亚马逊AWS官方博客
新增 – Amazon Connect 和 Amazon Lex 集成
Amazon Connect 和 Amazon Lex 这两项我最喜欢的服务最近推出了一些增强功能,我非常高兴有机会与大家分享这些功能。Amazon Connect 是一项基于云的自助式联络中心服务,可使任何企业能够轻松地以更低成本提供更优质的客户服务。Amazon Lex 是一项使用语音和文本构建对话界面的服务。通过将这两项服务相集成,您可以利用 Lex 的自动语音识别 (ASR) 和自然语言处理 (NLU) 功能为客户打造自助式体验。为了做到这一点,Amazon Lex 团队创建了新的深度学习模型,专门用来识别 8kHz 音频样本中的呼叫中心对话,稍后我将对此进行详细介绍。如果自动程序可以处理 90% 的客户请求,则客户等待时间将会减少,从而有更多时间来使用您的产品。
如需 Amazon Connect 或 Amazon Lex 的更多背景信息,我强烈建议您阅读 Jeff 之前发布的有关这两项服务的帖子 [1][2] (尤其是在您喜欢 LEGO 的情况下)。
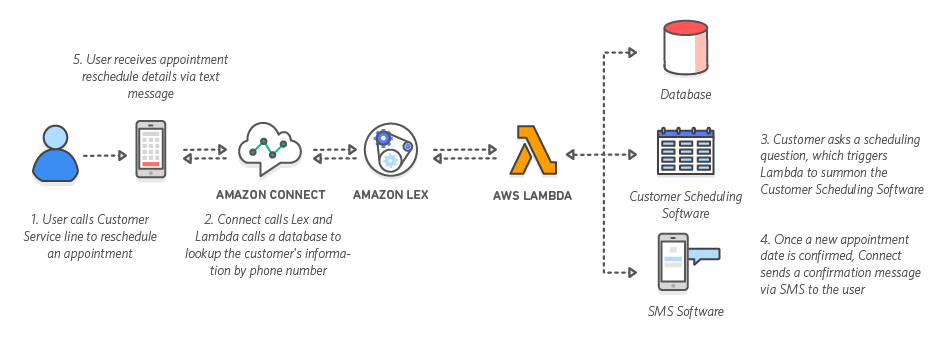
接下来,我将向您展示如何使用这项新集成。大家也许知道,我喜欢在自己的 Twitch 频道上试用这些服务。我会选择一款我们针对 Twitch 频道构建的应用程序,然后针对博客进行修改。在这款应用程序的核心,用户拨打 Amazon Connect 号码后,随即会出现一系列“连锁反应”:将用户连接到 Amazon Lex 自动程序,自动程序调用 AWS Lambda 函数,而函数随后执行一组操作。
我们的应用程序有什么作用呢?我想最终解决哪个代码编辑器最为出色这个问题:我钟爱 Vim,这是一款超赞的编辑器,它的代码编辑功能非常棒 (堪称最好的编辑器)。我的同事 Jeff 偏爱 Emacs,它是一款强大的
操作系统
编辑器…如果您的手指头足够灵活的话。另一名同事 Tara 习惯用 Visual Studio 和 Sublime。究竟哪个才是最佳编辑器?无需为此纠结,我想还是让诸位亲爱的读者来投票吧,不要担心您甚至可以为 butterflies投票。
对投票感兴趣?请拨打 +1 614-569-4019,告诉我们您要为哪款编辑器投票!我们不会存储您的号码,也不记录您的语音,尽管放心投票吧,您可为 Vim 多次投票。想看投票的直播吗? http://best-editor-ever.s3-website-us-east-1.amazonaws.com
现在,我们该如何进行巧妙设计呢?
Amazon Lex
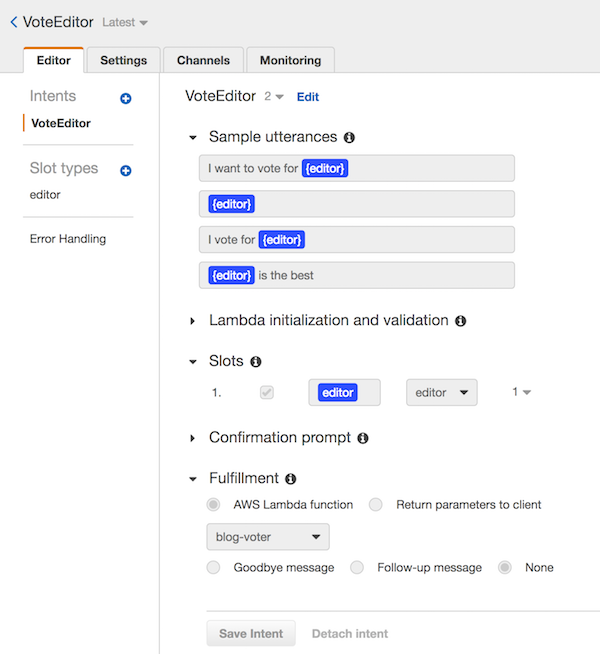
我们先看看 Lex 方面的相关设计吧。创建一个名为 VoteEditor 的自动程序,它具有单个目的 VoteEditor、名为 editor 和 ConnectToAgent的单个槽。我们会将编辑器槽填满不同的代码编辑器名称 (或许不会考虑 Emacs)。
AWS Lambda
我们的 Lambda 函数也非常简单。先创建一个Amazon DynamoDB 表来存储投票信息,然后创建帮助程序方法来响应 Lex (build_response),随后再确定逻辑。我们将使用 Python 这种最优秀的语言在最佳编辑器中进行编写。
基本上,如果我们收到某个编辑器的投票,而该编辑器并不存在,那么我们会添加该编辑器并附上 1 次投票。否则会增加该编辑器的得票数 (每次增加 1 票)。非常简单。
我们会告诉 Lex 自动程序使用 Lambda 函数来实现我们的目的。在执行下一步之前,我们可以测试一切是否能在 Lex 控制台中正常运行。

Amazon Connect
接下来就到了有趣的部分了。将 Lex 自动程序连接到 Connect 联系流,然后开始存储这些结果。
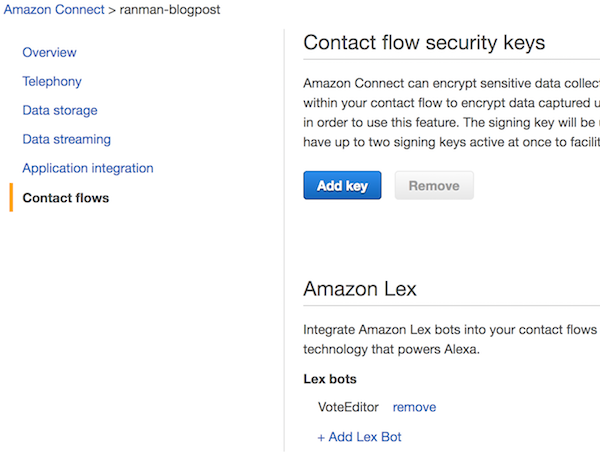
在联系流中使用自动程序之前,必须确保 Amazon Connect 实例拥有对它的访问权限。为此,我们需要转到 Amazon Connect 服务控制台,选择实例,然后导航至联系流。其中应该有一个名为“Amazon Lex”的部分,在那里,您可以添加自己的自动程序!
现在 Connect 实例已经知道 Lex 自动程序可供调用,接下来我们就可以创建包含 Lex 自动程序的新联系流。通过熟悉的“获取客户输入”小部件将自动程序添加到流中,但在单击该小部件时,其中会出现一个新的“Amazon Lex”选项卡。

里面提供有诸多选项,但简单来说,我们要添加使用自动程序的目的、要使用的自动程序版本,以及介绍自动程序的简短提示 (可能会提示客户输入信息)。
我们的最终联系流如下所示:

在真实示例中,系统可能会允许客户通过 Lex 自动程序执行许多事务,然后,根据“Error”或“ConnectToAgent”目的,将客户放入他们可与真人对话的队列中。
在此,我想特别指出教 Lex 理解 8kHz 音频的巨大优势及其如此重要的原因。Lex 最初接受训练时使用的语音模型与电话相比占用较大的带宽信道。当您与 Alexa 或 Lex 自动程序对话时,系统通常会以 16kHz 的最低速率对您发送的文本进行采样。通过这种保真度较高的记录,可更加轻松地识别声音差异,如“ess”(/s/) 和“eff”(/f/),音频专家如是告诉我。如果使用 Alexa,则音频流还会来自我们控制的有限的一些设备,因此,我们确切地知道麦克风发出的声音应是什么样子。但是,电话及其记录的音频依赖由人类植入的一些“卑鄙技巧”。人类及其耳朵非常擅长根据情景来辨识质量较差的录音的内容 (要获取此方面的证据,请参阅 NASA 阿波罗录音)。因此,大多数数字电话系统默认设置为使用 8kHz 采样率 (而非更高采样率),从而使带宽和保真度之间达到了一种较好平衡。这种基本采样率的首要问题是,您还必须应对以下事实:大量电话数据已失真 (您现在能听到我说话吗?)。目前市面上有数百家不同制造商提供的数千种不同设备,以及大量不同的软件实施方案和编解码器。那么,您该如何解决这一识别问题呢?
Lex 团队找出了解决此问题的最佳方法,即,扩展他们用来解析语音输入的模型集,以纳入专为 Connect 集成设计的 8kHz 模型。他们在 8kHz 数据集的真实客户服务呼叫中保留了自己的模型和网络,而且与其传统模型相比,单词识别率提高了 60% 以上。检测各个单词的准确率越高,识别目的的准确率也就越高。团队为此付出了巨大努力,这可让众多客户通过 Connect 执行更多操作。
最后再说明一下,Connect 使用完全相同的 PostContent 终端节点,因此,如果您是外部开发人员,也可使用该节点,而无需通过 Connect 来利用 Lex 中的这项 8kHz 功能。
希望大家都能喜欢这项功能,与往常一样,要了解真实细节,请参阅这些文档、API 参考指南。
– Randall