AWS News Blog
New – Auto Scaling for Amazon DynamoDB
Amazon DynamoDB has more than one hundred thousand customers, spanning a wide range of industries and use cases. These customers depend on DynamoDB’s consistent performance at any scale and presence in 16 geographic regions around the world. A recent trend we’ve been observing is customers using DynamoDB to power their serverless applications. This is a good match: with DynamoDB, you don’t have to think about things like provisioning servers, performing OS and database software patching, or configuring replication across availability zones to ensure high availability – you can simply create tables and start adding data, and let DynamoDB handle the rest.
DynamoDB provides a provisioned capacity model that lets you set the amount of read and write capacity required by your applications. While this frees you from thinking about servers and enables you to change provisioning for your table with a simple API call or button click in the AWS Management Console, customers have asked us how we can make managing capacity for DynamoDB even easier.
Today we are introducing Auto Scaling for DynamoDB to help automate capacity management for your tables and global secondary indexes. You simply specify the desired target utilization and provide upper and lower bounds for read and write capacity. DynamoDB will then monitor throughput consumption using Amazon CloudWatch alarms and then will adjust provisioned capacity up or down as needed. Auto Scaling will be on by default for all new tables and indexes, and you can also configure it for existing ones.
Even if you’re not around, DynamoDB Auto Scaling will be monitoring your tables and indexes to automatically adjust throughput in response to changes in application traffic. This can make it easier to administer your DynamoDB data, help you maximize availability for your applications, and help you reduce your DynamoDB costs.
Let’s see how it works…
Using Auto Scaling
The DynamoDB Console now proposes a comfortable set of default parameters when you create a new table. You can accept them as-is or you can uncheck Use default settings and enter your own parameters:
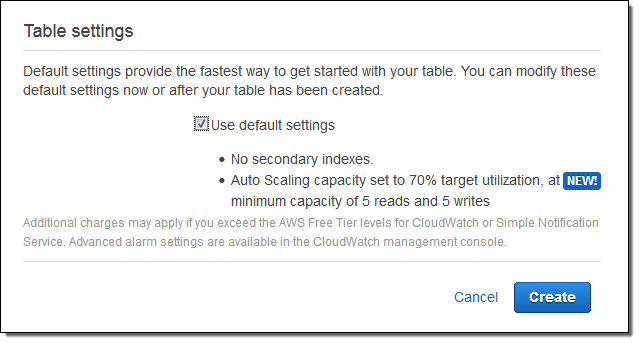
Here’s how you enter your own parameters:
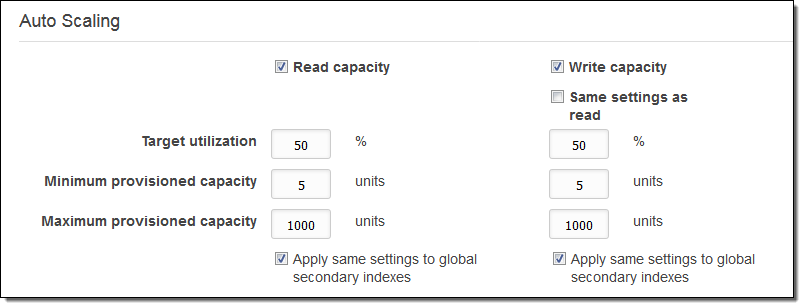
Target utilization is expressed in terms of the ratio of consumed capacity to provisioned capacity. The parameters above would allow for sufficient headroom to allow consumed capacity to double due to a burst in read or write requests (read Capacity Unit Calculations to learn more about the relationship between DynamoDB read and write operations and provisioned capacity). Changes in provisioned capacity take place in the background.
Auto Scaling in Action
In order to see this important new feature in action, I followed the directions in the Getting Started Guide. I launched a fresh EC2 instance, installed (sudo pip install boto3) and configured (aws configure) the AWS SDK for Python. Then I used the code in the Python and DynamoDB section to create and populate a table with some data, and manually configured the table for 5 units each of read and write capacity.
I took a quick break in order to have clean, straight lines for the CloudWatch metrics so that I could show the effect of Auto Scaling. Here’s what the metrics look like before I started to apply a load:
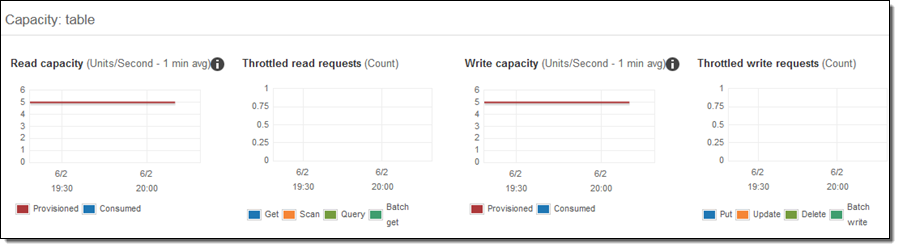
I modified the code in Step 3 to continually issue queries for random years in the range of 1920 to 2007, ran a single copy of the code, and checked the read metrics a minute or two later:
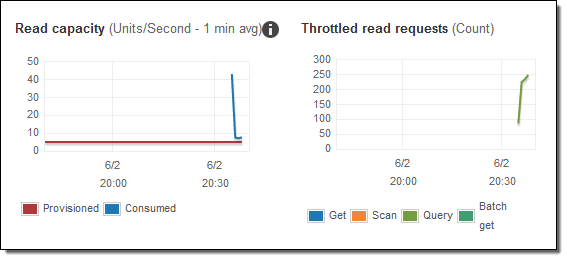
The consumed capacity is higher than the provisioned capacity, resulting in a large number of throttled reads. Time for Auto Scaling!
I returned to the console and clicked on the Capacity tab for my table. Then I clicked on Read capacity, accepted the default values, and clicked on Save:
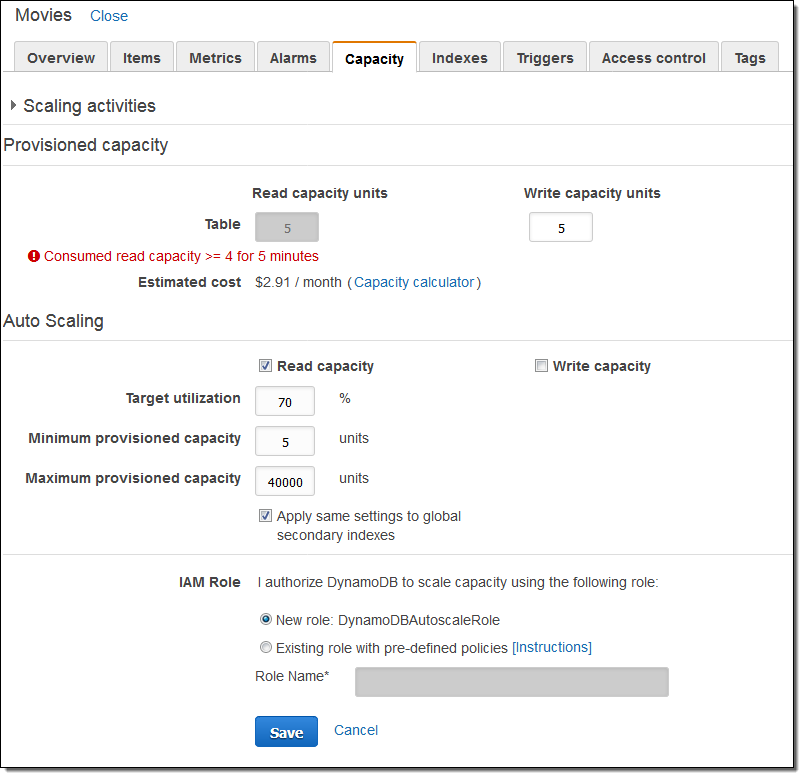
DynamoDB created a new IAM role (DynamoDBAutoscaleRole) and a pair of CloudWatch alarms to manage the Auto Scaling of read capacity:
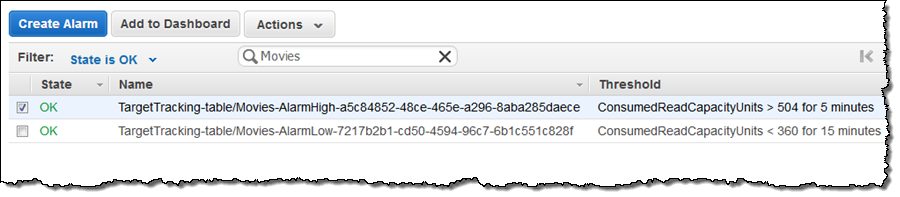
DynamoDB Auto Scaling will manage the thresholds for the alarms, moving them up and down as part of the scaling process. The first alarm was triggered and the table state changed to Updating while additional read capacity was provisioned:
The change was visible in the read metrics within minutes:
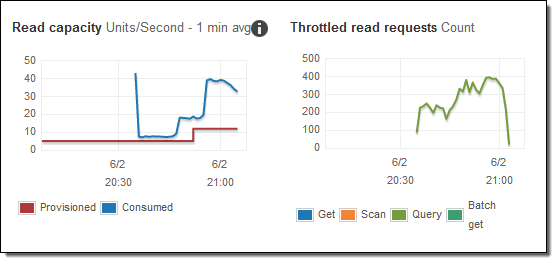
I started a couple of additional copies of my modified query script and watched as additional capacity was provisioned, as indicated by the red line:
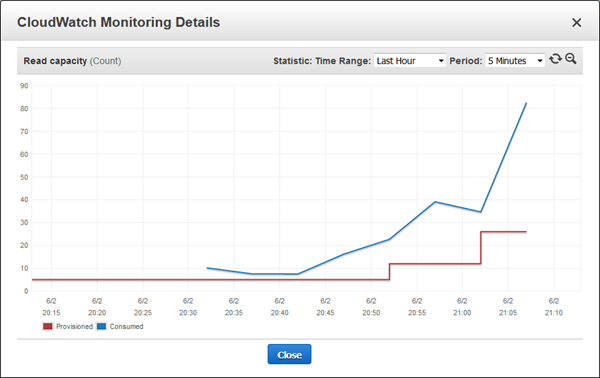
I killed all of the scripts and turned my attention to other things while waiting for the scale-down alarm to trigger. Here’s what I saw when I came back:
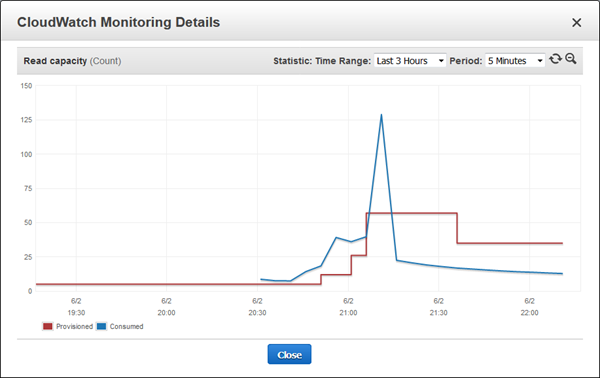
The next morning I checked my Scaling activities and saw that the alarm had triggered several more times overnight:
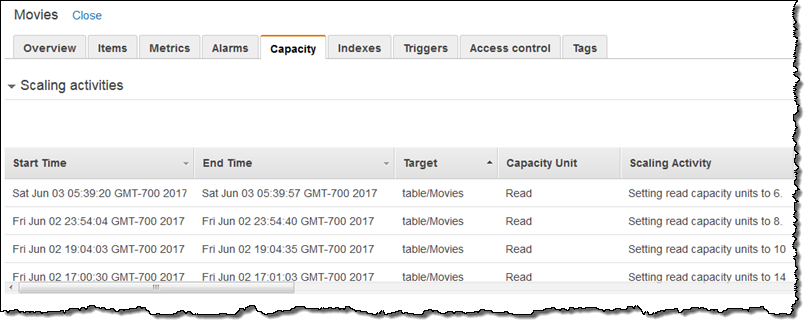
This was also visible in the metrics:
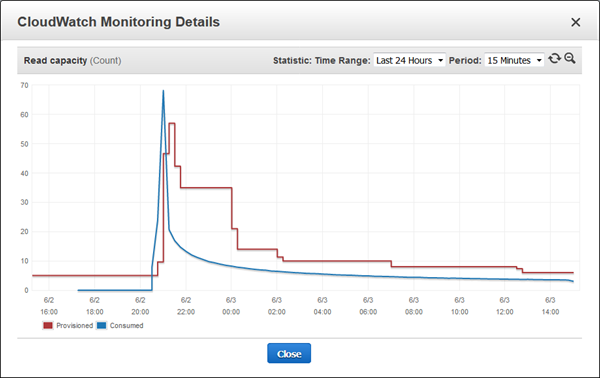
Until now, you would prepare for this situation by setting your read capacity well about your expected usage, and pay for the excess capacity (the space between the blue line and the red line). Or, you might set it too low, forget to monitor it, and run out of capacity when traffic picked up. With Auto Scaling you can get the best of both worlds: an automatic response when an increase in demand suggests that more capacity is needed, and another automated response when the capacity is no longer needed.
Things to Know
DynamoDB Auto Scaling is designed to accommodate request rates that vary in a somewhat predictable, generally periodic fashion. If you need to accommodate unpredictable bursts of read activity, you should use Auto Scaling in combination with DAX (read Amazon DynamoDB Accelerator (DAX) – In-Memory Caching for Read-Intensive Workloads to learn more). Also, the AWS SDKs will detect throttled read and write requests and retry them after a suitable delay.
I mentioned the DynamoDBAutoscaleRole earlier. This role provides Auto Scaling with the privileges that it needs to have in order for it to be able to scale your tables and indexes up and down. To learn more about this role and the permissions that it uses, read Grant User Permissions for DynamoDB Auto Scaling.
Auto Scaling has complete CLI and API support, including the ability to enable and disable the Auto Scaling policies. If you have some predictable, time-bound spikes in traffic, you can programmatically disable an Auto Scaling policy, provision higher throughput for a set period of time, and then enable Auto Scaling again later.
As noted on the Limits in DynamoDB page, you can increase provisioned capacity as often as you would like and as high as you need (subject to per-account limits that we can increase on request). You can decrease capacity up to nine times per day for each table or global secondary index.
You pay for the capacity that you provision, at the regular DynamoDB prices. You can also purchase DynamoDB Reserved Capacity to further savings.
Available Now
This feature is available now in all regions and you can start using it today!
— Jeff;