- Was ist Cloud Computing?›
- Hub für Konzepte zum Cloud Computing›
- Künstliche Intelligenz
Was ist der Unterschied zwischen Datenwissenschaft und künstlicher Intelligenz?
Was ist der Unterschied zwischen Datenwissenschaft und künstlicher Intelligenz?
Sowohl Datenwissenschaft als auch künstliche Intelligenz (KI) sind Überbegriffe für Methoden und Techniken, die sich auf das Verstehen und Verwenden digitaler Daten beziehen. Moderne Organisationen sammeln Informationen aus einer Reihe von Online- und physischen Systemen zu allen Aspekten des menschlichen Lebens. Wir haben große Mengen an Text-, Ton-, Video- und Bilddaten zur Verfügung. Die Datenwissenschaft kombiniert statistische Werkzeuge, Methoden und Technologien, um aus Daten Bedeutung zu gewinnen. Künstliche Intelligenz geht noch einen Schritt weiter und nutzt die Daten, um kognitive Probleme zu lösen, die üblicherweise mit menschlicher Intelligenz in Verbindung gebracht werden, wie Lernen, Mustererkennung und menschenähnlicher Ausdruck. Es handelt sich um eine Sammlung komplexer Algorithmen, die im Laufe der Zeit „lernen“ und im Laufe der Zeit immer besser darin werden, Probleme zu lösen.
Ähnlichkeiten zwischen Datenwissenschaft und künstlicher Intelligenz
Sowohl KI als auch Datenwissenschaft umfassen Tools, Techniken und Algorithmen zur Analyse und Nutzung großer Datenmengen. Im Folgenden sind einige Ähnlichkeiten aufgeführt.
Prädiktive Anwendungen
Sowohl künstliche Intelligenz als auch datenwissenschaftliche Technologien treffen Vorhersagen auf der Grundlage neuer Daten, als Ergebnis der Anwendung von Modellen und Methoden, die bei der Analyse früherer Daten gelernt wurden. Ein Beispiel für die Analyse von Zeitreihendaten in der Datenwissenschaft ist beispielsweise die Vorhersage zukünftiger monatlicher Umsatzumsätze auf der Grundlage von Daten aus den Vorjahren.
In ähnlicher Weise ist ein selbstfahrendes Auto ein Beispiel für ein prädiktives künstliches Intelligenzsystem. Wenn ein selbstfahrendes Auto unterwegs ist, berechnet es die Entfernung zum vorausfahrenden Auto und die Geschwindigkeit beider Autos. Es hält seine Geschwindigkeit auf einer Geschwindigkeit, die einen Unfall vermeiden würde, basierend auf der Vorhersage des plötzlichen Abbremsens des vorausfahrenden Autos.
Anforderungen an die Datenqualität
Sowohl KI- als auch Datenwissenschafts-Technologien liefern weniger genaue Ergebnisse, wenn die Trainingsdaten inkonsistent, verzerrt oder unvollständig sind. Datenwissenschaft und KI-Algorithmen können beispielsweise:
- Neue Daten herausfiltern, wenn sie völlig neu sind und nicht in ihrem ursprünglichen Datensatz enthalten sind.
- Bestimmte Attribute im Datensatz vor allen anderen priorisieren, wenn die Eingabedaten keine Variation aufweisen.
- Nicht vorhandene oder fiktive Informationen erstellen, da die Eingabedaten falsch waren.
Machine Learning
Machine Learning (ML) wird als Untertyp sowohl der Datenwissenschaft als auch der KI betrachtet. Das bedeutet, dass alle ML-Modelle als Datenwissenschafts-Modelle betrachtet werden und alle ML-Algorithmen auch als KI-Algorithmen betrachtet werden. Es gibt ein weit verbreitetes Missverständnis, dass jede KI ML verwendet, aber das ist nicht der Fall. ML ist in komplexen KI-Lösungen nicht immer erforderlich. Ebenso beinhalten nicht alle Datenwissenschafts-Lösungen ML.
Hauptunterschiede: Datenwissenschaft im Vergleich zu künstlicher Intelligenz
Datenwissenschaft beinhaltet die Analyse von Daten, um zugrunde liegende Muster und interessante Punkte für Vorhersagen zu ermitteln. Die angewandte Datenwissenschaft verwendet die in der Datenanalyse verwendeten Modelle und Methoden und wendet diese auf neue Daten in realen Situationen an, um probabilistische Ergebnisse zu erzielen. Im Gegensatz dazu verwendet KI angewandte datenwissenschaftliche Techniken und andere Algorithmen, um komplexe maschinengestützte Systeme zusammenzustellen und auszuführen, die der menschlichen Intelligenz nahekommen.
Datenwissenschaft kann auch in anderen Anwendungen als KI und Informatik eingesetzt werden.
Ziele
Das Ziel der Datenwissenschaft besteht darin, bestehende statistische und rechnerische Modelle und Methoden anzuwenden, um interessante Punkte oder Muster in gesammelten Daten zu verstehen. Die Ergebnisse sind im Voraus festgelegt und von Anfang an leicht zu definieren. Sie können Daten beispielsweise verwenden, um zukünftige Verkäufe vorherzusagen oder festzustellen, wann eine Maschine zur Reparatur bereit ist.
Das Ziel der KI ist es, mithilfe von Computern aus komplexen neuen Daten ein Ergebnis zu erzielen, das von intelligentem menschlichem Denken nicht zu unterscheiden ist. Die Ergebnisse sind generisch und schwer zu definieren – zum Beispiel das Generieren von kreativem Text oder das Generieren von Bildern aus Text. Die Details des Problemsatzes sind zu umfangreich, um sie genau zu definieren, und das KI-System interpretiert das Problem von selbst.
Umfang
Die Datenwissenschaft hat einen kleineren Umfang, da das Ergebnis im Voraus festgelegt ist. Der Prozess beginnt mit der Identifizierung von Fragen, die anhand von Daten beantwortet werden können. Der Umfang umfasst:
- Datenerfassung und Vorverarbeitung.
- Anwendung geeigneter Modelle und Algorithmen auf die Daten, um diese Fragen zu beantworten.
- Interpretation der Ergebnisse.
Im Gegensatz dazu hat KI einen viel breiteren Anwendungsbereich und die Schritte variieren je nach dem zu lösenden Problem. Der Prozess beginnt mit der Identifizierung einer arbeitsintensiven manuellen Aufgabe oder einer komplexen Denkaufgabe, die Menschen erfolgreich ausführen, und wir möchten, dass die Maschine sie repliziert. Der Geltungsbereich kann Folgendes umfassen:
- Explorative Datenanalyse.
- Unterteilung der Aufgabe in algorithmische Komponenten, um ein System zu bilden.
- Erfassung von Testdaten, um die Eignung des logischen Ablaufs und die Komplexität des Systems zu überprüfen und zu verfeinern.
- Testen des Systems.

Methoden
Die Datenwissenschaft verfügt über eine Vielzahl von Techniken zur Modellierung von Daten. Die Auswahl der richtigen Technik hängt von den Daten und der gestellten Frage ab. Dazu gehören lineare Regression, logistische Regression, Anomalieerkennung, binäre Klassifikation, K-Means-Clustering, Hauptkomponentenanalyse und vieles mehr. Eine falsch angewandte statistische Analyse führt zu unerwarteten Ergebnissen.
KI-Anwendungen basieren in der Regel auf komplexen, vorgefertigten, produktionstechnischen Komponenten. Dazu können Gesichtserkennung, natürliche Sprachverarbeitung, verstärkendes Lernen, Wissensgraphen, generative künstliche Intelligenz (generative KI) und vieles mehr gehören.
Anwendungen: Datenwissenschaft im Vergleich zu künstlicher Intelligenz
Datenwissenschaft kann überall dort angewendet werden, wo es genügend hochwertige Daten und ein Modell gibt, um bei der Beantwortung einer bestimmten Frage zu helfen. Zu den Anwendungen gehören:
- Prognose der Verkaufsnachfrage.
- Betrugserkennung.
- Sportwettenquoten.
- Risikobewertung.
- Prognose des Energieverbrauchs.
- Optimierung des Umsatzes.
- Verfahren zur Überprüfung von Kandidaten.
KI-Anwendungen sind nahezu endlos. Zu den beliebten Anwendungen gehören:
- Robotische Produktionslinien.
- Chatbots.
- Biometrische Erkennungssysteme.
- Medizinische Bildgebungsanalyse.
- Prädiktive Wartung.
- Stadtplanung.
- Personalisierung des Marketings.
Karriere: Datenwissenschaft im Vergleich zu künstlicher Intelligenz
Das Hauptaugenmerk eines Datenwissenschaftlers liegt in der Regel auf technischen Fragen und arbeitet tief in den Daten. Datenwissenschaftler können an der Erfassung und Verarbeitung von Daten arbeiten, die richtigen Modelle für die Daten auswählen und die Ergebnisse interpretieren, um Empfehlungen abzugeben. Die Arbeit kann innerhalb bestimmter Software oder Systeme oder sogar in Buildingsystemen selbst erfolgen.
Arten von Rollen
Zu den Jobs im Bereich Datenwissenschaft gehören Datenwissenschaftler, Datenanalyst, Datentechniker, Techniker für Machine Learning, Forschungswissenschaftler, Spezialist für Datenvisualisierung, fachspezifische Analystenrollen und mehr. KI umfasst auch all diese Rollen. Da das Fachgebiet jedoch so breit gefächert ist, gibt es viele weitere damit verbundene Rollen und Berufsschwerpunkte wie Softwareentwickler, Produktmanager, Marketingspezialist, KI-Tester, KI-Techniker und mehr.
Skillset
Datenwissenschaftler verfügen über Kenntnisse in der praktischen Anwendung statistischer und algorithmischer Methoden zur Qualifizierung und Analyse von Daten, um relevante Erkenntnisse zu gewinnen. Datenwissenschaftler benötigen einen Hintergrund in statistischer Mathematik und Informatik sowie Kenntnisse in den entsprechenden Werkzeugen.
Je nach Rolle im Bereich der künstlichen Intelligenz können die erforderlichen Fähigkeiten eher technischer Natur sein oder auf Soft Skills basieren. In einigen Rollen ist möglicherweise keine technische Erfahrung erforderlich. Zum Beispiel würde ein KI-Softwareentwickler praktische Kenntnisse in relevanten Programmiersprachen, Bibliotheken und Tools benötigen. Ein KI-Tester für ein generatives KI-Tool würde jedoch sprachliche Fähigkeiten, kreatives Denken und Verständnis dafür erfordern, wie Benutzer mit dem System interagieren sollten.
Karriereförderung
Da Datenwissenschafts-Tools und Workflows zunehmend automatisiert und produktbezogen werden, nimmt die Anzahl der rein datenwissenschaftlichen Rollen ab. Datenwissenschaftler, die reine Rollen im Bereich Datenwissenschaft anstreben, neigen zu akademischen und hochmodernen Anwendungen. Analystenrollen, bei denen der Datenwissenschaftler für den Betrieb der Tools verantwortlich ist, bleiben relevant. Von einer jüngeren Position aus nehmen Datenwissenschaftler höhere Positionen ein, wechseln ins Personal- oder Projektmanagement und steigen sogar zum Chief Data Officer auf.
Je nachdem, welchen Schwerpunkt die KI-Rolle selbst einnimmt, sind ähnliche Karrieremöglichkeiten zu erwarten. Sie können daher zum Chief Technology Officer, Chief Marketing Officer, Chief Product Officer usw. aufsteigen. Kritisch darüber nachzudenken, welche Jobs in den nächsten zehn Jahren automatisiert werden, kann dazu beitragen, Ihre berufliche Ausrichtung zukunftssicher zu gestalten.
Zusammenfassung der Unterschiede: Datenwissenschaft im Vergleich zu künstlicher Intelligenz
|
Datenwissenschaft |
Künstliche Intelligenz |
|
|
Wie lautet es? |
Die Verwendung statistischer und algorithmischer Modelle, um Erkenntnisse aus Daten zu gewinnen. |
Ein weit gefasster Begriff für maschinengestützte Anwendungen, die menschliche Intelligenz nachahmen. |
|
Am besten geeignet für |
Beantwortung einer Frage anhand eines Datensatzes. |
Effiziente Erledigung einer komplexen menschlichen Aufgabe. |
|
Methoden |
Lineare Regression, logistische Regression, Anomalieerkennung, binäre Klassifikation, k-Means-Clustering, Hauptkomponentenanalyse und mehr. |
Gesichtserkennung, natürliche Sprachverarbeitung, verstärkendes Lernen, Wissensgraphen, generative KI und mehr. |
|
Umfang |
Vordefinierte Fragen, die anhand der Daten beantwortet werden können. |
Weit gefasst und schwer zu definieren – aufgabenbasiert. |
|
Implementierung |
Verwendet eine Reihe verschiedener Tools, um Daten zu erfassen, zu bereinigen, zu modellieren, zu analysieren und Berichte darüber zu erstellen. |
Aufgabenabhängig. Basiert in der Regel auf komplexen, vorgefertigten, serienreifen Komponenten. |
Wie kann AWS Ihnen bei Ihren Anforderungen an Datenwissenschaft und künstliche Intelligenz helfen?
AWS bietet eine breite Palette von Produkten und Services für Datenwissenschaft und KI, die Ihnen helfen sollen, Ihre organisatorischen und individuellen Datenanalytik und -informationen zu stärken und auszubauen.
Dazu gehören API-basierte Datenwissenschafts- und KI-Modelle für strukturierte und unstrukturierte Daten sowie vollständig verwaltete Umgebungen, die die durchgängige Erstellung und Bereitstellung von Datenwissenschafts- und KI-Lösungen ermöglichen.
- Amazon SageMaker Studio ist eine integrierte Entwicklungsumgebung (IDE), die einen speziell entwickelten Tool-Stack für die Entwicklung von Datenwissenschafts- und ML-Lösungen umfasst.
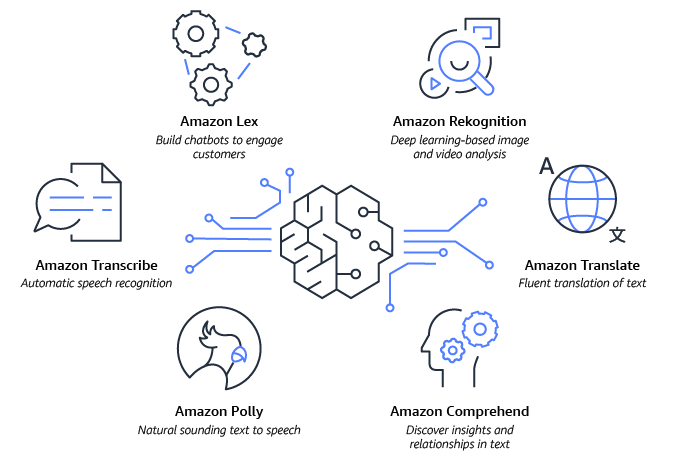
- Amazon Lex hilft Ihnen dabei, Ihre eigenen Chatbots mit dialogorientierter KI zu erstellen.
- Sie können mit Amazon Rekognition vortrainierte und anpassbare Computer-Vision-Funktionen (CV) nutzen, um Informationen und Erkenntnisse aus Ihren Bildern und Videos zu gewinnen.
- Amazon Comprehend hilft Ihnen, wertvolle Erkenntnisse aus Text in Dokumenten abzuleiten und zu verstehen.
- Amazon Personalize nutzt ML, um Ihnen zu helfen, das Kundenerlebnis zu personalisieren.
- Amazon Forecast hilft bei der Durchführung von Zeitreihenprognosen.
- Amazon Fraud Detector hilft Ihnen bei der Erstellung, Bereitstellung und Verwaltung von Betrugserkennungsmodellen.
AWS bietet auch eine wachsende Liste erstklassiger Lösungen mit generativer KI, mit denen neue Inhalte und Ideen erstellt werden können, darunter Konversationen, Geschichten, Bilder, Videos und Musik. Generative KI-Lösungen umfassen:
- Amazon Bedrock unterstützt Unternehmen bei der Entwicklung und Skalierung generativer KI-Lösungen.
- Mit AWS Trainium können generative KI-Modelle schneller trainiert werden.
- Amazon Q Developer ist ein auf generative KI gestützter Assistent für die Softwareentwicklung.
Beginnen Sie mit Datenwissenschaft und künstlicher Intelligenz auf AWS, indem Sie noch heute ein Konto erstellen.