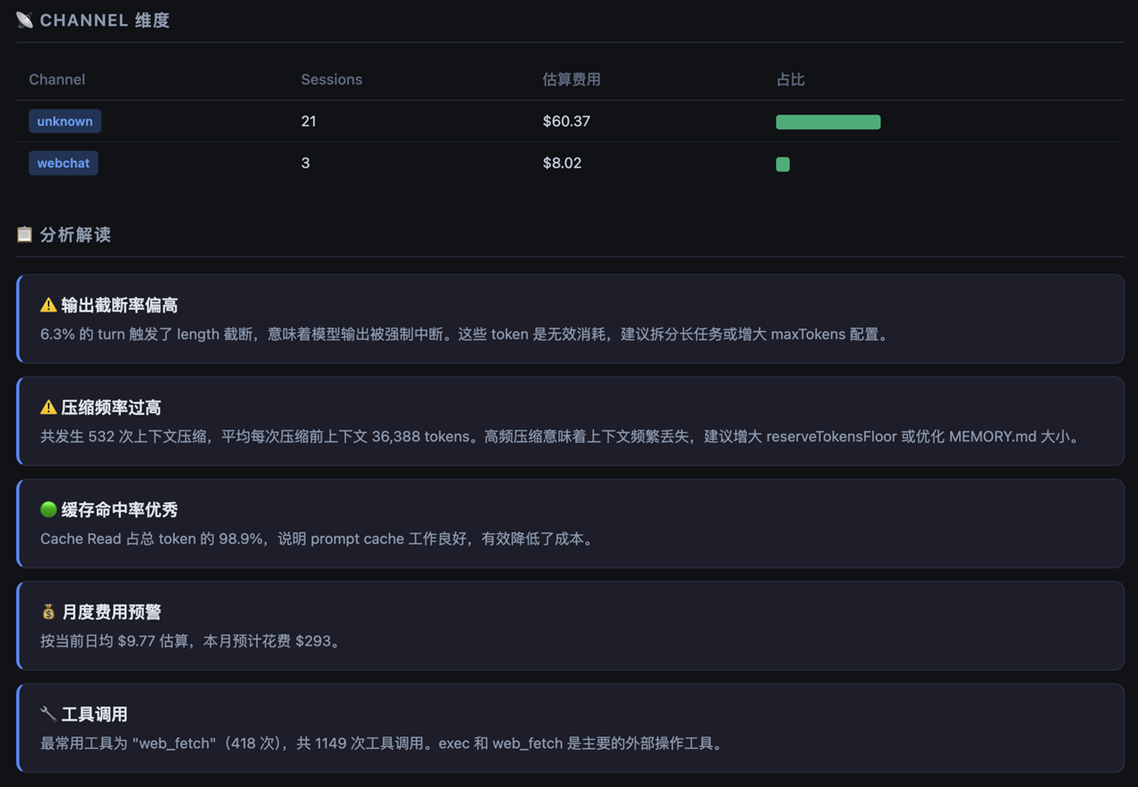
[图 9-11:Skill 解析本地日志 + HTML 展示方案成果示例] |
2.3.1 回答了哪些问题
✅ 花了多少钱:Bedrock 内置价格表估算,含月度费用预测
✅ 钱花在哪里:Skill 归因、工具调用分布、Channel 维度、截断率分析
❌ 主动告警:该方案由 Skill 生成 HTML 文件展示,如果需要主动告警建议通过 Skill 自行来实现
适用场景:日常巡检报告,并希望对结果进行初步解析。
2.4 方案四:S3 + Athena + QuickSight(交互式分析 + 自然语言提问)
前三种方案回答的都是”你已经知道要看什么”——提前建好图表,只能看你想到的维度。但 AI Agent 的行为是非确定的,真正出问题时你往往不知道该看哪里。方案四用 Amazon Q in QuickSight 填补了这个空白:用自然语言描述你的疑问,直接得到图表答案,不需要预设分析角度,也不需要写 SQL。
核心思路:将 session 日志持续上传至 S3,通过 Athena 做 Serverless SQL 分析,QuickSight 可视化 + Amazon Q 自然语言提问,实现对于系统状态的深挖分析。
2.4.1 核心组件
- Skill – flatten-and-upload:本地预处理脚本,读取 OpenClaw session .jsonl 文件,将嵌套 JSON 扁平化(提取 stopReason、工具调用、Skill 归因等字段),按日期分区上传至 S3。见下面“核心代码示例”部分。
- Amazon S3:存储扁平化后的 session 日志,按 date=YYYY-MM-DD 分区,Athena 查询时做分区裁剪降低扫描成本
- Glue Data Catalog:自动注册 schema,让 Athena 能直接查询 S3 上的 JSONL 文件,无需 ETL 流程
- Amazon Athena:Serverless SQL 查询引擎,直接查询 S3 文件,按扫描量计费($5/TB),基于 8 个预置视图覆盖费用、工具调用、Skill 归因、stopReason 等全部分析维度
- Amazon QuickSight:托管的商业智能服务,通过 DIRECT_QUERY 模式直连 Athena,S3 有新文件即可查询,无需数据导入,Dashboard 覆盖 13 个面板
- Amazon Q in QuickSight:自然语言提问能力,直接用中文描述分析需求,自动生成图表回答,无需预设分析角度,也无需编写 SQL
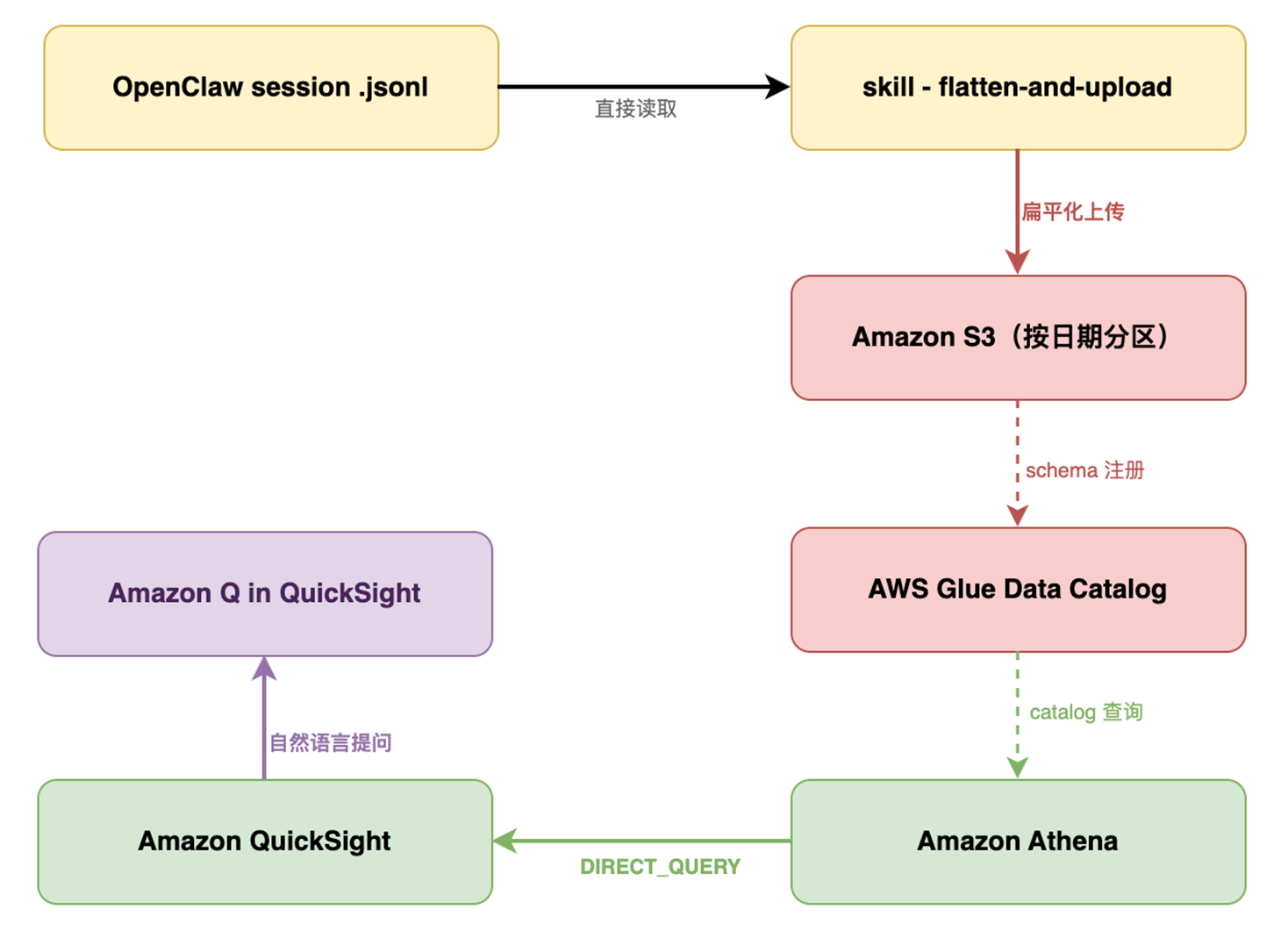
[图 12:S3 + Athena + QuickSight方案流程图] |
如下图所示,您可以在 Dashboard 右上角的 Chat 入口,可以直接用自然语言提问:
“上周费用最高的是哪天?”
“exec 工具调用次数的趋势如何?”
“哪个 skill 花费最多?”
“cache 命中率和费用有相关性吗?”
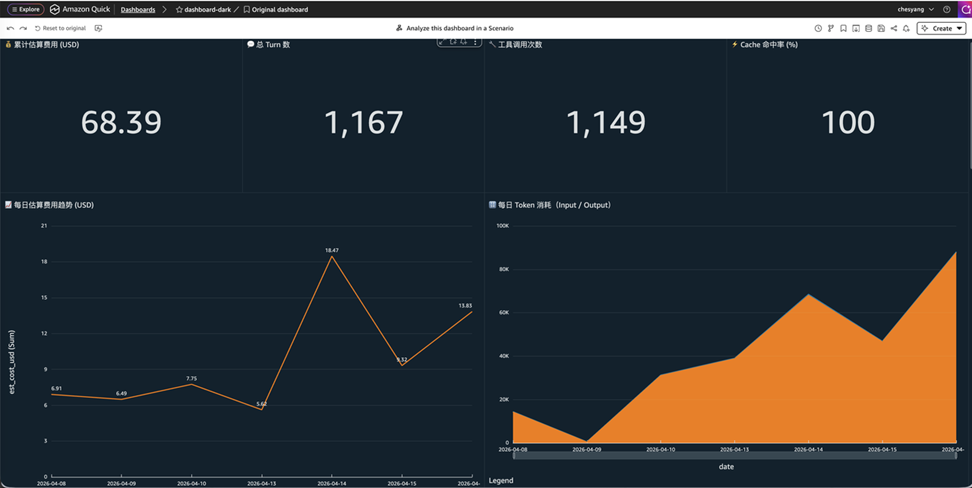 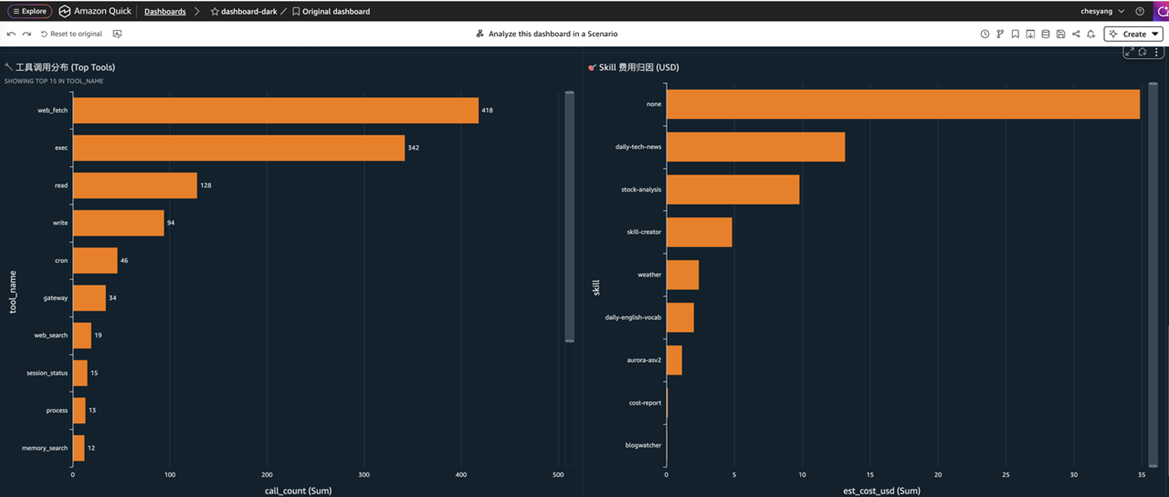 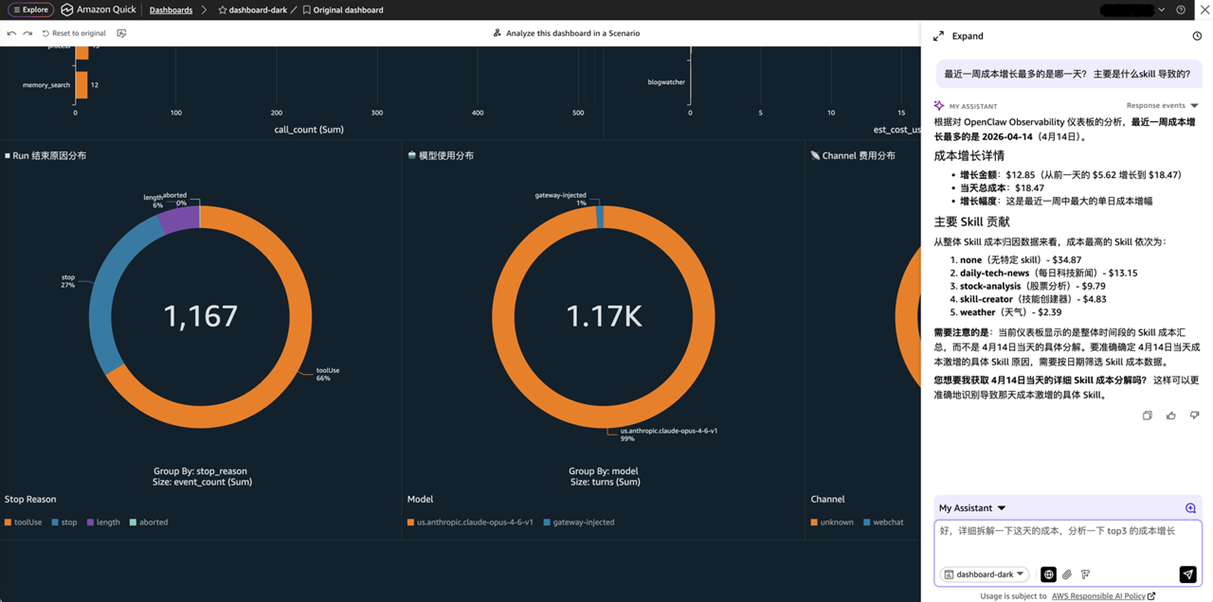
[图 13-15:S3 + Athena + QuickSight方案流程图] |
2.4.2 与纯开源日志分析方案相比的优势
- 纯开源方案:需要自行维护查询引擎、存储、可视化三套组件,且没有自然语言提问能力。
- 亚马逊云科技方案:Athena Serverless 按查询量计费成本极低,QuickSight DIRECT_QUERY 模式 S3 有新文件即可查询,Amazon Q 的自然语言能力是核心差异化。
2.4.3 回答了哪些问题
✅ 花了多少钱:内置价格表估算,含 Bedrock 费用
✅ 钱花在哪里:Skill 归因、工具调用分布、Channel 维度、Run 结束原因
✅ 自定义深挖:Amazon Q 自然语言提问,任意维度即席分析
适用场景:需要自定义深挖数据、不确定该看哪个维度时;出现问题时快速分析现状并给出优化建议。
2.4.4 核心代码示例
- Skill – flatten-and-upload – 扁平化处理并上传 S3
import json, boto3
from pathlib import Path
PRICE = { # USD per 1M tokens(claude-opus-4-6,Bedrock 不返回费用字段,本地估算)
"input": 5.0, "output": 25.0, "cache_write": 6.25, "cache_read": 0.5
}
def flatten_session(jsonl_path):
records = []
for line in Path(jsonl_path).read_text().splitlines():
entry = json.loads(line)
if entry.get("type") != "message" or entry.get("role") != "assistant":
continue
usage = entry.get("usage", {})
inp, out = usage.get("inputTokens", 0), usage.get("outputTokens", 0)
cw, cr = usage.get("cacheWriteTokens", 0), usage.get("cacheReadTokens", 0)
records.append({
"type": "message", "role": "assistant",
"timestamp": entry.get("timestamp", ""),
"date": entry.get("timestamp", "")[:10],
"model": entry.get("model", ""),
"stop_reason": entry.get("stopReason", ""),
"input_tokens": inp, "output_tokens": out,
"cache_write": cw, "cache_read": cr,
"est_cost_usd": round(
inp/1e6*PRICE["input"] + out/1e6*PRICE["output"] +
cw/1e6*PRICE["cache_write"] + cr/1e6*PRICE["cache_read"], 6
),
"tool_names": ",".join(
c["name"] for c in entry.get("content", []) if c.get("type") == "tool_use"
),
})
return records
def upload_to_s3(records, bucket, date):
body = "\n".join(json.dumps(r) for r in records)
boto3.client("s3").put_object(
Bucket=bucket,
Key=f"flat/date={date}/data.jsonl",
Body=body.encode()
)
2. Athena 视图示例 – 每日费用
-- 在 Athena 中创建视图,直接查询 S3 上的扁平化数据
CREATE OR REPLACE VIEW openclaw_db.v_daily_cost AS
SELECT
date,
COUNT(*) AS turns,
SUM(input_tokens) AS input_tokens,
SUM(output_tokens) AS output_tokens,
SUM(cache_write) AS cache_write_tokens,
SUM(cache_read) AS cache_read_tokens,
ROUND(
SUM(input_tokens) / 1e6 * 5.0 +
SUM(output_tokens) / 1e6 * 25.0 +
SUM(cache_write) / 1e6 * 6.25 +
SUM(cache_read) / 1e6 * 0.5
, 4) AS est_cost_usd
FROM openclaw_db.session_flat
WHERE type = 'message' AND role = 'assistant'
GROUP BY date
ORDER BY date;
更换模型时只需修改视图中的四个系数,QuickSight Dashboard 无需任何改动。
三、四种方案全维度对比
| 维度 | OTel + Grafana | ClawProbe + Grafana | 本地日志分析 + HTML 展示 | QuickSight + Amazon Q |
| 告警方式 | Grafana 告警规则 | Grafana 告警规则 | 自定义 Skill 分析并触发告警 | CloudWatch 告警规则 |
| Bedrock 费用 | ❌ 无数据 | ✅ 内置价格表 | ✅ 内置价格表 | ✅ 内置价格表 |
| Skill 级归因 | ❌ | ✅ | ✅ | ✅ |
| Token 明细 | ✅ | ✅ | ✅ | ✅ |
| 自然语言提问 | ❌ | ❌ | ❌ | ✅ Amazon Q |
| 历史趋势 | ✅ 长期存储 | ✅ 长期存储 | 手动对比文件 | ✅ 长期存储 |
| 运维复杂度 | 中 | 高 | 中 | 中 |
| 成本 | AMP + Grafana | AMP + Grafana | 免费 | S3 + Athena + QS |
四、进阶:企业级方案演进路径
当 OpenClaw 从个人工具扩展为团队或企业级部署时,数据量和并发需求上来,可以考虑引入 Amazon Redshift Serverless 替代 Athena:
- Auto-copy:持续监听 S3,有新文件自动加载,数据延迟降至分钟级
- 列存储 + 物化视图:GB 级以上数据的聚合查询快 10-100x,Dashboard 响应从秒级降到毫秒级
- 跨数据源 JOIN:将 OpenClaw 的 token 消耗与业务数据(用户活跃度、任务完成率)关联,评估 AI Agent 的实际 ROI
迁移路径平滑:QuickSight 的 Dashboard 面板、图表布局、Amazon Q 功能完全不需要修改,只需将数据源从 Athena 切换为 Redshift,用户界面没有任何变化。
适用场景:多实例部署、长期运营分析(数据量 GB 级以上)、业务数据关联分析、成本分摊审计。
五、总结
可观测性是解决 Agentic AI Token 爆炸问题的前提——看不见的成本,无法优化。本文围绕三个核心问题(花了多少钱、钱花在哪里、异常如何发现),实测了四种方案,它们不是竞争关系,而是各有侧重、互相补充:
- OTel + Managed Grafana:系统级实时指标监控,适合需要长期存储和团队协作的生产环境
- ClawProbe + Grafana:填补费用盲区,提供逐轮 Token 明细和 Skill 级归因
- 本地日志分析 + HTML :零外部依赖,定制推送到 webchat,有异常时文字解读直接说明原因,个人场景首选
- S3 + Athena + QuickSight:当你不知道该看哪个维度时,用 Amazon Q 自然语言提问直接得到答案,是其他三种方案无法替代的临时深挖能力
四种方案共同构成一个完整的可观测性闭环:本地 HTML 日报展示负责主动发现异常,Dashboard 负责趋势回顾,Amazon Q 负责深挖根因。
亚马逊云科技方案的核心价值不只是”托管省运维”,更在于 Amazon Q in QuickSight 的自然语言提问能力——这是纯开源方案无法复制的差异化功能,让”临时深挖”从写 SQL 变成说人话,让”每一分 Token 消耗都可量化”成为可落地的目标。
本系列文章
- Data for AI:取之有度,用之有节!从Harness视角破解Agent应用Token爆炸难题
- Data for AI:明其所耗,知其所因!让每一分 Token 消耗都可量化的全栈实践
- 存之有序,治之有矩——Agent 记忆系统的工程实践与演进
➡️ 下一步行动:
相关产品:
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon Athena — 使用 SQL 在 S3 中查询数据
- Amazon QuickSight — 高速业务分析服务
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon Redshift — 经济高效的数据仓库
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
