亚马逊AWS官方博客
从 N 台 EC2 到 Amazon EKS + Amazon S3 Files:Waylens 的 OpenClaw 多智能体平台改造
摘要:本文以车载视频 AI 与车队智能化厂商 Waylens 的真实案例为例,介绍如何把分散在多台 Amazon EC2 实例上的 OpenClaw 多智能体(multi-agent)框架,迁移到由 Amazon Elastic Kubernetes Service(Amazon EKS)+ Custom Resource Definition(CRD)+ Operator 统一管理的形态。改造前,Waylens 工程师用于调试 agent 平台的时间已经超过实际使用 agent 完成业务的时间;改造后,升级、巡检、故障恢复都由 agent 自己完成:Operator 负责 EKS 层的滚动升级与 liveness 自愈,Admin agent 负责跨 agent 的升级编排和日常运维,Admin 自身出问题时由 Rex(Backup EKS Operator)接管,多 agent 平台的日常运维交给 agent 自行处理。附 aws-samples/sample-your-opc-eks-agents 一键部署仓库。
目录
一、背景:为什么 Waylens 需要重构 AI Agent 运行平台
Waylens 总部位于美国,业务包含两条线:消费级行车记录仪(Horizon、Secure360 等产品,主要通过 Amazon 美国站零售),以及面向车队管理与保险行业的 AI 视频平台 cam2cloud。由于核心用户都在美国本土,Waylens 的整套云基础设施部署在亚马逊云科技海外区域,并使用 Amazon Bedrock 驱动 AI Agent。
随着 AI Agent 协作在 Waylens 研发流程里越用越多,三类典型场景陆续落地:
- 研发:用 Agent 辅助代码评审、生成测试用例、跑回归
- 市场与文档:Agent 协助多语言文档与素材整理
- 云资源运维:Agent 协助查询 EKS / EC2 资源状态、排查告警、汇总成本异常
Waylens 早期选用了开源多智能体协作框架 OpenClaw(每个 agent 独立持有人设、工作区与对外通道),并按”每台 EC2 跑一个 agent”的模式部署到了 Amazon EC2 上。这种方式部署简单,但运营 1~2 个月后,工程师投入在调试 agent 平台本身的时间已经明显超过实际使用 agent 完成业务的时间。引入 agent 本是为了替工程师减少重复劳动,结果工程师反而被 agent 平台自身的运维问题占去了大量精力。具体暴露出三类痛点:
1. 升级易导致进程崩溃:OpenClaw 在 EC2 上是用户空间的单进程,每次跟随上游做小版本升级或日常调参(改 SOUL/IDENTITY 文件、切换 Bedrock 模型、调整插件),都有不小概率导致进程崩溃——健康检查失败、Discord 通道掉线、消息积压。两个月里 Waylens 遇到过多次故障, 典型案例有两种:一种是跟随上游小版本升级时,多个 agent 中有几个 Discord 未能自动重连,工程师逐个重启进程,花了几十分钟才全部恢复在线;另一种是批量改 SOUL 文件时漏改了其中一台 EC2 上的人设描述,结果同一个 agent 在不同频道里”性格漂移”,QA 排查了一个多小时才定位到问题。
2. N 台 EC2 = N 套运维:每多一个 agent 就多一台 EC2,打补丁、装监控、配 IAM 角色、归档日志都得逐台来一遍。任何一处配置漂移都会变成一张新工单:”为什么只有这一台行为不一样”。
3. 跨 agent 协作依赖手工 scp:一个 agent 产出的调研资料需要交给另一个 agent 处理,或几个 agent 协同撰写一份会议纪要时,工程师都得在多台机器之间手工同步文件,既不可复现也容易丢失。
Waylens 的诉求很清楚:让多个 agent 的部署、升级、数据共享、对外接入像 Kubernetes 上的普通工作负载那样统一声明、统一管理;同时把 agent 平台的日常运维(升级、自愈、故障恢复)尽量交给 agent 自己处理,工程师只在关键决策点介入。
二、方案概览:Amazon EKS + OpenClaw Operator + 共享文件系统
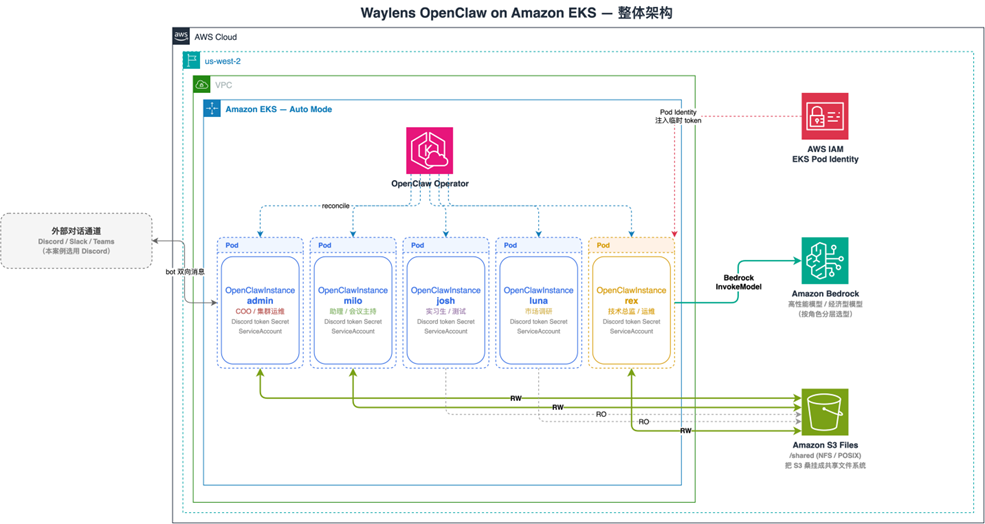
[图1 整体架构:5 个 OpenClaw agent 跑在同一个 Amazon EKS 集群上,由 OpenClaw Operator 管理生命周期,通过 Amazon S3 Files 共享 `/shared` 目录,模型推理走 Amazon Bedrock,外部对话通过 Discord 接入] |
整套方案围绕四个亚马逊云科技产品组合:
| 产品 | 在本方案中的角色 |
| Amazon Elastic Kubernetes Service | 5 个 agent 的统一调度平面(Auto Mode,免管理节点组) |
| Amazon Bedrock | 为 5 个 agent 提供大语言模型推理(按角色分层选型) |
| Amazon S3 Files (26年新服务) | 跨 agent 共享文件系统 /shared,把 Amazon S3 桶以 NFS/POSIX 形态挂进 Pod |
| EKS Pod Identity | 各 agent ServiceAccount 到 IAM Role 的细粒度映射 |
在这套架构里,每个 OpenClaw agent 都被抽象成一份 OpenClawInstance 自定义资源(CR),Operator 把它展开成 StatefulSet + Pod + Service。升级、切换模型、更新人设都通过 kubectl apply 一次完成,不再需要逐台登录 EC2。
三、关键设计决策
3.1 用 CRD + Operator 替代 N×EC2
把每个 agent 抽象成一份 YAML,是这次迁移收益最大的一步。Waylens 使用的 Operator 来自社区开源项目 paperclipinc/openclaw-operator,它定义了 OpenClawInstance 这一自定义资源。
apiVersion: openclaw.io/v1alpha1
kind: OpenClawInstance
metadata:
name: milo
namespace: opc-agents
spec:
image:
repository: openclaw/openclaw
digest: sha256:<DIGEST>
model:
primary: <bedrock-model-id> # 经济型模型,按角色替换
resources:
requests: { cpu: "500m", memory: "2Gi" }
limits: { cpu: "2", memory: "3Gi" }
security:
rbac:
serviceAccountName: opc-agent-default
storage:
privatePVC:
storageClassName: auto-ebs-sc
size: 10Gi
sharedMount:
pvcName: opc-shared
mountPath: /shared
readOnly: false
升级、新增 agent、调整资源都只要改 YAML 再 kubectl apply。reconcile、滚动重启、健康检查这些都由 Kubernetes 标准控制面 + Operator 接管,工程师不必再为每台 EC2 写脚本。
3.2 Amazon Bedrock 模型选型:用多模型组合最大化性价比
多 agent 架构比单 agent 多了一个关键自由度:每个角色的工作负载不一样,没必要全部跑在同一个最贵的模型上。把每个 agent 的模型独立写进 CR 之后,就能按角色挑模型——决策密度高的用高性能模型,调用频次高的用经济型模型,整体推理成本通常能比”全员都用高性能模型”低一个量级,而决策质量依然不会降低。
Waylens 的实际配比:
| 角色 | 工作负载特征 | 模型档位 | 选型理由 |
| Admin(COO / 集群运维) | 长上下文、跨 agent 决策、不可逆操作签字 | 高性能模型 | 决策错代价大,配最强模型;调用频次低,单价不敏感 |
| Rex(技术总监 / AWS 运维 / Backup EKS) | 复杂工程判断 + 真实 AWS 资源操作 | 高性能模型 | 同上;资源操作破坏性大,优先保证决策质量,不为省单价冒险 |
| Milo(助理 / 会议主持) | 长会议上下文、议程编排、写纪要 | 高性能模型(长上下文优先) | 工作偏组织而非创造,长上下文比顶尖推理更重要 |
| Luna(市场调研) | 大量搜索 + 信息汇总 | 经济型模型 | 调研结论有 Rex 复核([[3.6]]),可以用便宜模型跑高吞吐 |
| Josh(实习生 / 回归测试) | 轻任务 + 高频短对话 | 经济型模型 | 频次最高,适合用经济型模型;出错可由 Rex 复核纠正 |
这种”分层选模型”是多 agent 架构本身带来的能力。单 agent 没有这个自由度:要么全员用高性能模型(贵),要么全员用经济型模型(重要决策不放心)。多 agent 架构允许把预算集中投到决策密度高的少数角色(Admin、Rex),同时让高频低风险角色(Josh、Luna)跑在更经济的模型上;再借助 [[3.6]] 的”调研 → 验证”协作链,让便宜模型的产物经过高性能模型复核,把成本压下来的同时控制住质量风险。
CR 里只需声明 spec.model.primary: <bedrock-model-id>,切换模型就是改一行 YAML 加一句 kubectl apply,业务代码不动、容器镜像不重建,做 A/B 对比的代价非常低。
再往前一步,既然”改一行就能换模型”的成本这么低,模型选型实验也就可以交给 agent 自己跑。Waylens 的做法是把”试新模型”做成一个 agent 任务:上游有新模型发布时,Admin 在 Discord 里把任务派给 Josh(实习生角色,本来就以试错为主),Admin用 kubectl patch 把Josh的 spec.model.primary 切到候选模型,跑一组预先准备的回归用例(同一组用户提问,覆盖多个领域),把每条回答和原模型的产出一起写到 /shared/eval/<date>-<model>.md;Rex 读对比报告做技术评审,Milo 在周会上汇总结论。整条链路里工程师只在最后”是否把 Admin / Rex 切到候选模型”那一步确认决策,前面的探索和测试全都由 agent 完成。这样一来,”模型选型”从一项需要工程师手动安排的运维事项,变成了平台日常的自助实验,迭代节奏可以跟上 Bedrock 上游的发布速度。
3.3 EKS Pod Identity 实现单 agent 升权
Waylens 希望只让技术总监角色 Rex 拥有有限的 AWS 运维权限(查询 EKS / EC2 资源状态、调试基础设施告警等),其他 agent 仅持有调 Bedrock 的最小权限。如果用传统的 IAM User + AccessKey 方式,得在 EC2 上发凭据、定期轮换、出问题时回收,运维负担相当重。EKS Pod Identity 把权限直接绑到 ServiceAccount 上,CR 里只需改一行 serviceAccountName 就能切换权限边界:
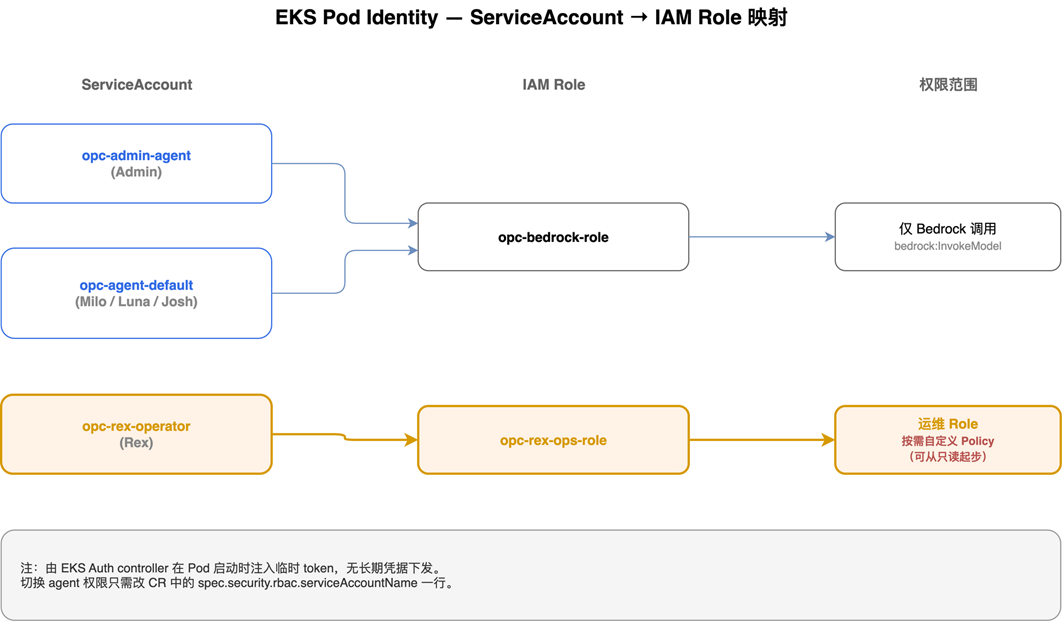
[图2 ServiceAccount → IAM Role 映射:默认 SA 走 Bedrock-only Role,Rex 单独走运维 Role] |
| Service Account | IAM Role | 权限范围 |
opc-admin-agent(Admin) |
opc-bedrock-role |
仅 Bedrock 调用 |
opc-agent-default(Milo / Luna / Josh) |
opc-bedrock-role |
仅 Bedrock 调用 |
opc-rex-operator(Rex) |
opc-rex-ops-role |
运维 Role(按需自定义 Policy) |
opc-rex-ops-role 的 Policy 由各团队按”最小权限”原则自定义(推荐先从只读策略如 ReadOnlyAccess 起步,再按实际运维场景逐条加写权限);本文不展开具体策略,关键在于 Pod Identity 让”切换权限边界”变成 CR 里改一行 YAML的简单步骤,而不是再给某台 EC2 assign custom role。
整个过程也不涉及生成、不下发任何长期凭据;IAM Role 只在 Pod 启动时由 EKS Auth controller 注入一个临时 token。
3.4 用 Amazon S3 Files 做跨 agent 共享文件系统
所有 agent 容器都会挂载同一个 /shared 目录,里面放三类数据:会议纪要、跨 agent 的研究产物、运维变更日志。OpenClaw 进程访问 /shared 习惯按 POSIX 方式来(ls、grep -r、tail -f);如果直接调用 Amazon S3 的对象 API(PutObject / GetObject),agent 代码就会绕过文件系统抽象,也拿不到 NFS 的读写一致性保证。
Amazon S3 Files(发布博客)是 Amazon Simple Storage Service 提供的共享文件系统服务:把一个 S3 通用型桶以 NFS v4.1 / POSIX 形态挂载给 Amazon EC2、AWS Lambda、Amazon EKS(含 AWS Fargate)、Amazon ECS 等计算资源,并支持多客户端并发挂载(NFS close-to-open 一致性)。内部用一层高性能存储缓存活跃数据,原始数据始终保留在 S3 上,活跃数据访问延迟约 1 毫秒,同时继承 S3 的耐久性和成本优势。这种特性非常契合 Waylens 的场景:”5 个 agent 都按文件系统语义读写,单 agent 数据量不大,但需要长期归档”。具体到本方案:
- 创建一个 S3 桶
waylens-opc-shared,为它开启 S3 Files 文件系统能力 - 在 Amazon EKS 集群里通过 PVC 把这个文件系统挂载到每个 Pod 的
/shared - agent 写入的会议纪要直接落到
/shared/meetings/2026-05-29.md,文件系统侧的写入会在分钟级内回写到 S3 桶,借此自动获得版本控制和 Lifecycle policy 归档能力,不必再自己写脚本;S3 侧对桶内对象的修改会在几秒到一分钟内反映回挂载的文件系统
权限模型:S3 Files 同时使用 IAM 与 POSIX 两层权限。挂载侧由 IAM 资源策略限定哪些主体能挂载、以及挂载是读写还是只读;文件侧由 POSIX 的 UID/GID 决定每个 agent 进程对具体文件的读写权限。Waylens 给 Admin / Milo / Rex 配可读写挂载,给 Josh / Luna 配只读挂载,避免实习生或调研 agent 误改入档资料。
3.5 双层自驱动升级 + 自愈:把运维交回给 agent
Waylens 在 EC2 上原来的升级方式是工程师操作让Agent自行升级,一旦上游版本出现回归,所有 agent 会同时故障;而且整个升级过程——拉取镜像、修改配置、重启进程、验证健康检查——全部由工程师手动执行。迁移到 EKS 之后,Waylens 把这条流水线拆成两层,每一层都不再需要工程师介入:
第一层:Operator 自动保障(EKS 层)
OpenClaw Operator 在 reconcile 循环里负责所有 EKS 原生的健康保障:
- 滚动升级:CR 里的
image.digest一变,Operator 就按 StatefulSet 的滚动策略逐个替换 Pod,新 Pod 健康检查通过后才会动下一个 - liveness 自愈:Pod 异常退出或健康检查失败时,Operator 自动重建新副本,不必人工
kubectl delete pod - 配置漂移收敛:若某个 Pod 的环境变量或 ConfigMap 被误改,下一个 reconcile 周期会自动将其恢复为 CR 声明的状态
这一层是 Kubernetes 控制面 + Operator 模式天然提供的能力,工程师既不用写脚本,也不用逐台登录。
第二层:Admin agent 编排(Agent 层)
EKS 能保证Pod 不挂,但回答不了”什么时候升、怎么灰度、新版人设是不是真的好用”这种需要语义判断的问题。Waylens 把这部分交给 Admin agent(COO 角色,使用高性能模型)来做。Admin 持有 kubectl 工具,以及 opc-agents 命名空间的 RBAC 权限,可以执行下列动作:
| 触发 | Admin 的动作 |
| 上游发布新 image digest | 选 Josh 当 canary,kubectl patch openclawinstance josh ...,观察 24 小时 |
| canary 期间日志和对话质量正常 | 批量 patch 其余 agent,并把变更记到 /shared/ops/changelog.md |
| canary 期间发现回归 | 自动 patch 回上一个 digest,并在 Discord 告警频道 @ 工程师说明现象 |
| 某个 agent 反复 CrashLoopBackOff | 先按预案重启并收集日志,超过阈值再 @ 工程师 |
Admin 的人设(SOUL/IDENTITY)里写死了两条规则:”先读后写”,以及”破坏性操作必须先在频道里 @ 工程师确认”。这样 Admin 能自主完成日常升级和重启,但不会越过工程师去做不可逆操作。
Admin 自身故障时由谁恢复:Rex 作为 Backup EKS Operator
把升级编排交给 Admin 之后,Admin 自己就成了新的单点:如果 Admin Pod 进入 CrashLoopBackOff,或者由于一次失败的自我升级崩溃,谁来恢复?Waylens 在 Rex(技术总监角色)的 IDENTITY 里显式写了 Role: Tech Director + AWS Resource Operator + Backup EKS Operator,并把对应的 EKS RBAC 与 AWS 权限都挂到 Rex 的 ServiceAccount 上:
- 触发条件:Admin Pod
Ready=False超过 5 分钟,或 Admin 在 Discord 频道里连续 N 轮没回应 Milo 的点名 - 接管动作:Rex 用自己的 kubectl 权限去查 Admin Pod 的事件和日志,按预案恢复(重启、回滚 image digest,必要时重建 PVC)
- 不对称设计:Admin 不持有 AWS 资源运维权限(仅保留部分EKS权限),所以 Admin 不能完全 backup Rex。这里是单向的 Rex → Admin,不是”互为 backup”;这种不对称是故意的,因为 AWS 资源面的破坏性远大于 EKS 面,权限收窄到一个角色更容易管控。
完整的自愈链路是:Pod 异常退出 → Operator 重建副本;Operator 无法恢复或升级出现回归 → Admin 编排回滚;Admin 自身故障 → Rex 接管 Admin。只剩最外层一种情况需要工程师介入:连 Rex 也不宜自主执行的破坏性 AWS 资源操作(如删除 IAM、销毁 EKS 集群级资源),这类操作本就应当由人工签字确认。
整节所有动作都是声明式的:kubectl patch openclawinstance --type=merge -p '{"spec":{"image":{"digest":"sha256:..."}}}',升级和回滚是同一个命令、不同参数。Admin 和 Rex 跑这条命令,与工程师跑没有任何区别。
3.6 多 agent 协作:点对点协同 + 主持人会议
把 5 个 agent 部署在同一个 EKS 集群、共享同一个 /shared 后,跨 agent 协作不再靠人工 scp,而是落到两类场景里:
场景 A:点对点协同,Luna 调研、Rex 验证
Luna 是市场调研角色,产出是 markdown 报告;Rex 是技术总监兼 AWS 运维角色,能调用真实云资源进行验证。一个典型的协作链路:
4. Luna 在 Discord #research 频道收到任务:”调研 Bedrock Cross-Region Inference 在目标区域的可用性和定价”
5. Luna 完成桌面调研后,把结论写到 /shared/research/2026-05-30-bedrock-cross-region.md
6. Luna 在频道里 @rex 把文件路径发给 Rex,附一句”麻烦你跑一次 InvokeModel 验证一下我引用的 token 计费数字”
7. Rex 读这份文件,用自己的 opc-rex-ops-role 实际调一次 Bedrock,把验证结果追加到同一份文件的 Validation 段落
8. Luna 在频道里看到 Rex 回执,把这份带验证结论的报告交付出去
整条链路不需要人工 scp,工程师也不必在多台机器之间登录;agent 之间靠 Discord @ 提及加 /shared 的 POSIX 路径完成上下文传递。背后两个关键设计:EKS Pod Identity 给 Rex 比 Luna 更高的权限边界([[3.3]]),Amazon S3 Files 的 /shared 让两个 agent 看到同一份文件([[3.4]])。
场景 B:多 agent 会议,Milo 主持、防止无限对话
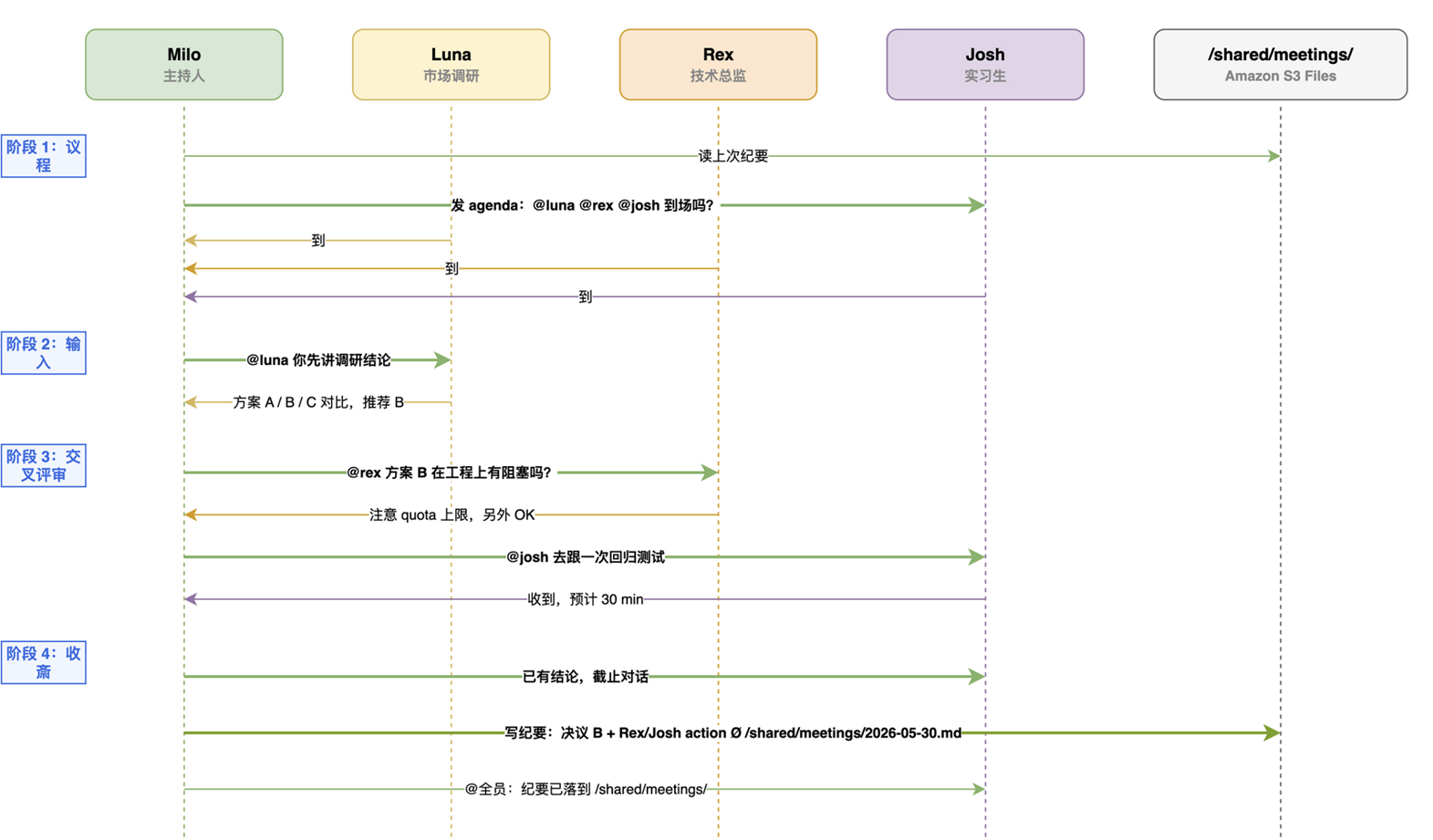
[图3 会议时序:Milo 逐轮点名 → agent 输入 → 交叉评审 → 收敛写纪要到 `/shared/meetings/`] |
3 个以上 agent 在同一频道讨论时,最容易出现的问题是”互相回复无限循环”:一个 agent 看到 @ 自己就回应,另一个被它的回应触发又回应回去,循环不收敛。Waylens 的做法是把会议主持权固定给 Milo(助理角色,使用高性能模型的长上下文),其他 agent 一律不主动发言,只在 Milo 点名时回应:
| 阶段 | 谁说话 | 产物 |
| 议程 | Milo 列出议程,逐个 @ 与会 agent 确认到场 | 议程贴 |
| 输入 | Milo 按议题点名(”@luna 你先讲调研结论”) | 每个 agent 一段输入 |
| 交叉评审 | Milo 让 agent 互相评审(”@rex 你看 luna 的方案在工程上有没有阻塞”) | 评审意见 |
| 收敛 | Milo 判断已经有结论或超过 N 轮发言时,强制收敛并写纪要 | /shared/meetings/YYYY-MM-DD.md |
具体实现上,Milo 的人设里写死了两条规则:(1) 其他 agent 收到非 Milo 的 @ 一律不回应(每个 agent 的 SOUL 文件里也对称声明);(2) 同一议题发言超过 3 轮,Milo 强制总结收敛。这两条规则没有写死在代码里,而是放在 OpenClawInstance 的人设字段中,由 Operator 同步给所有 agent,这样每改一次会议规则就不必再像 EC2 时代那样逐台登录调 prompt。
会议纪要写到 /shared/meetings/;下次会议 Milo 会先读上次纪要再开场,所以会议是有”记忆”的。
四、部署实操:从 0 到 5 个 agent 上线
完整可运行代码在 aws-samples/sample-your-opc-eks-agents。下列步骤已在亚马逊云科技海外区域验证通过。
4.1 前置条件
- AWS CLI v2,并已用具备管理员权限的身份登录
kubectl≥ 1.30,helm≥ 3.14- 一个自有的 Discord 服务器,并已在 Discord Developer Portal 创建 5 个 bot(每个 agent 一个)、拿到对应的 token
4.2 五步部署
# 0. 把自己的 Discord 服务器/频道/bot ID 填进配置
cp discord-config.example.env discord-config.env
$EDITOR discord-config.env
# 1. 检查前置条件
./scripts/check-prerequisites.sh
# 2. 创建 Amazon S3 Files file system 作为 /shared 共享文件系统
./scripts/setup-s3files.sh
# 3. 端到端:创建 EKS 集群 + 安装 Operator + 部署 5 个 agent
./scripts/deploy.sh
# 部署过程会暂停一次,要求你为 5 个 agent 各创建一个 Discord token Secret
部署完成后,期望看到:
$ kubectl get openclawinstance -n opc-agents
NAME READY MODEL AGE
admin True <high-performance> 5m
milo True <high-performance> 5m
josh True <economy> 5m
marketing True <economy> 5m
devlead True <high-performance> 5m
4.3 Discord 配置说明
每个 agent 对应一个独立的 Discord bot:
9. 在 Discord Developer Portal 创建 Application → Bot → 复制 Token
10. 在 Bot 设置里开启 MESSAGE CONTENT INTENT
11. 在 OAuth2 → URL Generator 里勾选 bot + applications.commands,生成的邀请链接邀请 bot 入服务器
12. 把每个 bot 的 ID 写到 discord-config.env,再为 5 个 agent 各创建一个 EKS Secret:
for AGENT in admin milo josh marketing devlead; do
read -s -p "Discord bot token for $AGENT: " TOKEN; echo
kubectl create secret generic ${AGENT}-discord-token \
--namespace opc-agents \
--from-literal=DISCORD_BOT_TOKEN="$TOKEN"
done
ℹ️ 注意:
重启 5 个 agent 的 Pod 时不要同时触发,建议至少间隔 30 秒,避开 Discord 的速率限制。
五、迁移后日常运维由谁来做
这次迁移节省的时间不算最大的变化,更明显的是许多原本需要工程师亲自处理的运维动作,现在由 agent 接管了。下表列出几项 Waylens 日常遇到的运维事项,左侧是 EC2 时代工程师的处理方式,右侧是迁移到 EKS 后的责任归属:
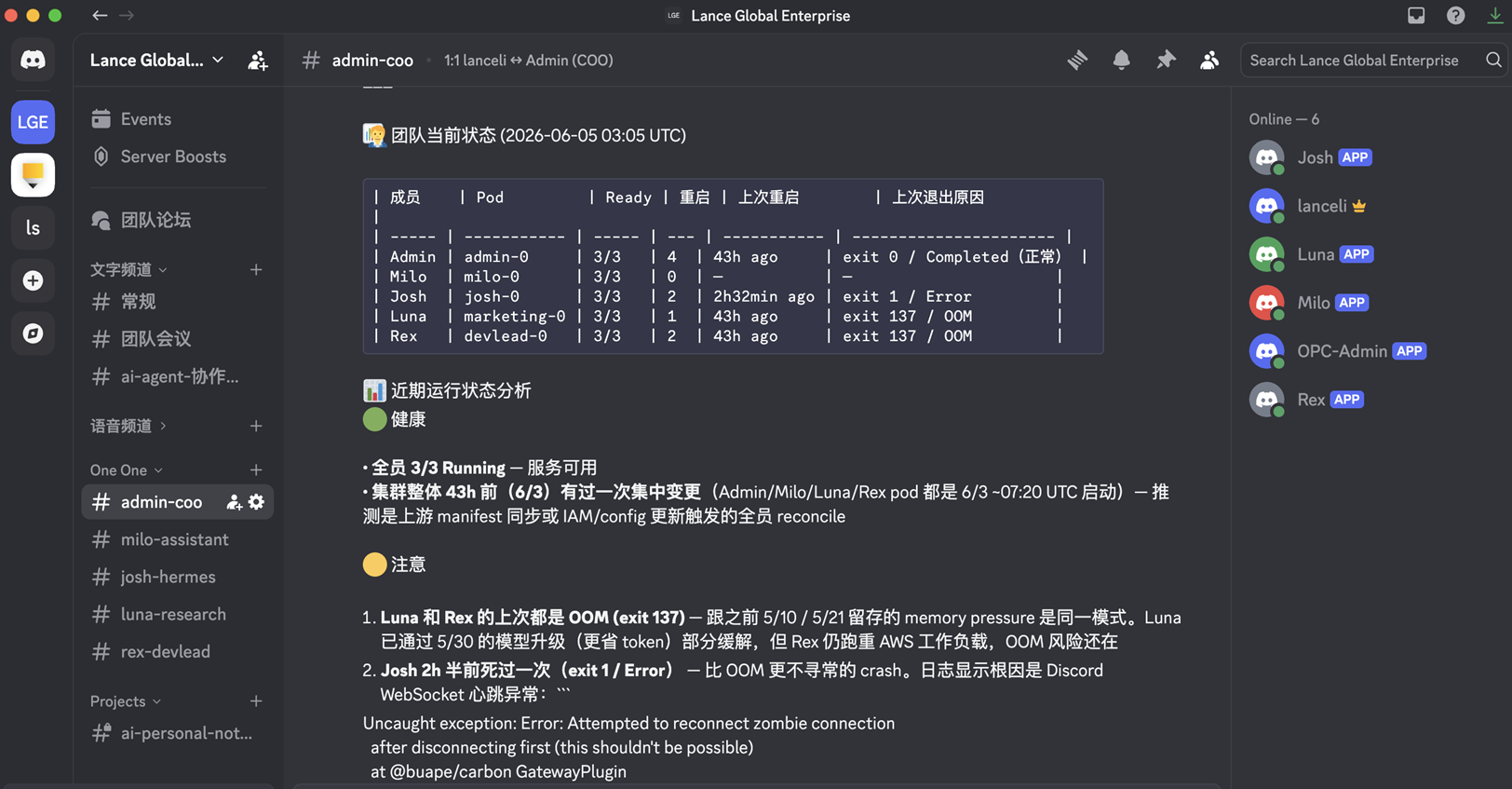
[图4 运行总览:`kubectl get openclawinstance` 输出 + Discord 频道里 5 个 bot 全部在线] |
| 维度 | 典型场景 A:EC2 直接部署 | 典型场景 B:Amazon EKS + Operator + Agent 自驱动 |
| 跟随上游升级 | 工程师逐台 ssh、scp、重启、验证 | Admin agent 编排 canary 与滚动升级;工程师仅在审计 changelog 时复核 |
| Pod / 进程异常退出 | 工程师收到告警 → 登录排查 → 手动重启 | Operator 自动重建;无法恢复时由 Admin 介入;Admin 自身故障时由 Rex 接管 |
| 升级回归 | 工程师手动回退到旧二进制(数十分钟) | Admin 检测到回归后 patch 回上一个 image digest(不到 1 分钟) |
| 配置漂移 | 工程师人工比对、手动修正 | 每次 reconcile 自动将 Pod 恢复为 CR 声明的状态 |
| 跨 agent 数据共享 | 工程师在多台机器间手工 scp | agent 自己读写 /shared POSIX 路径 |
| 单 agent 升权 | 工程师生成、派发、轮换 IAM AccessKey | 改 CR 里一行 serviceAccountName,Pod Identity 自动注入临时 token |
| 工程师在日常运维里的角色 | 一线操作员(被工单追着跑) | 决策签字人(只看 Admin 上报,仅在破坏性 AWS 操作上签字) |
表格右列的大部分事项,工程师已无需再亲自处理。Waylens 内部对这次改造的总结是:改造前调试平台所花的时间已经多于实际使用 agent 完成业务的时间;改造后这些日常运维大多由 agent 自己完成,工程师只在关键决策点参与。
除了运维侧的收益,Waylens 也把这套平台用在内部团队周会上:5 个 agent 通过 Discord 频道完成议程→输入→交叉评审→纪要的多智能体讨论,工程师只在关键决策点出现。
六、总结
Waylens 这次迁移的关键收益,是把 AI Agent 这种新工作负载放进 Kubernetes 已经成熟的工具集里,再用 Admin、Rex 这两个角色把”让 agent 自己运维 agent”落地。声明式配置、滚动升级、RBAC、存储编排都是 EKS 现成的能力,团队不必再为 agent 单独造一套运维流程;升级编排、健康巡检、故障接管这些原本由工程师承担的工作,转由 Admin 和 Rex 自行处理。把 agent 定义成自定义资源之后:
- 升级流程可控且无人值守(Operator 滚动 + Admin canary 编排 + Rex 接管 Admin)
- 权限边界清晰(Pod Identity 给单个 agent 升权;Rex → Admin 单向 backup)
- 数据共享统一(Amazon S3 Files
/shared) - 配置漂移消失(YAML 是唯一事实来源)
- 工程师从”调试平台耗时多于实际使用”回到”只在关键决策点签字”
如果你的团队也在跑多个 AI Agent,并在 EC2 上遇到过”N 台机器 = N 套运维”,或者”调试时间超过使用时间”,可以直接复用 aws-samples/sample-your-opc-eks-agents 这个仓库,使用 Kiro 或其他 AI Coding 工具参考 README 操作约 30 分钟,即可在自己的账号中部署一套同样的平台。
➡️ 下一步行动:
相关产品:
- Amazon EKS — 托管 Kubernetes 集群,支持 Auto Mode 免节点组管理
- Amazon Bedrock — 通过统一 API 访问多种主流大语言模型,支持按需切换
- Amazon S3 Files — 把 Amazon S3 桶以 NFS / POSIX 形态挂进多 Pod 共享读写
- Amazon IAM — Pod 到 IAM Role 的细粒度映射
相关文章:
- Launching S3 Files, making S3 buckets accessible as file systems
- paperclipinc/openclaw-operator
- 基于 Amazon ECS Fargate 和 Graviton 构建企业级多租户 AI Agent 平台:OpenClaw + Hermes 双 Agent 实践
- 如何使用OpenClaw+飞书实现亚马逊云的运维
- 5 分钟拉起、90 秒自愈、成本 1/8——基于 Firecracker microVM 与 Bedrock AgentCore 的生产级多租户 AI Agent 平台 OpenClaw Pool
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
