AWS Big Data Blog
Introducing Amazon EMR integration with Apache Ranger
This post was last updated July 2022.
Data security is an important pillar in data governance. It includes authentication, authorization , encryption and audit.
Amazon EMR enables you to set up and run clusters of Amazon Elastic Compute Cloud (Amazon EC2) instances with open-source big data applications like Apache Spark, Apache Hive, Apache Flink, and Presto. You may also want to set up multi-tenant EMR clusters where different users (or teams) can use a shared EMR cluster to run big data analytics workloads. In a multi-tenant cluster, it becomes important to set up mechanisms for authentication (determine who is invoking the application and authenticate the user), authorization (set up who has access to what data), and audit (maintain a log of who accessed what data).
Apache Ranger is an open-source project that provides authorization and audit capabilities for Hadoop and related big data applications like Apache Hive, Apache HBase, and Apache Kafka.
We’re happy to share that starting with Amazon EMR 5.32, we’re including plugins to integrate with Apache Ranger 2.0 that enable authorization and audit capabilities for Apache SparkSQL, Amazon Simple Storage Service (Amazon S3), and Apache Hive.
You can set up a multi-tenant EMR cluster, use Kerberos for user authentication, use Apache Ranger 2.0 (managed separately outside the EMR cluster) for authorization, and configure fine-grained data access policies for databases, tables, columns, and S3 objects. In this post, we explain how you can set up Amazon EMR to use Apache Ranger for data access controls for Apache Spark and Apache Hive workloads on Amazon EMR. We show how you can set up multiple short-running and long-running EMR clusters with a single, centralized Apache Ranger server that maintains data access control policies.
Managed Apache Ranger plugins for PrestoSQL and PrestoDB will soon follow.
You should consider this solution if one or all of these apply:
- Have experience setting up and managing Apache Ranger admin server (needs to be self-managed)
- Want to port existing Apache Ranger Hive policies over to Amazon EMR
- Need to use the database-backed Hive Metastore and can’t use the AWS Glue Data Catalogdue to limitations
- Require authorization support for Apache Spark (SQL and storage and file access) and Amazon S3
- Store Apache Ranger authorization audits in Amazon Cloudwatch, avoiding the need to maintain an Apache Solr infrastructure
With this native integration, you use the Amazon EMR security configuration to specify Apache Ranger details, without the need for custom bootstrap scripts. You can reuse existing Apache Hive Ranger policies, including support for row-level filters and column masking.

The following image shows table and column-level access set up for Apache SparkSQL.

Additionally, SSH users are blocked from getting AWS Identity and Access Management (IAM) permissions tied with the Amazon EMR instance profiles. This disables access to Amazon S3 using tools like the AWS Command Line Interface(AWS CLI).
The following screenshot that shows access to Amazon S3 blocked when using AWS CLI.

The following screenshots shows how access to the same Amazon S3 location is set up and used through EMRFS (default EMR file system implementation for reading and writing files from Amazon S3).


Prerequisites
Before getting started, you must have the following prerequisites:
- Self-managed Apache Ranger server (2.x only) outside of an EMR cluster
- TLS mutual authentication enabled between Apache Ranger server and Apache Ranger plugins running on the EMR cluster
- Additional IAM roles:
- IAM role for Apache Ranger– Defines privileges that trusted processes have when submitting Spark and Hive jobs
- IAM role for other AWS services– Defines privileges that end-users have when accessing services that aren’t protected by Apache Ranger plugins.
- Updates to the Amazon EC2 EMR role:
- Access to AWS Secrets Manager
- Ability to tag sessions:
sts:TagSession
- New Apache Ranger service definitions installed for Apache Spark and Amazon S3
- Apache Ranger server certificate and private key for plugins uploaded into Secrets Manager
- A CloudWatch log group for Apache Ranger audits
Architecture overview
The following diagram illustrates the architecture for this solution.
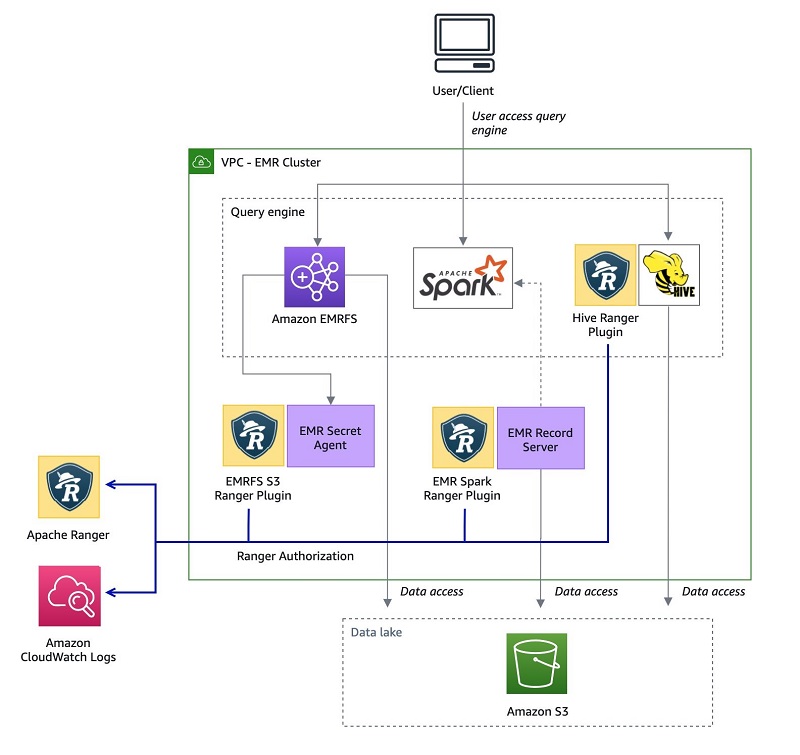
In the architecture, the Amazon EMR secret agent intercepts user requests and vends credentials based on user and resources. The Amazon EMR record server receives requests to access data from Spark, reads data from Amazon S3, and returns filtered data based on Apache Ranger policies.
See Amazon EMR Components to learn more about Amazon EMR Secret Agent and Record Server.
Setting up your resources
In this section, we walk you through setting up your resources manually.
If you want to use CloudFormation scripts to automate the setup, see the section Setting up your architecture with CloudFormation later in this post.
Uploading SSL private keys and certificates to Secrets Manager
Upload the private keys for the Apache Ranger plugins and SSL certification of the Apache Ranger server to Secrets Manager. When the EMR cluster starts up, it uses these files to configure the plugin. For reference, see the script create-tls-certs.sh.
Setting up an Apache Ranger server
You need to set up a two-way SSL-enabled Apache Ranger server. To set up the server manually, refer to the script install-ranger-admin-server.sh.
Installing Apache Ranger service definitions
In this section, we review installing the Apache Ranger service definitions for Apache Spark and Amazon S3.
Apache Spark
To add a new Apache Ranger service definition, see the following script:
This script is included in the Apache Ranger server setup script, if you’re deploying resources with the CloudFormation template.
The policy definition is similar to Apache Hive, except that the actions are limited to select only. The following screenshot shows the definition settings.

To change permissions, for the user, choose select.

Amazon S3 (via Amazon EMR File System)
Similar to Apache Spark, we have a new Apache Ranger service definition for Amazon S3. See the following script:
If you’re using the CloudFormation template, this script is included in the Apache Ranger server setup script.
The following screenshot shows the policy details.

You can enable standard Amazon S3 access permissions in this policy.
Importing your existing Apache Hive policies
You can import your existing Apache Hive policies into the Apache Ranger server tied to the EMR cluster. For more information, see User Guide for Import-Export.
The following image shows how to use Apache Ranger’s export and import option.

CloudWatch for Apache Ranger audits
Apache Ranger audits are sent to CloudWatch. You should create a new Cloudwatch log group and specify that in the security configuration. See the following code:
You can search audit information using CloudWatch Insights. The following screenshot shows a query.


New Amazon EMR security configuration
The new Amazon EMR security configuration requires the following inputs:
- IP address of the Apache Ranger server
- IAM role for the Apache Ranger service (see the GitHub repo) running on the EMR cluster and accessing other AWS services (see the GitHub repo)
- Secrets Manager name with the Apache Ranger admin server certificate
- Secrets Manager name with the private key used by the plugins
- CloudWatch log group name
The following code is an example of using the AWS CLI to create this security configuration:
Install Amazon EMR cluster with Kerberos
Start the cluster by choosing Amazon EMR version 5.32 and this newly created security configuration.
Setting up your architecture with CloudFormation
To help you get started, we added a new GitHub repo with setup instructions. The following diagram shows the logical architecture after the CloudFormation stack is fully deployed. Review the roadmap for future enhancements.

To set up this architecture using CloudFormation, complete the following steps:
- Use the create-tls-certs.sh script to upload the SSL key and certifications to Secrets Manager.
- Set up the VPC or Active Directory server by launching the following CloudFormation template.

- Verify DHCP options to make sure the domain name servers for the VPC are listed in the right order (LDAP/AD server first, followed by
AmazonProvidedDNS). - Set up the Apache Ranger server, Amazon Relational Database Service (Amazon RDS) instance, and EMR cluster by launching the following CloudFormation template.
Limitations
When using this solution, keep in mind the following limitations:
- As of this writing, Amazon EMR 6.x isn’t supported (only Amazon EMR 5.32+ is supported)
- Non-Kerberos clusters will not be supported.
- Jobs must be submitted through Apache Zeppelin, Hue, Livy, and SSH.
- Only selected applications can be installed on the Apache Ranger-enabled EMR cluster, such as Hadoop, Tez and Ganglia. For a full list, see Supported Applications. The cluster creation request is rejected if you choose applications outside this supported list.
- As of this writing, the SparkSQL plugin doesn’t support column masking and row-level filters.
- You can’t view audits on the Apache Ranger UI as they’re sent to CloudWatch.
- The AWS Glue Data Catalog isn’t supported as the Apache Hive Metastore.
Available now
Native support for Apache Ranger 2.0 with Apache Hive, Apache Spark, and Amazon S3 is available in all regions where Amazon EMR is available except KIX (ap-northeast-3).
Conclusion
Amazon EMR 5.32 includes plugins to integrate with Apache Ranger 2.0 that enable authorization and audit capabilities for Apache SparkSQL, Amazon S3, and Apache Hive. This post demonstrates how to set up Amazon EMR to use Apache Ranger for data access controls for Apache Spark and Apache Hive workloads on Amazon EMR. If you have any thoughts of questions, please leave them in the comments.
About the Author
 Varun Rao Bhamidimarri is a Sr Manager, AWS Analytics Specialist Solutions Architect team. His focus is helping customers with adoption of cloud-enabled analytics solutions to meet their business requirements. Outside of work, he loves spending time with his wife and two kids, stay healthy, mediate and recently picked up gardening during the lockdown.
Varun Rao Bhamidimarri is a Sr Manager, AWS Analytics Specialist Solutions Architect team. His focus is helping customers with adoption of cloud-enabled analytics solutions to meet their business requirements. Outside of work, he loves spending time with his wife and two kids, stay healthy, mediate and recently picked up gardening during the lockdown.