亚马逊AWS官方博客
Category: Amazon Simple Storage Service (S3)

AWS 每周综述:一键 Lambda 设置提示、Bedrock 上的 OpenAI GPT-5.6 模型等(2026 年 7 月 20 日)
一键 Lambda 设置提示、Bedrock 上的 OpenAI GPT-5.6 模型等

AWS 一周综述:纽约峰会回顾、河内 Local Zone、Bedrock 中的 Grok 4.3、降价等(2026 年 6 月 22 日)
纽约峰会回顾、河内 Local Zone、Bedrock 中的 Grok 4.3、降价等
2026 年纽约 AWS Summit 的热门公告
今天在纽约市 AWS Summit 上,AWS 代理式人工智能副总裁 Swami Sivasubramanian 发表了当天的主题演讲。
Amazon S3 注释:将丰富的可查询上下文直接附加到您的对象
今天,我们宣布为 Amazon Simple Storage Service(Amazon S3)推出一项名为“注释”的全新元数据功能,该功能让您可以直接为对象挂载海量、丰富的业务上下文。您最多可以为单个对象存储 1000 个命名注释,单条注释的大小上限为 1MB,单对象注释的总大小最高为 1GB,支持 JSON、XML、YAML、纯文本等多种灵活格式。您可以随时修改、删除注释,无需重写对象,从而轻松实时更新对象上下文。
AWS 一周综述:Amazon Bedrock 中的 Claude Mythos 预览版、AWS 代理注册表等(2026 年 4 月 13 日)
Amazon Bedrock 中的 Claude Mythos 预览版、AWS 代理注册表等

推出 S3 Files:使 S3 存储桶能够以文件系统形式直接访问
Amazon S3 Files 正式推出。这是一款全新的文件系统,能够将任意 AWS 计算资源与 Amazon Simple Storage Service(Amazon S3)无缝连接。
AWS 一周综述:Amazon S3 推出 20 周年、Amazon Route 53 Global Resolver 正式推出等(2026 年 3 月 16 日)
二十年前的上周,Amazon S3 于 2006 年 3 月 14 日公开发布。虽然 Amazon Simple Storage Service 通常被认为是定义云基础设施的基础存储服务,但最初的简单对象存储服务已发展成为范围和规模要大得多的服务。
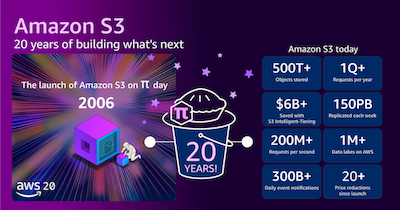
Amazon S3 二十周年:回望初心,共筑未来
二十年前的今天,即 2006 年 3 月 14 日,Amazon Simple Storage Service(Amazon S3)悄然上线。
为 Amazon S3 通用存储桶引入账户区域命名空间
今天,我们宣布推出 Amazon Simple Storage Service(Amazon S3)的一项新功能,您可以使用该功能在自己的账户区域命名空间中创建通用存储桶,从而在数据存储需求规模和范围增长时简化存储桶的创建和管理。您可以跨多个 AWS 区域创建通用存储桶名称,确保所需的存储桶名称始终可供您使用。

适用于 NetApp ONTAP 的 Amazon FSx 现已与 Amazon S3 集成,实现无缝数据访问
今天我们宣布推出通过 Amazon Simple Storage Service(Amazon S3)访问适用于 NetApp ONTAP 的 Amazon FSx 文件系统中数据的功能。借助此功能,您可利用企业文件数据增强生成式人工智能应用,通过 Amazon Bedrock 知识库实现检索增强生成(RAG);运用 Amazon SageMaker 训练机器学习(ML)模型;通过 Amazon S3 集成的第三方服务生成洞察;在 Amazon Quick Suite 等人工智能驱动的商业智能(BI)工具中使用全面研究功能;并基于 Amazon S3 运行云原生应用程序分析。所有这些操作均可在文件数据持续驻留于适用于 NetApp ONTAP 的 FSx 文件系统的同时完成。