Was ist logistische Regression?
Was ist logistische Regression?
Logistische Regression ist eine Datenanalysetechnik, die mithilfe von Mathematik die Beziehungen zwischen zwei Datenfaktoren ermittelt. Diese Beziehung wird dann verwendet, um den Wert eines dieser Faktoren basierend auf dem anderen vorherzusagen. Die Vorhersage hat normalerweise eine begrenzte Anzahl von Ergebnissen, wie ja oder nein.
Nehmen wir zum Beispiel an, Sie möchten erraten, ob Ihr Website-Besucher in seinem Warenkorb auf die Schaltfläche zur Kasse klickt oder nicht. Die logistische Regressionsanalyse untersucht das Verhalten vergangener Besucher, z. B. die auf der Website verbrachte Zeit und die Anzahl der Artikel im Warenkorb. Es wird festgestellt, dass Besucher, die in der Vergangenheit mehr als fünf Minuten auf der Website verbracht und mehr als drei Artikel in den Warenkorb gelegt haben, auf die Schaltfläche zur Kasse geklickt haben. Anhand dieser Informationen kann die logistische Regressionsfunktion dann das Verhalten eines neuen Website-Besuchers vorhersagen.
Warum ist logistische Regression wichtig?
Die logistische Regression ist eine wichtige Technik im Bereich der künstlichen Intelligenz und des maschinellen Lernens (KI/ML). ML-Modelle sind Softwareprogramme, die Sie trainieren können, um komplexe Datenverarbeitungsaufgaben ohne menschliches Eingreifen auszuführen. ML-Modelle, die mithilfe der logistischen Regression erstellt wurden, helfen Unternehmen, umsetzbare Erkenntnisse aus ihren Geschäftsdaten zu gewinnen. Sie können diese Erkenntnisse für prädiktive Analysen nutzen, um Betriebskosten zu senken, die Effizienz zu steigern und schneller zu skalieren. Unternehmen können beispielsweise Muster aufdecken, die die Mitarbeiterbindung verbessern oder zu einem profitableren Produktdesign führen.
Im Folgenden listen wir einige Vorteile der Verwendung der logistischen Regression gegenüber anderen ML-Techniken auf.
Einfachheit
Logistische Regressionsmodelle sind mathematisch weniger komplex als andere ML-Methoden. Daher können Sie sie auch dann implementieren, wenn niemand in Ihrem Team über fundierte ML-Kenntnisse verfügt.
Geschwindigkeit
Logistische Regressionsmodelle können große Datenmengen mit hoher Geschwindigkeit verarbeiten, da sie weniger Rechenkapazität, wie Speicher und Rechenleistung, benötigen. Dies macht sie ideal für Organisationen, die mit ML-Projekten beginnen, um schnelle Gewinne zu erzielen.
Flexibilität
Sie können die logistische Regression verwenden, um Antworten auf Fragen zu finden, die zwei oder mehr endliche Ergebnisse haben. Sie können es auch zur Vorbearbeitung von Daten verwenden. Beispielsweise können Sie Daten mit einem großen Wertebereich, wie Banktransaktionen, mithilfe der logistischen Regression in einen kleineren, endlichen Wertebereich sortieren. Sie können diesen kleineren Datensatz dann verarbeiten, indem Sie andere ML-Techniken für eine genauere Analyse verwenden.
Sichtbarkeit
Die logistische Regressionsanalyse gibt Entwicklern einen besseren Einblick in interne Softwareprozesse als andere Datenanalysetechniken. Fehlersuche und Fehlerkorrektur sind ebenfalls einfacher, da die Berechnungen weniger komplex sind.
Was sind die Anwendungen der logistischen Regression?
Die logistische Regression hat mehrere reale Anwendungen in vielen verschiedenen Branchen.
Herstellung
Fertigungsunternehmen verwenden logistische Regressionsanalysen, um die Wahrscheinlichkeit eines Teileausfalls in Maschinen einzuschätzen. Anschließend planen sie Wartungspläne auf der Grundlage dieser Schätzung, um zukünftige Ausfälle zu minimieren.
Gesundheitswesen
Medizinische Forscher planen die Vorsorge und Behandlung, indem sie die Wahrscheinlichkeit einer Erkrankung bei Patienten vorhersagen. Sie verwenden logistische Regressionsmodelle, um die Auswirkungen von Familienanamnese oder Genen auf Krankheiten zu vergleichen.
Finanzen
Finanzunternehmen müssen Finanztransaktionen auf Betrug analysieren und Kreditanträge und Versicherungsanträge auf Risiken prüfen. Diese Probleme eignen sich für ein logistisches Regressionsmodell, da sie diskrete Ergebnisse wie hohes Risiko oder geringes Risiko und betrügerisch oder nicht betrügerisch haben.
Marketing
Online-Werbetools verwenden das logistische Regressionsmodell, um vorherzusagen, ob Nutzer auf eine Anzeige klicken. Auf diese Weise können Vermarkter die Reaktionen der Nutzer auf verschiedene Wörter und Bilder analysieren und leistungsstarke Anzeigen erstellen, mit denen sich Kunden beschäftigen.
Wie funktioniert die Regressionsanalyse?
Die logistische Regression ist eine von mehreren verschiedenen Regressionsanalysetechniken, die Datenwissenschaftler häufig beim Machine Learning (ML) verwenden. Um die logistische Regression zu verstehen, müssen wir zunächst die grundlegende Regressionsanalyse verstehen. Im Folgenden zeigen wir anhand eines Beispiels einer linearen Regressionsanalyse, wie die Regressionsanalyse funktioniert.
Identifizieren Sie die Frage
Jede Datenanalyse beginnt mit einer Geschäftsfrage. Für die logistische Regression sollten Sie die Frage formulieren, um bestimmte Ergebnisse zu erzielen:
- Beeinflussen Regentage unseren monatlichen Umsatz? (ja oder nein)
- Welche Art von Kreditkartenaktivitäten führt der Kunde aus? (autorisiert, betrügerisch oder potenziell betrügerisch)
Sammeln Sie historische Daten
Nachdem Sie die Frage identifiziert haben, müssen Sie die beteiligten Datenfaktoren identifizieren. Sie sammeln dann vergangene Daten für alle Faktoren. Um beispielsweise die erste oben aufgeführte Frage zu beantworten, könnten Sie die Anzahl der Regentage und Ihre monatlichen Verkaufsdaten für jeden Monat in den letzten drei Jahren erfassen.
Trainieren Sie das Regressionsanalysemodell
Sie verarbeiten die historischen Daten mit einer Regressionssoftware. Die Software verarbeitet die verschiedenen Datenpunkte und verbindet sie mithilfe von Gleichungen mathematisch. Wenn die Anzahl der Regressionstage für drei Monate beispielsweise 3, 5 und 8 beträgt und die Anzahl der Verkäufe in diesen Monaten 8, 12 und 18 beträgt, verbindet der Regressionsalgorithmus die Faktoren mit der Gleichung:
Anzahl der Verkäufe = 2 x (Anzahl der Regentage) + 2
Treffen Sie Vorhersagen für unbekannte Werte
Bei unbekannten Werten verwendet die Software die Gleichung, um eine Vorhersage zu treffen. Wenn Sie wissen, dass es im Juli sechs Tage lang regnen wird, schätzt die Software den Verkaufswert für Juli auf 14.
Wie funktioniert das logistische Regressionsmodell?
Um das logistische Regressionsmodell zu verstehen, sollten wir zunächst Gleichungen und Variablen verstehen.
Gleichungen
In der Mathematik geben Gleichungen die Beziehung zwischen zwei Variablen an: x und y. Sie können diese Gleichungen oder Funktionen verwenden, um ein Diagramm entlang der X- und Y-Achse darzustellen, indem Sie verschiedene Werte für x und y eingeben. Wenn Sie beispielsweise den Graphen für die Funktion y = 2 x x darstellen, erhalten Sie eine gerade Linie, wie unten gezeigt. Daher wird diese Funktion auch als lineare Funktion bezeichnet.
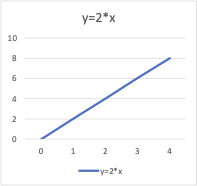
Variablen
In der Statistik sind Variablen die Datenfaktoren oder Attribute, deren Werte variieren. Für jede Analyse sind bestimmte Variablen unabhängige oder erklärende Variablen. Diese Eigenschaften sind die Ursache für ein Ergebnis. Andere Variablen sind abhängige Variablen oder Antwortvariablen; ihre Werte hängen von den unabhängigen Variablen ab. Im Allgemeinen untersucht die logistische Regression, wie sich unabhängige Variablen auf eine abhängige Variable auswirken, indem historische Datenwerte beider Variablen betrachtet werden.
In unserem obigen Beispiel wird x als unabhängige Variable, Prädiktorvariable oder erklärende Variable bezeichnet, da sie einen bekannten Wert hat. Y wird als abhängige Variable, Ergebnisvariable oder Antwortvariable bezeichnet, da ihr Wert unbekannt ist.
Logistische Regressionsfunktion
Logistische Regression ist ein statistisches Modell, das die logistische Funktion oder Logit-Funktion in der Mathematik als Gleichung zwischen x und y verwendet. Die logit-Funktion bildet y als Sigmoidfunktion von x ab.
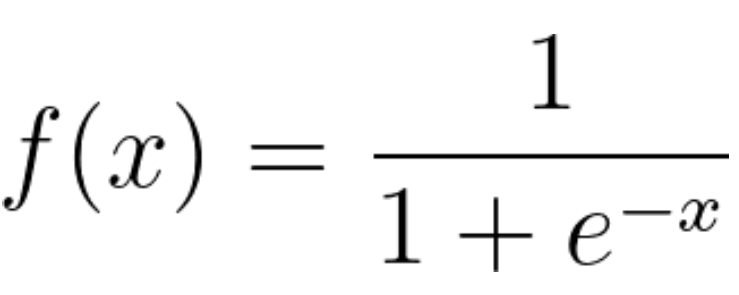
Wenn Sie diese logistische Regressionsgleichung darstellen, erhalten Sie eine S-Kurve, wie unten gezeigt.
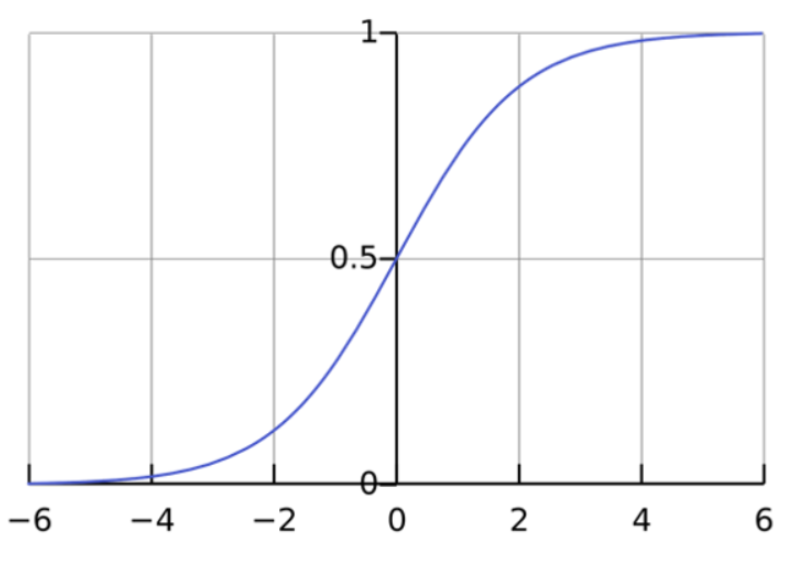
Wie Sie sehen können, gibt die logit-Funktion nur Werte zwischen 0 und 1 für die abhängige Variable zurück, unabhängig von den Werten der unabhängigen Variablen. Auf diese Weise schätzt die logistische Regression den Wert der abhängigen Variablen. Logistische Regressionsmethoden modellieren auch Gleichungen zwischen mehreren unabhängigen Variablen und einer abhängigen Variablen.
Logistische Regressionsanalyse mit mehreren unabhängigen Variablen
In vielen Fällen wirken sich mehrere erklärende Variablen auf den Wert der abhängigen Variablen aus. Um solche Eingabe-Datensätze zu modellieren, gehen logistische Regressionsformeln von einer linearen Beziehung zwischen den verschiedenen unabhängigen Variablen aus. Sie können die Sigmoid-Funktion ändern und die endgültige Ausgabevariable wie folgt berechnen
y = f(β0 + β1x1 + β2x2+… βnxn)
Das Symbol β steht für den Regressionskoeffizienten. Das Logit-Modell kann diese Koeffizientenwerte umkehren, wenn Sie ihm einen ausreichend großen experimentellen Datensatz mit bekannten Werten sowohl abhängiger als auch unabhängiger Variablen geben.
P-Quoten
Das Logit-Modell kann auch das Verhältnis von Erfolg zu Misserfolg oder Log-Quote bestimmen. Wenn Sie zum Beispiel mit Ihren Freunden Poker gespielt haben und vier von zehn Spielen gewonnen haben, sind Ihre Gewinnchancen vier Sechstel oder vier von sechs, was dem Verhältnis von Erfolg zu Misserfolg entspricht. Die Gewinnwahrscheinlichkeit liegt dagegen bei vier von zehn Punkten.
Mathematisch gesehen sind Ihre Chancen in Bezug auf die Wahrscheinlichkeit p/(1 - p) und Ihre Log-Quoten sind log (p/(1 - p)). Sie können die logistische Funktion wie unten gezeigt als Log-Quoten darstellen:
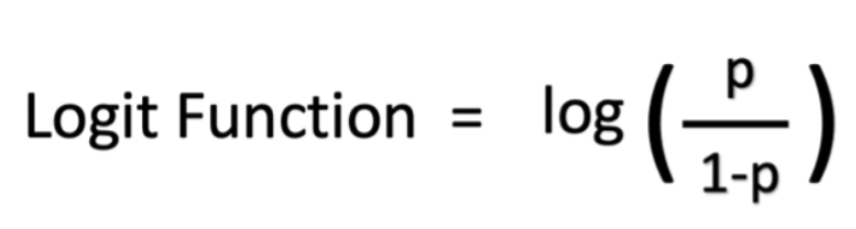
Was sind die Arten der logistischen Regressionsanalyse?
Es gibt drei Ansätze für die logistische Regressionsanalyse, die auf den Ergebnissen der abhängigen Variablen basieren.
Binäre logistische Regression
Die binäre logistische Regression eignet sich gut für binäre Klassifizierungsprobleme, die nur zwei mögliche Ergebnisse haben. Die abhängige Variable kann nur zwei Werte haben, wie Ja und Nein oder 0 und 1.
Obwohl die logistische Funktion einen Wertebereich zwischen 0 und 1 berechnet, rundet das binäre Regressionsmodell die Antwort auf die nächstgelegenen Werte. Im Allgemeinen werden Antworten unter 0,5 auf 0 gerundet, und Antworten über 0,5 werden auf 1 gerundet, sodass die Logistikfunktion ein binäres Ergebnis zurückgibt.
Multinomiale logistische Regression
Die multinomiale Regression kann Probleme analysieren, die mehrere mögliche Folgen haben, solange die Anzahl der Ergebnisse begrenzt ist. Beispielsweise kann es basierend auf Bevölkerungsdaten vorhersagen, ob die Immobilienpreise um 25 %, 50 %, 75 % oder 100 % steigen werden, aber es kann nicht den genauen Wert eines Hauses vorhersagen.
Die multinomiale logistische Regression funktioniert, indem Ergebniswerte verschiedenen Werten zwischen 0 und 1 zugeordnet werden. Da die logistische Funktion einen Bereich kontinuierlicher Daten wie 0,1, 0,11, 0,12 usw. zurückgeben kann, gruppiert die multinomiale Regression die Ausgabe auch auf die nächstmöglichen Werte.
Ordinale logistische Regression
Die ordinale logistische Regression oder das geordnete Logit-Modell ist eine spezielle Art der multinomialen Regression für Probleme, bei denen Zahlen eher Ränge als tatsächliche Werte darstellen. Sie können beispielsweise die ordinale Regression verwenden, um die Antwort auf eine Umfragefrage vorherzusagen, in der Kunden aufgefordert werden, Ihren Service anhand eines numerischen Werts, z. B. der Anzahl der Artikel, die sie im Laufe des Jahres bei Ihnen kaufen, als schlecht, fair, gut oder ausgezeichnet einzustufen.
Wie ist die logistische Regression im Vergleich zu anderen ML-Techniken?
Die beiden gängigen Datenanalysetechniken sind lineare Regressionsanalyse und Deep Learning.
Lineare Regressionsanalyse
Wie oben erläutert, modelliert die lineare Regression die Beziehung zwischen abhängigen und unabhängigen Variablen unter Verwendung einer linearen Kombination. Die lineare Regressionsgleichung lautet
y = β0X0+ β1X1+ β 2X2+... β nXn+ ε, wobei β1 bis βn und ε Regressionskoeffizienten sind.
Logistische Regression gegenüber linearer Regression
Die lineare Regression prognostiziert eine stetige abhängige Variable unter Verwendung eines bestimmten Satzes unabhängiger Variablen. Eine stetige Variable kann einen Wertebereich haben, wie Preis oder Alter. Die lineare Regression kann also tatsächliche Werte der abhängigen Variablen vorhersagen. Es kann Fragen beantworten wie „Wie hoch wird der Preis für Reis nach 10 Jahren sein?“
Im Gegensatz zur linearen Regression ist die logistische Regression ein Klassifizierungsalgorithmus. Es kann keine tatsächlichen Werte für kontinuierliche Daten vorhersagen. Es kann Fragen beantworten wie „Wird der Reispreis in 10 Jahren um 50 % steigen?“
Deep Learning
Deep Learning nutzt neuronale Netzwerke oder Software-Komponenten, die das menschliche Gehirn simulieren, um Informationen zu analysieren. Deep-Learning-Berechnungen basieren auf dem mathematischen Konzept der Vektoren.
Logistische Regression gegenüber Deep Learning
Die logistische Regression ist weniger komplex und weniger rechenintensiv als Deep Learning. Noch wichtiger ist, dass Deep-Learning-Berechnungen von Entwicklern aufgrund ihrer komplexen, maschinengesteuerten Natur nicht untersucht oder geändert werden können. Auf der anderen Seite sind logistische Regressionsberechnungen transparent und lassen sich leichter beheben.
Wie können Sie eine logistische Regressionsanalyse in AWS ausführen?
Sie können die logistische Regression auf AWS mithilfe von Amazon SageMaker ausführen. SageMaker ist ein vollständig verwalteter Service für Machine Learning (ML) mit integrierten Algorithmen für lineare Regression und logistische Regression, neben mehreren anderen statistischen Softwarepaketen.
- Jeder Datenwissenschaftler kann SageMaker verwenden, um logistische Regressionsmodelle schnell vorzubereiten, zu erstellen, zu trainieren und bereitzustellen.
- SageMaker nimmt Ihnen bei jedem Schritt des logistischen Regressionsprozesses die Arbeit ab, um die Entwicklung hochwertiger Modelle zu erleichtern.
- SageMaker bietet alle Komponenten, die Sie für die logistische Regression benötigen, in einem einzigen Werkzeugsatz, sodass Sie Modelle schneller, einfacher und kostengünstiger in die Produktion bringen können.
Beginnen Sie mit der logistischen Regression, indem Sie noch heute ein AWS-Konto erstellen.
Nächste Schritte mit AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages