Blog de Amazon Web Services (AWS)
Frávega redujo en un ~ 52% el costo operativo de sus instancias de bases de datos en AWS
Por Pablo Tilotta, líder de DataOps, Frávega; Adrián Diaz, Technical Account Manager, AWS; Leandro Santi, Arquitecto de Soluciones, AWS.
Frávega es una compañía líder en la venta de electrodomésticos y tecnología de origen argentino. Fundada en 1910, cuenta con más de 116 años de vida y es la única cadena con presencia física en 23 provincias a través de sus más de 100 sucursales. A lo largo de ese tiempo, ha evolucionado desde la venta de artículos para el hogar hasta convertirse en un referente en la comercialización de productos electrónicos y artículos tecnológicos.
Frávega Tech (FT) es el equipo que impulsa la transformación digital de Frávega. Tiene como misión diseñar productos digitales simples, escalables y resilientes, que resuelvan los desafíos de negocio en un ambiente altamente competitivo y en constante evolución. Tiene a su cargo el desarrollo y mantenimiento de los productos de comercio electrónico, logística, pagos, posventa, fintech y marketplace.
Actualmente Frávega Tech opera +2.500 bases de datos distribuidas entre sus centros de datos on-prem, la nube de Oracle (OCI), Mongo Atlas, GCP y AWS. Hacia febrero de 2025 la empresa encomendó al equipo de DataOps la tarea de optimizar su ecosistema de bases de datos relacionales y documentales en AWS, buscando mejorar la experiencia del usuario final y la eficiencia de la plataforma sin impactar en la continuidad operativa del negocio.
En este blog te invitamos a recorrer el enfoque elegido por Frávega para resolver exitosamente este desafío y su impacto positivo en la operación de tecnología de la empresa.
Enfoque para consolidar bases de datos a gran escala en AWS
El objetivo del proyecto apuntó a completar la consolidación de las bases distribuidas en 2 organizaciones de AWS entre junio y diciembre de 2025.
En líneas generales, esto implicó identificar decenas de clusters, desarrollar herramientas específicas o custom para soportar el proceso de consolidación, diseñar y ejecutar los procesos de validación, pruebas y migración de los datos. Como resultado, se buscó normalizar los datos dentro de una arquitectura basada en verticales de negocio consolidando bases y recursos.
A lo largo de este proyecto fue fundamental asumir un enfoque holístico para el rol de DataOps, es decir: desarrollar código robusto y eficiente para minimizar errores humanos, especialmente en tareas manuales que involucren muchos pasos.
El soporte de tecnología elegido por Frávega incluyó entre sus principales herramientas Kiro, Amazon Aurora, Amazon Relational Database Service (RDS), Amazon DocumentDB y CloudWatch Database Insights. Adicionalmente, el equipo de Enterprise Support de AWS brindó apoyo técnico a lo largo de todo el proyecto.
Revisiones estratégicas de negocio
El proceso de Revisiones Estratégicas de Negocio o Strategic Business Reviews (SBR), es una práctica de mejora continua que el equipo de Enterprise Support de AWS lleva adelante junto a clientes como Frávega. Esta actividad está orientada a realizar regularmente un análisis de salud de los sistemas críticos de negocio, y evaluar el progreso de los objetivos definidos en el Plan Estratégico de Soporte o Strategic Support Plan (SSP).
La cadencia de las SBRs se determina según las necesidades de cada cliente (típicamente de manera semestral) incluyendo aspectos de gobierno, gestión de costos, seguridad y otros pilares que resulten relevantes a los objetivos de negocio de la organización.
Entre noviembre de 2024 y noviembre de 2025, los equipos de Enterprise Support y Frávega Tech realizaron múltiples revisiones o SBRs. A modo de ejemplo en la figura 1 podemos ver un consolidado de oportunidades de mejora que pueden ser identificadas a lo largo del proceso.
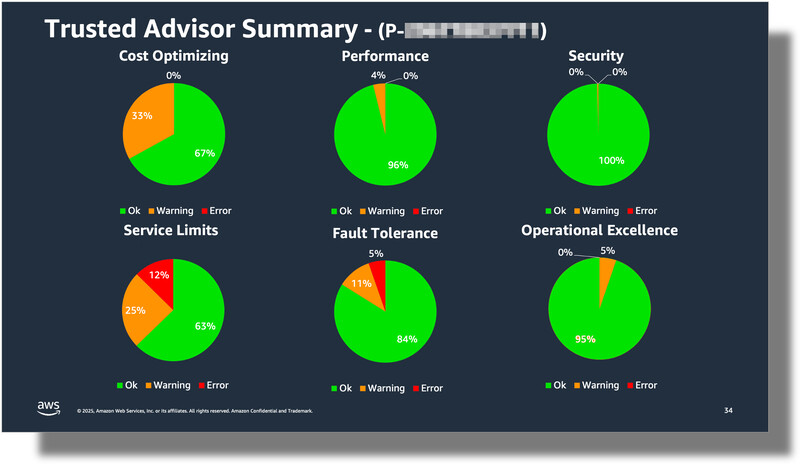
Figura 1: ejemplo de recomendaciones de Trusted Advisor agrupadas por unidades funcionales
En el caso específico de Frávega, dichos SBRs fueron enfocados en análisis e identificación de oportunidades de optimización para la plataforma (correspondientes al pilar de optimización de costos). De esta forma, la ejecución del SBR permitió generar un listado detallado de recomendaciones a ejecutar durante la ventana de tiempo del ejercicio.
Típicamente, las recomendaciones relacionadas con optimización de costos incluyen la conformación o renovación de planes de ahorro o savings plans, evaluación de instancias reservadas, evaluación del uso y cobertura de estos, realización de revisiones de arquitectura o Well-Architected Reviews, etc.
Como veremos en el apartado resultados (más abajo) la ejecución de las recomendaciones del SBR combinada con el acompañamiento técnico permitió a Frávega concretar en tiempo y forma la consolidación del parque de bases de datos, como así también mejorar el desempeño y resiliencia de sus datos.
Kiro-CLI como agente de automatización para DataOps
El equipo de DataOps decidió adoptar tempranamente Kiro como asistencia principal a las tareas operativas del proceso de consolidación de bases de datos. Kiro es un agente de inteligencia artificial que permite resolver problemas de todo tipo, que van desde el diseño y prototipado de soluciones, desarrollo de aplicaciones, implementación, troubleshooting, y tareas operativas de sistemas en la nube.
Kiro facilita que los equipos de ingeniería puedan acceder a herramientas avanzadas de desarrollo asistido por agentes. Por ejemplo, soporta desde su lanzamiento hacia mediados de 2025 la metodología de desarrollo denominada spec-driven development. Esencialmente, puede ayudar a cerrar la brecha entre la intención original y las especificaciones detalladas para construir código que funcione correctamente (ejemplo: “quiero implementar una integración con webhooks con exponential backoff para reintentos ante fallas en la entrega”).
El enfoque agéntico de Kiro permite configurar asistentes específicos para cada tarea a realizar, por ejemplo, para asistir en el proceso de migración el equipo de DataOps configuró en Kiro un asistente especializado en tareas de DevOps y administración de bases de datos (DBA).
El equipo de DataOps configuró el agente de DBA de Kiro en la terminal de comandos (Kiro-CLI) para incorporar herramientas que le permitieron realizar su tarea de manera más efectiva. En este caso, el equipo configuró conectores específicos para diferentes tipos de tecnologías de base de datos. Sumado a las herramientas nativas provistas en el asistente, esto facilitó una gestión más ágil de bases de datos Oracle (OCI/on-prem), Informix, SQL Server (on-prem), MongoDB (Atlas), MySQL y PostgreSQL.
En la figura 2 podemos ver un ejemplo práctico aplicado durante el proyecto de consolidación. Aquí, un colaborador del equipo de DataOps de Frávega instruye al agente para que se conecte a cada uno de los clusters de RDS e identifique problemas de desempeño en los últimos 30 días de operación: variaciones de latencia, cantidad de conexiones, parámetros de configuración, carga de la base de datos, uso de CPU y memoria.
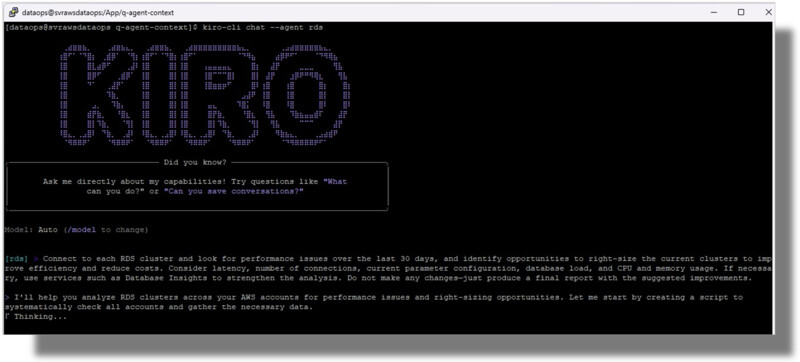
Figura 2: identificación de oportunidades de rightsizing de bases de datos asistidas por Kiro
Para llevar adelante esta tarea, en cuestión de segundos el asistente de DataOps arma un plan de trabajo que incluye enumerar los clusters de bases de datos e iterar para cada uno de ellos analizando las métricas de desempeño disponibles en CloudWatch Database Insights.
El conjunto de métricas de desempeño disponibles en CloudWatch es variado y depende del servicio de base de datos involucrado. Por ejemplo, Amazon Aurora por defecto envía métricas de uso de CPU, memoria, entrada/salida (I/O) tanto a nivel instancia como clúster, red, consultas SQL, desempeño de transacciones, replicación, etc.
Estas métricas son enviadas automáticamente, por defecto, hacia CloudWatch. Para mayor profundidad, se pueden activar métricas de nivel de sistema operativo (OS) y a nivel consultas con la opción Enhanced Monitoring. Para mayor información, consultar aquí.
Para más información sobre capacidades de observabilidad específicas para performance en Amazon Aurora y Amazon RDS, visitar el blog: “Increase visibility of performance and events on Amazon RDS and Amazon Aurora”.
Para cada uno de los clusters RDS bajo análisis, el agente de Kiro para DataOps genera una recomendación como se muestra en la figura 3. En este caso, el análisis de métricas de desempeño arrojó una recomendación de reducción de la capacidad de procesamiento o downsizing. Como puede verse en la figura, dicha recomendación fue generada a partir de 3.600 mediciones individuales que permitieron al agente diagnosticar el tamaño de la infraestructura, identificar capacidad ociosa y realizar la recomendación de optimización.

Figura 3: ejemplo: rightsizing/downsizing de Aurora PostgreSQL asistido por Kiro. El agente de inteligencia artificial revisa 3.600 métricas de desempeño para diagnosticar el sizing actual de la infraestructura y recomendar una reducción en la cantidad de recursos de procesamiento y memoria de la base de datos
Adopción a escala de Amazon Aurora
Para incrementar los niveles de resiliencia y tolerancia a fallas, Frávega decidió desplegar Amazon Aurora a escala, como principal tecnología de base de datos para llevar adelante el proceso de consolidación.
Amazon Aurora (o simplemente Aurora) es un motor de base de datos relacional completamente administrado compatible con MySQL y PostgreSQL, diseñado para ofrecer características de rendimiento y disponibilidad de bases de datos comerciales con prestaciones avanzadas, al precio de una base de datos de código abierto.
La compatibilidad nativa de Aurora con MySQL y PostgreSQL permitió transformar decenas de simples instancias de Postgres o MySQL en clusters de Aurora sin que esto impacte en los aplicativos de negocio y procesos conectados a estas bases de datos. Asimismo permitió incrementar el rendimiento y disponibilidad de los datos, como veremos a continuación.
En la figura 4 podemos ver la arquitectura de referencia para Amazon Aurora. Esta arquitectura ofrece tolerancia a errores por diseño: cuando los datos son escritos en la instancia primaria de la base de datos, la base de datos replica sincrónicamente la información hacia 6 nodos que componen el clúster de almacenamiento de la base de datos. Estos 6 nodos se encuentran distribuidos en tres grupos de datacenters o zonas de disponibilidad (availability zones o AZs, en inglés).
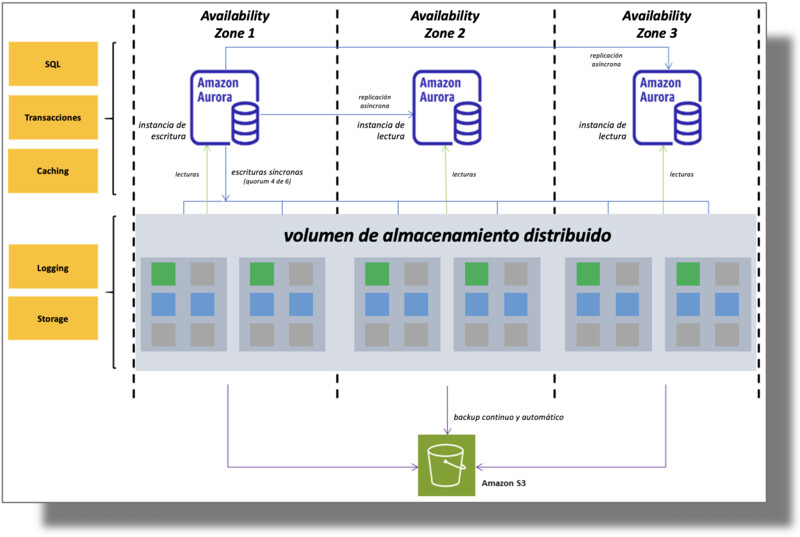
Figura 4: arquitectura de clúster de base de datos de Amazon Aurora
Así, el despliegue a escala de Aurora permite incrementar la redundancia de los datos, eliminar bloqueos o demoras por I/O y reducir picos de latencia durante operaciones de backup. Si se produce un error en la instancia principal de un clúster de base de datos, Aurora conmuta automáticamente a una nueva instancia principal, ya sea promoviendo una réplica de Aurora ya existente a nueva instancia principal o creando una nueva instancia.
Para más información sobre las características de alta disponibilidad de Amazon Aurora, visite la guía del usuario de Amazon Aurora y el blog: “Amazon Aurora under the hood: quorums and correlated failure”.
Adopción a escala de Graviton 4
AWS Graviton son procesadores desarrollados por AWS específicamente para clientes que necesiten mejorar la relación precio/performance de sus cargas de trabajo. Los procesadores Graviton, basados en la arquitectura ARM de 64 bits, son soportados por distribuciones del sistema operativo Linux y aplicaciones y servicios tanto de AWS como desarrolladores independientes de software o independent software vendors (ISVs).
AWS provee una amplia selección de tipos de instancias basadas en Graviton para diferentes casos de uso. Esto comprende múltiples combinaciones de CPU, memoria, almacenamiento y red, otorgando mayor flexibilidad para que el usuario pueda configurar la combinación apropiada de recursos para el caso de uso específico. Típicamente, esto permite a clientes de AWS incrementar en hasta un 40% la relación precio/performance relativa a procesadores actuales con arquitecturas de tipo x86 a lo largo de un amplio espectro de cargas de trabajo.
Impacto del pasaje a Graviton 4 en el servicio de gestión de contenidos. En la figura 5 podemos ver un ejemplo aplicado a la operación de negocios de Frávega. El gestor de contenidos o content management system (CMS) es un sistema usado en la empresa para administrar información relativa a los productos que se ofrecen a la venta en el catálogo online. Aquí es donde vive el contenido de la ficha de producto, que es replicada mediante integraciones a todo el frente de e-commerce de Frávega.
Mantener acotada la latencia de acceso a la ficha de producto permite a Frávega asegurar una buena experiencia de compra dentro de la aplicación de comercio electrónico. La figura 5 muestra la representación de la serie de tiempos del tiempo de acceso (latencia) en milisegundos a la base DocumentDB del CMS.
En particular, observamos que el motor original (basado en una arquitectura x86) promediaba unos 243,92 milisegundos de latencia P99. En la mitad inferior de la figura podemos ver que el pasaje del motor de base de datos a Graviton 4 (abajo) permitió reducir esa métrica en un ~ 80% (unas 5 veces), promediando los 50 milisegundos de latencia P99.
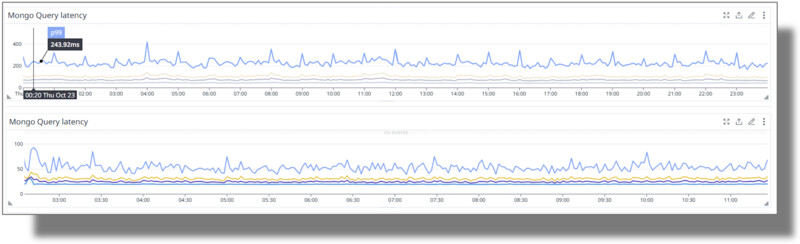
Figura 5: latencia del gestor de contenidos de la ficha de productos de Frávega. El pasaje del motor DocumentDB a Graviton 4 permitió reducir la latencia de lectura P99 unas ~ 5 veces, pasando de 243,92ms (arriba) a unos ~ 50ms (abajo)
El pasaje del CMS –servicio crítico para la operación de Frávega– tuvo una mejora inédita en la latencia P99 al migrar a Graviton. Adicionalmente, este cambio facilitó reducir el tamaño de la instancia en 2 niveles (es decir, reducir 4 veces la cantidad de recursos de cómputo/memoria), con el consiguiente ahorro de costos a la vez que se incrementó la carga en el motor de base de datos.
NB: Frávega realizó la respectiva reserva de la instancia de base de datos a posteriori, es decir, luego de esta operación de rightsizing. Para casos en los cuales existiese una instancia reservada de Amazon RDS, sugerimos visitar este link. Asimismo visite el blog “Introducing Database Savings Plans for AWS Databases” para una introducción a database savings plans.
Resultados
La etapa de consolidación del proyecto tomó en total ~ 3 meses (agosto a noviembre). Durante este período los equipos de Frávega aplicaron a plena escala todos los recursos que fueron previamente identificados durante la etapa de análisis del proyecto:
Adopción a escala de procesadores Graviton 4 con arquitectura ARM de 64 bits específicamente diseñada por AWS para cargas de trabajo de bases de datos, big-data y analítica, aplicaciones web y microservicios entre otras.
Conformación/renovación de instancias reservadas para Amazon Aurora en línea con las recomendaciones identificadas en las revisiones estratégicas de negocio (SBRs) desarrolladas por el equipo de Enterprise Support de AWS.
Implementación de las recomendaciones de rightsizing con asistencia de agentes de IA en Kiro-CLI y CloudWatch Database Insights para identificar familia y tamaño de instancia correcta para cada motor de base de datos, usando métricas disponibles en CloudWatch para una correcta toma de decisiones basada en datos operacionales.
Consolidación a escala de datos operativos y de negocio en AWS, usando arquitecturas multi-AZ como la que provee Amazon Aurora para incrementar la disponibilidad y resiliencia de la granja completa de motores de base de datos productivos.
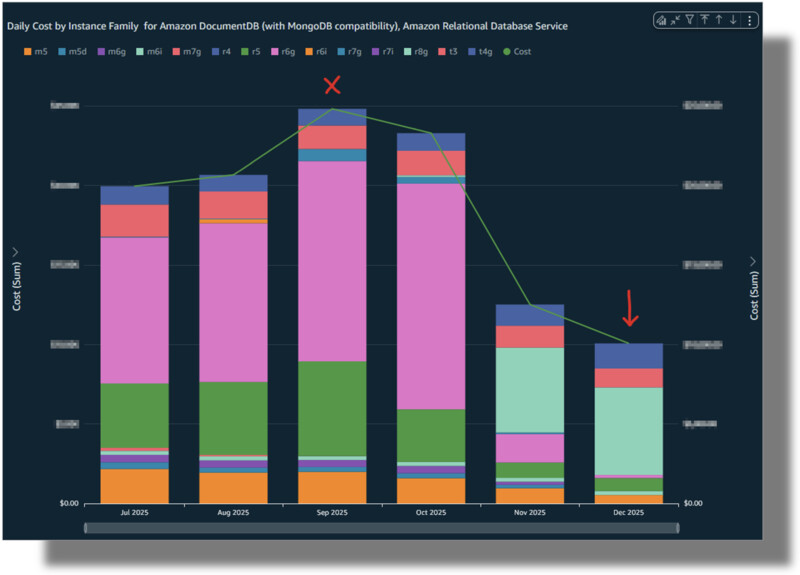
Figura 6: vista financiera de la etapa de consolidación de bases de datos en AWS. El diagrama muestra el consumo mensual de bases de datos relacionales y documentales, logrando una reducción de ~ 52%
La figura 6 muestra el efecto combinado de las acciones de consolidación y reducción de costos. Hacia el mes de diciembre, Frávega logró una reducción de ~ 41% para los costos ligados a tecnologías relacionales y de un ~ 70% para bases de datos documentales. Combinadas, esto representa una reducción total de ~ 52% en el costo operativo de base de datos.
Asimismo se logró un incremento en el desempeño gracias a la reducción de 3x en el uso de CPU y hasta un ~ 80% en la latencia de acceso a motores de bases de datos relacionales que soportan procesos críticos de tiempo real para la operación de negocios de la empresa.
Finalmente, se logró incrementar la resiliencia operativa de todo el parque productivo de bases de datos gracias a la implementación de arquitecturas multi-AZ en AWS.
Conclusiones
En este blog hemos recorrido el camino y el enfoque elegido por Frávega para consolidar una importante porción de su parque de bases de datos en AWS, partiendo desde una plataforma de más de 2.500 bases de datos relacionales y documentales dispersas entre centros de datos y proveedores de servicios de nube.
El proyecto fue realizado de punta a punta entre febrero y diciembre de 2025, permitiendo capitalizar reducciones combinadas de ~ 52% en los costos operativos de bases de datos relacionales y documentales.
Esta iniciativa permitió además mejorar el desempeño y resiliencia de los sistemas y aplicativos relacionados. Esto incluye una reducción de hasta 3 veces en tiempo de procesamiento de CPU y hasta un ~ 80% en los tiempos de respuesta (latencia) que soportan procesos críticos de tiempo real para la operación de negocios. Asimismo, la consolidación en una nueva arquitectura de datos multi-AZ permitió incrementar la resiliencia operativa de todo el parque productivo de bases de datos.
La combinación de tecnologías de AWS –Kiro-CLI, CloudWatch Database Insights, instancias Graviton 4 para Amazon Aurora y DocumentDB– junto con herramientas de automatización desarrolladas por el equipo de DataOps permitió a Frávega consolidar gran parte del parque de bases de datos a escala en tiempo y forma.
El acompañamiento permanente del equipo de Enterprise Support de AWS permitió reducir el riesgo operativo del proceso de consolidación para el negocio, colaborando con Frávega en el planeamiento proactivo, herramientas y mejores prácticas, ayudando a validar los resultados a través de actividades como Strategic Business Reviews (SBRs).
Próximos pasos
Frávega se encuentra en vías de realizar su próxima iteración del SBR. Entre otras cosas, el foco para 2026+ estará en evaluar las nuevas instancias Graviton 5 (actualmente en preview), Database Savings Plans e incrementar el nivel de automatización a través de sus agentes de Kiro.
Sobre los autores
 |
Pablo Tilotta es líder de DataOps en el equipo de la gerencia de infraestructura e ingeniería cloud, Frávega Tech. |
 |
Adrián Diaz es Technical Account Manager en el equipo de Enterprise Support de AWS. |
 |
Leandro Santi es Arquitecto de Soluciones en AWS. |