亚马逊AWS官方博客
使用AWS Glue在Amazon S3上构建数据湖实战
现状
在实际应用场景中,客户的大数据部门会接到基于不同业务场景的数据分析需求,而大数据部门的痛点常常出现在,这些需求背后的数据往往来自一个个数据孤岛,并没有通过有效的方式打通。数据孤岛的产生可能来源于不同的数据摄入/获取方式,当业务规模不断扩展,业务部分需要不同环节的数据联合起来所产生的分析结果来进一步做业务决策,此时便是数据湖发挥其优势的时刻。数据湖可让组织将所有结构化和非结构化数据存储在一个集中式存储库中,可解决处理海量异构数据的难题。AWS Glue 是一项完全托管的 ETL(提取、转换和加载)服务,使您能够轻松而经济高效地对数据进行分类、清理和扩充,并在各种数据存储和数据流之间可靠地移动数据。此文记录了两类典型数据类型注入以Amazon S3构建的数据湖的过程实战,帮助 Apache Spark 应用程序和 Glue ETL 作业的开发人员、大数据架构师、数据工程师自动扩展在 AWS Glue 上运行的数据处理作业的最佳实践。
概念简介
Glue Data Catalog
AWS Glue Data Catalog 是您在 AWS 云中的持久性技术元数据存储,与 Apache Hive Metastore 兼容。
Glue Crawler
AWS Glue 还能让您设置爬网程序,它可以扫描所有类型的存储库中的数据,对其进行分类,从中提取架构信息,并自动在 AWS Glue Data Catalog中存储元数据。
Glue ETL Jobs
AWS Glue 中有三种类型的作业:Spark、Streaming ETL 和 Python shell,本文以Spark任务为例,以PySpark为代码语言。Spark 任务会在由 AWS Glue 托管的 Apache Spark 环境中执行。
DynamicFrame
DynamicFrame类似于Apache Spark SQL DataFrame ,后者是用于将数据组织到行和列中的数据抽象,不同之处在于每条记录都是自描述的,因此初始化时并不需要任何schema。借助DynamicFrame,您可以获得架构灵活性和一组专为DynamicFrame设计的Function。
解决方案架构总览
 |
方案实战
任务1:在Glue Job中通过Apache Spark DataFrame将S3中的JSON格式数据以Parquet格式注入S3数据湖
透过开源的Spark DataFrame read function直接指定s3路径来做转换。源数据是JSON格式(含有Nested JSON)存储在S3上,其中S3 prefix按年、月、日、小时划分文件夹,业务按分钟级别生成 log.gz 文件,示例: s3://xxxdatalake/json/2022/08/01/01/xxxx.log.gz。
目标数据是按天分区,存储文件格式为Parquet,存放在S3上。
1.1循环读写,Glue ETL Jobs代码片段示例和解析:
从源数据的天目录下循环读取每个小时下的多个log.gz文件到DataFrame, 写到路径为‘dt=年-月-日’路径下存成parquet格式:
1.2处理Nested JSON
Glue ETL Jobs也可以像Apache Spark DataFrame自行定义schema,来确保schema是预期的结构,使用者可根据数据原有格式定义嵌套字段,如’mlbTeam’下含有嵌套字段:
1.3 注意输出的struct 字段的内容
当数据按照1.1的方式写出成parquet格式文件时,后续在使用Glue Crawler来进行表结构的爬取,嵌套部分默认会在对应字段下以struct的格式呈现,struct格式下如有特殊字符如$,会在Athena Query时出现报错,可按需确认相关字段是否为必要字段来做丢弃或者改写。
1.4 处理Glue Job ConcurrenRunExceededException
 |
在测试以及使用Glue Studio 创建的Job时,默认会retry 3次,Maximum Concurrency为1,当我们看到任务失败的时候常常会立刻对Job script做修改后再点击一次运行,此时上次的失败的任务还在重试,便会遇到 ConcurrenRunExceededException。我们可以透过增加 Maximum Concurrency
 |
或者将 number of retry调整成0 来避免此报错:
 |
任务2: : Glue Job结合Glue Data Catalog将S3中的JSON格式数据以Parquet格式注入S3数据湖
在日期多层结构的处理上,对比任务1中的循环读取方式,任务2中我们先使用了Glue Data Catalog来定义好分区信息,就可以在读取的时候一次读取需要的分区,并且后续的DataFrame也会有分区信息。
2.1 使用Glue Crawler创建表后在Glue ETL Job使用Spark sql 读取
对于相同格式的源数据(s3://xxxdatalake/json/2022/08/01/01/xxxx.log.gz)创建Glue Crawler,针对路径s3://xxxdatalake/json/ 做爬取后会在Glue Data Catalog中产出一张表(名为json),此时读取到的数据会有分区信息: 年,月,日,小时,分别映射为partition_0, partition_1, partition_2,partition_3,接下来从Glue ETL Jobs中从Glue Data Catalog来读取数据,:
当数据量较大时,程序里如果需要一次弄数月资料的话, 可以改成写出到S3的时候用partition by,并以分区信息当作键値。此时分区信息在DataFrame中的字段名称是partition_0, partition_1, partition_2:
注意,如果原始路径是Hive Style Naming Conventions 格式,如 (s3://xxxdatalake/json/year=2022/month=08/day=01/), Crawler 的分区字段就从partition_0, partition_1, partition_2变成year, month, day。
2.2 Glue Crawler爬虫程序爬出表结构后的timestamp字段处理
Glue Crawler 遇到时间类型的数据时通常会判断为String或者数字类型。若是此类格式的 “2018-08-15 22:03:25.296” String类型,可以在Athena做Query直接(使用 > 或者<)比较大小,但是无法用更多的时间类型的函数,有时原始数据为Epoch Time, 则在后续Query时,将时间通过epoch和human-readable data做转换后进行比较大小。
当然,进阶做法是在Glue Job中将字段转换成timestamp类型以便在后续的Athena Query中充分利用时间函数。
任务3: 通过JDBC连接将数据注入S3数据湖
3.1 构建网络连通性
客户侧通过JDBC连接获取的数据一般以Amazon RDS或者在Amazon EC2自建关系型数据库或者MPP数据库为主。为保证Glue ETL Job后续的连通性,此处需要先行在AWS Glue Studio – Connectors处创建Connection,为后续Glue Job绑定VPC和安全组资源,以便JDBC数据源侧可以配置从安全组允许对应目标的访问。此Connection也会用在3.2的爬网程序中。
   |
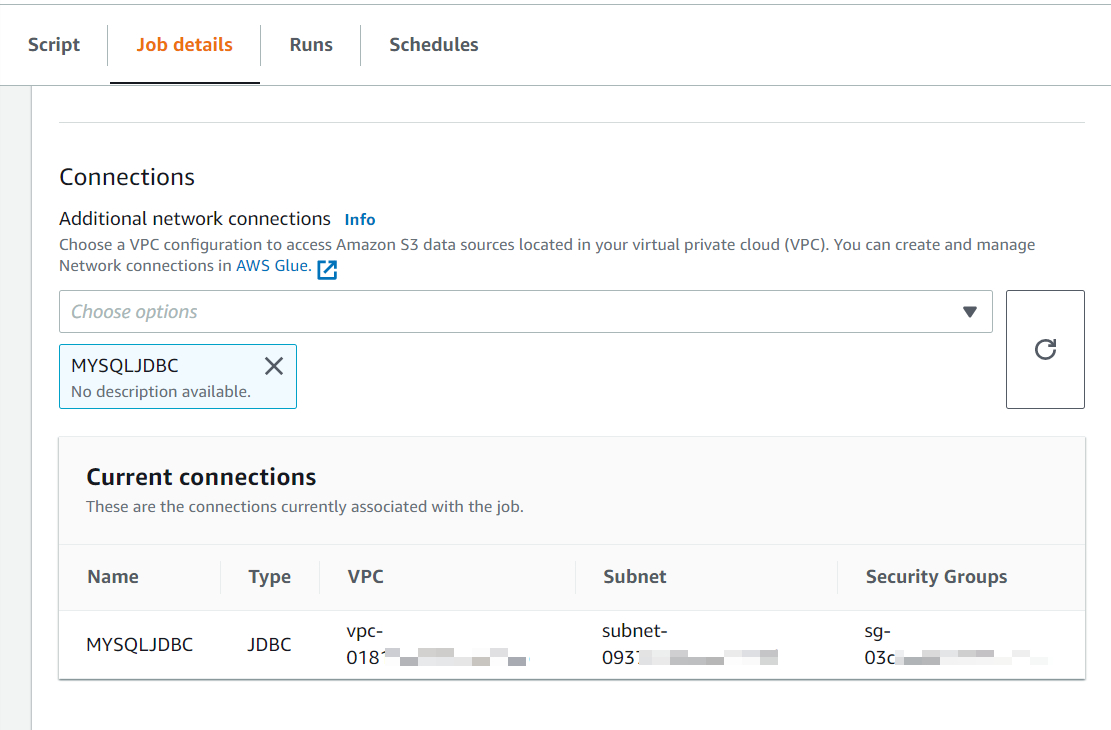
此后3.3创建Glue Job时,可在Jobs Details – Connections处选择上述定义好的Connections。
 |
3.2 Glue Crawler创建爬网程序获取JDBC数据表结构
选择数据源的位置,勾选3.1设置的Connection,其他步骤和创建Glue Crawler爬网程序的步骤一致。
 |
运行Glue Crawler爬网程序之后,在定义好的Glue Data Catalog的Table中会出现JDBC数据源的表结构:
 |
3.3 Glue ETL Job将JDBC数据转换为Parquet数据写入数据湖代码片段和解析
有别于前两个范例,这个任务展示如何用Glue DynamicFrame操作。基于Glue Data Catalog中存储的库和表名,创建DynamicFrame,再创建TempView:
将通过SQL Query出来的目标数据以Parquet格式写到S3中:
3.4读取JDBC数据慢或者Out of memory 问题
在使用JDBC读取Amazon RDS等数据库来源的时候,最常见的问题是读取数据源太久或者读进来之后马上OutOfMemory。这两者其实是类似的问题,因为读取的时候平行度不够,单一Spark task处理太多数据。可以透过指定平行度处理如下:
将 hashfield 设置为 JDBC 表中用于将数据划分为分区的列的名称,此列可以是任何数据类型。 AWS Glue 生成非重叠查询,这些查询并行运行以读取此列分区的数据。将 hashpartitions 设置为 JDBC 表的并行读取数。
总结
此文整体采用无服务器的架构,利用AWS Glue加载并转换应用日志和JDBC数据源,并以目标格式写到以S3构建的数据湖中,该技术可以有效的打通因为不同摄入/获取数据方式形成的数据孤岛,以数据为基石更好的帮助业务部门做业务决策。