亚马逊AWS官方博客
Amazon S3 二十周年:回望初心,共筑未来
二十年前的今天,即 2006 年 3 月 14 日,Amazon Simple Storage Service(Amazon S3)悄然上线。当时仅在最新资讯页面发布了一段简短的公告:
Amazon S3 是面向互联网的存储服务。该服务旨在帮助开发者简化 Web 级计算。Amazon S3 提供简单的 Web 服务接口,可随时随地从 Web 上的任何位置存储和检索任意数量的数据。它使所有开发人员都能访问 Amazon 运行自身全球网站网络的同款高扩展性、高可靠性、快速、低成本的数据存储基础设施。
就连 Jeff Barr 的博客文章也只有短短几段,写在他飞往加州参加开发者大会之前。没有代码示例。没有演示。发布十分低调。当时没人能预料到,这项服务会彻底重塑我们整个行业。
早期岁月:可靠有效的基础组件
从本质上讲,S3 引入了两个简单的原语:PUT 用于存储对象,GET 用于稍后检索对象。但真正的创新在于其背后的理念:创建可处理无差别繁重工作的基础组件,让开发人员腾出时间专注于更高层次的工作。
从诞生第一天起,S3 就坚守五大基本指导原则,至今未变:
安全性:意味着您的数据默认受到保护。持久性:设计为可达到 11 个 9(99.999999999%),使 S3 运行不丢失任何数据。可用性:可用性设计融入每一层,假设硬件随时可能出现故障,必须进行处理。性能:经过优化,几乎可以存储任意数量的数据,而不会降级。弹性:意味着系统会在您添加和删除数据时自动增长和收缩,无需手动干预。
将这些方面做好时,服务就变得非常简单,大多数用户甚至无需思考这些概念有多复杂。
今天的 S3:规模超乎想象
二十年来,尽管 S3 已经发展到了难以想象的规模,仍然始终坚守初心。
S3 首次推出时,在横跨三个数据中心的 15 个机架中的大约 400 个存储节点上提供大约 1 PB 的总存储容量,总带宽为 15 Gbps。我们旨在使系统能够存储数百亿对象,单个对象最大 5GB。初始价格为每 GB 15 美分。
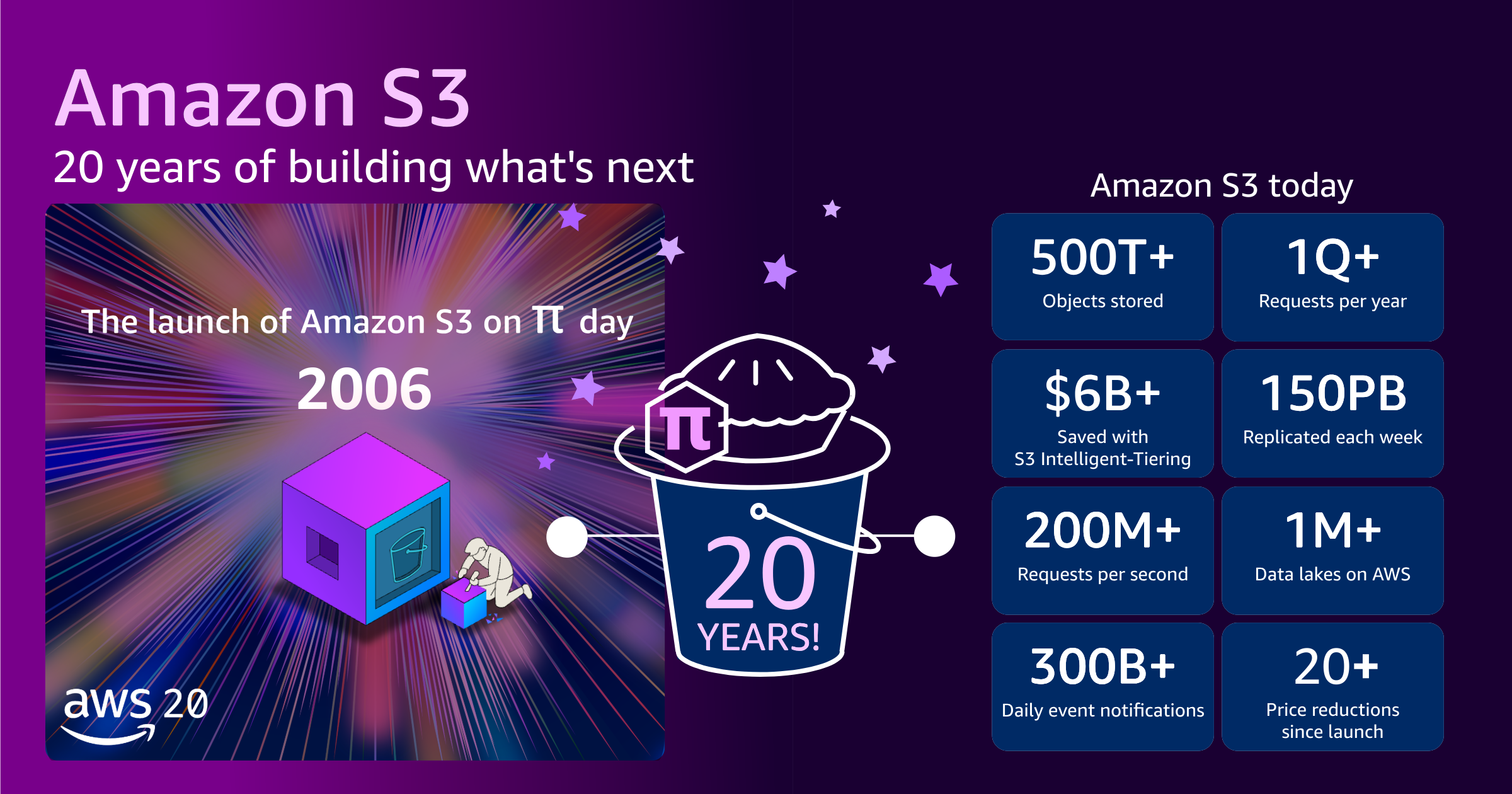
如今,S3 在 39 个 AWS 区域的 123 个可用区为数百万客户存储超过 500 万亿个对象,并通过数百 EB 的数据在全球范围内每秒处理超过 2 亿个请求。最大对象大小已从 5 GB 增加到 50 TB,增长了一万倍。如果把 S3 所用的数千万块硬盘叠起来,高度可以往返国际空间站。
尽管 S3 已经发展到能够支持这种令人难以置信的规模,但您的成本却下降了。目前,AWS 每 GB 的费用仅为 2 美分多一点。自 2006 年推出以来,价格下降了约 85%。同时,我们继续推出通过存储层进一步优化存储支出的方法。例如,与使用 Amazon S3 Standard 相比,使用 Amazon S3 Intelligent-Tiering 已帮助用户累计节省超过 60 亿美元存储成本。
在过去二十年间,S3 API 已被存储行业广泛采纳,并成为行业参考标准。现在,许多供应商都推出了兼容 S3 的存储工具和系统,实施相同的 API 模式和惯例。这意味着为 S3 开发的技能和工具往往可以直接转移到其他存储系统中,使您能够更轻松地访问更广泛的存储环境。
尽管规模与行业普及程度不断提升,但 S3 最令人称道的成就或许是:您在 2006 年为 S3 编写的代码,至今无需任何修改仍可正常运行。您的数据陪伴着行业走过了二十年的创新和技术进步。我们完成了跨多代磁盘和存储系统的基础设施迁移。处理请求的所有代码都已重写。但是,20 年前存储的数据今天仍然可用,而且我们保持了完整的 API 向后兼容性。这就是我们对提供始终“可靠有效”的服务的承诺。
庞大规模背后的工程实力
是什么支持 S3 做到如此规模? 答案是持续的工程创新。
下文内容主要摘自 AWS 数据与分析副总裁 Mai‑Lan Tomsen Bukovec 与 The Pragmatic Engineer 的 Gergely Orosz 之间的对话。如需深入了解技术细节,可阅读完整深度访谈内容。在接下来的段落中,我分享了一些示例:
S3 持久性的核心是一套微服务系统,它会持续巡检整个实例集中的每一字节数据。这些审计服务会仔细分析数据,并在检测到退化迹象时自动触发修复机制。S3 从设计上确保数据零丢失:11 个 9 的持久性目标体现了复制因子和重新复制实例集的规模设计,但该系统是为了避免对象丢失而构建的。
S3 工程师在生产环境中使用形式化方法和自动推理,从数学层面证明系统的正确性。当工程师向索引子系统提交代码时,自动证明机制会验证一致性未受影响。该方法同样用于验证跨区域复制和访问策略的正确性。
过去 8 年间,AWS 逐步使用 Rust 语言重写 S3 请求路径中对性能关键的代码,包括 Blob 迁移和磁盘存储,其他组件的重构工作仍在持续推进。除性能提升外,Rust 的类型系统与内存安全保证能在编译时消除多类错误。对于具有 S3 这种规模和正确性要求的系统而言,这一特性至关重要。
S3 的设计哲学是:“规模即是优势”。 工程师在设计系统时,让规模的增长能够为所有用户带来更好的服务特性。S3 的规模越大,工作负载之间的关联性就越低,从而为所有用户提升可靠性。
展望未来
S3 的愿景已经超越存储服务,延伸为成为所有数据和 AI 工作负载的统一基础。我们的愿景很简单:任何类型的数据只需在 S3 中存储一次,就能直接使用,无需在专用系统之间迁移。这种方法可以降低成本,消除复杂性,并且无需为同一份数据创建多个副本。
以下是近年来发布的几项备受瞩目的功能:
- S3 表类数据存储服务 — 完全托管的 Apache Iceberg 表,具有自动维护功能,可随着时间的推移优化查询效率并降低存储成本。
- S3 Vectors — 用于语义搜索和 RAG 的原生向量存储,每个索引支持多达 20 亿个向量,查询延迟低于 100 毫秒。在短短 5 个月内(2025 年 7 月至 12 月),您创建了超过 25 万个索引,摄取了超过 400 亿个向量,并执行了超过 10 亿次查询。
- S3 元数据 — 用于即时数据发现的集中化元数据,无需对大型存储桶进行递归遍历即可构建目录,从而大幅缩短数据湖的洞察耗时。
这些功能均采用 S3 的成本结构运行。过去需要依赖昂贵数据库或专用系统才能处理的多种数据类型,如今都能以经济高效的方式大规模处理。
从 1PB 到数百 EB;从每 GB 15 美分到 2 美分;从简单的对象存储到 AI 和分析的基础。一路走来,我们的五大基本原则(安全性、持久性、可用性、性能、弹性)始终未变,您在 2006 年编写的代码至今仍可正常运行。
期待 Amazon S3 下一个二十年的创新。