- What is Cloud Computing?›
- Cloud Comparisons Hub›
- Storage›
- What’s the Difference Between Block, Object, and File Storage?
What’s the Difference Between Block, Object, and File Storage?
Page topics
- What's the difference between block, object, and file storage?
- What are the similarities between object storage, block storage, and file storage?
- How do object storage, block storage, and file storage work?
- What are the key differences between object storage, block storage, and file storage?
- When should one use object storage, block storage, and file storage?
- Summary of differences: object vs. block vs. file storage
- How can AWS support your object, block, and file storage requirements?
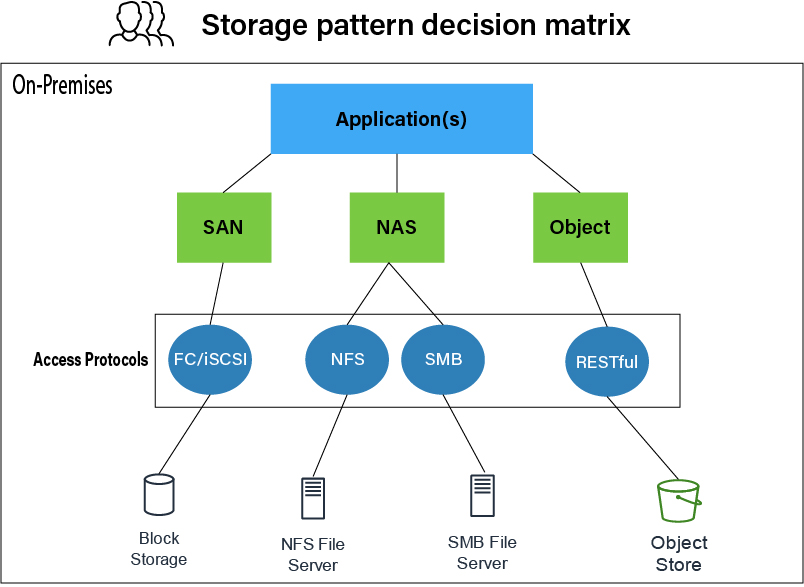
What's the difference between block, object, and file storage?
Block, object, and cloud file storage are three ways of storing data in the cloud so that users and applications can access it remotely over a network connection. Object storage stores and manages all data in an unstructured format and in units called objects. Block storage takes any data, like a file or database entry, and divides it into blocks of equal sizes. It then stores the data block on underlying physical storage in a way that’s optimized for fast access and retrieval. Cloud file storage is another data storage method that provides servers and applications access to data through shared file systems. Each type offers its own unique advantages for various use cases.
What are the similarities between object storage, block storage, and file storage?
Object, block, and file storage are cloud storage services that users and applications can use to store and share data. They have many similarities, which we discuss next.
Availability
Data persistence is the ability of data to remain within a storage system for an extended period. Block, object, and file storage systems provide data availability and reliability through various data persistence mechanisms. For instance, all three use data replication. By storing data in multiple locations, you can access it even if one location fails. All three systems also use checksums and error detection codes to verify data and detect corruption during storage.
Accessibility
You can access all three of these storage systems over a network using APIs. Remote access ensures you can share stored data across multiple users and applications.
Scalability
All three storage types offer scalability, which allows for the storage of large volumes of data. They can accommodate expanding storage needs by adding additional resources or nodes to the storage infrastructure.
Data security
Security features like encryption of data at rest and in transit are supported in all three storage types. They offer measures to protect data confidentiality and integrity, which helps ensure that stored data remains secure.
Metadata management
Cloud file storage, object storage, and block storage systems typically provide ways to manage metadata associated with stored data. Metadata can include attributes like file or object names, sizes, timestamps, and permissions. Metadata facilitates the organization, search, and retrieval of stored data.
How do object storage, block storage, and file storage work?
Object, block, and cloud file storage work differently. They each use distinct structures, systems, and storage solutions.
Object storage
Object storage stores and manages data as discrete units called objects. An object typically consists of the actual data—such as documents, images, or data values— and its associated metadata. Metadata is additional information about the object that you can use to retrieve it. The metadata can include attributes like the unique identifier, object's name, size, creation date, and custom-defined tags.
Object storage systems use a flat namespace, so objects are stored without the need for a hierarchical structure. Instead, the object’s unique identifier provides the address for the object within the storage system. A hashing algorithm generates the ID from the object's content, which ensures that objects with the same content have the same identifier.
Block storage
Block storage works by dividing data into fixed-sized blocks and storing them as individual units. Blocks range from a few kilobytes to several megabytes in size. They can be predetermined during the configuration process.
The operating system gives each block a unique address or block number, logged inside a data lookup table. The addressing uses a logical block addressing (LBA) scheme that assigns a sequential number to each block.
Block storage allows direct access to individual data blocks. You can read or write data to specific blocks without having to retrieve or modify the entire dataset the block belongs to.
Cloud file storage
Cloud file storage is a hierarchical storage system that provides shared access to file data. It uses a remote infrastructure of servers to store data. The cloud provider maintains the servers and manages data on them. Files contain metadata like the file name, size, timestamps, and permissions.
You can create, modify, delete, and read files. You can also organize them logically in directory trees for intuitive access. Multiple users can simultaneously access the same files. Security for online file storage is managed with user and group permissions, so that administrators can control access to the shared file data.
What are the key differences between object storage, block storage, and file storage?
Object storage, block storage, and cloud file storage have some key differences.
File management
Object storage solutions support storage of files as objects. Accessing them with existing applications requires new code, the use of APIs, and direct knowledge of naming semantics.
Similarly, block storage can be used as the underlying storage component of a self-managed file storage solution. However, the one-to-one relationship required between the host and volume makes it difficult to have the scalability, availability, and affordability of a fully managed file storage solution. You require additional budget and management resources to support files on block storage.
Only file-based storage supports common file-level protocols and permissions models. You don’t require new code to integrate with applications configured to work with shared file storage.
Metadata management
Object storage metadata can hold any amount of information about an object. This includes its name, content type, creation date, size, or other custom-defined inputs. By using a flexible metadata schema, you can create additional fields that help you locate data.
Block storage stores as little metadata as possible to maintain high efficiency. A very basic metadata structure ensures minimal overheads during a data transfer. Block storage mainly uses unique identifiers for each block when searching, finding, and retrieving data.
Cloud file storage uses metadata to describe the data that a file holds. You can access and change the metadata that’s attached to files. This function depends on your access. Cloud storage systems using access control lists (ACLs) as permission control of who can access and change metadata.
Performance
Object storage systems prioritize storage quantity over availability. As highly scalable systems, you can store large volume of unstructured data in an object storage system. However, there’s more latency when you access these files. Object storage also has a lower throughput compared to block storage and cloud storage.
Block storage offers high performance, low latency, and quick data transfer rates. As it operates on a block level, you can directly access data and achieve a high I/O performance. You use block storage for applications that need fast access to data you have stored, like a virtual machine or database.
Cloud file storage can offer high performance, but this isn’t the main reason you would use it. Instead, cloud file storage is more about storing data in a manner intuitive for human access. File sharing, collaboration, and shared repositories are more common with cloud file storage than high performance.
Physical storage systems
Object storage normally uses a distributed storage environment across multiple different storage nodes or servers.
On the other hand, block storage uses RAID, SSDs, and hard disk drives (HDDs) for storage.
Finally, cloud file storage uses network-attached storage (NAS) in an on-premises setup. In the cloud, file storage service may be set up over underlying physical block storage.
Read a comparison of SDDs and HDDs »
Scalability
Object storage offers near-infinite scaling, to petabytes and billions of objects.
Block storage offers scalability by adding more storage volumes or expanding existing volumes. Scalability depends on the block storage system's ability to handle increased I/O demands and capacity requirements.
Because of the inherent hierarchy and pathing, file storage hits scaling constraints and is the least scalable of the three.
When should one use object storage, block storage, and file storage?
Object storage is best used for large amounts of unstructured data. This is especially true when durability, unlimited storage, scalability, and complex metadata management are relevant factors for overall performance.
Block storage offers high-speed data processing, low latency, and high-performance storage. Any service that requires fast access to data works well with block storage. For example, real-time analytics, high-performance computing, and systems with many rapid transactions all benefit from block storage.
Cloud file storage is best when users need concurrent access to a shared system of files. Additionally, file-level access control allows you to set up permissions and access control lists (ACLs) to increase security. For example, collaborative work environments that require sharing files between remote teams use file storage.
Summary of differences: object vs. block vs. file storage
|
Object storage |
Block storage |
Cloud file storage |
|
|
File management |
Store files as objects. Accessing files in object storage with existing applications requires new code and the use of APIs. |
Can store files but requires additional budget and management resources to support files on block storage. |
Supports common file-level protocols and permissions models. Usable by applications configured to work with shared file storage. |
|
Metadata management |
Can store unlimited metadata for any object. Define custom metadata fields. |
Uses very little associated metadata. |
Stores limited metadata relevant to files only. |
|
Performance |
Stores unlimited data with minimal latency. |
High-performance, low latency, and rapid data transfer. |
Offers high performance for shared file access. |
|
Physical storage |
Distributed across multiple storage nodes. |
Distributed across SSDs and HDDs. |
On-premises NAS servers or over underlying physical block storage. |
|
Scalability |
Unlimited scale. |
Somewhat limited. |
Somewhat limited. |
How can AWS support your object, block, and file storage requirements?
Amazon Web Services (AWS) has various storage resources to meet your needs.
Amazon Simple Storage Service (Amazon S3) provides unlimited object storage in the cloud. With cost-effective storage classes and easy-to-use management features, you can optimize costs, organize data, and configure fine-tuned access controls to meet specific business, organizational, and compliance requirements.
Amazon Elastic Block Store (Amazon EBS) is an easy-to-use, scalable, high-performance block storage service designed for Amazon Elastic Compute Cloud (Amazon EC2) workloads. It provides a highly scalable storage solution for mission-critical and I/O-intensive applications.
Amazon Elastic File System (Amazon EFS) is a serverless, fully elastic file storage that automatically grows and shrinks as you add and remove files, with no need for management or provisioning.
Amazon FSx makes it easy to launch, run, and scale high-performance, feature-rich file systems in the cloud. It supports workloads with its scalability, broad capabilities, security, and reliability.
Get started with cloud storage on AWS by creating an account today.