AWS News Blog
Amazon DynamoDB Accelerator (DAX) – In-Memory Caching for Read-Intensive Workloads

|
I’m fairly sure that you already know about Amazon DynamoDB. As you probably know, it is a managed NoSQL database that scales to accommodate as much table space, read capacity, and write capacity as you need. With response times measured in single-digit milliseconds, our customers are using DynamoDB for many types of applications including adtech, IoT, gaming, media, online learning, travel, e-commerce, and finance. Some of these customers store more than 100 terabytes in a single DynamoDB table and make millions of read or write requests per second. The Amazon retail site relies on DynamoDB and uses it to withstand the traffic surges associated with brief, high-intensity events such as Black Friday, Cyber Monday, and Prime Day.
While DynamoDB’s ability to deliver fast, consistent performance benefits just about any application and workload, there’s always room to do even better. The business value of some workloads (gaming and adtech come to mind, but there are many others) is driven by low-latency, high-performance database reads. The ability to pull data from DynamoDB as quickly as possible leads to faster & more responsive games or ads that drive the highest click-through rates.
Amazon DynamoDB Accelerator
 In order to support demanding, read-heavy workloads, we are launching a public preview of the Amazon DynamoDB Accelerator, otherwise known as DAX.
In order to support demanding, read-heavy workloads, we are launching a public preview of the Amazon DynamoDB Accelerator, otherwise known as DAX.
DAX is a fully managed caching service that sits (logically) in front of your DynamoDB tables. It operates in write-through mode, and is API-compatible with DynamoDB. Responses are returned from the cache in microseconds, making DAX a great fit for eventually-consistent read-intensive workloads. DAX is seamless and easy to use. As a managed service, you simply create your DAX cluster and use it as the target for your existing reads and writes. You don’t have to worry about patching, cluster maintenance, replication, or fault management.
Each DAX cluster can contain 1 to 10 nodes; you can add nodes in order to increase overall read throughput. The cache size (also known as the working set) is based on the node size (dax.r3.large to dax.r3.8xlarge) that you choose when you create the cluster. Clusters run within a VPC, with nodes spread across Availability Zones.
You will need to use the DAX SDK for Java to communicate with DAX. This SDK communicates with your cluster using a low-level TCP interface that is fine-tuned for low latency and high throughput (we’ll support access to DAX through other languages as quickly as possible).
Creating a DAX Cluster
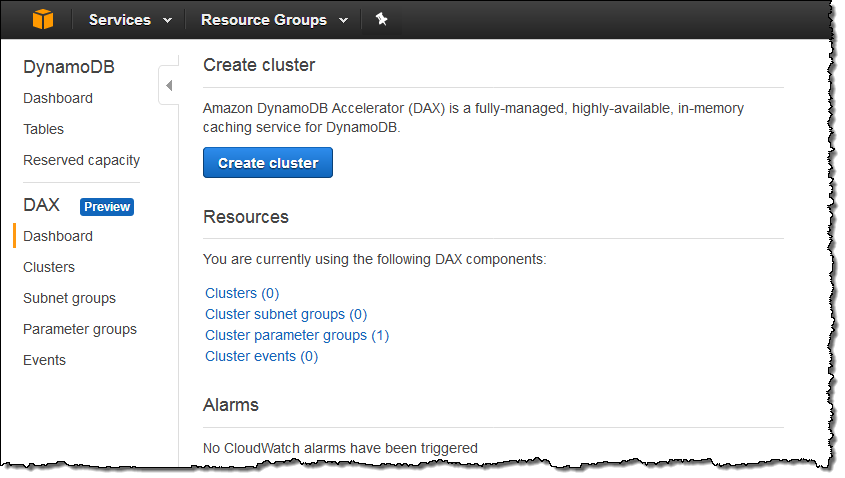
Let’s create a DAX cluster from the DynamoDB Console (API and CLI support is also available). I open up the console and click on Create cluster to get started:
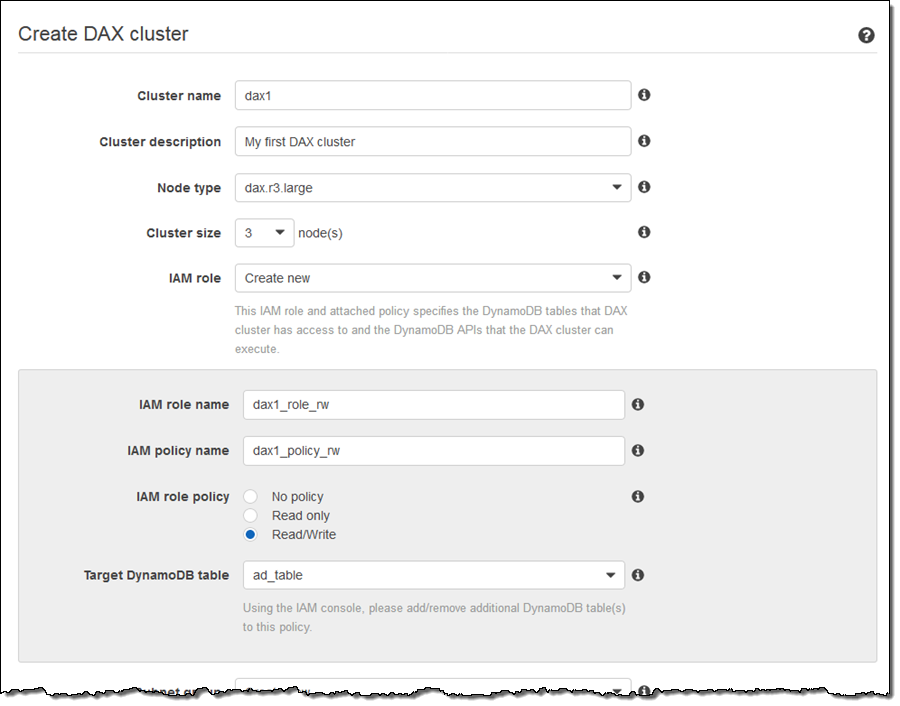
I enter a name and description, choose a node type, and set the initial size of my cluster. Then I create an IAM role and policy that gives DAX permission to access my DynamoDB tables (I can also choose an existing role):
The console allows me to create a policy that grants access to a single table. I add additional tables to the policy using the IAM Console.
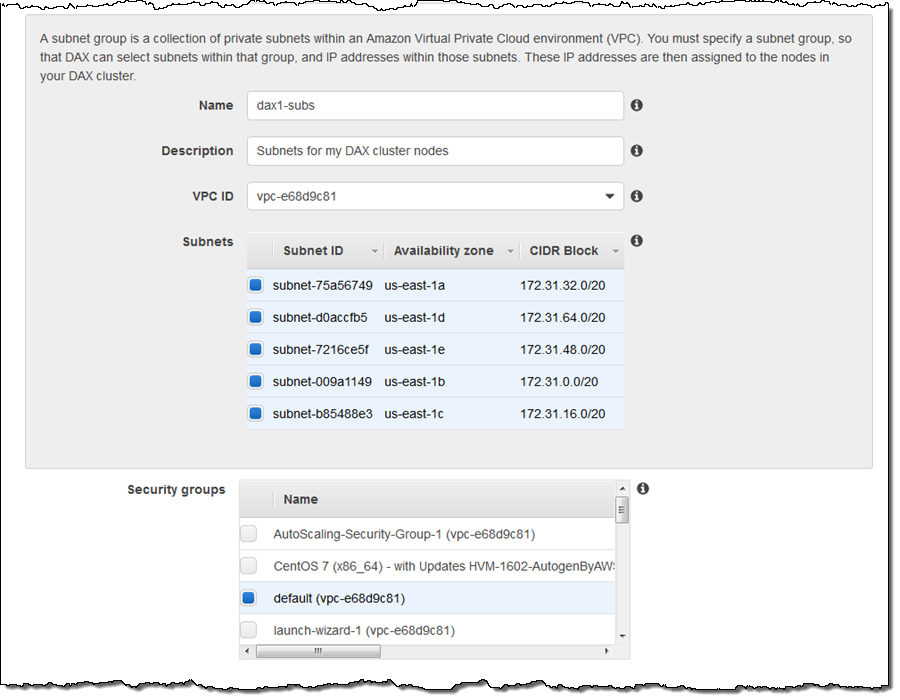
Next, I create a subnet group that DAX uses to place cluster nodes. I name the group and choose the desired subnets:
I accept the default settings and then click on Launch cluster:
My cluster is ready to use within minutes:
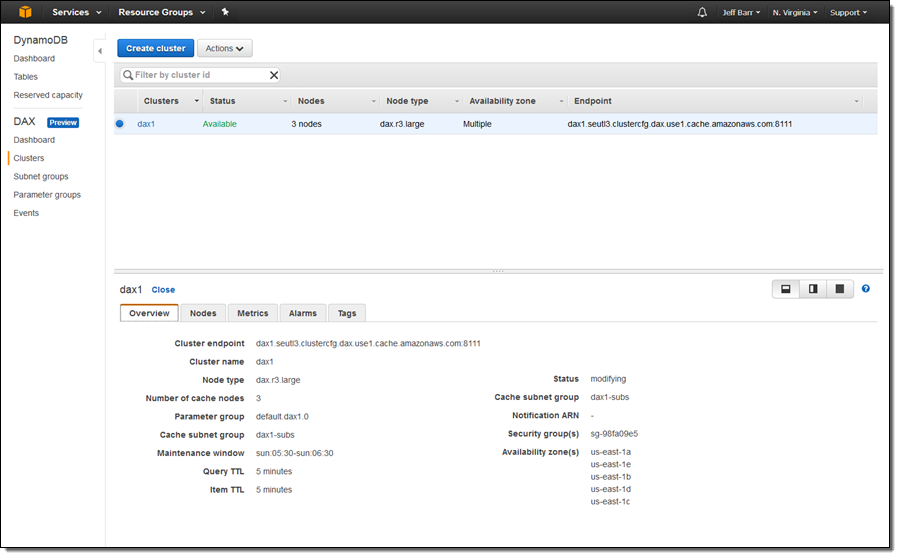
The next step is to update my application to use the DAX SDK for Java and to configure it to use the endpoint of my cluster (dax1.seutl3.clustercfg.dax.use1.cache.amazonaws.com:8111 in this case).
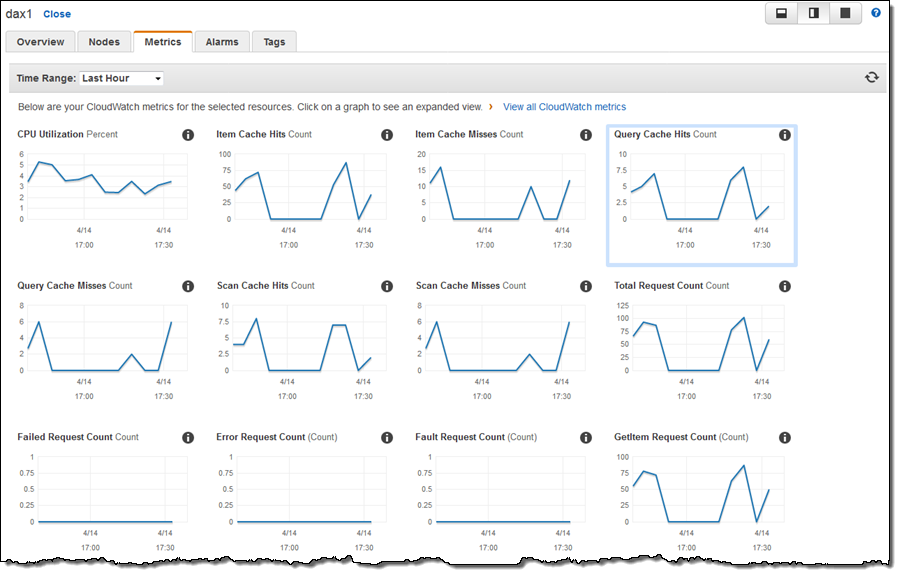
Once my application is up and running, I can visit the Metrics tab to see how well the cache is performing. The Amazon CloudWatch metrics include cache hits and misses, request counts, error counts, and so forth:
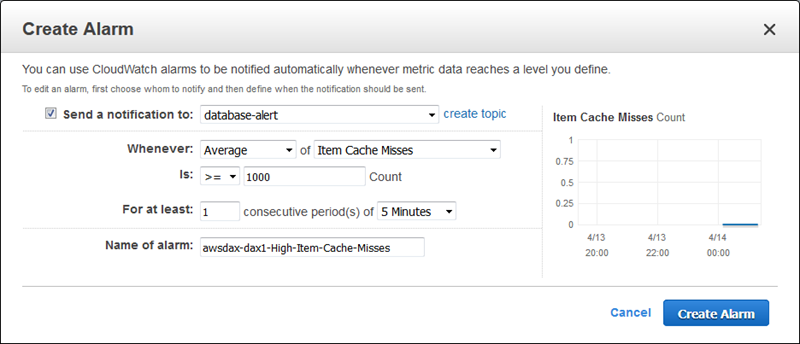
I can use the Alarms tab to create a CloudWatch Alarm for any of the metrics. Perhaps I want to know if an excessive number of cache misses are taking place:
I can use the Nodes tab to see the nodes in my cluster. I can also add new nodes or delete existing ones:
In order to see how DAX works, I installed the DAX Sample Application and ran it twice. The first run accessed DynamoDB directly and demonstrated the non-cached, baseline performance:
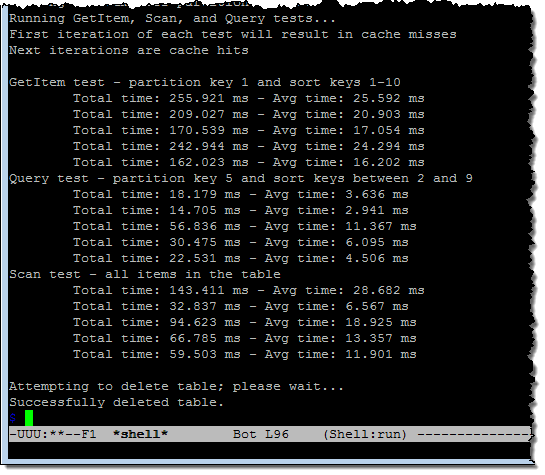
As you can see from the middle group of results, the queries ran in 2.9 to 11.3 milliseconds. The second run used DAX and showed the effect of caching on performance:
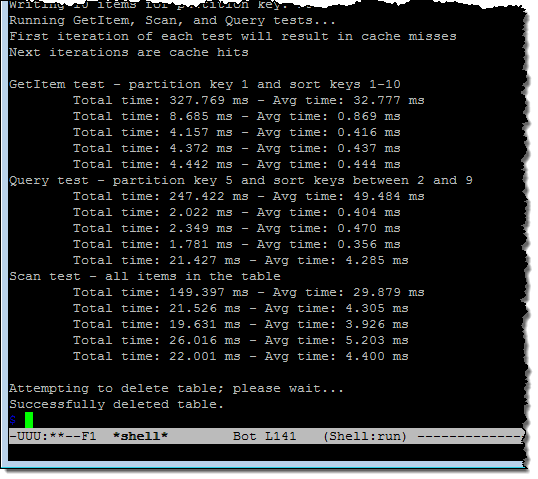
The first iteration of each test results in a cache miss. The subsequent iterations retrieve the results from the cache, and are (as you can see) quite a bit faster.
Things to Know
Here are a few things to keep in mind as you think about how to put DAX to use in your environment:
Java API – As I mentioned earlier, we are launching this public preview with support for Java, with plans to add support for other languages. DAX is API-compatible with DynamoDB so there’s no need to write your own caching logic or make changes to your code.
Consistency – DAX offers the best opportunity for performance gains when you are using eventually consistent reads that can be served from the in-memory cache (DAX always refers back to the DynamoDB table when processing consistent reads).
Write-Throughs – DAX is a write-through cache. However, if there is a weak correlation between what you read and what you write, you may want to direct your writes to DynamoDB. This will allow DAX to be of greater assistance for your reads.
Deprovisioning – After you have put DAX to use in your environment, you should be able to reduce the amount of read capacity provisioned for the underlying tables. This will reduce your costs (dramatically in many cases), while allowing DAX to provide spare capacity for sudden surges in usage.
Available Now
The public preview of DAX is available today in the US East (N. Virginia), US West (Oregon), and Europe (Ireland) Regions and you can sign up today. You can use the public preview at no charge and you can also learn more by reading the DAX Developer Guide.
— Jeff;