亚马逊AWS官方博客
从IDC到云上GPU:基于 Amazon EKS 的大模型推理混合云弹性部署实践
摘要:基于 Amazon EKS 与 NVIDIA NIM 构建混合云大模型推理架构,实现本地 GPU 优先、云上 Spot 实例弹性兜底,结合 KEDA 和 Karpenter 达成 0→N 自动扩缩容与成本最优。
目录
一、引言:当大模型推理遇到混合云
生成式 AI 正在重塑企业的业务流程,从智能客服到代码辅助生成,从内容创作到实时风控——大模型推理已经从”尝鲜”走向”生产”。然而,当我们与客户深入探讨大模型推理的实际落地时,一个绕不开的问题浮出水面:推理服务到底该部署在哪里?
答案往往不是非此即彼的”全部上云”或”全部本地”,而是一个更复杂的混合态。在过去一年中,我们接触了大量中国客户的真实需求,总结下来有以下几个核心原因让”全面上云”并不现实:
延迟敏感:对于实时推理场景,如制造业产线质检、金融实时风控,每增加几十毫秒的网络往返延迟都可能影响业务效果。本地推理可以将 TTFT(首 Token 延迟)控制在 70ms 以内,这是跨地域云端调用难以企及的。
数据本地化需求:部分企业出于数据安全和内部合规要求,倾向于将敏感业务数据的推理处理保留在本地,减少数据在网络上的传输。
成本考量:GPU 资源昂贵,7×24 小时运行云上 GPU 实例的成本不菲。许多客户的推理流量有明显的波峰波谷特征,峰值时间可能只有每天 8 小时。
已有 GPU 投资:不少企业已经采购了 NVIDIA A100/H100 等 GPU 服务器,这些资源不能浪费。客户希望在利旧本地 GPU 的同时,在流量高峰时能弹性扩展到云上。
从客户的业务侧和 IT 侧视角来看,典型的需求和挑战包括:
业务侧需求:
- GPU 资源受限,现有 N 块 A100 卡,无法及时采购新卡扩容
- 利旧 IDC 现有资源,仅在流量溢出时将推理扩展至云上
- 终端用户无感知,对外接口透明统一
- 在保证服务质量的前提下节约成本
IT 侧挑战:
- 协调本地和云上的资源调度——仅当本地无法支撑时才使用云上 GPU
- 在本地和云端之间实现智能负载均衡,统一对外入口
- 确保本地和云端模型版本一致性和数据同步
- 避免云端资源过度使用导致成本失控,避免跨可用区流量费用
这些需求指向了一个明确的技术方向:混合云弹性推理架构。本文将详细介绍我们如何基于 Amazon EKS、NVIDIA NIM、KEDA 和 Karpenter 构建了一套完整的混合云大模型推理方案,并分享实测数据、成本分析和踩坑经验。
二、方案架构:双集群混合推理
2.1 整体架构设计
我们的方案采用了双集群架构——本地 IDC 的 Kubernetes 集群(集群 B)和 AWS 上的 Amazon EKS 集群(集群 A)协同工作,通过智能路由和自动弹性伸缩实现”本地优先、云上兜底”的推理策略。
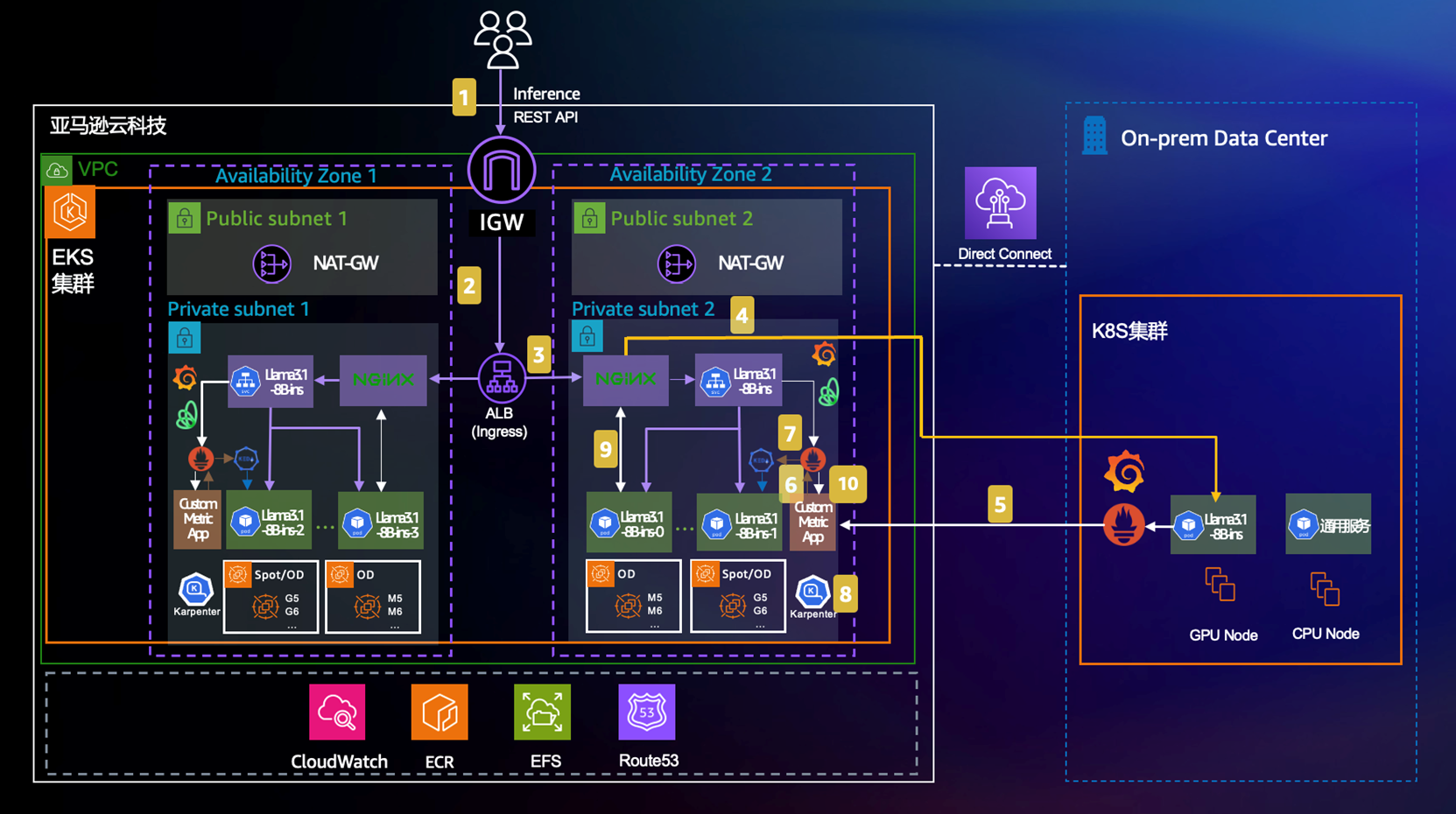
[图 1:混合推理整体架构 — EKS 集群 + 本地数据中心 + ALB 统一入口] |
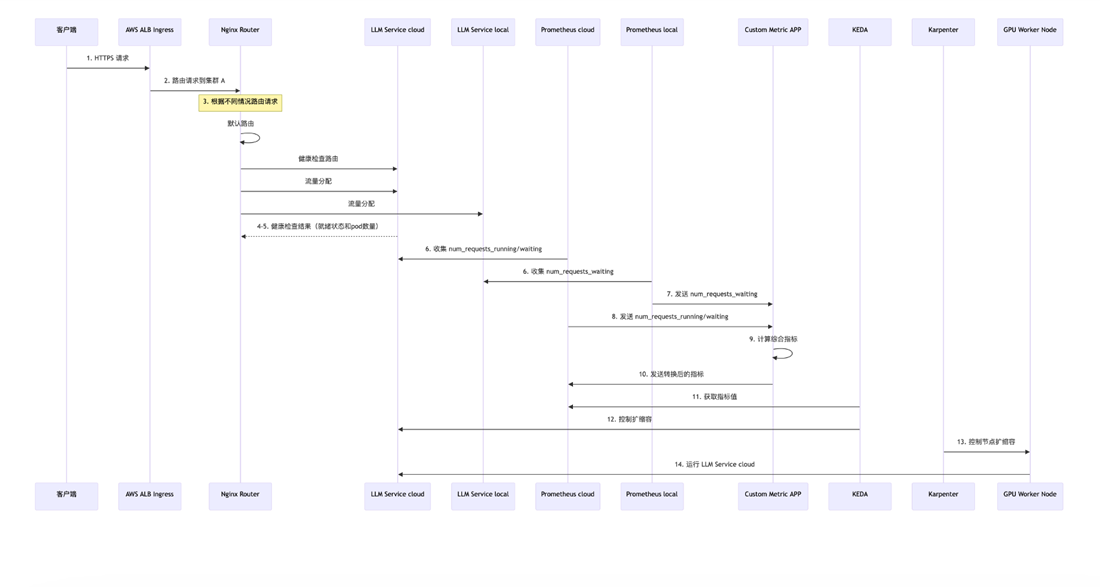
[图 2:请求流转时序图 — 从 HTTPS 请求到云上自动扩容的完整时序] |
整体架构的核心组件和流程如下:
① 统一入口层:
- 客户端通过 HTTPS 请求访问 AWS Application Load Balancer(ALB)作为 Ingress 入口
- 使用 Amazon Route53 做 DNS 解析,域名为 `infer.aaabbbccc.xyz`
- ALB 配置 HTTPS:443 监听器,挂载 SSL 证书,对外提供安全的 REST API 接口
② 智能路由层:
- ALB 将请求路由到 EKS 集群中的 Nginx Router(基于 OpenResty)
- Nginx Router 是整个方案的”交通指挥官”,根据以下逻辑分发流量:
- – 默认路由:优先将请求发往本地推理服务(LLM Service B)
- – 健康检查路由:持续检测本地推理服务的就绪状态
- – 权重切分:根据健康检查结果和负载情况,按权重在本地(Service B)和云上(Service A)之间分配流量
③ 推理服务层:
- 本地集群(On-prem K8s):部署 NVIDIA NIM 推理服务,运行 Llama3.1-8B-instruct 模型
- 云上集群(Amazon EKS):部署相同的 NIM 推理服务,作为弹性扩展的”兜底”资源
- 两端使用完全相同的模型版本和 API 接口,确保推理结果一致
④ 弹性伸缩层:
- Prometheus 分别从本地和云上收集推理指标(`num_requests_running`、`num_requests_waiting`)
- Custom Metric APP 计算综合指标,转换为 KEDA 可消费的 `custom_metric`
- KEDA 根据指标值控制云上推理服务的 Pod 扩缩容(0 到 N)
- Karpenter 负责 GPU 工作节点的自动供给和回收
⑤ 存储与镜像层:
- Amazon ECR 存储 NIM 容器镜像
- Amazon EFS 提供持久化存储
- CloudWatch 提供日志和监控
2.2 网络连接
本地 IDC 与 AWS VPC 之间通过 AWS Direct Connect 或 Site-to-Site VPN 建立私有连接。在实验环境中,我们使用了 VPN 连接来模拟生产场景。
2.3 网络 CIDR 规划
网络 CIDR 规划是整个方案中最容易出错的环节。四套 CIDR 必须互不重叠,且都可路由。以下是我们的规划:
| 网络区域 | CIDR | 说明 |
| 本地节点网络 | `192.168.0.0/21` | On-prem K8s 节点 |
| 本地 Pod 网络 | `100.99.0.0/16` | On-prem Pod CIDR |
| 本地 Service 网络 | `10.100.0.0/16` | On-prem Service CIDR |
| AWS VPC 网络 | `10.1.0.0/21` | EKS 集群 VPC |
| AWS Pod 网络 | `100.64.0.0/16` | EKS Pod CIDR |
| AWS Service 网络 | `172.20.0.0/16` | EKS Service CIDR |
最佳实践:在创建 EKS 集群之前,先完成 CIDR 规划并验证双向网络连通性。”先通再建”是铁律,事后改 CIDR 代价极大。
2.4 EKS 集群配置
云上 EKS 集群使用了 2 个 m5.xlarge 节点作为基础控制节点(运行 Nginx Router、Prometheus、KEDA 等组件),GPU 工作节点由 Karpenter 按需动态创建和销毁。
三、为什么选择 NVIDIA NIM
在大模型推理引擎的选择上,我们对比了两个主流方案:NVIDIA NIM 和 RayServe + vLLM。最终选择了 NIM,原因来自实测数据。
3.1 NIM 的核心优势
NVIDIA NIM(NVIDIA Inference Microservices)是 NVIDIA 推出的企业级推理微服务框架,具有以下特点:
- 预优化的推理引擎:针对不同 GPU 架构(A100/H100/L40S/A10G)预编译 TensorRT-LLM 引擎,开箱即用
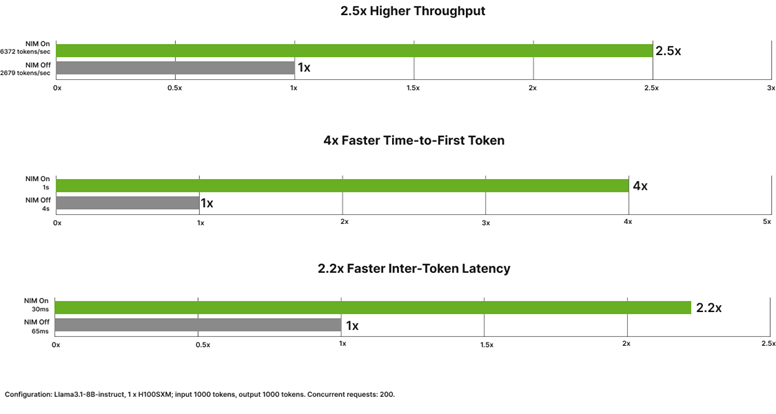
[图 3:NIM 性能基准 — 2.5x 吞吐量提升、4x TTFT 加速、2.2x ITL 优化(H100 SXM, Llama3.1-8B)] |
- 标准 OpenAI 兼容 API:提供 `/v1/completions`、`/v1/chat/completions` 等标准接口,应用层无需改动
- 企业级安全与支持:经过安全审计,提供 API 稳定性保证和安全补丁
- 优化的吞吐量和延迟:通过 Continuous Batching、PagedAttention 等技术最大化Token生成和响应能力
NVIDIA 官方在 H100 SXM 上的评测数据(Llama3.1-8B-instruct,输入 1000 tokens,输出 1000 tokens,并发 200)显示,NIM 相比原始推理框架有显著的性能提升。
3.2 NIM vs RayServe + vLLM:实测对比
我们在相同的 EKS 环境中进行了对比测试,结果令人印象深刻:
启动时间对比:
| 场景 | NIM on EKS | RayServe + vLLM on EKS |
| 无实例预热(冷启动) | 5-6 分钟 | 12-15 分钟 |
| 有实例预热(热启动) | 2-3 分钟 | 8-11 分钟 |
资源消耗对比:
| 方案 | GPU 实例 | 额外资源 |
| NIM on EKS | 1× g5.2xlarge | 无额外开销 |
| RayServe + vLLM on EKS | 1× g5.8xlarge (worker: 10 CPU + 60GB Mem) | 1× m5.xlarge (head: 2 CPU + 12GB Mem) |
关键结论:NIM 在单台 g5.2xlarge 实例上的性能效率(包括 RPS、Latency、Throughput 等)均优于 RayServe + vLLM 在 g5.8xlarge + m5.xlarge 双实例组合上的表现。
换言之,NIM 用更少的资源达到了更好的性能,冷启动时间快了 2-3 倍,这对于弹性伸缩场景至关重要——启动越快,用户等待时间越短,成本浪费越少。
3.3 为什么冷启动时间如此关键?
在”0→N”弹性伸缩场景中,冷启动时间直接决定了用户体验的”空窗期”。考虑以下时间线:
使用 NIM 的情况下,从触发到可用大约 5-6 分钟(冷启动)或 2-3 分钟(热启动)。而 RayServe + vLLM 需要 12-15 分钟(冷启动)或 8-11 分钟(热启动)。在这段时间内,所有溢出的请求只能排队等待。5 分钟和 15 分钟的差距,对于用户体验来说可能是”可以接受”和”完全不可用”的区别。
此外,NIM 只需要一台 g5.2xlarge 即可提供完整的推理服务,而 RayServe + vLLM 需要一台 g5.8xlarge(GPU Worker)加一台 m5.xlarge(Head 节点)的组合。在 Spot 实例场景下,需要的实例类型越多,被中断的风险越大,成本也越高。这使得 NIM 在弹性伸缩场景中的优势更加明显。
四、弹性伸缩:KEDA + Karpenter 联动
弹性伸缩是本方案的精华所在。我们实现了”本地优先、云上兜底、用完即还”的策略——平时流量由本地 GPU 承接,当本地推理服务饱和时,自动在云上拉起 GPU 实例和推理 Pod;流量回落后,自动缩容到零,实现零成本待机。
4.1 核心逻辑
整个弹性伸缩链路由三个组件协同工作:
缩容则是反向流程:
4.2 自定义指标计算
这里的关键创新是自定义综合指标(custom_metric)的设计。我们不是简单地看某一个推理服务的指标,而是综合考虑本地和云上的负载状况:
- Prometheus A(云上)收集云上推理服务的 `num_requests_running` 和 `num_requests_waiting`(2
分钟滑动平均值) - Prometheus B(本地)收集本地推理服务的 `num_requests_waiting`(2
分钟滑动平均值) - Custom Metric APP 综合计算:当本地的 `num_requests_waiting` 超过阈值,说明本地已饱和,需要云上资源介入
这个综合指标被转换为一个 0/1 信号:
- `custom_metric = 0`:本地有余量,无需云上资源
- `custom_metric = 1`:本地饱和,触发云上扩容
以下是 Custom Metric APP 的核心代码:
核心逻辑解读:
- 扩容触发(返回 1):当本地 num_requests_waiting 超过 20,说明本地推理服务已经排队积压,需要云上资源分担;或者云上已经有超过 10 个并发请求在处理,说明流量确实很大
- 缩容触发(返回 0):当云上 num_requests_running 低于 5,说明流量已经回落,可以安全释放云上资源
- 维持现状(返回 0.5):介于两者之间的灰色地带,避免频繁扩缩容抖动
- 容错处理:当任一 Prometheus 查询失败时,默认返回 0.5(维持现状),避免因监控中断导致误判
这个应用以 Prometheus Exporter 的形式运行在云上 EKS 集群中,每 30 秒更新一次指标值,KEDA 每 15 秒轮询该指标进行扩缩容决策。
4.3 KEDA 配置详解
KEDA(Kubernetes Event-Driven Autoscaling)是我们用来驱动 Pod 级弹性伸缩的核心组件。以下是 ScaledObject 的关键配置:
几个关键设计决策:
- `minReplicaCount: 0`:这是实现零成本待机的关键。当没有流量溢出时,云上不运行任何推理 Pod
- `threshold: 0.25`:略低于 1,确保指标从 0 跳变到 1 时能可靠触发
- `pollingInterval: 15`:15 秒的检测间隔在响应速度和 API 调用频率间取得平衡
4.4 Karpenter 节点自动供给
当 KEDA 创建了新的推理 Pod,但集群中没有可用的 GPU 节点时,Karpenter 自动介入:
Karpenter 的配置针对 GPU 推理场景做了优化:
- 实例类型:`g5.2xlarge`(1× NVIDIA A10G GPU,24GB 显存)
- 购买策略:优先使用 Spot 实例,大幅降低成本
- Spot 中断处理:集成 SQS + EventBridge,接收 Spot Instance Interruption Warning 和 EC2 Instance Rebalance Recommendation 信号,实现优雅迁移
4.5 扩容实战:从 0 到 1 的完整链路
以下是我们实测记录的一次完整扩容过程(来自 KEDA 和 Karpenter 日志):
Step 1 – KEDA 触发扩容:
当 custom_metric 从 0 跳变到 1(本地推理饱和),KEDA 立即将 StatefulSet 副本从 0 扩到 1。
Step 2 – Karpenter 发现 Pending Pod:
新创建的 Pod 因为没有可用 GPU 节点而处于 Pending 状态,Karpenter 自动发起节点创建。
Step 3 – 启动 Spot 实例:
Spot 实例启动并加入 Kubernetes 集群。
Step 4 – Pod 调度与启动:
Step 5 – NIM 就绪,开始接流:
NIM 容器加载 Llama3-8B-instruct 模型,就绪后 Nginx Router 将部分流量切到云上实例。
4.6 缩容实战:优雅释放资源
当流量回落,缩容过程同样自动化:
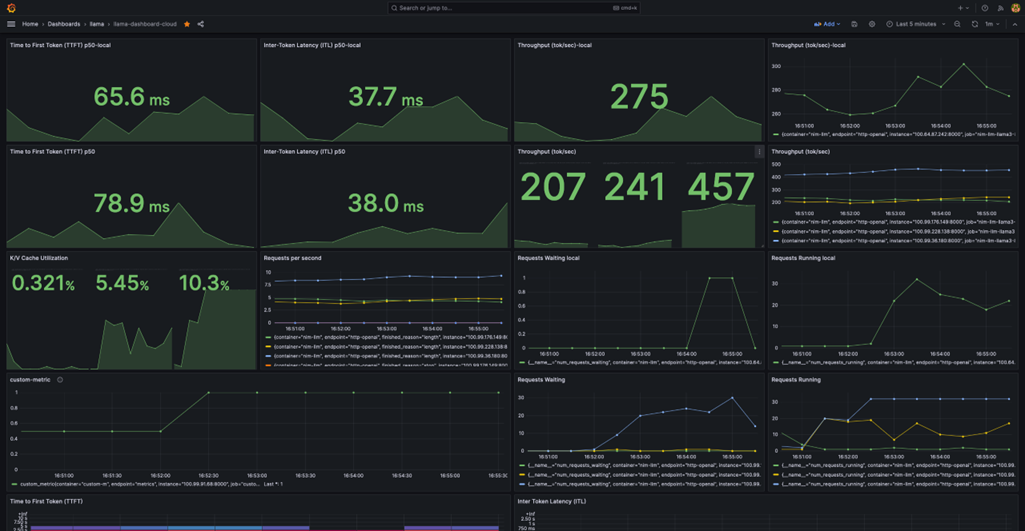
[图 4:Grafana 云上推理仪表板 — custom_metric 扩容触发与多实例负载] |
Karpenter 的 emptiness 策略会检测节点上没有任何工作负载后,自动终止实例并注销节点,真正实现”用完即还”。
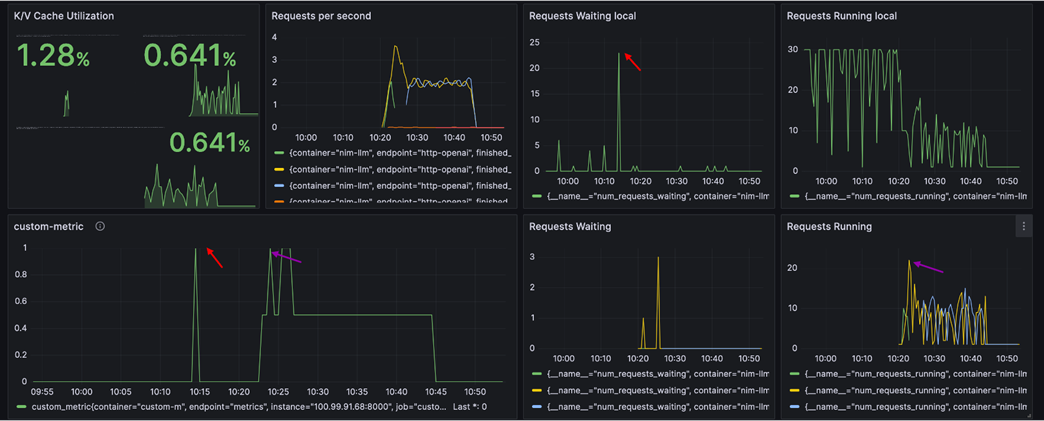
[图 5:Grafana 统一监控仪表板 — 从本地饱和到云上接管的完整扩容时间线(箭头标注关键联动节点)] |
这张 Grafana 仪表板完整记录了一次从「本地饱和」到「云上接管」的弹性扩容全过程。六个面板的箭头标注了关键时间节点的联动关系:
1. ~10:15 Requests Waiting Local 飙升至 ~20,custom_metric 同步从 0 跳变到 1(右上红色箭头 + 左下红色箭头):本地 num_requests_waiting 达到阈值 20,Custom Metric APP 立即判定为「本地饱和」,将 custom_metric 置为 1,KEDA 随即触发扩容。
2. ~10:23 云上 Requests Running 从 0 跃升至 ~20(右下紫色箭头):Karpenter 供给的 g5.2xlarge Spot 实例就绪,NIM Pod 启动完成,开始承接溢出流量。多条曲线代表多个推理实例并行处理。
3. ~10:23 云上 Requests Waiting 出现短暂峰值后快速回落(中下):云上实例刚上线时有短暂排队,随着 Pod 完全就绪,等待队列迅速清空。
4. ~10:15-10:23 Requests per second 出现明显下降(左上):这正是扩容空窗期的直观体现——本地已饱和但云上尚未就绪,整体吞吐量暂时下降。
5. ~10:30 之后全面回稳:流量被本地 + 云上共同消化,KV Cache 利用率从 1.28% 降至 0.641%(左上),说明负载已分散。本地 Requests Running 恢复平稳(右上),云上持续处理溢出请求。
整个扩容链路从 custom_metric 触发(~10:15)到云上实例开始接流(~10:23),耗时约 8分钟(含 Karpenter 启动 Spot 实例 + NIM 加载模型)。其中约 5-10 分钟的空窗期内整体吞吐量有所下降,这也印证了前文对冷启动时间影响的分析。
4.7 突破 KEDA 限制:不同指标驱动扩容与缩容
在实践中我们发现 KEDA 有一个设计限制:它默认使用同一个指标同时驱动扩容和缩容。但在我们的场景中,理想的策略是:
- 扩容:当本地 `num_requests_waiting` 超过阈值时触发(本地饱和了,需要云上帮忙)
- 缩容:当云上 `num_requests_running` 降到较低水平(如低于 5)时触发
我们通过 Custom Metric APP 将这两种指标合并为一个综合的 custom_metric,用不同的计算逻辑分别控制上升沿(扩容)和下降沿(缩容),从而突破了 KEDA 的这一限制。
五、性能实测
5.1 测试环境
本次实验使用 Amazon EC2 g5.2xlarge 实例,配备单块 NVIDIA A10G GPU(24GB 显存)。A10G 是 NVIDIA Ampere 架构的推理优化 GPU,在性价比和推理性能之间取得了良好平衡,是目前 AWS 上最具性价比的 GPU 推理实例之一。基于 A10G 的 24GB 显存限制,我们选择了 Llama3-8B-instruct 作为本次 Demo 的测试模型——8B 参数量的模型在 FP16 精度下约占用 16GB 显存,可以完整加载到单块 A10G 上并留有足够的 KV Cache 空间。在实际生产环境中,客户可根据 GPU 型号选择更大的模型:例如 A100 80GB 可运行 70B 模型,H100 可进一步提升吞吐量。NIM 的优势在于针对不同 GPU 架构(A10G/A100/H100/L40S)均提供了预优化的 TensorRT-LLM 引擎,切换 GPU 和模型时无需手动调参。
| 项目 | 配置 |
| GPU 实例 | Amazon EC2 g5.2xlarge(1× NVIDIA A10G,24GB 显存) |
| 模型 | Meta Llama3-8B-instruct |
| 推理引擎 | NVIDIA NIM 1.1.2 |
| 测试工具 | GenAI Perf Analyzer |
| 测试端点 | `v1/completions` via `inference endpoint` |
| 并发度 | 32(单实例测试)/ 120(压力测试) |
| 输入/输出 | 100 tokens / 100 tokens(单实例测试) |
5.2 单实例性能基线
在单台 g5.2xlarge 上运行 NIM 的 Llama3-8B-instruct 模型,使用 GenAI Perf Analyzer 进行基准测试(并发 32,输入/输出各 100 tokens),获得了稳定的性能基线数据。

[图 6:Grafana 性能仪表板 — TTFT 215ms、ITL 37.6ms、吞吐量 530 tok/s] |

[图 7:EKS 集群资源概览 — GPU 利用率 46%、GPU 显存 97.9%] |
5.3 压力测试
使用 GenAI Perf Analyzer 以 120 并发对推理端点进行压力测试,多轮测试记录了 Request Latency、Output/Input Sequence Length 和 Throughput 等关键指标。
通过 kubectl get pods 和 kubectl get svc 可以观察到 NIM pods 和 nginx-router 的运行状态:
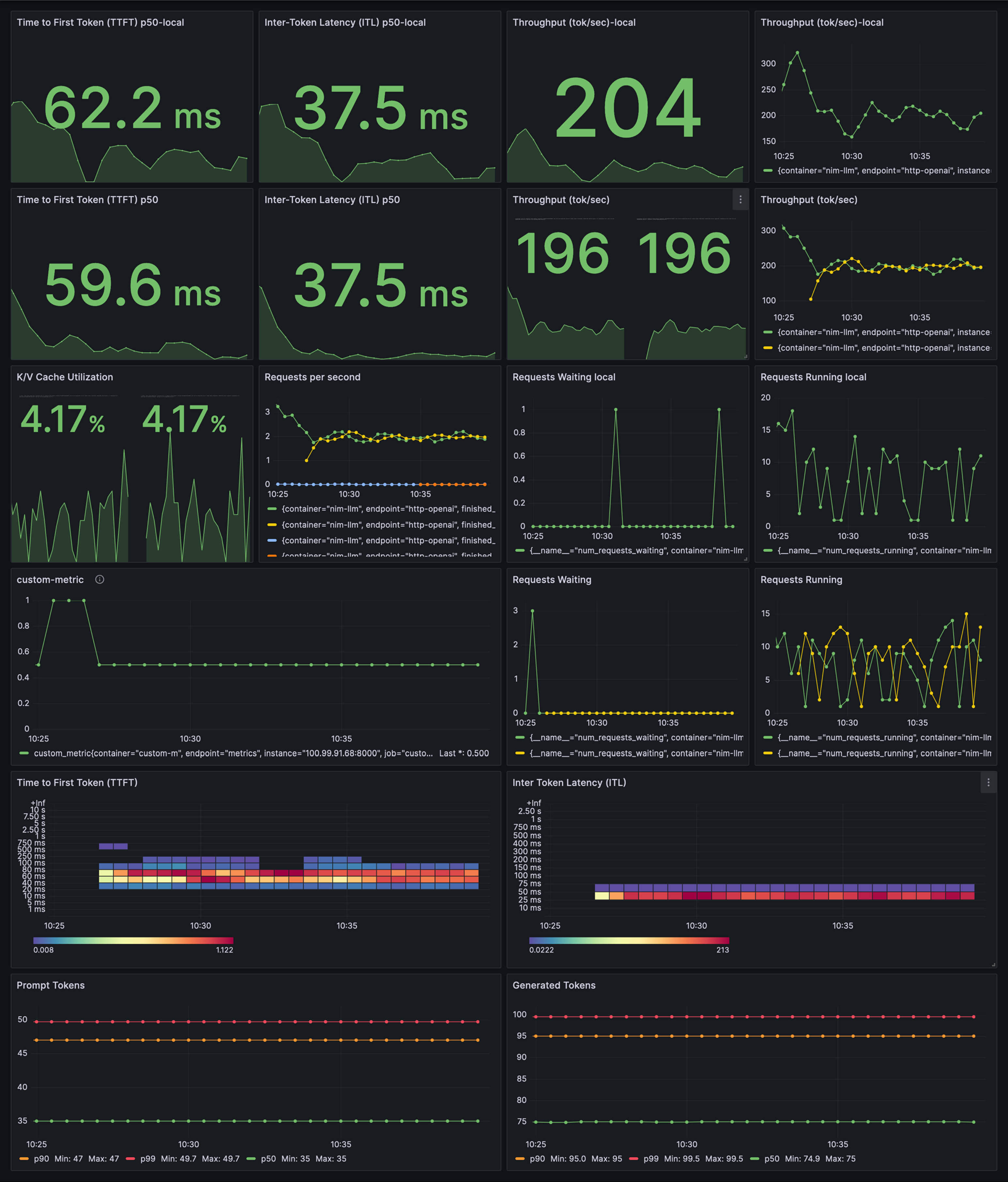
[图 8:压力测试 Grafana 仪表板 — TTFT 3.53s、ITL 37.9ms、吞吐量 193/202 tok/s、32 Requests Running] |
六、成本优化
成本优化是本方案的另一大亮点。通过多层次的成本优化策略,我们将混合推理的云上成本控制在了一个非常有竞争力的水平。
6.1 Spot 实例:节省 67% GPU 成本
GPU 实例是推理成本的大头。我们通过 Karpenter 优先使用 Spot 实例,实现了显著的成本节约:
| 项目 | 价格 | 说明 |
| g5.2xlarge On-Demand | ~$1.212/hr | 按需定价 |
| g5.2xlarge Spot | $0.403/hr | **比 On-Demand 便宜 67%** |
*注:Spot 价格为 撰写时在 US East (N. Virginia) 区域的实际定价。Spot 实例价格会随供需情况浮动,所有价格仅供参考,不构成亚马逊云科技的任何承诺或报价。*
6.2 0→N 弹性:不用时零成本
这是最核心的成本优化策略。通过 KEDA 的 minReplicaCount: 0 配置:
- 无流量溢出时:云上 0 个推理 Pod,0 个 GPU 节点,零 GPU 成本
- 流量溢出时:自动扩容到 1-3 个 GPU 节点,按需付费
- 流量回落后:自动缩回 0,停止计费
假设每天仅 8 小时需要云上 GPU 资源,相比 7×24 小时运行,成本直接降低 67%。再叠加 Spot 的 67% 折扣,综合成本仅为 On-Demand 全天候运行的约 11%。
6.3 跨 AZ 流量优化
在 AWS 中,跨可用区(AZ)的数据传输会产生额外费用($0.01/GB 双向)。对于高吞吐的推理服务,这笔费用不容忽视。我们通过多种策略优化了跨 AZ 流量:
Pod 到 Pod 通信优化:
- Pod Topology Spread Constraints:确保 Pod 均匀分布在各 AZ
- Topology Aware Routing:让流量优先路由到同 AZ 的推理服务
- `internalTrafficPolicy: Cluster`:集群内流量策略
LoadBalancer 到 Pod 通信优化:
- Target-Type IP 模式:ALB 直接路由到 Pod IP,减少一跳
- `externalTrafficPolicy: Local`:外部流量保持在本地节点
- Affinity 和 Anti-Affinity 规则:精细控制 Pod 调度
实测数据验证了优化效果——同 AZ 的 Nginx 副本将流量 100% 分发给同 AZ 的推理节点,跨 AZ 流量降为零。
6.4 成本概算
以下是基于实测数据的月度成本概算:
| 组件 | 规格 | 单价 (USD) | 月度成本 (USD) | 百万 Tokens 成本(USD) |
| g5.2xlarge Spot | 670 tok/s | $0.403/hr | $96.72* | $0.167 |
| m5.xlarge (控制节点) | On-Demand | $0.192/hr | $88.33 | – |
| Amazon EKS 集群 | 托管费 | – | $73.00 | – |
*假设每台 g5.2xlarge 每天运行 8 小时,30 天。具体实例类型按生产环境要求选型后需重新估算。
七、统一监控
在混合云架构中,统一监控是保障服务质量的关键。我们基于 Prometheus + Grafana 构建了跨本地和云上的统一监控体系。
7.1 监控架构
两套 Prometheus 分别采集本地和云上的推理指标,汇聚到统一的 Grafana Dashboard 中,运维团队可以在一个界面上同时看到所有推理实例的实时状态。
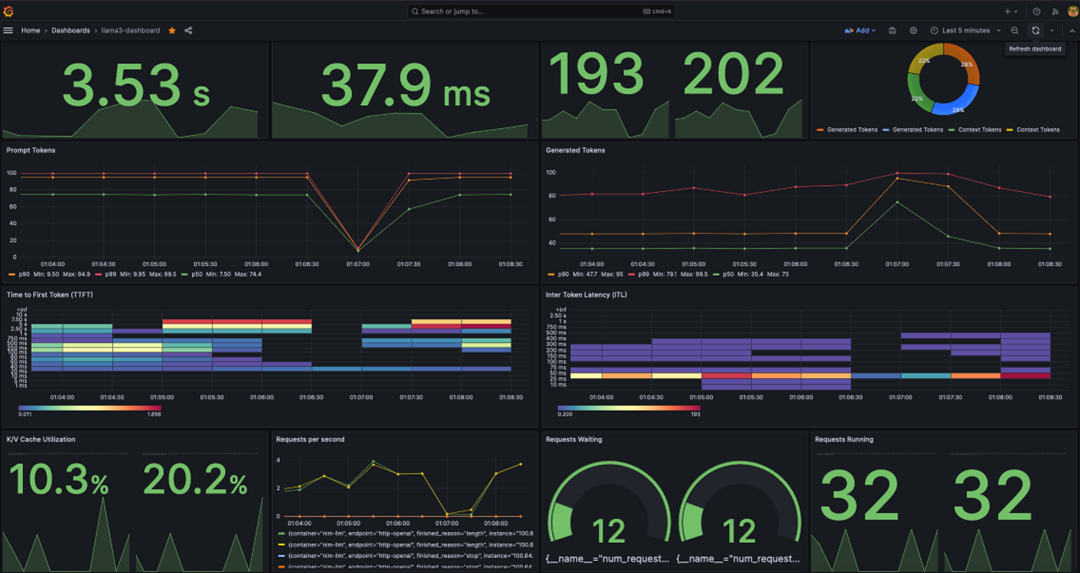
[图 9:Pods 监控概览 — 68 容器运行中,Pod GPU 显存使用 97.9%] |
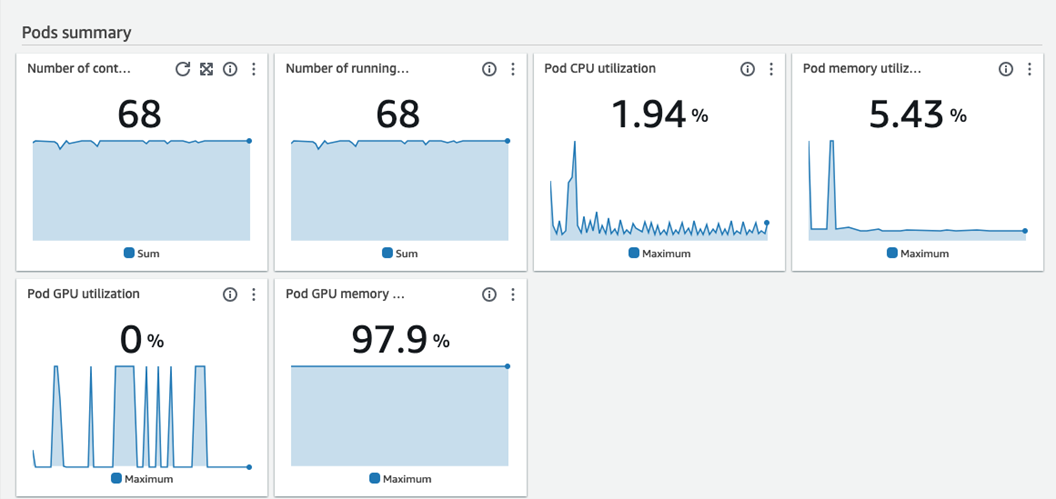
[图 10:集群节点监控 — CPU 11.1%、内存 22.7%、GPU 46%,资源使用健康] |
7.2 关键监控指标
我们的 Grafana 仪表板包含以下关键指标:
| 指标 | 含义 | 监控价值 |
| **TTFT** (Time to First Token) | 从请求到达到返回第一个 Token 的延迟 | 反映推理服务响应速度 |
| **ITL** (Inter-Token Latency) | 相邻 Token 之间的生成延迟 | 反映 GPU 计算效率 |
| **Throughput** (tok/s) | 每秒生成的 Token 数 | 反映推理服务的整体吞吐能力 |
| **Requests Running** | 当前正在处理的请求数 | 反映实时负载 |
| **Requests Waiting** | 排队等待处理的请求数 | 这是触发扩容的关键指标 |
| **KV Cache Usage** | KV Cache 显存占用比例 | 反映显存压力,过高可能导致 OOM |
| **custom_metric** | 综合指标(0 或 1) | KEDA 扩缩容的直接驱动指标 |
7.3 监控面板实际效果
从实际的 Grafana 仪表板中,我们可以清晰地观察到:
1. 稳态运行:本地推理服务保持 TTFT 66.7ms、ITL 37.8ms、276 tok/s 的稳定表现,KV Cache 使用率仅 0.321%,说明单实例远未到性能瓶颈
2. 扩容触发:当 custom_metric 从 0 跳变到 1 时,云上实例开始启动,Requests Running 从 0 上升
3. 多实例负载均衡:云上多个实例运行时,可以看到吞吐量在 207/241/457 tok/s 之间波动,反映了负载在多实例间的分配
7.4 告警策略建议
基于实际运维经验,我们推荐配置以下告警规则:
| 告警名称 | 条件 | 严重级别 | 说明 |
| 推理服务不可用 | Requests Running = 0 且 Requests Waiting > 0 持续 2 分钟 | Critical | 推理服务可能已挂,需要立即介入 |
| KV Cache 即将满 | KV Cache Usage > 80% | Warning | 显存压力过大,可能导致 OOM |
| TTFT 异常升高 | TTFT > 200ms 持续 5 分钟 | Warning | 可能是 GPU 负载过高或网络问题 |
| 扩容失败 | custom_metric = 1 但 Pod 数量未增加持续 5 分钟 | Critical | KEDA 或 Karpenter 可能存在问题 |
| Spot 中断预警 | 收到 Spot Interruption Warning | Info | 提前准备迁移,Karpenter 会自动处理 |
此外,我们还推荐使用 KubeCost 进行成本监控,实时追踪各 Namespace、Deployment 的 GPU 使用成本。
八、中国客户场景分析
基于与中国客户的实际合作经验,我们认为这套混合推理方案在以下场景中具有独特价值。
8.1 制造业边缘 AI
中国制造业正在大规模采用 AI 质检、预测性维护等场景。这些工作负载的特点:
- 数据量大:高分辨率图像/视频流,传输到云端成本高
- 实时性要求高:产线速度决定推理窗口,每件产品只有几百毫秒
- 工厂网络环境复杂:到云的连接可能不稳定
本方案让工厂已有的 GPU 服务器承担日常推理任务,在产能高峰或模型升级测试时弹性扩展到云上,实现统一编排、统一监控、统一升级,避免每个工厂单独维护一套 Kubernetes 集群。
8.2 已有 GPU 投资复用
许多中国企业已经采购了 NVIDIA A100/H100/A10G 等 GPU 服务器,但目前以裸机或 Docker Compose 方式运行,面临以下问题:
- 缺乏弹性伸缩能力,忙时 GPU 利用率 100%,闲时大量浪费
- 缺乏统一的编排和监控手段
- 模型版本管理混乱,更新困难
通过将本地 GPU 服务器纳入 Kubernetes 管理(本方案中通过独立的 On-prem K8s 集群),配合 EKS 云上集群和智能路由,这些”沉没投资”立即获得了:
- 弹性能力:流量溢出时自动扩展到云上
- 统一管理:通过 Kubernetes 标准化部署、监控、升级流程
- 成本优化:本地处理基线流量,云上只为峰值付费
8.3 网络考量
对于中国客户,网络连接的选择需要考虑:
- 使用 AWS 中国区域(北京/宁夏):通过 Direct Connect 或 VPN 即可,网络延迟可控
- 使用海外 Region:需考虑跨境网络延迟。不过由于推理数据留在本地,跨境的只是 Kubernetes 控制面流量和监控数据,带宽需求不大
- Direct Connect vs VPN:生产环境推荐 Direct Connect,提供更稳定的带宽和更低的延迟;PoC 阶段可以先用 VPN 验证
九、最佳实践与踩坑总结
以下是我们在方案实施过程中积累的经验教训,希望能帮助读者少走弯路。
9.1 网络配置(最容易出错)
✅ CIDR 规划先行:
四套 CIDR(本地节点、本地 Pod、AWS VPC、AWS Service)不重叠是硬性要求。建议在创建任何集群之前,先完成网络规划并画出网络拓扑图。
✅ 先通再建:
先确认 VPN/Direct Connect 双向通、防火墙规则开放,然后再建集群。我们曾经遇到先建集群后配网络,导致需要重建集群的情况——这个教训非常痛。
✅ DNS 统一:
混合模式下本地 Pod 需要能解析云上的服务名,确保 CoreDNS 配置正确。
9.2 GPU 节点管理
✅ 必加 Taint:
这防止了 CoreDNS、Prometheus 等非 GPU 工作负载被调度到昂贵的 GPU 节点上。
✅ NVIDIA GPU Operator 一站式安装:
生产环境推荐使用 NVIDIA GPU Operator 通过 Helm 一站式安装 GPU 驱动、Container Toolkit、Device Plugin 和 DCGM Exporter,统一管理 GPU 驱动的生命周期。
✅ Device Plugin DaemonSet 限制:
如果 EKS 集群中同时有 Auto Mode 节点和自管节点,Device Plugin DaemonSet 必须通过 nodeSelector 限制只在非 Auto Mode 节点运行,否则会与 Auto Mode 自带的 GPU 支持冲突。
9.3 NIM 镜像缓存
NIM 的容器镜像非常大(10-30GB),第一次拉取耗时长。这在弹性伸缩场景中尤其关键——镜像拉取时间直接影响扩容速度。常见的优化方案:
9.4 自动缩放精细控制
✅ 根据实测和历史流量数据调优:
- 配置 KEDA 和 Karpenter 的参数(阈值、冷却期、polling interval)需要基于实际流量模式
- 避免资源抖动(频繁扩缩容导致的 Pod 反复启停)
- 在成本和性能之间找到平衡点
✅ 资源预热建议:
在推理流量高峰到达前,建议提前预热实例,缩短云上推理服务的冷启动时间。可以通过 KEDA 的定时触发器(Cron Trigger)实现。
✅ 综合指标持续优化:
优化综合指标(custom_metric)的转换条件和阈值以适应实际业务情况,定期回顾扩缩容日志,持续调优。
✅ 多 AZ 部署策略权衡:
需要在负载均衡效果和减少跨 AZ 流量成本之间做权衡。监控跨 AZ 流量使用情况,根据数据决策是否启用严格的 Topology Aware Routing。
十、结语
本文完整呈现了一套基于 Amazon EKS、NVIDIA NIM、KEDA 和 Karpenter 的混合云大模型推理方案。从架构设计到弹性伸缩,从性能实测到成本优化,每一个环节都经过了真实环境的验证。
这套方案的核心价值可以用一句话概括:让本地 GPU 处理日常负载,让云上 GPU 承接峰值溢出,用完即还。既保护了企业已有的 GPU 投资,又获得了云的弹性和规模优势。
当然,没有银弹。混合云架构带来了额外的网络复杂度、运维成本和调试难度。本文第九章的踩坑总结正是希望帮助后来者少走弯路。如果你的团队也在面对「本地 GPU 不够用,但全面上云成本又太高」的困境,希望这篇文章能提供一条可落地的技术路径。欢迎交流探讨。
➡️ 下一步行动:
相关产品:
- Amazon EKS — 托管式 Kubernetes 服务
- Amazon EFS — 弹性文件存储
- Amazon VPC — 隔离云网络
- Amazon Connect — AI 客户体验解决方案
- Amazon EC2 — 安全且可调整大小的计算容量
相关文章:
- 增强Amazon EKS 节点自愈方案:基于 NPD 的故障持久化与安全修复探索
- 基于 Amazon EKS 和 Graviton 构建多租户 AI Agent 平台:OpenClaw on Kubernetes 实践
- 在Amazon EKS上部署OpenClaw AI Agent:基于Kata Containers的企业级沙箱实践
- 宣布推出适用于工作负载编排和云资源管理的 Amazon EKS Capabilities
- 为AI Agent构建安全沙箱基础架构:在Amazon EKS上部署Kata Containers的最佳实践
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
