亚马逊AWS官方博客
在 Amazon EC2 GPU 实例上部署 NVIDIA NemoClaw — 以 Amazon Bedrock 作为推理后端的生产级参考架构
摘要:本文将通过一次完整的部署实践,演示如何在 Amazon EC2 GPU 实例上跑通 NVIDIA NemoClaw,并在此基础上引入 NVIDIA 官方刚开源的 LLM Router Blueprint 做请求级别的智能路由。
1. 引言
部署一个企业级 AI agent,”调用一次大模型 API”只是起点。当你的 agent 同时要服务客户产品咨询、为员工生成代码、为运维总结日志、为高管提炼洞察时,请求的复杂度天差地别,但它们往往被送往同一个 inference 后端——这意味着简单查询占用了与复杂推理同等的计费单位,整体推理成本与用户体验都有优化空间。如何让”合适的模型”在”合适的场景”被调用,是企业 agent 落地中一个值得关注的优化方向。本文将选用 NVIDIA Nemotron 系列模型作为推理后端——Nemotron 是 NVIDIA 专为 agent 工作负载训练的开源模型家族,针对推理(reasoning)、工具调用(tool calling)、长上下文处理做过专项优化,且同时支持本地部署与 Amazon Bedrock 上的托管推理,为我们演示混合架构提供了一致的模型基础。
亚马逊云科技提供了一整套生成式 AI 基础设施栈来直接面对这个问题。底层的 Amazon EC2 GPU 实例系列(搭载 NVIDIA A10G、L4、L40S、H100、H200 多代加速卡)让你能在自有 VPC 内自托管小型与中型模型,单位 token 边际成本极低;上层的 Amazon Bedrock 通过其 OpenAI 兼容 endpoint 直接以托管方式提供 NVIDIA Nemotron、Anthropic Claude、Amazon Nova、Moonshot Kimi 等头部模型,按 token 计费,无需自管 GPU 容量;中间通过 AWS Systems Manager Session Manager、AWS IAM、Amazon CloudWatch 一系列原生治理工具把”自托管”与”全托管”两条路径无缝缝合。客户可以根据请求复杂度、QPS、延迟预算自由组合两种模式。
> 关于 GPU 实例可用性:NVIDIA H100 / H200 等高端加速卡在部分区域属限售产品,下单前请与亚马逊云科技团队确认目标区域配额与采购流程。本文示例使用的 g6e.xlarge(L40S)在主要商业区域均可正常使用。
NVIDIA 在 GTC 2026 发布的 NemoClaw 是一个开源参考栈,通过一组开发者友好的 CLI 与声明式 blueprint,把”如何把 OpenClaw agent 安全地跑起来”这件复杂的工程化问题,简化为可重复执行的命令。它在 OpenClaw(NVIDIA 的开源 agent 框架)之上,提供了三个企业落地的关键能力。第一是 OpenShell 沙箱:每个 agent 实例运行在一个被 Linux 内核三层机制(Landlock 文件系统访问控制 + seccomp 系统调用过滤 + 网络命名空间)隔离的容器里,agent 即使被 prompt injection 劫持,也无法越界读取 host 文件、执行任意系统调用、或访问未授权的网络端点。第二是 Policy-as-Code 的 declarative 网络策略:以 host + path + method 粒度的 YAML 文件描述 sandbox 出网白名单(例如”允许 GET huggingface.co/api/, 拒绝其他一切”),与 Amazon VPC Security Group(IP/端口粒度)形成 L4/L7 互补防御。NemoClaw 内置 12+ 个常用服务(GitHub、Slack、Notion、Stripe 等)的 preset policy,开箱即用。第三是 可插拔的 inference 路由层:agent 代码内部统一调用 https://inference.local/v1,由 OpenShell gateway 在 host 侧做透明 routing,可指向本地 NIM 容器、本地 vLLM、NVIDIA Build 云端、或任意 OpenAI 兼容 endpoint——agent 代码无需修改即可在不同 inference backend 之间切换。NemoClaw 还提供完整的生命周期管理(nemoclaw onboard 一键创建 sandbox、policy-add 增量添加策略、inference set 运行时切换模型、status / logs / doctor 可观测性命令),把 agent 部署的工程复杂度封装为开发者友好的 CLI。NemoClaw 在 inference 后端上的开放设计,恰好把”自托管 vs 全托管”的选择权交还给部署者——这是它与亚马逊云科技多种 inference 路径自然契合的关键。
本文将通过一次完整的部署实践,演示如何在 Amazon EC2 GPU 实例上跑通 NVIDIA NemoClaw,并在此基础上引入 NVIDIA 官方刚开源的 LLM Router Blueprint 做请求级别的智能路由——让简单请求落在本地 vLLM 上享受 GPU 已购的零边际成本,让复杂推理与多模态请求落在 Amazon Bedrock 上享受弹性容量与最新模型。我们以 g6e.xlarge(NVIDIA L40S 48GB)作为参考机型,在同一台 EC2 上同时跑本地 vLLM(运行 NVIDIA 在 HuggingFace 公开发布的 Llama-3.1-Nemotron-Nano-8B-v1 权重)、NVIDIA LLM Router(运行 Qwen3-1.7B 做意图分类)、以及一个约 80 行的 dispatch 层,把 Router 推荐的模型名映射到本地或 Bedrock 上的实际 backend。文章给出完整的部署命令、dispatch 参考实现、端到端验证流程,以及亚马逊云科技原生的四层安全防御实践。这是一种参考实现,并非唯一选择——你完全可以根据业务场景,选择全 Bedrock、全自托管、或本文的混合路径。
2. 一种可选的成本优化方案:按请求特征分流
实际场景里,企业 agent 经常在同一天处理复杂度天差地别的输入。同一个支持 agent 可能:
- 早上:”Amazon S3 的 Standard-IA 存储类适合什么场景?” → 一句话事实查询,8B 小模型已能给出合格回答
- 中午:”分析这段 5 万行交易日志中的异常模式,给出根因假设” → 多步推理,70B+ 大模型表现更佳
- 下午:”翻译这段产品文案为日文,保持语气” → 中等任务,小模型够用、大模型更精
- 晚上:”这张架构图能优化吗?” → 多模态推理,Bedrock 的 multimodal 模型最合适
如果所有请求一律走 Bedrock 上最强的模型,简单查询的单位 token 成本会显著高于让小模型完成同样任务——成本是有优化空间的。如果所有请求一律走本地 8B 模型,复杂推理任务上的回答质量会不及 frontier 模型,用户体验也是有优化空间的。一种可选的方案是按请求特征分流:让每个请求都被路由到”足以胜任的合适模型”,把账单与体验同时纳入考虑。
NemoClaw + NVIDIA LLM Router + 混合 backend
这种”按请求特征分流”在工程上要回答两个问题:怎么判(决策)和怎么落(代理转发)。本文采用职责分离的实现:
- 怎么判:用 NVIDIA 官方刚开源的 LLM Router Blueprint(v2,experimental 分支)。它是 NVIDIA AI Blueprints 之一,构建在 NVIDIA NeMo Agent Toolkit + FastAPI 之上,对外暴露 OpenAI 兼容的 chat completions endpoint。它支持两种路由策略:Intent-based(用 Qwen3-1.7B 做语义分类,开箱即用、决策可解释)与 Auto-routing(用 CLIP embedding + 神经网络,可在自己的流量数据上重训,按”成本/延迟/质量”联合优化);同时原生支持文本与图像多模态输入。本文示例用 Intent-based 模式起步——它对 g6e.xlarge 单机部署最友好,决策语义化便于审计
- 怎么落:本文给出一个 ~80 行的 Python dispatch 层,把 Router 推荐的模型名映射到本文环境中的实际 backend——简单意图走本地 vLLM 跑 Llama-3.1-Nemotron-Nano-8B-v1,复杂或多模态意图走 Amazon Bedrock 上的 nvidia.nemotron-nano-12b-v2 或 Anthropic Claude Sonnet 4.5
整条链路对 sandbox 内的 agent 代码透明:agent 仍然只调 https://inference.local/v1,NemoClaw 的 OpenShell gateway 把请求送到 dispatch 层,dispatch 调 Router 拿决策,再调对应 backend 拿响应,原路返回。Agent 代码无需感知”决策 + 代理”的存在。
这种设计可能带来三个层面的价值:
| 维度 | 可能的价值 |
| 成本 | 高频简单请求由本地 vLLM 处理,单位边际成本接近 GPU 已购的电费水平 |
| 性能 | 复杂任务交给 Bedrock 上的 frontier 模型,agent 整体表现得到保障 |
| 演进 | 决策层是 NVIDIA 官方维护的开源组件,未来可平滑升级到 NN auto-router、自训练分类器、或 Amazon Comprehend 等托管服务 |
本文给出的是这种混合架构的一份开箱即用参考实现,与 NVIDIA NemoClaw / Nemo Agent Toolkit 团队联合作者共同验证。需要强调的是,它只是众多可行方案之一——如果你的场景以复杂任务为主、或对运维投入有限,直接使用 Bedrock 是更简单且同样有效的选择。本文讨论的混合架构只在特定场景(高 QPS 简单请求占比大、或团队希望对不同业务流量做差异化路由)下有意义。
3. 解决方案架构
3.1 单 sandbox + 智能路由 + 多 backend
NemoClaw 的设计假设是每个 sandbox 都是一个独立的 agent 部署单元——独立的 OpenClaw 进程、独立的 IM channels、独立的 memory、独立的 policy preset。本文聚焦最朴素的形态:单一 sandbox,跑一个 agent,但通过引入路由层让它能调用多个 backend。这样既保留了 NemoClaw sandbox 的隔离与治理价值,又实现了请求级别的混合推理。
整体架构如下图——sandbox 内的 agent 代码透明地调 https://inference.local/v1,OpenShell gateway 把请求 forward 给 host 上的 dispatch 层,dispatch 先去问 NVIDIA LLM Router “该用哪个模型”(Router 用 Qwen3-1.7B 做意图分类),拿到推荐后再翻译到我们环境里的实际 backend——本地 vLLM、Bedrock 上的 Claude Sonnet、Bedrock 上的 Nemotron VLM 等:
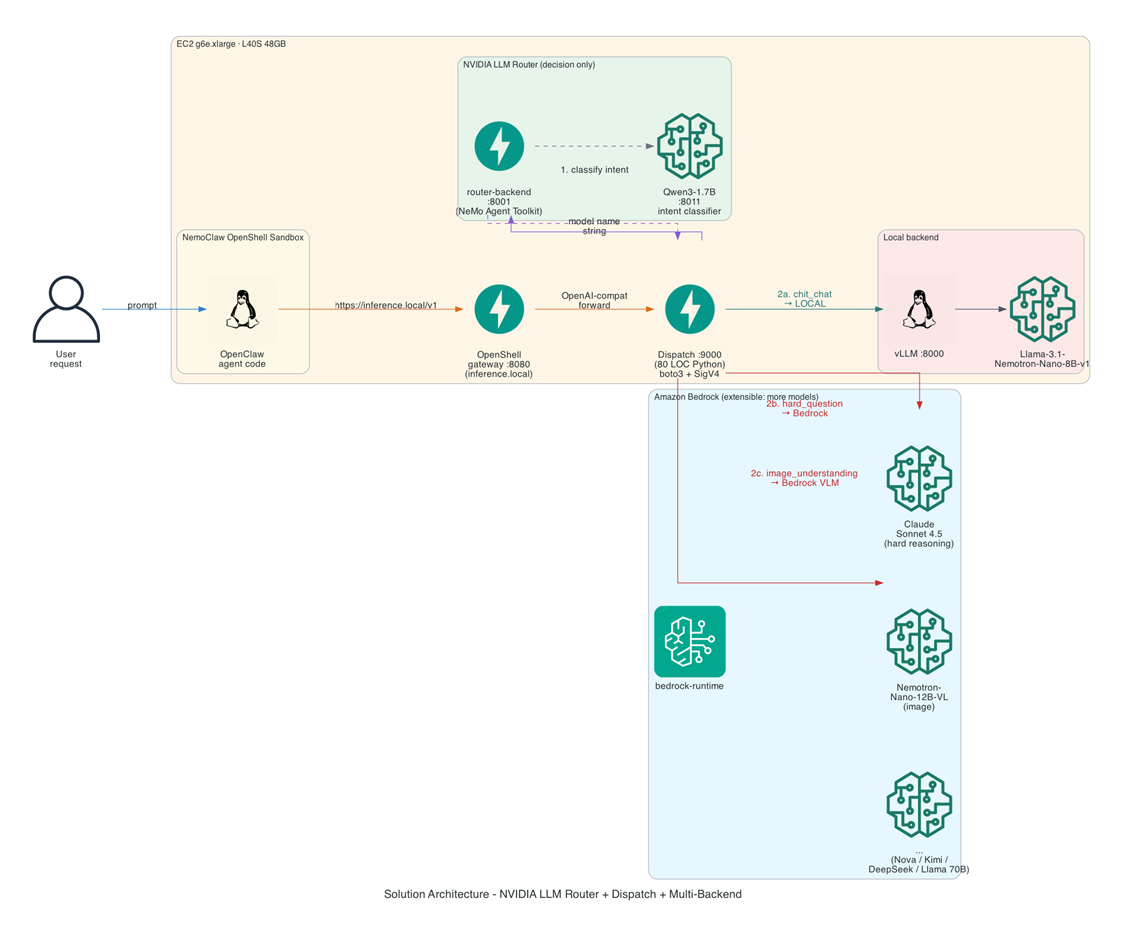
[图1:Solution architecture: NVIDIA LLM Router + Dispatch + Multi-Backend] |
关于 backend 数量:图里我们演示了 3 个具体 backend(本地 vLLM、Bedrock Sonnet、Bedrock Nemotron VLM)以保持示例的可读性。真实场景里可以挂任意多个 backend——Amazon Nova Lite / Pro、Moonshot Kimi、DeepSeek R1、Llama 3.3 70B、自托管 NIM 容器、其他 OpenAI 兼容 endpoint 等等都能加进来——只需要在 dispatch 层的 ROUTING_MAP 里加一条映射。
为什么决策与代理拆开? NVIDIA Router v2 做了一个有意思的架构选择——只做分类,不做代理。它接受 OpenAI 兼容请求,运行 Qwen3-1.7B 给出”该用哪个模型”的建议,但不实际转发请求。这让 routing 算法可以做得很重(语义意图分类、未来还可以叠加 CLIP 多模态 embedding、成本/延迟/质量联合优化的 NN auto-router),同时把代理转发的轻量职责留给应用层——也就是我们的 dispatch 层。Dispatch 层只做一件事:把 Router 推荐的模型名映射到本文环境里的实际 backend。这种分层让”决策可演进、代理保持简单”。
下面这张时序图把”sandbox → gateway → dispatch → Router → backend”一次请求里各组件的协作画了出来——可以看出 Router 只参与决策路径(虚线返回模型名建议),dispatch 才是真正承担代理转发与 backend 翻译的那一层:
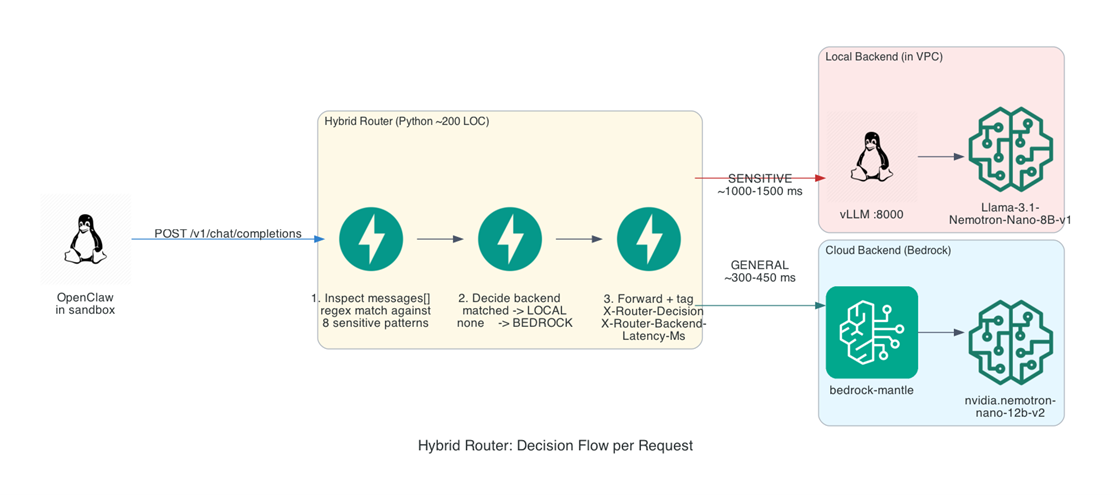
[图2:Routing decision flow: sandbox → gateway → dispatch → Router → backend] |
3.2 GPU 实例选型
如果只用 Bedrock,EC2 不需要 GPU,t3.medium 就够装 NemoClaw + sandbox 直连 Bedrock,月成本约 $30——这是简单稳健的起点。本文要演示自托管 + 全托管混合,需要 GPU。具体跑哪些 GPU 进程决定显存下限:
- 本地 vLLM 跑 Llama-3.1-Nemotron-Nano-8B-v1(BF16 ≈ 16 GB)
- NVIDIA LLM Router 内置的 Qwen3-1.7B(约 6 GB)
- 留 ~25 GB 给并发 batching 与 KV cache 共享
参考机型矩阵:
| 实例 | GPU | VRAM | $/hr (us-east-1) | 适配本文场景 |
| g5.xlarge | 1× A10G | 24 GB | $1.006 | 显存不足,装不下两个 GPU 进程 |
| g6.xlarge | 1× L4 | 24 GB | $0.805 | 同上 |
| g6e.xlarge | 1× L40S | 48 GB | $1.861 | 本文默认配置 |
| p4d.24xlarge | 8× A100 40GB | 320 GB | $32.77 | 适合 Nemotron-3-Super-120B 等更大模型 |
如果你只跑本地推理不跑 Router(例如把 Router 部署在另一台机器上),g5.xlarge / g6.xlarge 24 GB 也够。本文的混合路径在以下场景下值得考虑:
- 高 QPS 简单请求占比大:FAQ、模板回复、内部知识查询等高频但语义简单的请求,本地 8B 已能胜任,单位 token 边际成本远低于按 token 计费的托管路径
- 数据治理诉求:部分内部数据希望”不出 VPC”——dispatch 层按规则强制路由到本地 backend,避免出公网
- 决策可演进:从今天的”按意图分类”路由,到明天的”按成本/质量/延迟联合优化”——NVIDIA Router 提供了清晰的 NN auto-router 升级路径,业务方可以在自家数据上重训
3.3 在 NemoClaw 之上的 4 层亚马逊云科技安全护城河
NemoClaw 自身已经有 sandbox 隔离,亚马逊云科技还能再叠加几层:
| 层 | 机制 | 控制粒度 |
| L1 | VPC Security Group | IP / 端口 — 谁能连进来 |
| L2 | IAM Role + boto3 SigV4 | API 操作 — agent 调 Bedrock 用 instance role 自动签名,无 API key |
| L3 | NemoClaw network policy | sandbox 出网白名单(host + path + method) |
| L4 | Dispatch 层路由策略 | 请求级别 — 哪类请求走哪个 backend,便于审计与成本归因 |
L1-L3 是基础设施层防御,L4 是应用层路由控制。L4 的特点是它不阻止请求,而是改变请求的目的地——除了承担成本/性能优化这一主要职责外,当业务方有内部数据治理诉求时(例如某些字段需要留在 VPC 内),通过同一框架增加规则即可满足,无需重构 agent 代码。
下文 Section 5 会逐层展开。
4. 准备工作
4.1 亚马逊云科技账号要求
GPU 实例在新账号默认 quota 是 0,先查并按需申请:
L-DB2E81BA 是 “Running On-Demand G and VT instances” 的 vCPU 配额。g6e.xlarge 需要 4 vCPU。我们的测试账号 quota 是 768,已经足够。
4.2 Bedrock 模型访问
确认你的账号在目标区域开通了 Bedrock 模型访问,并且能 invoke 我们要用的几个 model:
us-east-1 当前 Bedrock 提供 nvidia.nemotron-nano-12b-v2、us.anthropic.claude-sonnet-4-5-20250929-v1:0(cross-region inference profile)、moonshotai.kimi-k2.5 等。本文使用 Nemotron 与 Claude Sonnet。本文 dispatch 层用 EC2 instance role + Bedrock SigV4(boto3 自动签名)调 Bedrock——不需要 Bedrock API key,比 API key 更安全(无落盘、无轮换、无密钥分发)。
4.3 本地工具
如果 Session Manager plugin 没装,参考官方安装指南。
5. 端到端 Walkthrough
整个流程分 7 个阶段,约 45 分钟拿到一个工作的混合推理环境(首次部署,主要时间在 vLLM 模型权重下载与 Docker image 构建上;后续重启 < 5 分钟):
| Stage | 任务 | 预计耗时 |
| A · 起一台 GPU EC2 + Session Manager 接入 | aws ec2 run-instances + IAM Role | ~3 min |
| B · 验证 GPU 环境 | 确认 DLAMI 预装的 driver / CUDA / Docker 健康 | <1 min |
| C · 部署本地推理后端 | vLLM 跑 Llama-3.1-Nemotron-Nano-8B-v1 | ~12 min |
| D · 部署 NVIDIA LLM Router | docker compose 起 Qwen3-1.7B + Router backend | ~5 min |
| E · 部署 dispatch 层 | ~80 行 Python,把 Router 推荐映射到实际 backend | <1 min |
| F · Onboard NemoClaw sandbox | inference endpoint 指向 dispatch:9000 | ~10 min |
| G · 端到端验证 | 5 个不同特征的 prompt,看 Router 怎么判,dispatch 怎么落 | <2 min |
完整脚本见附录 A、B。读者可以直接复制粘贴到本地文件运行,无需访问任何外部仓库。下面按阶段说明每一步的关键决策与命令。
5.1 Stage A · 起一台 GPU EC2 + Session Manager 接入
5.1.1 A.1 启动 EC2
本文需要的基础设施很简单:一台 g6e.xlarge GPU 机器、一个 IAM Role 让 EC2 实例能用 SSM + 调 Bedrock。最佳实践:
- AMI 用 SSM Parameter 自动解析最新 DLAMI Ubuntu 22.04 GPU,预装好 NVIDIA driver / CUDA / Docker / DCGM
- IAM Role 附 AmazonSSMManagedInstanceCore(远程接入)+ AmazonBedrockFullAccess(调 Bedrock,生产环境可收紧到 bedrock:InvokeModel + 具体 modelArn)
- EBS gp3 200GB 加密,留足 sandbox image + vLLM 模型缓存空间
- IMDSv2 强制、Security Group 默认仅出站——零入站端口
如果你已有合适的 IAM instance profile,一行 aws ec2 run-instances 就够:
如果是从零起步、连 IAM Role / Security Group 都还没建,下面这组命令一次性把它们建好(约 30 秒):
然后把上面 aws ec2 run-instances 命令里的 <your-profile-with-ssm-and-bedrock> 替换成 $TAG-profile、加上 --security-group-ids $SG_ID 即可。Console 操作也行——EC2 Console → Launch Instance → 勾选 IMDSv2 / 不开 SSH 端口 / 附带新建的 IAM Role。
5.1.2 A.2 通过 Session Manager 接入
或者从 Console 进入——EC2 实例详情页 → Connect → Session Manager → Connect:
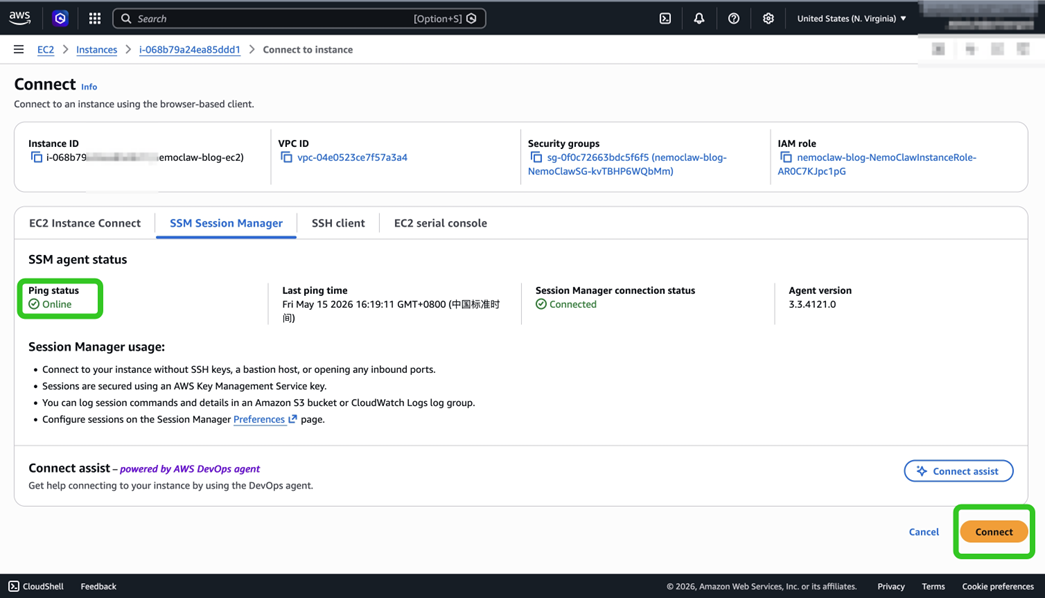
[图3:EC2 Console → Connect → Session Manager 页:Ping status Online、Connection 已建立] |
为什么不开 SSH?Session Manager 提供等价的远程 shell 体验,但零入站端口、零密钥分发、IAM 控制访问、CloudTrail 记录每次会话——这是亚马逊云科技对运维通道的推荐做法。
| 维度 | SSH | Session Manager |
| 入站端口 | 需要开 22 | 零 |
| 凭证 | 私钥分发 | IAM role |
| 审计 | sshd 日志 | CloudTrail |
| 撤销 | 删 key | 改 IAM policy |
> 提示:接下来 Stage B–G 的所有命令,都在你刚刚通过 Session Manager 进入的 EC2 实例内执行。每个 Stage 开头会再次提示,方便你不会迷失。如果中途断开 SSM 会话,重新跑 aws ssm start-session --target $INSTANCE_ID --region $REGION 即可恢复。
5.2 Stage B · 验证 GPU 环境
> 执行环境:EC2 实例内(Session Manager 会话)
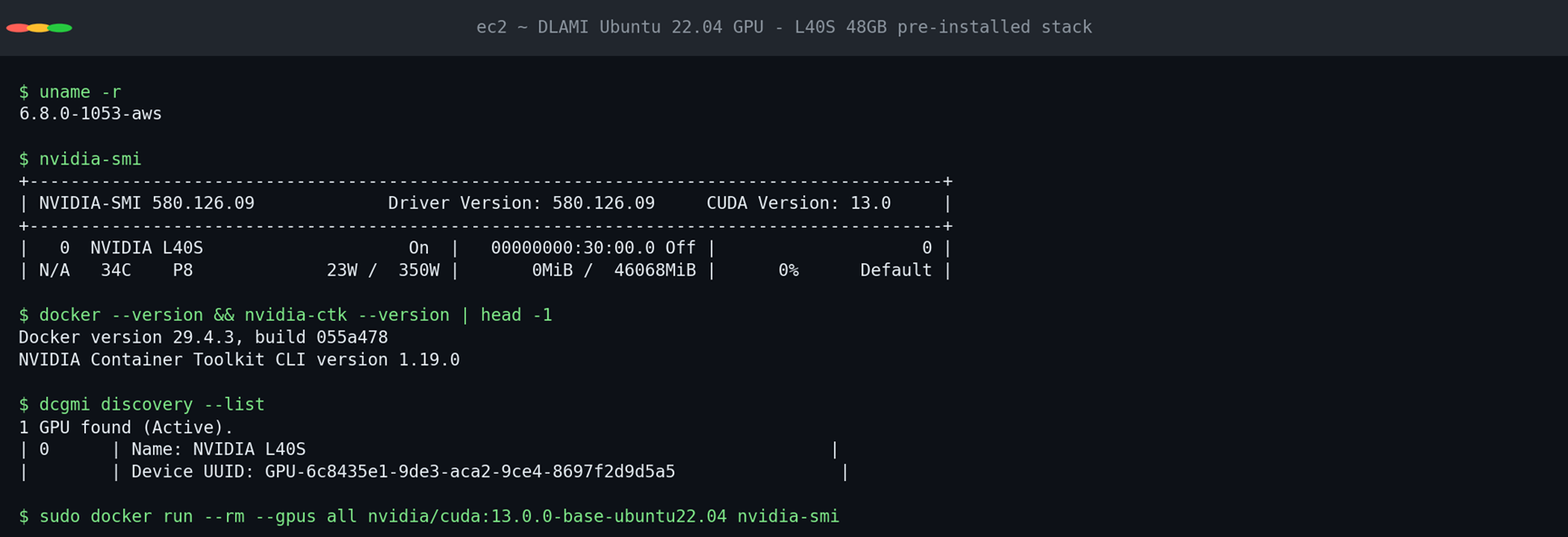
DLAMI Ubuntu 22.04 GPU 已经预装好 NVIDIA driver、CUDA、cuDNN、NVIDIA Container Toolkit、Docker、DCGM——零安装步骤。一组命令快速确认就位:
GPU-in-Docker 透传是否工作(这是 NemoClaw sandbox 与 vLLM 容器都需要的前提):
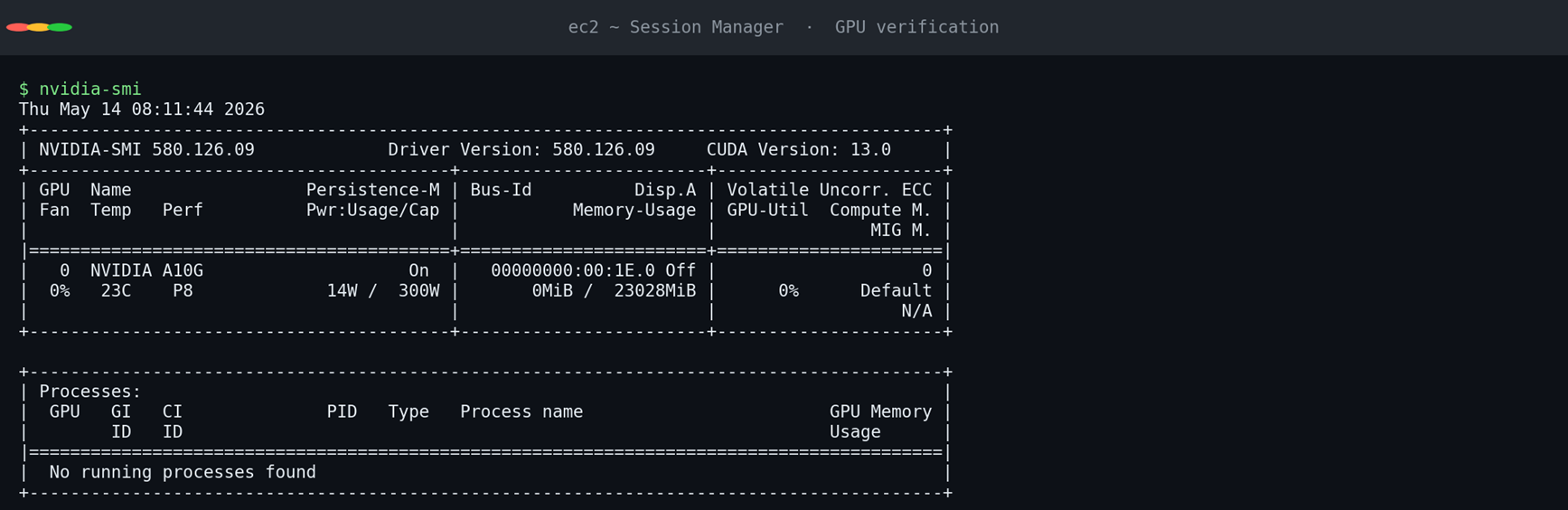
[图4:nvidia-smi:L40S 48GB、driver 580.95.05、CUDA 13.0 在 DLAMI 上原生就位] |
[图5:DLAMI 预装栈:driver / CUDA / Docker / DCGM 四件套] |
5.3 Stage C · 部署本地推理后端:vLLM 跑 NVIDIA Nemotron
> 执行环境:EC2 实例内(Session Manager 会话)
我们用 vLLM 跑 `nvidia/Llama-3.1-Nemotron-Nano-8B-v1`——NVIDIA 在 HuggingFace 上发布的 8B 开源权重,128K context,L40S 48GB 单卡跑 BF16 占约 16 GB。
注意 --gpu-memory-utilization 0.40——只让 vLLM 占用 40% 显存(≈19 GB),给后面的 NVIDIA Router 留够空间。
启动时序:Docker pull 7 分钟 + 模型权重下载 16GB / 4 分钟 + engine 加载 1 分钟,约 12 分钟首次就绪。第二次启动镜像和模型都已缓存,约 2 分钟。
启动完成后用一组命令快速验证 vLLM 容器、应用日志、GPU 占用同步就位:
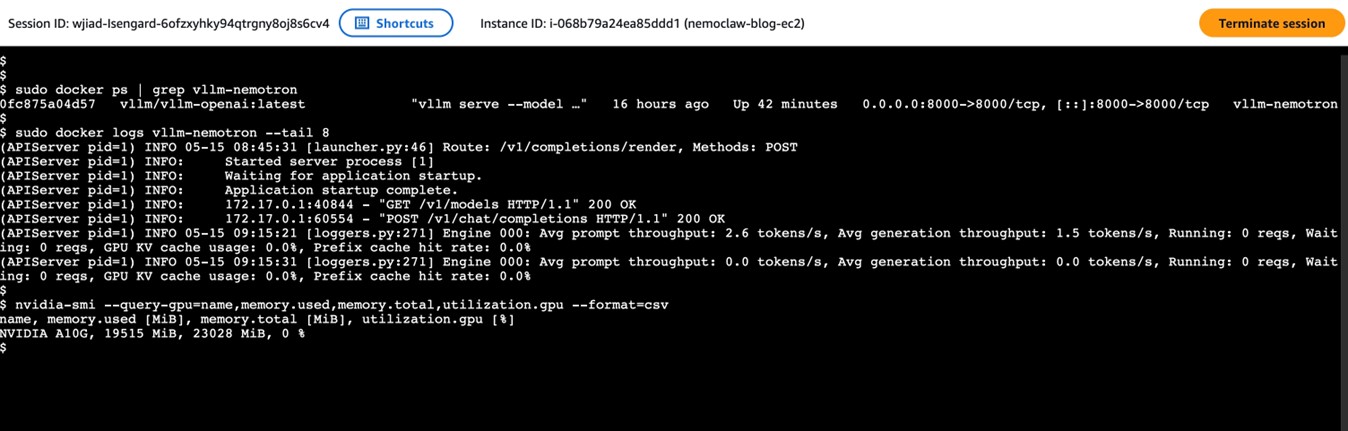
[图6:vLLM 容器、应用日志、GPU 占用三同步就位] |
显存占用稳定在 18GB / 46GB,留有大量余量给 Router 与并发 batching。
直接 smoke test 本地 vLLM:
5.4 Stage D · 部署 NVIDIA LLM Router
> 执行环境:EC2 实例内(Session Manager 会话)
5.4.1 D.1 这个 Blueprint 是什么
NVIDIA LLM Router 是 NVIDIA AI Blueprints 之一,构建在 NVIDIA NeMo Agent Toolkit + FastAPI 之上,源码 开源在 GitHub(experimental 分支,Apache-2.0)。它把”该用哪个模型”这件事抽象成一个 OpenAI 兼容的 endpoint,让任何应用层都能以 chat completions 的形态调用。它的核心能力:
- 两种路由策略——Intent-based(用 Qwen3-1.7B 对 prompt 做语义分类,零训练、决策可解释);Auto-routing(用 CLIP embedding + 神经网络,按”成本/延迟/质量”联合优化,可在自有数据上重训)。本文用 Intent-based 起步。
- 多模态原生支持——文本与图像混合输入都能进入路由决策(图像走 base64 data URL)。
- Recommendation Engine 模式——返回最优模型名(字符串),不实际转发请求。这是 NVIDIA 的设计选择:让 routing 算法保持轻量与可演进,把代理转发的责任留给应用层,让接入更灵活。
- 预置的目标模型清单——默认配置面向 NVIDIA Build / Azure OpenAI 的 Llama 3.1 8B/70B、Mixtral 8x22B、DeepSeek R1、Nemotron Nano 9B / 12B VL、GPT-5 Chat 等模型。意图与目标模型的映射写在配置文件(MAP_INTENT_TO_PIPELINE),可以直接改成本文环境里的 Bedrock 模型 ID(详见 §E 末尾的”进阶”段)。
- 完整的 Docker Compose 部署 + Gradio 演示 UI + Jupyter 训练 notebook——从开发到生产的工具链是齐的。
5.4.2 D.2 部署
把仓库 clone 下来并起 docker compose——--profile intent 这条路径只起 router-backend 与 qwen-router 两个容器,不需要任何 API key(NVIDIA / OpenAI / Azure 这些 key 只有 Gradio demo-app 才用,而我们不用 demo-app):
启动时序:第一次 build router-backend 镜像 + Qwen 模型下载 ≈3.5 GB ≈ 5 分钟。后续 docker compose up 约 30 秒。
5.4.3 D.3 验证 Router 能正确分类
!NVIDIA LLM Router 启动 + 分类 smoke test <!– PHASE2: regenerate after real run –>
注意 Router 返回的是模型名字符串——这是 NVIDIA Build / Azure OpenAI 上的模型 ID(例如 nvidia/nvidia-nemotron-nano-9b-v2、gpt-5-chat、nvidia/nemotron-nano-12b-v2-vl)。本文环境的实际 backend 是本地 vLLM + Amazon Bedrock,这些符号需要被映射到我们具体的 backend——这是下一节 dispatch 层的职责。
5.5 Stage E · 部署 dispatch 层
> 执行环境:EC2 实例内(Session Manager 会话)
5.5.1 E.1 为什么需要 dispatch 层
读到这里你可能会问:既然 NemoClaw 已经有 OpenShell gateway 了,为什么还要在 host 上再写一层 dispatch?让 OpenShell gateway 或 OpenClaw 配置直接做”模型名映射”不行吗?
答:当前版本的 NemoClaw / OpenShell 没有内置的模型名映射机制。OpenShell gateway 的设计假设是”一个 inference route 对应 (provider, model) 的固定二元组,请求按这个 route 转给一个 OpenAI 兼容 endpoint”——它不会做”router 推荐 X,gateway 自动转 Y”这种动态翻译。所以两条路:
- 路径 A:在 host 上叠 dispatch 层(本文采用)——80 行 Python 一个文件,对外暴露 OpenAI 兼容 endpoint 给 OpenShell,对内调 Router 拿决策再调对应 backend。0 改动 NemoClaw / OpenShell / Router 任何一方
- 路径 B:改 Router 的配置文件——把 MAP_INTENT_TO_PIPELINE 直接写成 Bedrock 模型 ID(如 anthropic.claude-sonnet-4-5-…),让 Router 直接推荐我们 backend 里的模型名。这样 dispatch 层可以退化为更薄的纯转发(仍然要写,因为 Router 不做 proxy),但 Router 的 demo notebook 与 Gradio UI 也会跟着用 Bedrock 模型,与 NVIDIA 官方示例 ID 不一致
本文采用路径 A:保留 Router 默认配置(对官方示例 0 改动),把映射逻辑全部封装在 80 行的 dispatch 层里——便于读者把 Router 当一个开箱即用的”决策黑盒”看待,需要替换或升级时也最容易。如果你的部署里希望 Router 推荐就是最终模型 ID,§E 末尾给出”进阶:让 Router 直接推 Bedrock 模型 ID”的简化路径。
5.5.2 E.2 部署 dispatch
dispatch 层是一段 ~80 行的 Python OpenAI 兼容 proxy(完整源码见附录 A)。每次拿到请求时它做两件事:
1. 决策:把请求转发给 NVIDIA Router(host:8001),拿到推荐模型名(一个字符串)
2. 代理:按 ROUTING_MAP 把推荐模型名翻译成实际 backend + 实际模型 ID,转发请求并返回响应
核心映射表(可按业务场景调整):
部署分三步:先把脚本搬到 EC2 上、装好依赖、然后后台启动。
Step 1:把 dispatch 脚本下到 EC2 上。把附录 A 整段源码复制粘贴进 /opt/dispatch_with_nv_router.py:
如果你已经把脚本提交到自己的 Git 仓库或 S3 上,也可以用 git clone / aws s3 cp 直接下:
Step 2:安装 Python 依赖。dispatch 唯一的外部依赖是 boto3(用来调 Bedrock):
Step 3:后台启动。dispatch 用 EC2 instance role + SigV4 自动签名调 Bedrock,无需任何 API key:
> 生产化建议:本文用 nohup + 后台运行只为演示。生产环境推荐写一个 systemd unit 文件(/),用 etc/systemd/system/dispatch.servicesystemctl enable + start 启动,获得自动重启、日志归集、依赖管理等能力。
启动日志:
直接打 dispatch 做 smoke test:
X-NV-Router-Suggested / X-Dispatch-Backend / X-Dispatch-Model 这三个 header 让每次请求的路由决策对外可见,便于审计与成本归因。
!Dispatch smoke test:simple→LOCAL,hard→BEDROCK,附响应 header <!– PHASE2: regenerate after real run –>
5.5.3 E.3 进阶:让 Router 直接推 Bedrock 模型 ID
如果你不想保留 Router 默认配置里的 NVIDIA Build 模型符号,可以直接改 Router 的意图 → 模型映射,让它推荐就是你 backend 里的最终模型 ID。改 llm-router/src/nat_sfc_router/functions/hf_intent_objective_fn.py 里的 MAP_INTENT_TO_PIPELINE:
然后 docker compose restart router-backend 即可。这样 Router 直接推荐 Bedrock 模型 ID,dispatch 层的 ROUTING_MAP 可以退化为更薄——只需要按 model ID 选对应的 backend URL(vLLM URL 还是 Bedrock URL)+ 对应的 auth header。
两条路径的取舍:默认配置(路径 A)保持 Router 与 NVIDIA 官方示例一致,便于读者理解、也便于后续切换到 NN auto-router;进阶配置(路径 B)让映射逻辑集中到 Router 端,dispatch 层更简单。本文示例用路径 A——更适合”评估 Router”阶段;生产部署可考虑路径 B——更适合”已经定型”阶段。
5.6 Stage F · Onboard NemoClaw sandbox
> 执行环境:EC2 实例内(Session Manager 会话)
5.6.1 F.1 安装 NemoClaw CLI
NVIDIA 官方提供一行 install 命令,CI/headless 环境用 NEMOCLAW_ACCEPT_THIRD_PARTY_SOFTWARE=1 跳过交互式 EULA:
安装时序:约 30-60 秒下载与编译,磁盘增量约 1GB。
5.6.2 F.2 Onboard sandbox:把 dispatch 层接入
NemoClaw 的 onboard 一步完成 5 件事:启动 OpenShell gateway、配置 inference provider、build sandbox Docker image、应用 policy presets、在 sandbox 内启动 OpenClaw。通过环境变量预设就能完全 non-interactive。我们把 sandbox 的 inference endpoint 指向 dispatch 层(host:9000):
NEMOCLAW_PROVIDER=custom 对应 onboard 选项 “Other OpenAI-compatible endpoint”,把 dispatch 层接进 sandbox。http://172.17.0.1:9000/v1 是 sandbox 容器看到的 host bridge 地址。--no-sandbox-gpu 声明 sandbox 内不需要直接 GPU 访问(推理由 dispatch + 上游 backend 完成)。--fresh 表示忽略任何旧的 sandbox 状态——首次部署时它没作用,重跑时它会重建。
整个 onboard 大致 5-7 分钟,主要时间在 sandbox Docker image 构建上(npm ci + OpenClaw 配置生成 + policy preset 应用)。NemoClaw 在 onboard 过程中会做一次 OpenAI Chat Completions 探测,验证 NEMOCLAW_ENDPOINT_URL(也就是 dispatch 层)可达——这一步成功,即说明 sandbox → OpenShell gateway → dispatch → NVIDIA Router → backend 这条完整链路通了。
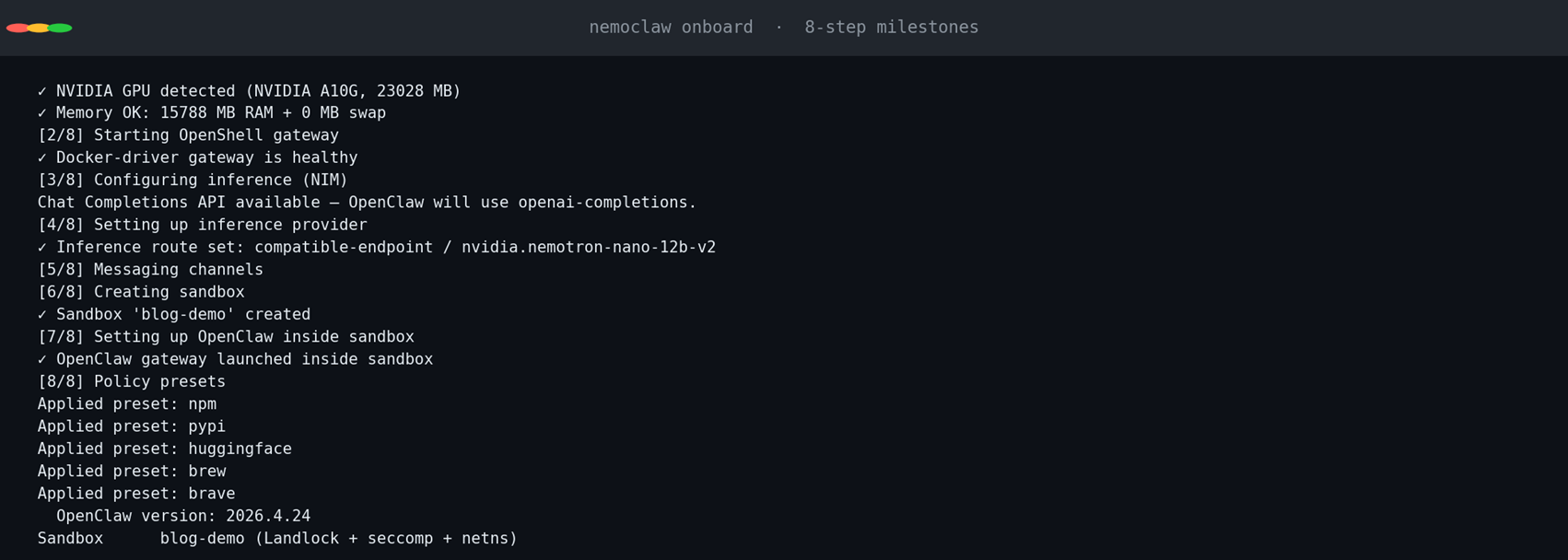
[图7:NemoClaw onboard:5 个阶段一次完成,dispatch 探测通过] |
Onboard 完成后用 NemoClaw CLI 速查 sandbox 状态:
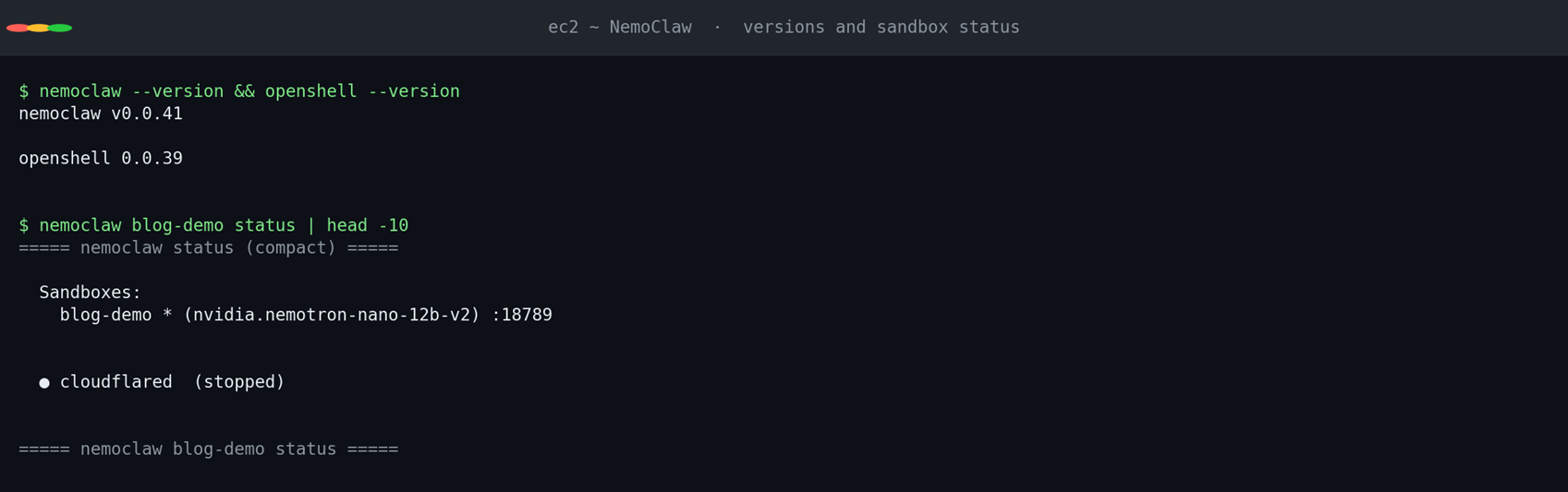
[图8:NemoClaw CLI:sandbox 状态、provider、policy preset 一目了然] |
到这里,一个由 NemoClaw 部署、推理走 dispatch + NVIDIA Router 智能路由、policy 已加固的 sandboxed agent 已经在 sandbox 内就绪。
5.7 Stage G · 端到端验证
> 执行环境:EC2 实例内(Session Manager 会话)
整条链路(sandbox → OpenShell gateway → dispatch → NVIDIA Router → backend)已经就位。验证最直接的方式是用 NemoClaw 自己的 OpenClaw CLI 给 sandbox 内的 agent 发 prompt——这就是真实业务里最终用户的入口。我们用 openshell sandbox exec 在 sandbox 内调用 openclaw agent,给 5 个不同性质的 prompt:
每发一条 prompt,OpenClaw 都会通过 sandbox 内的 inference.local 调到 host 上的 dispatch(172.17.0.1:9000),dispatch 再去问 NVIDIA Router 并落到对应的 backend。下面是真实的 5-prompt 完整输出(来自 g6e.xlarge 实例上的 sandbox agent-demo)——这是最终用户视角:
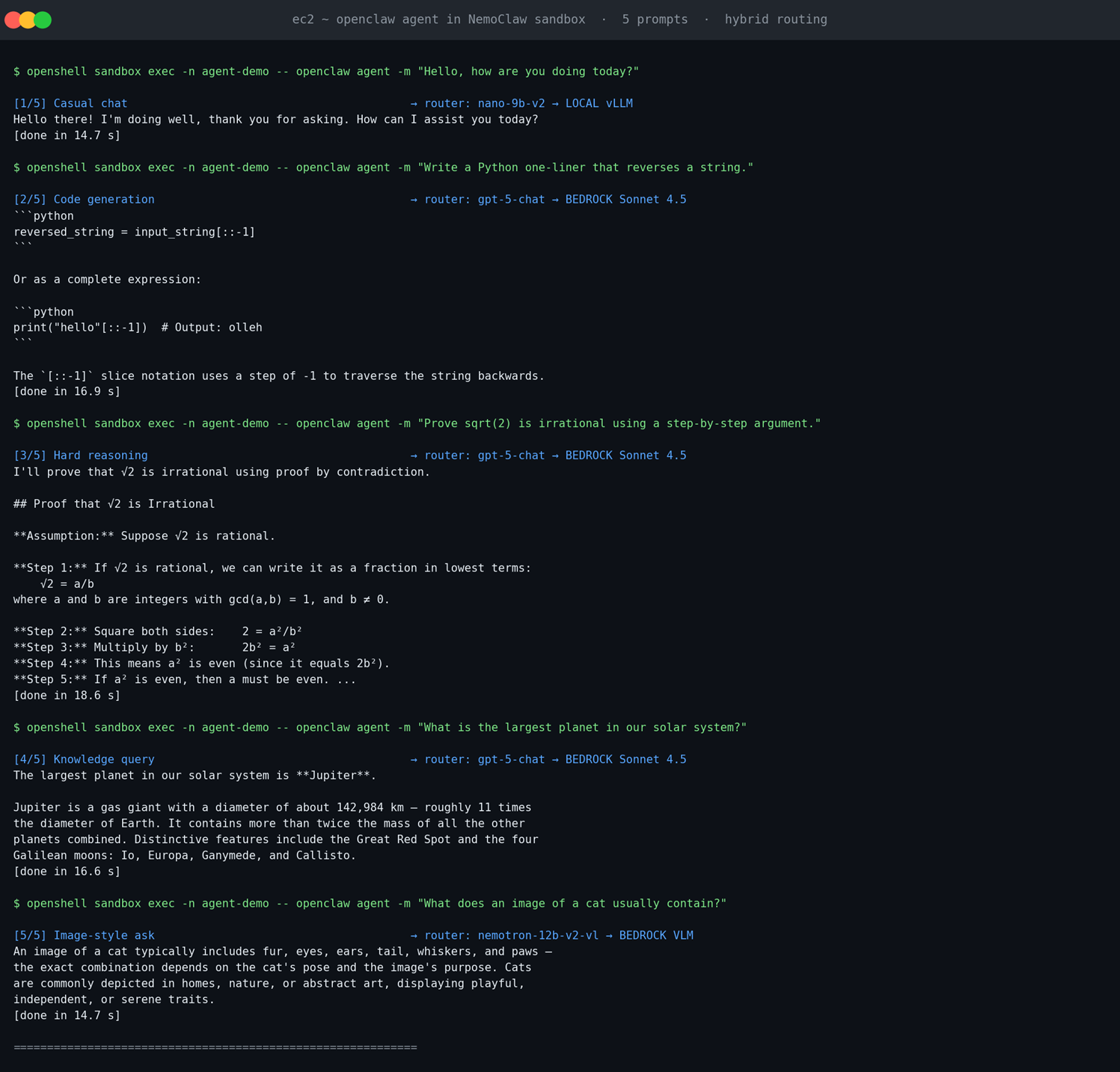
[图9:ec2 ~ openclaw agent in NemoClaw sandbox · 5 prompts · hybrid routing] |
每一条都得到了真实有用的回答:casual chat 是友好的简短问候;code generation 给出 Python [::-1] slice 的标准答案;hard reasoning 输出结构化的反证法 markdown;knowledge query 给出 Jupiter 的事实细节;image-style ask 由 VLM 描述图像通常包含的元素。5 个 prompt,5 段贴合问题特征的回答。
但这只是用户看到的部分。运维 / SRE 还需要知道每一次请求落在了哪个 backend、决策依据是什么。我们在另一个会话 tail -f /var/log/dispatch.log,看到的是同一组请求的操作员视角:
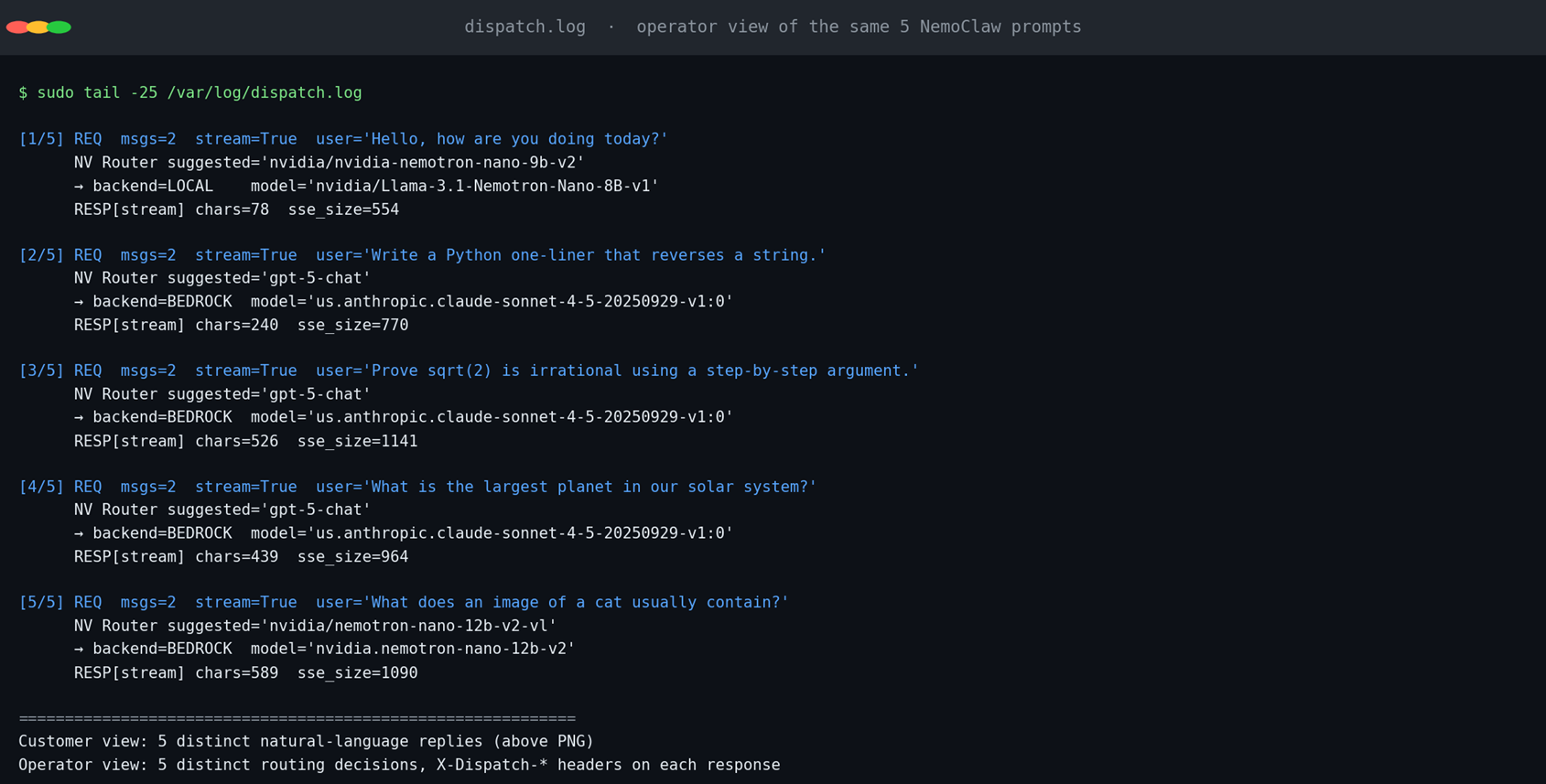
[图10:dispatch.log · operator view of the same 5 NemoClaw prompts] |
两张图完整闭环:用户视角看到的是符合预期的自然语言回答;运维视角看到的是 5 个不同的 NVIDIA Router 决策(nano-9b-v2 / gpt-5-chat / nemotron-12b-v2-vl),分别落到 LOCAL vLLM、BEDROCK Claude Sonnet 4.5、BEDROCK Nemotron VLM 三种 backend——同一个 sandbox、同一个 dispatch、同一个 Router、3 个 backend,按请求特征自动分流。
| Prompt 类别 | NVIDIA Router 推荐 | dispatch 落点 | 实际后端模型 | 端到端时长 |
| Casual chat | nano-9b-v2 | LOCAL | Llama-3.1-Nemotron-Nano-8B-v1 (vLLM) | 14.7 s |
| Code generation | gpt-5-chat | BEDROCK | Claude Sonnet 4.5 (cross-region inference) | 16.9 s |
| Hard reasoning | gpt-5-chat | BEDROCK | Claude Sonnet 4.5 | 18.6 s |
| Knowledge query | gpt-5-chat | BEDROCK | Claude Sonnet 4.5 | 16.6 s |
| Image-style ask | nemotron-12b-v2-vl | BEDROCK | nvidia.nemotron-nano-12b-v2 | 14.7 s |
测试条件:us-east-1 / g6e.xlarge / sandbox agent-demo / 通过 openshell sandbox exec 调 OpenClaw agent 命令 / 单次冷请求 / 各 prompt 之间约 1 秒间隔。端到端时长包含 OpenClaw 内部 plugin 加载、HEARTBEAT 心跳、Router 分类、backend 推理与 SSE 响应解析的完整链路。
> 关于 Router 的判定结果:实测里 NVIDIA Router 把 “code generation”、”hard reasoning”、”knowledge query” 都判成了 gpt-5-chat(即 hard_question 类),而不是 chit_chat。这正是 intent-based 路由的真实行为——Qwen3-1.7B 把”写代码”和”问知识”都视为需要更强模型的任务。如果你希望让简单代码或常识查询走本地 8B,可以编辑 Router 的 MAP_INTENT_TO_PIPELINE 配置,或者升级到 NN auto-router 模式让它在自家流量上重训。
这意味着在本文的混合架构里,两条路径各有所长,互补而非互替:
| 维度 | 本地 vLLM | Amazon Bedrock |
| 单位 token 边际成本 | 接近 GPU 电费水平(GPU 已购) | per-token 计费 |
| 延迟 P50 | 取决于本地 GPU 工程化深度 | 由 Bedrock 托管优化 |
| 运维负担 | 你自己管 GPU 调度、模型版本 | 由 Bedrock 托管 |
| 可用模型 | HuggingFace 公开权重 | Bedrock catalog(NVIDIA Nemotron / Anthropic Claude / Amazon Nova / Moonshot Kimi 等) |
6. 生产化加固
走通 walkthrough 后,下面这些是上生产前不能省的几件事。
6.1 L1:Session Manager 替代 SSH
我们 Stage A 起的 EC2 已经做到这一步——Security Group 配置为零入站规则。如果你要加额外审计,给 Session Manager 配 S3 + CloudWatch Logs 输出:
然后所有 session 的 stdin/stdout 都会落到 S3 + CloudWatch,可被 Athena 查询、被 GuardDuty 用作行为分析输入。
6.2 L2:IAM Role 调 Bedrock(无 API key)
本文 dispatch 层用 boto3.client("bedrock-runtime").converse() 调 Bedrock,鉴权由 EC2 instance role + SigV4 自动完成——零 API key、零 secret 落盘、零密钥分发、零轮换工作。生产环境推荐把 instance role 的 Bedrock 权限收紧到具体 modelArn:
如果你的 dispatch 链路里仍有 API key(例如调外部 OpenAI 或 Anthropic),用 AWS Secrets Manager 自动轮换 + Lambda hook 管理。
6.3 L3:NemoClaw 网络策略
NemoClaw 提供 L7 出网白名单——以 host + path + method 粒度控制 sandbox 能访问哪些外部 API。这一层和 VPC Security Group(L4,按 IP/端口控制)互补:恶意 agent 即使知道 SG 允许 0.0.0.0/0:443 出网,也无法在 sandbox 里访问 https://exfil.attacker.com,因为该 host 不在 policy 白名单里。
NemoClaw onboard 默认装 5 个 preset(npm / pypi / huggingface / brew / brave)。需要给 agent 加 GitHub 等访问能力,一行命令搞定:
社区维护的 awesome-nemoclaw 仓库还提供了 AWS、GCP、Stripe、Notion 等扩展 preset。本文聚焦混合推理路由,policy 治理的更多细节超出本文范围,感兴趣的读者可以从该仓库获得开箱即用的扩展。
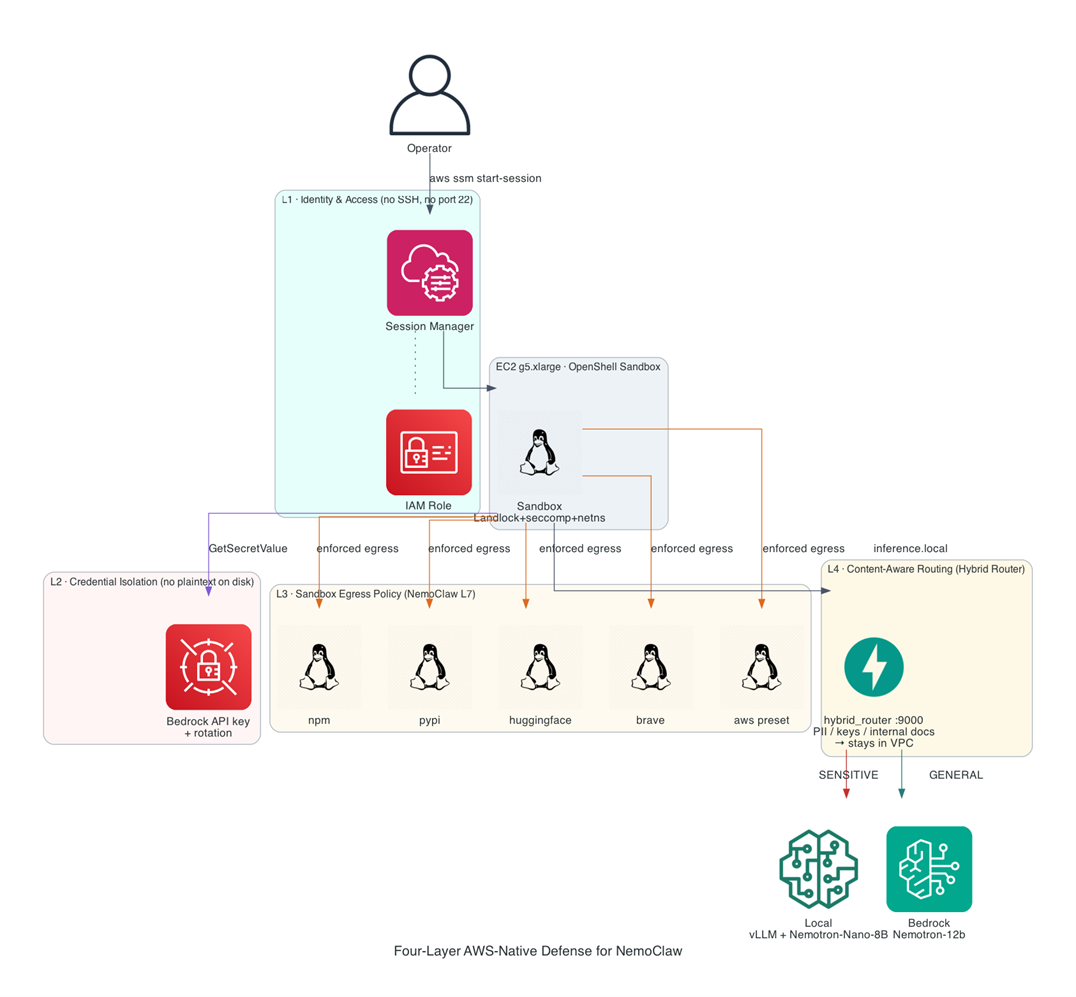
[图10:Four-layer AWS-native defense for NemoClaw] |
6.4 L4:Dispatch 层的可观测性与策略点
§E 的 dispatch 层在每次响应都会注入 3 个 header(X-NV-Router-Suggested / X-Dispatch-Backend / X-Dispatch-Model)。它和前三层互补:
| 层 | 控制粒度 | 作用 |
| L1 SG | IP / port | 谁能连进来 |
| L2 IAM | API 操作 | 谁能调亚马逊云科技 API |
| L3 NemoClaw policy | host / path / method | sandbox 出去找谁 |
| L4 Dispatch | 请求特征 | 请求送给哪个 backend |
L1-L3 是”基础设施层”防御,L4 是”应用层”路由控制。L4 的特点是它不阻止请求,而是改变请求的目的地——除了承担成本/性能优化这一主要职责外,当业务方有内部数据治理诉求时(例如某些字段需要留在 VPC 内),通过同一框架增加规则即可满足,无需重构 agent 代码。
生产化建议:
- 把 dispatch 的 routing 决策日志接到 Amazon CloudWatch Logs Insights:每次请求 X-NV-Router-Suggested + X-Dispatch-Backend 落到 log,便于事后分析”哪些意图被分到哪个 backend”
- 接 CloudWatch Metrics:每分钟上报 Decision=LOCAL / Decision=BEDROCK 的计数比例
- 在 dispatch 层加规则覆盖:检测特定 prompt 模式(PII / 敏感字段)时强制走本地不出网,覆盖默认的 Router 决策
- 接 Amazon Bedrock Guardrails:BEDROCK 路径上叠加内容审核
- 升级路由决策:把 NVIDIA Router 切到 NN auto-router 模式(CLIP+NN,需要训练),让路由按”成本/延迟/质量”联合优化,而不是只按意图分类
6.5 监控:CloudWatch + DCGM
DLAMI 已经装了 DCGM 4.5.3。把指标接入 CloudWatch 需要 CloudWatch Agent + DCGM exporter prometheus scrape:
为 GPU temp > 85°C、status check failed、内存超 90% 配 CloudWatch alarm。
7. 成本考量
混合架构的成本由”基础设施”和”按用量”两部分组成。
基础设施侧(us-east-1,2026 年 5 月):
| 资源 | 单价 | 月度(24×7) | 月度(8h×22d) |
| g6e.xlarge | $1.861/hr | $1,340 | $327 |
| EBS gp3 200GB | $0.08/GB-月 | $16 | $16 |
| Session Manager | $0 | $0 | $0 |
| 基础设施小计 | ~$1,356 | ~$343 |
按用量侧(取决于分流比例)
| 推理路径 | 计费方式 | 备注 |
| 本地 vLLM (Nemotron-Nano-8B) | 由 EC2 GPU 时间承担 | 已包含在基础设施成本里 |
| NVIDIA LLM Router (Qwen3-1.7B) | 由 EC2 GPU 时间承担 | 同上 |
| Bedrock (Nemotron-12B / Claude Sonnet 4.5) | per-token | 详见 Bedrock 定价 |
举例:100K 次/月对话,假设每次平均 200 输入 + 80 输出 token:
- 全 Bedrock Sonnet 4.5:100K × 280 token = 28M token,约 $84/月
- 全本地(仅 vLLM):占用约 5-10% 的 GPU 时间,但 GPU 反正都在跑,额外成本 = $0
- 混合 70/30(70% 简单请求被 Router 路由到本地,30% 复杂请求走 Bedrock Sonnet):约 $25 Bedrock 费用 + 0 本地费用,相对全 Bedrock 节省约 70% 推理成本
两个常用做法
- 开发环境用 Stop/Start:非工作时间停掉 EC2,只付 EBS 存储费用,省 65-75%。Stop 会让 sandbox / vLLM / Router / dispatch / OpenClaw 全部下线但保留 EBS 上的状态与镜像缓存;Start 后冷启动约 5-8 分钟即可恢复(sandbox image 已缓存、vLLM 模型权重已下载、Qwen 镜像已下载,无需重做)。如果团队需要”随时可用”,则保持 EC2 持续运行 + 用 Compute Savings Plans 优化成本
- 24×7 生产环境用 Compute Savings Plans:1 年承诺约 27% 折扣,3 年约 50%
架构选择对成本的影响
- 简单查询少 / 全是复杂任务 → 不需要 GPU,t3.medium + 全 Bedrock,月成本约 $30 + Bedrock 用量
- 中等规模混合负载 → 本文参考方案 g6e.xlarge,月成本约 $343-1,356;当大量简单请求被路由到本地时,Bedrock 部分的 token 计费会有相应下降(具体优化幅度取决于流量分布)
- 大规模本地推理 / 需要更大模型 → p4d.24xlarge / p5.48xlarge,月成本翻倍但能跑 30B-120B 模型
8. 清理资源
如果还想清理 IAM Role / Security Group / Instance Profile,按创建时的反向顺序删除即可(detach role → delete profile → delete role → delete SG)。
9. 下一步
本文给出了一个 g6e.xlarge 单机的混合推理参考实现。延伸方向:
- NN auto-router:把 NVIDIA LLM Router 切到 neural-network 模式(CLIP+NN),用自家流量数据重训路由决策,按”成本/延迟/质量”联合优化,而不是固定的意图分类
- 多 backend 扩展:在 dispatch 层 ROUTING_MAP 里加 Amazon Nova Lite、Moonshot Kimi、Llama 70B 等更多模型,让”合适的请求落到合适的模型”维度更细
- 多模态扩展:升级本地 vLLM 跑 Nemotron-Nano-VLM-12B(需要更大显存),让多模态请求也能在本地处理
- Amazon Bedrock Guardrails 集成:在 dispatch 的 BEDROCK 路径上叠加 Guardrail,做 PII 过滤、主题禁用、合规策略
- Amazon API Gateway + Lambda 替代 host 上的 Python:把 dispatch 也”无服务器化”,让路由层水平扩展
➡️ 下一步行动:
相关产品:
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon EC2 — 安全且可调整大小的计算容量
- Amazon IAM — 身份管理和访问权限
- Amazon CloudWatch — 可观测性工具
- Amazon VPC — 隔离云网络
相关文章:
- 基于 MIG 技术在 Amazon SageMaker HyperPod 上实现 GPU 虚拟化的最佳实践
- 基于Amazon Bedrock的云基础设施代码化自动解决方案实践
- 从IDC到云上GPU:基于 Amazon EKS 的大模型推理混合云弹性部署实践
10. 附录 A:Dispatch 层完整实现
下面是 dispatch_with_nv_router.py 的简化版(~120 行,可直接 copy 跑)。完整源码见 validation-output/dispatch_with_nv_router.py。它把 NVIDIA Router 的”推荐模型名”映射到本文环境里的实际 backend——简单意图走本地 vLLM,复杂推理走 Bedrock 上的 Claude Sonnet 4.5,多模态走 Bedrock 上的 Nemotron VLM。Bedrock 调用走 boto3 + EC2 instance role + SigV4 自动签名,无需任何 API key;同时为了兼容 OpenAI vision 风格的 list-content 与 SSE streaming 客户端(包括 NemoClaw 内置的 OpenClaw agent),dispatch 在调 Bedrock 前会把 array content 展平成 string,并在 stream=True 时把单次响应包装成单 chunk SSE。


{kind=link}
{kind=link}