AWS News Blog
New for Amazon Aurora – Use Machine Learning Directly From Your Databases

|
March 23, 2020: Post updated to clarify networking, IAM permissions, and database configurations required to use machine learning from Aurora databases. A new notebook using SageMaker Autopilot gives a complete example, from the set up of the model to the creation of the SQL function using the endpoint. The integrations described in this post are now available for MySQL and PostgreSQL compatible Aurora databases.
Machine Learning allows you to get better insights from your data. But where is most of the structured data stored? In databases! Today, in order to use machine learning with data in a relational database, you need to develop a custom application to read the data from the database and then apply the machine learning model. Developing this application requires a mix of skills to be able to interact with the database and use machine learning. This is a new application, and now you have to manage its performance, availability, and security.
Can we make it easier to apply machine learning to data in a relational database? Even for existing applications?
Starting today, Amazon Aurora is natively integrated with two AWS machine learning services:
- Amazon SageMaker, a service providing you with the ability to build, train, and deploy custom machine learning models quickly.
- Amazon Comprehend, a natural language processing (NLP) service that uses machine learning to find insights in text.
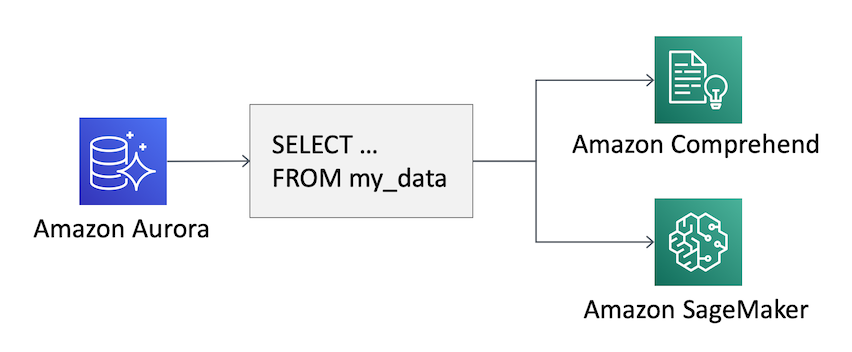
Using this new functionality, you can use a SQL function in your queries to apply a machine learning model to the data in your relational database. For example, you can detect the sentiment of a user comment using Comprehend, or apply a custom machine learning model built with SageMaker to estimate the risk of “churn” for your customers. Churn is a word mixing “change” and “turn” and is used to describe customers that stop using your services.
You can store the output of a large query including the additional information from machine learning services in a new table, or use this feature interactively in your application by just changing the SQL code run by the clients, with no machine learning experience required.
Let’s see a couple of examples of what you can do from an Aurora database, first by using Comprehend, then SageMaker.
Configuring Database Permissions
The first step is to give the database permissions to access the services you want to use: Comprehend, SageMaker, or both. In the RDS console, I create a new Aurora MySQL 5.7 (version 2.07.0 or higher) database.
To use Comprehend or a SageMaker endpoint, the database needs to have network access to those APIs. For simplicity, I am using a publicly accessible database protected by a security group, but you can also use a NAT Gateway.
When the database is available, in the Connectivity & security tab of the regional endpoint, I look for the Manage IAM roles section.
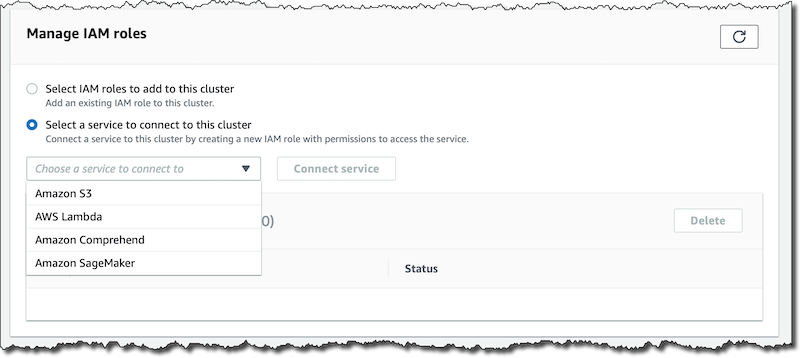
There I connect Comprehend and SageMaker to this database cluster. For SageMaker, I need to provide the Amazon Resource Name (ARN) of the endpoint of a deployed machine learning model. The console takes care of creating the service roles for the Aurora database to access those services in order for the new machine learning integration to work.

When the service roles are active, I create a new DB Cluster Parameter Group and configure the aws_default_comprehend_role and aws_default_sagemaker_role parameters to the ARN of the IAM role created by the console for each service. I get the two role ARNs from the AWS Identity and Access Management (IAM) console.
I modify the database to use this new DB Cluster Parameter Group and select to apply modifications immediately. Then, I reboot the database for the change to take effect.
Using Comprehend from Amazon Aurora
I connect to the database using a MySQL client. To run my tests, I create a table storing comments for a blogging platform and insert a few sample records:
CREATE TABLE IF NOT EXISTS comments (
comment_id INT AUTO_INCREMENT PRIMARY KEY,
comment_text VARCHAR(255) NOT NULL
);
INSERT INTO comments (comment_text)
VALUES ("This is very useful, thank you for writing it!");
INSERT INTO comments (comment_text)
VALUES ("Awesome, I was waiting for this feature.");
INSERT INTO comments (comment_text)
VALUES ("An interesting write up, please add more details.");
INSERT INTO comments (comment_text)
VALUES ("I don’t like how this was implemented.");To detect the sentiment of the comments in my table, I can use the aws_comprehend_detect_sentiment and aws_comprehend_detect_sentiment_confidence SQL functions:
SELECT comment_text,
aws_comprehend_detect_sentiment(comment_text, 'en') AS sentiment,
aws_comprehend_detect_sentiment_confidence(comment_text, 'en') AS confidence
FROM comments;
The aws_comprehend_detect_sentiment function returns the most probable sentiment for the input text: POSITIVE, NEGATIVE, or NEUTRAL. The aws_comprehend_detect_sentiment_confidence function returns the confidence of the sentiment detection, between 0 (not confident at all) and 1 (fully confident).
To estimate the average sentiment of my comments, I use a little bit of SQL to map the results of the aws_comprehend_detect_sentiment_confidence function to numeric values. To make my estimation more robust, I only use the results where confidence is higher than 80%:
SELECT AVG(CASE aws_comprehend_detect_sentiment(comment_text, 'en')
WHEN 'POSITIVE' THEN 1.0
WHEN 'NEGATIVE' THEN -1.0
ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total
FROM comments
WHERE aws_comprehend_detect_sentiment_confidence(comment_text, 'en') >= 0.80;
Using SageMaker Endpoints from Amazon Aurora
Similarly to what I did with Comprehend, I can access a SageMaker endpoint to enrich the information stored in my database. To see a practical use case, let’s implement the customer churn example mentioned at the beginning of this post.
Mobile phone operators have historical records on which customers ultimately ended up churning and which continued using the service. We can use this historical information to construct a machine learning model. As input for the model, we’re looking at the current subscription plan, how much the customer is speaking on the phone at different times of day, and how often has called customer service.
Here’s the structure of my customer table:
SHOW COLUMNS FROM customers;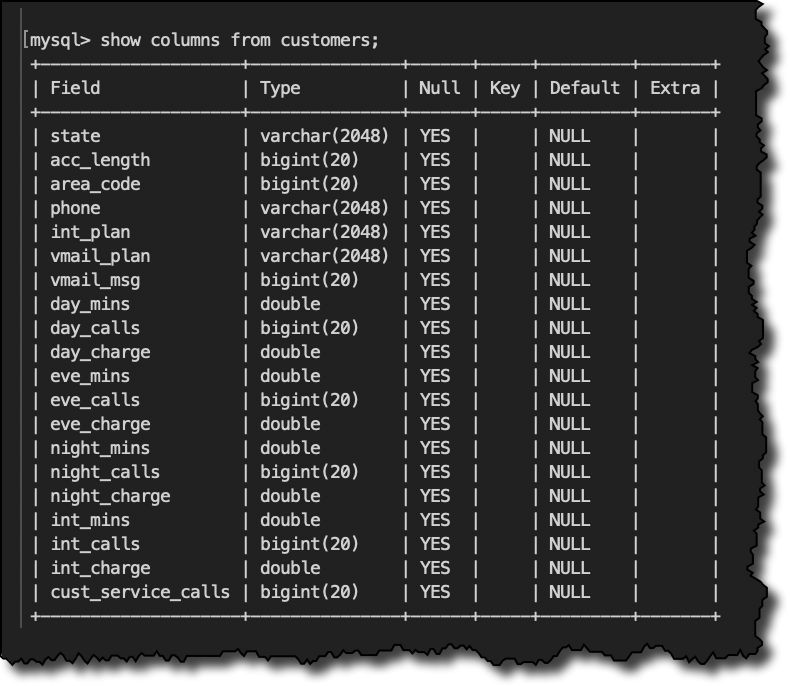
To be able to identify customers at risk of churn, I train a model using the XGBoost algorithm with this sample SageMaker notebook. I am using Amazon SageMaker AutoPilot here also to manage the data processing necessary to convert data formats between what used by the machine learning model and what is given in input to the endpoint for inference. For example, I need to convert fields containing categorical data into the numerical format expected/returned by the algorithm I am using.
When the SageMaker endpoint is in service, I go back to the Manage IAM roles section of the console to give the Aurora database permissions to access the endpoint ARN, and update the DB Cluster Parameter Group parameter aws_default_sagemaker_role to the ARN of the IAM role created by the console.
Now, I create a new will_churn SQL function giving input to the endpoint the parameters required by the model:
CREATE FUNCTION will_churn (
state varchar(2048), acc_length bigint(20),
area_code bigint(20), phone varchar(2048),
int_plan varchar(2048),
vmail_plan varchar(2048), vmail_msg bigint(20),
day_mins double, day_calls bigint(20), day_charge double,
eve_mins double, eve_calls bigint(20), eve_charge double,
night_mins double, night_calls bigint(20), night_charge double,
int_mins double, int_calls bigint(20), int_charge double,
cust_service_calls bigint(20))
RETURNS varchar(2048) CHARSET utf8mb4
alias aws_sagemaker_invoke_endpoint
endpoint name 'tuning-job-123';As you can see, the model looks at the customer’s phone subscription details and service usage patterns to identify the risk of churn. Using the will_churn SQL function, I run a query over my customers table to flag customers based on my machine learning model. To store the result of the query, I create a new customers_churn table:
CREATE TABLE customers_churn AS
SELECT *, will_churn(state, acc_length, area_code, phone, int_plan,
vmail_plan, vmail_msg, day_mins, day_calls, day_charge,
eve_mins, eve_calls, eve_charge, night_mins, night_calls, night_charge,
int_mins, int_calls, int_charge, cust_service_calls) will_churn
FROM customers;Let’s see a few records from the customers_churn table:
SELECT * FROM customers_churn LIMIT 7;
I am lucky the first 7 customers are apparently not going to churn. But what happens overall? Since I stored the results of the will_churn function, I can run a SELECT GROUP BY statement on the customers_churn table.
SELECT will_churn, COUNT(*) FROM customers_churn GROUP BY will_churn;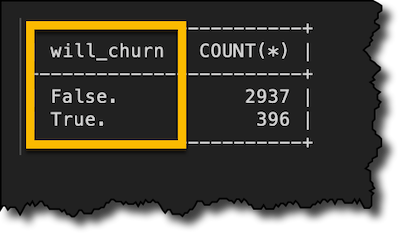
Starting from there, I can dive deep to understand what brings my customers to churn.
If I create a new version of my machine learning model, with a new endpoint ARN, I can recreate the will_churn function, and update IAM permissions, without changing my SQL statements.
Available Now
The new machine learning integration is available today for Aurora MySQL 5.7 (version 2.07.0 and higher), and Aurora PostgreSQL version 10.11, 11.6, or higher. You can learn more in the documentation.
The Aurora machine learning integration is available in all regions in which the underlying services are available. For example, if one of the Aurora compatible database engines and SageMaker are available in a region, then you can use the integration for SageMaker. For a complete list of services availability, please see the AWS Regional Table.
There’s no additional cost for using the integration, you just pay for the underlying services at your normal rates. Pay attention to the size of your queries when using Comprehend. For example, if you do sentiment analysis on user feedback in your customer service web page, to contact those who made particularly positive or negative comments, and people are making 10,000 comments a day, you’d pay $3/day. To optimize your costs, remember to store results.
It’s never been easier to apply machine learning models to data stored in your relational databases. Let me know what you are going to build with this!
— Danilo