亚马逊AWS官方博客
新增 – 使用 Amazon SageMaker Ground Truth 标记 3D 点云
Amazon Sagemaker Ground Truth 在 AWS re:Invent 2018 中推出,是 Amazon SageMaker 的一项功能,可用于轻松注释机器学习数据集。客户可以使用内置工作流高效准确地标记图像和文本数据,或使用自定义工作流标记任何其他类型的数据。数据示例将自动分发给工作人员(私人、第三方或 MTurk),且注释会存储在 Amazon Simple Storage Service (S3) 中。或者,还可以启用自动化数据标记,以同时减少标记数据集所需的时间和相关成本。
大约一年前,我曾见过汽车客户,他们表达了标记三维 (3D) 数据集以进行自主驾驶的兴趣。这些数据集由 LIDAR 传感器捕获,特别大,而且复杂。数据存储在通常包含 50000 到 500 万个点的帧中,每一个最多可以达到数百 MB。帧单独存储或按照顺序存储,更加便于跟踪移动物体。
可想而知,标记这些数据集非常耗时,因为工作人员需要导航复杂的 3D 场景并注释很多不同的对象类。这通常需要构建和管理非常复杂的工具。Ground Truth 团队一直在致力于帮助客户构建更简单、更高效的工作流,从而收集更多反馈,然后开始行动。
今天,我非常高兴地宣布您可以使用 Amazon Sagemaker Ground Truth 来通过内置的编辑器和一流的辅助标记功能标记 3D 点云。
介绍 3D 点云标记
与其他的 Ground Truth 任务类型一样,3D 点云的输入数据必须存储在 S3 存储桶中。它还需要通过清单文件进行描述,该文件是一个 JSON 文件,其中包含帧在 S3 中的位置及其属性。数据集可以包含单帧数据或多帧序列。
或者,数据集还可以包含机载摄像机捕获的图像数据。使用称为“传感器融合”的功能,Ground Truth 最多可以使用 8 个摄像机同步 3D 点云。由于这一点,工作人员可以获取场景的真实视图,并且还可以通过互换方式将标签应用至 2D 图像和 3D 点云。
当清单文件准备就绪后,Ground Truth 可让您创建以下任务类型:
- 对象检测:识别 3D 点云帧内的相关对象。
- 对象跟踪:跟踪一序列 3D 点云帧中的相关对象。
- 语义分割:将 3D 点云帧的点分割到预定义类别中。
它们可以是工作人员注释新帧的标记作业,也可以是他们查看和微调现有注释的调整作业。作业可以分发给私人劳动力,也可以分发给您在 AWS Marketplace 中选择的供应商劳动力。
使用内置图形用户界面 (GUI) 及其导航和标记快捷方式,工作人员可以快速准确地将标签、框和类别应用至 3D 对象(“汽车”、“行人”等等)。他们还可以添加用户定义的属性,例如汽车颜色,或者对象是完全可见还是部分可见。
GUI 包括很多辅助标记功能,这些功能可以显著简化标记工作、节省时间并改善注释质量。下面是几个示例:
- 快照:Ground Truth 推断物体周围有一个紧密贴合的框。
- 内插:标记人员在一个序列的第一个和最后一个帧中注释对象。Ground Truth 在中间的帧中自动注释对象。
- 地面检测和删除:Ground Truth 可以从对象框中自动检测和删除属于地面的 3D 点。
即使使用辅助标记,注释复杂的帧和序列也可能需要一段时间,因此,要定期保存工作以免发生任何数据丢失。
准备 3D 点云数据集
如前所述,您必须提供对您的 3D 数据集进行描述的清单文件。此文件的格式在 Ground Truth 文档中进行定义。当然,构建它所需的步骤将根据不同的数据集而不同。例如,Audi A2D2 数据集包含近 400000 个帧,其中有 360 度 3D LIDAR 数据和 2D 图像。KITTI 是自主驾驶研究的另一个常见选择,包括其中含有 15000 个图像及其相应点云的 3D 数据集,共有 80256 个标记对象。此笔记本向您显示如何将 KITTI 数据转换为 Ground Truth 格式。
当数据集中同时包含 3D LIDAR 数据和 2D 摄像机图像时,同步它们成为一大难题。这使我们能够将 3D 点投射到 2D 坐标中,将它们映射到机载摄像机捕获的图片中,反之亦然。另一大挑战是,给定设备捕获的数据使用此设备的本地坐标。幸运的是,我们知道设备位于汽车的哪个位置,以及它指向哪里。这一切都可以通过构建整体坐标系(也称为世界坐标系 [WCS])来解决。使用矩阵运算(我就不细说了),我们可以计算 WCS 内所有数据点的坐标。
当帧处理完毕后,它们的信息将保存在清单文件中:车辆的位置、LIDAR 数据在 S3 中的位置、相关图片在 S3 中的位置等等。对于大型数据集,整个过程会产生大量工作负载,您可以在 Amazon SageMaker Processing、Amazon EMR 或 AWS Glue 等托管服务中运行它。
使用 Amazon SageMaker Ground Truth 标记 3D 点云
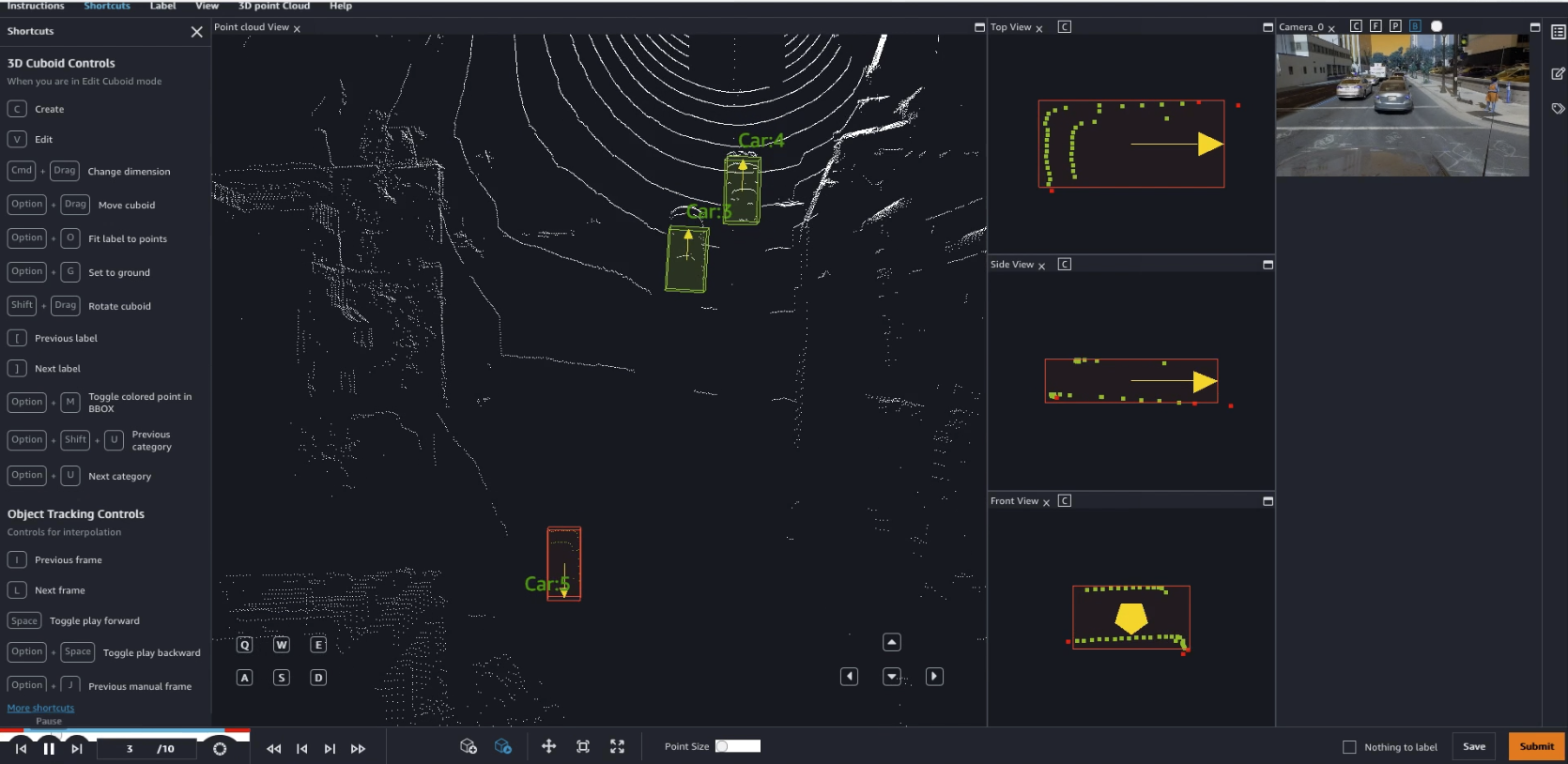
我们来根据此笔记本进行快速演示。从预处理样本帧开始,它简化了为六个任务类型(对象检测、对象跟踪、语义分割和相关的调整任务类型)中的每一个创建 3D 点云标记作业的过程。您可以将自己轻松设置为私人工作人员,并使用工作人员 GUI 及其标记工具开始标记帧。
一张图片胜过千言万语,一段视频更是如此! 在第一个视频中,我使用两个辅助标记功能对几辆车进行了注释。首先,我将框固定到地面上,从而帮助我捕获靠近地面的对象点,而不会实际捕获地面本身。其次,我将框固定在对象上,从而确保紧密贴合,没有任何空白区。

在第二个视频中,我使用相同方法对第三辆车进行注释。它比以前的对象更难“看到”,但我仍然想办法在它周围固定一个紧贴的框。播放接下来的九个帧,我看到这辆车真的在动。直接跳到第十个帧,我将边界框调整到车的新位置。Ground Truth 会自动标记八个中间的帧,称为内插的另一个辅助标记功能。
我在这里仅仅介绍了浅显的部分,还有很多要学习的内容。现在轮到您了!
开始使用
您现在可以在以下区域使用 Amazon Sagemaker Ground Truth 开始标记 3D 点云:
- 美国东部(弗吉尼亚北部)、美国东部(俄亥俄)、美国西部(俄勒冈)、
- 加拿大(中部)、
- 欧洲(爱尔兰)、欧洲(伦敦)、欧洲(法兰克福)、
- 亚太地区(孟买)、亚太地区(新加坡)、亚太地区(首尔)、亚太地区(悉尼)、亚太地区(东京)。
我们期待看到您的反馈。您可以通过您的常用支持联系方式,或者在 Amazon SageMaker 的 AWS 论坛中发送反馈。