AWS Compute Blog
Implementing Serverless Video Subtitles
This post is courtesy of Maxime Thomas, DevOps Partner Solutions Architect – AWS
This story begins when I joined AWS at the beginning of the year. I had a hard time during my ramp-up period trying to handle the amount of information coming from all directions. Technical training, meetings, new colleagues, in a worldwide company—the volume of information was overwhelming. However, my first priority was to get my AWS Certified Solutions Architect — Professional certification. This gave me plenty of opportunities to learn and focus on all of the new domains I had never heard about.
This intensive self-paced training quickly gave me a way to get experience. I was opening the AWS Management Console, diving deep into the service documentation, and comparing to my own experience and understanding of production constraints. I wasn’t disappointed by the scope of the platform and its various capabilities.
However, as a native French speaker, I struggled a bit because all of the training videos were in English. Okay, it’s not a problem when you speak another language for 20 minutes a day, but 6 hours every day was exhausting. (It did help me to learn the language faster.) I looked at all of those training videos, and I thought: It would be so much easier if they had French subtitles!
But they didn’t. I continued my deep dive into the serverless world, which led me to another consideration: It would be cool to have a service that could generate subtitles from a video in any language.
Wait–the AWS platform has everything we need to do that!

Video: Playing a video after subtitle generation
I mean, what is the process of translation when you watch a video? It’s basically the following:
- Listen
- Extract the information
- Translate
Proof of concept
I decided to focus on this subject to understand how I could build that kind of system. My pitch was this: The system can receive a video input, extract the audio track, transcribe it, and generate different subtitle files for your video. Since AWS re:Invent 2017, AWS has announced several services that helped me with my proof of concept:
- Listen: I could extract the audio from the video using Amazon Elastic Transcoder
- Extract: I could convert the audio to text using Amazon Transcribe
- Translate: I could achieve fast, high-quality language translation with Amazon Translate
Finally, the way to define subtitles has been specified by the World Wide Web Consortium under the WebVTT format, providing a simple way to produce subtitles for online videos.
I proved the concept in barely 20 minutes with a video file, an Amazon S3 bucket, some AWS IAM roles, and access to the beta versions of the different services. It was going to work, so I decided to transform it into a demo project.
Solution
The fun part of this project was doing it in a serverless way using AWS Lambda and AWS Step Functions. I could have developed it in other ways, but I eliminated them quickly: a custom code base on Amazon EC2 would take too long to code and was excessive computation for what I needed; a container with the code base on Amazon Elastic Container Service would be better, but still was overkill from a compute perspective.
So, Lambda was the solution of choice for compute. Step Functions would take care of coordinating the workflow of the application and the different Lambda functions, so I didn’t need to build that logic into the functions themselves. I split the solution into two parts:
- The backend processes an MP4 file and outputs the same file plus WebVTT files for each language
- The frontend provides a web interface to submit the video and render the result in a fancy way
The following image shows the solution’s architecture.
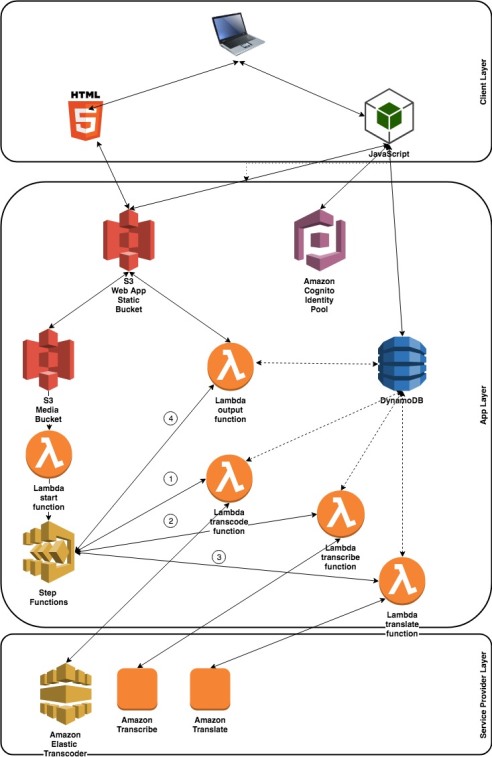
Backend
The solution consists of a Step Functions state machine that executes the following sequence triggered by an Amazon S3 event notification:
- Transcode the file with Elastic Transcoder using its API.
- Wait two minutes, which is enough time for transcoding.
- Submit the file to Amazon Transcribe and enter the following loop:
- Wait for 30 seconds.
- Check the API to know if transcription is over. If it is, go to step 4; otherwise, go back to step 3.1.
- Process the transcript to become a VTT file, which goes to Amazon Translate several times to get a version of the file in another language.
- Clean and wrap up.
The following image shows this sequence as a Step Functions state machine.

The power of Step Functions appears in the integration of such a sequence. You can set up different Lambda functions at each stage of the sequence, put them in parallel if you need to, and handle errors with a retry and fallback. Everything is declarative in the JSON that defines the state machine. The input object that the state machine evaluates between each transition is the one that you provide at the first call. You can enrich it as the state machine executes and gathers more information at later steps.
For instance, if you pass a JSON object as input, it goes through all the way through, and each step can add information that wasn’t there at the beginning of the workflow. This is useful when your decision tree is creating elements and you need to refer to it in other steps.
I also set up an Amazon DynamoDB table to store the state of each file for further processing on the front end.
Frontend
The front end’s setup is easy: an Amazon S3 bucket with the static website feature on and a combination of HTML, AWS SDK for JavaScript in the Browser, and a JavaScript framework to handle calls to the AWS Platform. The sequence has the following steps:
- Load HTML, CSS, and JavaScript from a bucket in Amazon S3.
- Specific JavaScript for this project does the following:
- Sets up the AWS SDK
- Connects to Amazon Cognito against a predefined identity pool set up for anonymous users
- Loads a custom IAM role that gives access to an Amazon S3 bucket
- The user uploads an MP4 file to the bucket, and the backend process starts.
- A JavaScript loop checks the DynamoDB table where the state of the process is stored and do the following:
- Add a description of the video process and show the state of the process.
- Update the progress bar in the description block to inform the user what the process is doing
- Update the video links when the process is over.
- When the process completes, the user can choose the list item to get an HTML5 video player with the VTT files loaded.
{kind=link}
Considerations
Keep the following points in mind:
- This isn’t a production solution. Don’t use it as is.
- The solution is designed for videos where a person speaks clearly. I tried with non- native English-speaking people, and results are poor at the moment.
- The solution is adapted for videos without background noise or music. I checked with different types of videos (movie scenes, music videos, and ads), and results are poor.
- Processing time depends on the length of the original video.
- The frontend check is basic. Improve it by implementing WebSockets to avoid polling from the browser, which it doesn’t scale.
What’s next?
Feel free to try out the code yourself and customize it for your own needs! This project is open source. To download the project files, see Serverless Subtitles on the AWSLabs GitHub website. Feel free to contribute (Pull Requests only).